Apply fine-grained information entry controls with AWS Lake Formation in Amazon SageMaker Information Wrangler

Amazon SageMaker Data Wrangler reduces the time it takes to gather and put together information for machine studying (ML) from weeks to minutes. You may streamline the method of function engineering and information preparation with SageMaker Information Wrangler and end every stage of the info preparation workflow (together with information choice, purification, exploration, visualization, and processing at scale) inside a single visible interface. Information is often saved in information lakes that may be managed by AWS Lake Formation, providing you with the power to implement fine-grained entry management utilizing a simple grant or revoke process. SageMaker Information Wrangler helps fine-grained information entry management with Lake Formation and Amazon Athena connections.
We’re completely happy to announce that SageMaker Information Wrangler now helps utilizing Lake Formation with Amazon EMR to offer this fine-grained information entry restriction.
Information professionals equivalent to information scientists wish to use the ability of Apache Spark, Hive, and Presto working on Amazon EMR for quick information preparation; nevertheless, the training curve is steep. Our clients needed the power to hook up with Amazon EMR to run advert hoc SQL queries on Hive or Presto to question information within the inside metastore or exterior metastore (such because the AWS Glue Data Catalog), and put together information inside a number of clicks.
On this publish, we present the best way to use Lake Formation as a central information governance functionality and Amazon EMR as a giant information question engine to allow entry for SageMaker Information Wrangler. The capabilities of Lake Formation simplify securing and managing distributed information lakes throughout a number of accounts by means of a centralized strategy, offering fine-grained entry management.
Resolution overview
We reveal this answer with an end-to-end use case utilizing a pattern dataset, the TPC data model. This information represents transaction information for merchandise and contains data equivalent to buyer demographics, stock, net gross sales, and promotions. To reveal fine-grained information entry permissions, we take into account the next two customers:
- David, an information scientist on the advertising and marketing workforce. He’s tasked with constructing a mannequin on buyer segmentation, and is barely permitted to entry non-sensitive buyer information.
- Tina, an information scientist on the gross sales workforce. She is tasked with constructing the gross sales forecast mannequin, and desires entry to gross sales information for the actual area. She can be serving to the product workforce with innovation, and subsequently wants entry to product information as effectively.
The structure is applied as follows:
- Lake Formation manages the info lake, and the uncooked information is accessible in Amazon Simple Storage Service (Amazon S3) buckets
- Amazon EMR is used to question the info from the info lake and carry out information preparation utilizing Spark
- AWS Identity and Access Management (IAM) roles are used to handle information entry utilizing Lake Formation
- SageMaker Information Wrangler is used as the one visible interface to interactively question and put together the info
The next diagram illustrates this structure. Account A is the info lake account that homes all of the ML-ready information obtained by means of extract, rework, and cargo (ETL) processes. Account B is the info science account the place a gaggle of knowledge scientists compile and run information transformations utilizing SageMaker Information Wrangler. To ensure that SageMaker Information Wrangler in Account B to have entry to the info tables in Account A’s information lake through Lake Formation permissions, we should activate the required rights.
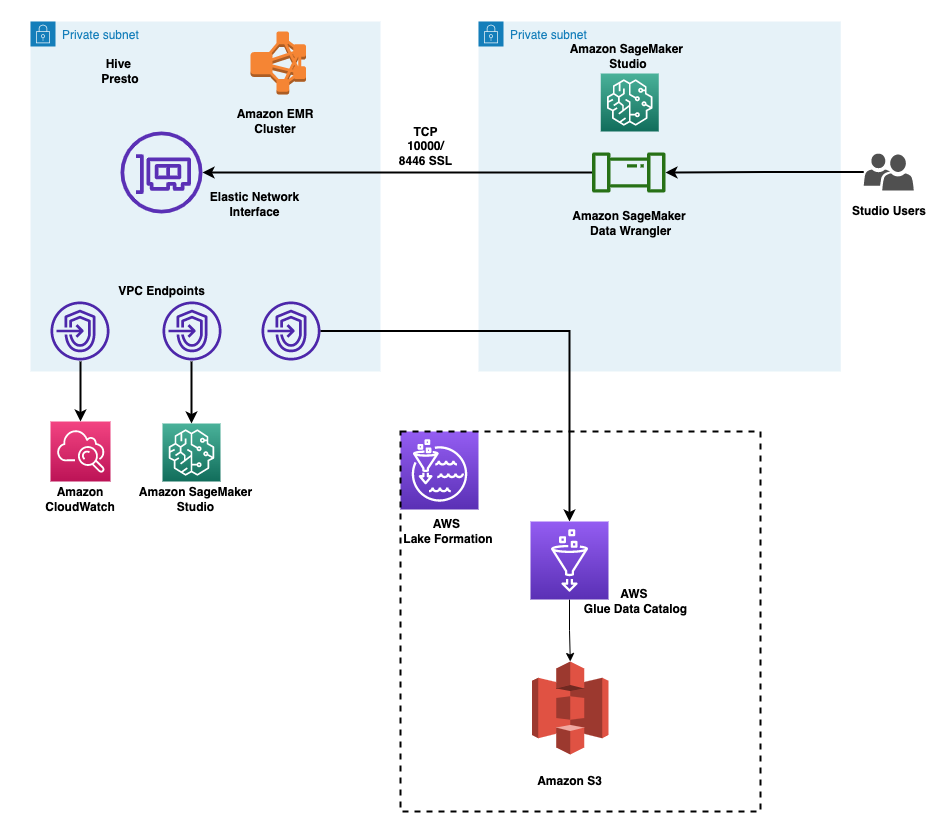
You should utilize the supplied AWS CloudFormation stack to arrange the architectural parts for this answer.
Stipulations
Earlier than you get began, be sure to have the next conditions:
- An AWS account
- An IAM consumer with administrator entry
- An S3 bucket
Provision sources with AWS CloudFormation
We offer a CloudFormation template that deploys the providers within the structure for end-to-end testing and to facilitate repeated deployments. The outputs of this template are as follows:
- An S3 bucket for the info lake.
- An EMR cluster with EMR runtime roles enabled. For extra particulars on utilizing runtime roles with Amazon EMR, see Configure runtime roles for Amazon EMR steps. Associating runtime roles with EMR clusters is supported in Amazon EMR 6.9. Be certain that the next configuration is in place:
- Create a safety configuration in Amazon EMR.
- The EMR runtime function’s belief coverage ought to enable the EMR EC2 occasion profile to imagine the function.
- The EMR EC2 occasion profile function ought to be capable of assume the EMR runtime roles.
- The EMR cluster must be created with encryption in transit.
- IAM roles for accessing the info in information lake, with fine-grained permissions:
- Advertising and marketing-data-access-role
- Gross sales-data-access-role
- An Amazon SageMaker Studio domain and two consumer profiles. The SageMaker Studio execution roles for the customers enable the customers to imagine their corresponding EMR runtime roles.
- A lifecycle configuration to allow the choice of the function to make use of for the EMR connection.
- A Lake Formation database populated with the TPC information.
- Networking sources required for the setup, equivalent to VPC, subnets, and safety teams.
Create Amazon EMR encryption certificates for the info in transit
With Amazon EMR launch model 4.8.0 or later, you’ve possibility for specifying artifacts for encrypting information in transit utilizing a safety configuration. We manually create PEM certificates, embody them in a .zip file, add it to an S3 bucket, after which reference the .zip file in Amazon S3. You doubtless wish to configure the non-public key PEM file to be a wildcard certificates that permits entry to the VPC area through which your cluster cases reside. For instance, in case your cluster resides within the us-east-1 Area, you would specify a standard title within the certificates configuration that enables entry to the cluster by specifying CN=*.ec2.inside within the certificates topic definition. In case your cluster resides in us-west-2, you would specify CN=*.us-west-2.compute.inside.
Run the next instructions utilizing your system terminal. It will generate PEM certificates and collate them right into a .zip file:
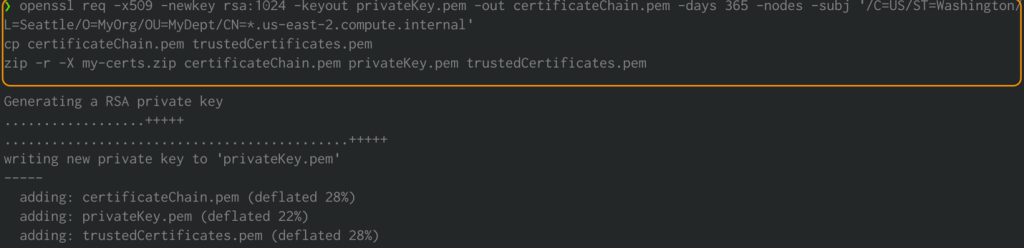
Add my-certs.zip to an S3 bucket in the identical Area the place you plan to run this train. Copy the S3 URI for the uploaded file. You’ll want this whereas launching the CloudFormation template.
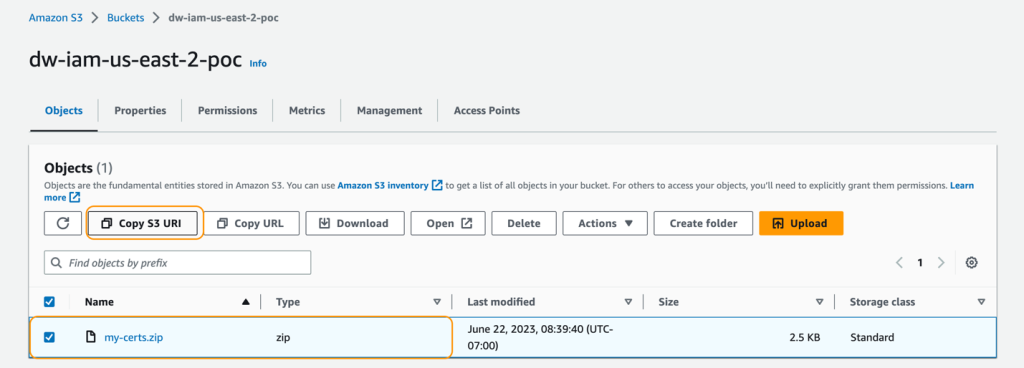
This instance is a proof of idea demonstration solely. Utilizing self-signed certificates just isn’t really helpful and presents a possible safety threat. For manufacturing methods, use a trusted certification authority (CA) to situation certificates.
Deploying the CloudFormation template
To deploy the answer, full the next steps:
- Sign up to the AWS Management Console as an IAM consumer, ideally an admin consumer.
- Select Launch Stack to launch the CloudFormation template:
![]()
- Select Subsequent.
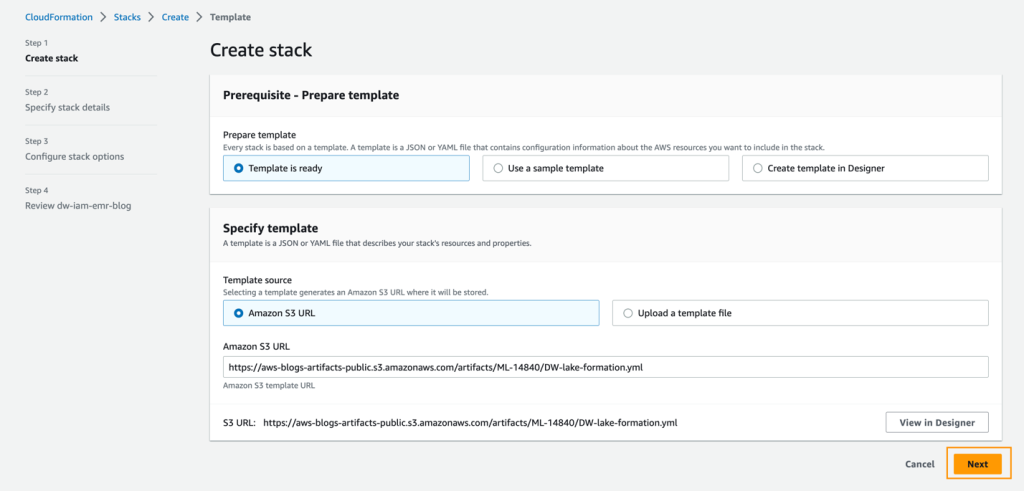
- For Stack title, enter a reputation for the stack.
- For IdleTimeout, enter a price for the idle timeout for the EMR cluster (to keep away from paying for the cluster when it’s not getting used).
- For S3CertsZip, enter an S3 URI with the EMR encryption key.
For directions to generate a key and .zip file particular to your Area, check with Providing certificates for encrypting data in transit with Amazon EMR encryption. In case you are deploying in US East (N. Virginia), keep in mind to make use of CN=*.ec2.inside. For extra data, check with Create keys and certificates for data encryption. Be certain that to add the .zip file to an S3 bucket in the identical Area as your CloudFormation stack deployment.
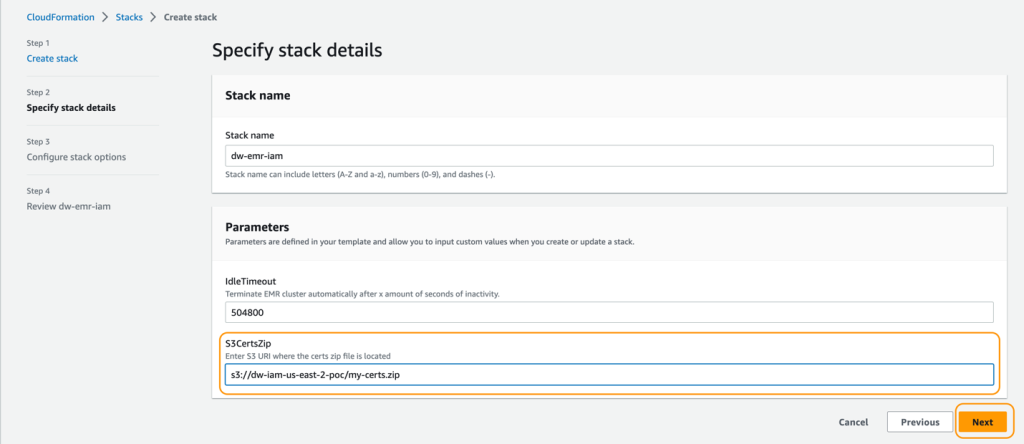
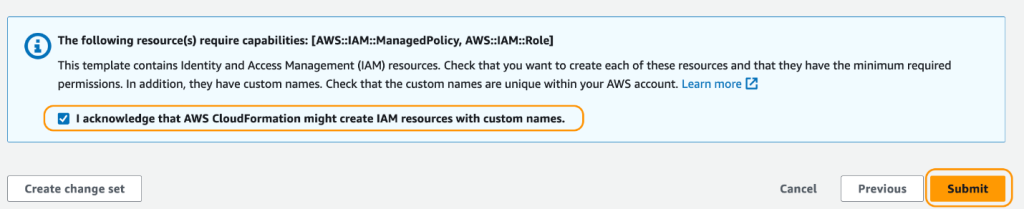
- On the evaluate web page, choose the verify field to verify that AWS CloudFormation would possibly create sources.
- Select Create stack.
Wait till the standing of the stack adjustments from CREATE_IN_PROGRESS to CREATE_COMPLETE. The method normally takes 10–quarter-hour.
After the stack is created, enable Amazon EMR to question Lake Formation by updating the Exterior Information Filtering settings on Lake Formation. For directions, check with Getting started with Lake Formation. Specify Amazon EMR for Session tag values and enter your AWS account ID beneath AWS account IDs.
Take a look at information entry permissions
Now that the required infrastructure is in place, you possibly can confirm that the 2 SageMaker Studio customers have entry to granular information. To evaluate, David shouldn’t have entry to any non-public details about your clients. Tina has entry to details about gross sales. Let’s put every consumer sort to the check.
Take a look at David’s consumer profile
To check your information entry with David’s consumer profile, full the next steps:
- On the SageMaker console, select Domains within the navigation pane.
- From the SageMaker Studio area, launch SageMaker Studio from the consumer profile david-non-sensitive-customer.
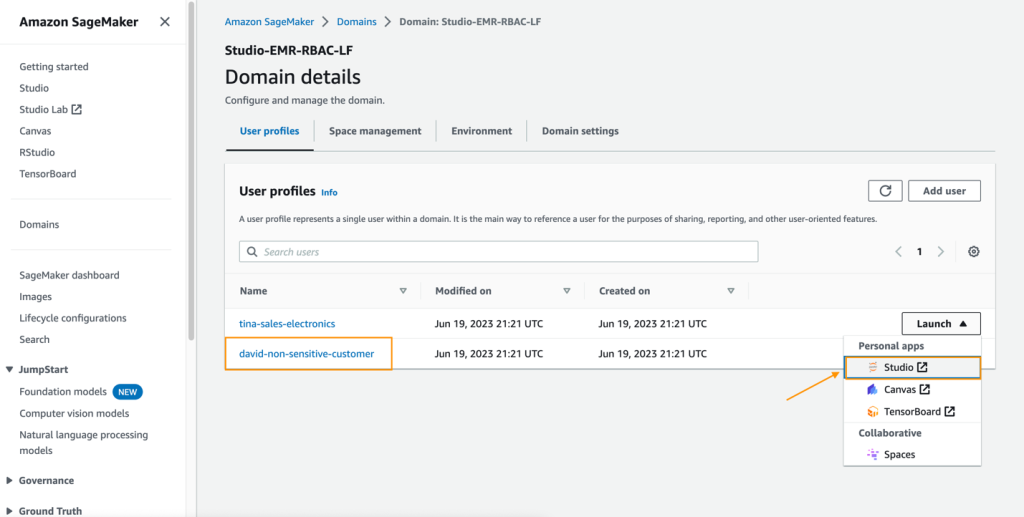
- In your SageMaker Studio setting, create an Amazon SageMaker Data Wrangler stream, and select Import & put together information visually.
Alternatively, on the File menu, select New, then select Information Wrangler stream.
We focus on these steps to create an information stream intimately later on this publish.
Take a look at Tina’s consumer profile
Tina’s SageMaker Studio execution function permits her to entry the Lake Formation database utilizing two EMR execution roles. That is achieved by itemizing the function ARNs in a configuration file in Tina’s file listing. These roles could be set utilizing SageMaker Studio lifecycle configurations to persist the roles throughout app restarts. To check Tina’s entry, full the next steps:
- On the SageMaker console, navigate to the SageMaker Studio area.
- Launch SageMaker Studio from the consumer profile
tina-sales-electronics.
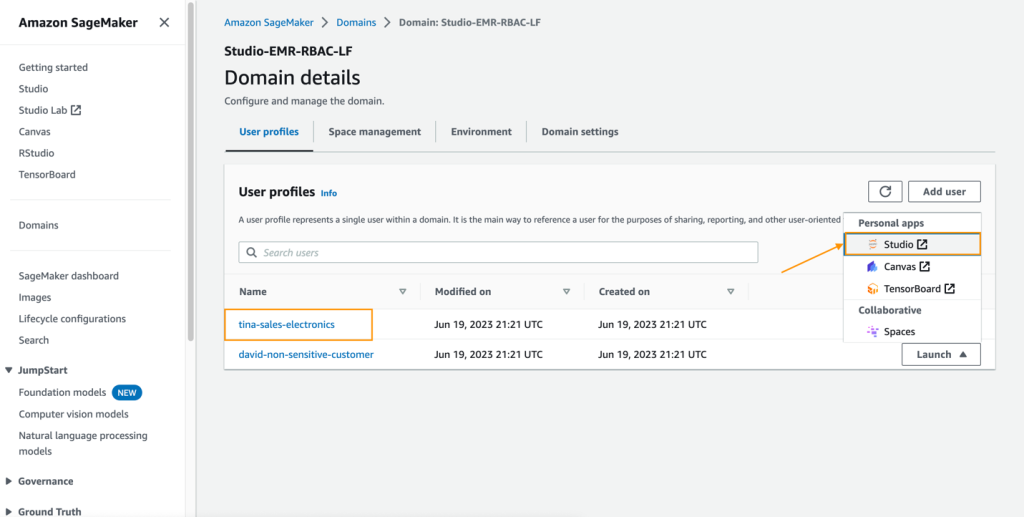
It’s an excellent observe to shut any earlier SageMaker Studio classes in your browser when switching consumer profiles. There can solely be one lively SageMaker Studio consumer session at a time.
- Create a Information Wrangler information stream.
Within the following sections, we showcase creating an information stream inside SageMaker Information Wrangler and connecting to Amazon EMR as the info supply. David and Tina can have related experiences with information preparation, apart from entry permissions, so they are going to see completely different tables.
Create a SageMaker Information Wrangler information stream
On this part, we cowl connecting to the prevailing EMR cluster created by means of the CloudFormation template as an information supply in SageMaker Information Wrangler. For demonstration functions, we use David’s consumer profile.
To create your information stream, full the next steps:
- On the SageMaker console, select Domains within the navigation pane.
- Select StudioDomain, which was created by working the CloudFormation template.
- Choose a consumer profile (for this instance, David’s) and launch SageMaker Studio.
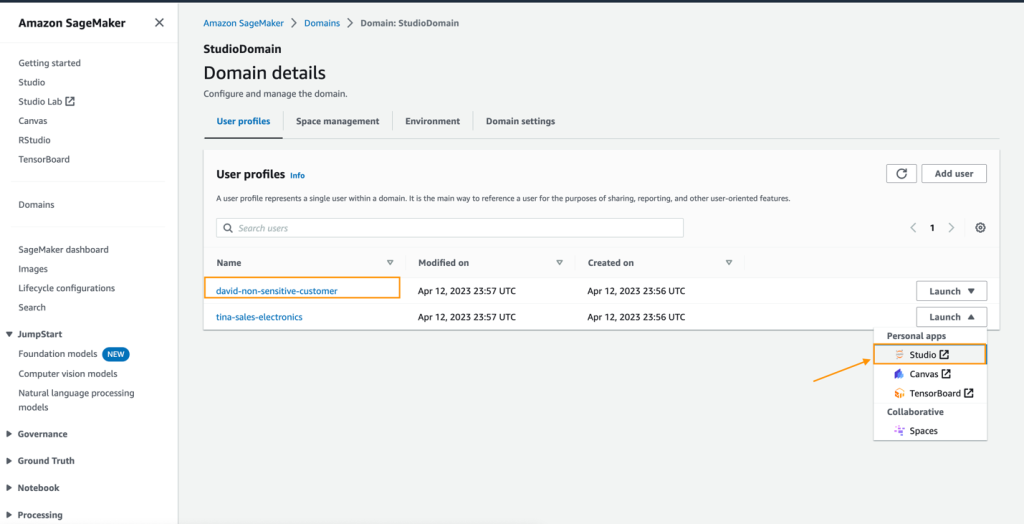
- Select Open Studio.
- In SageMaker Studio, create a brand new information stream and select Import & put together information visually.
Alternatively, on the File menu, select New, then select Information Wrangler stream.
Creating a brand new stream can take a couple of minutes. After the stream has been created, you see the Import information web page.
- So as to add Amazon EMR as an information supply in SageMaker Information Wrangler, on the Add information supply menu, select Amazon EMR.

You may browse all of the EMR clusters that your SageMaker Studio execution function has permissions to see. You could have two choices to hook up with a cluster: one is thru the interactive UI, and the opposite is to first create a secret utilizing AWS Secrets Manager with a JDBC URL, together with EMR cluster data, after which present the saved AWS secret ARN within the UI to hook up with Presto or Hive. On this publish, we use the primary methodology.
- Choose any of the clusters that you just wish to use, then select Subsequent.
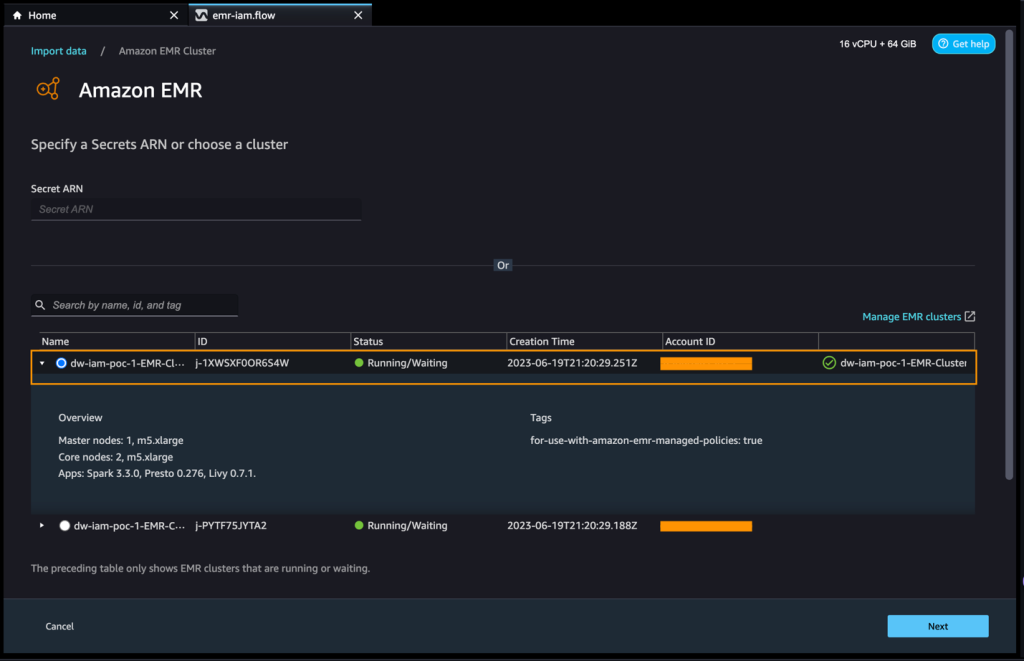
- Choose which endpoint you wish to use.
- Enter a reputation to determine your connection, equivalent to
emr-iam-connection, then select Subsequent.
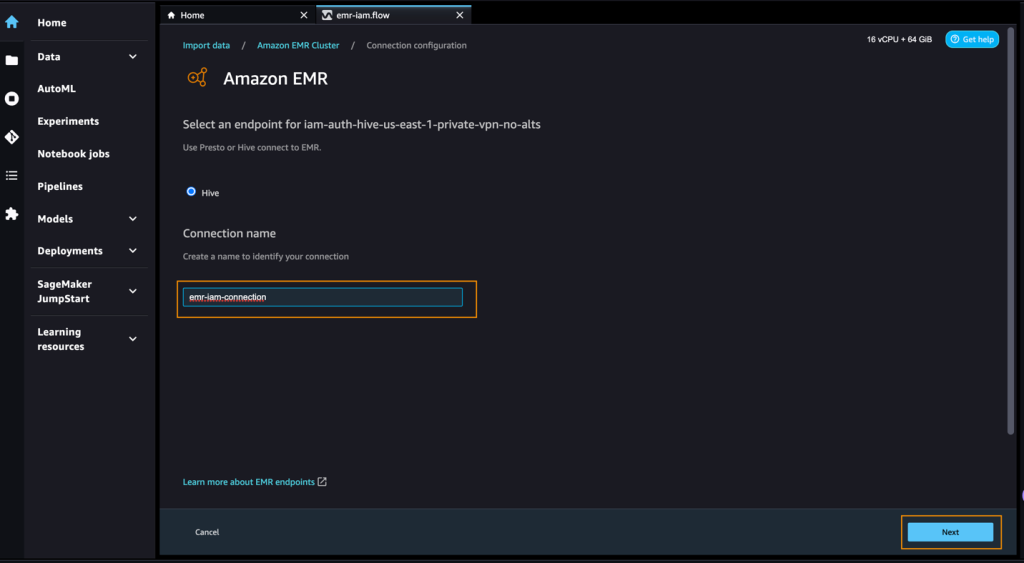
- Choose IAM as your authentication sort and select Join.
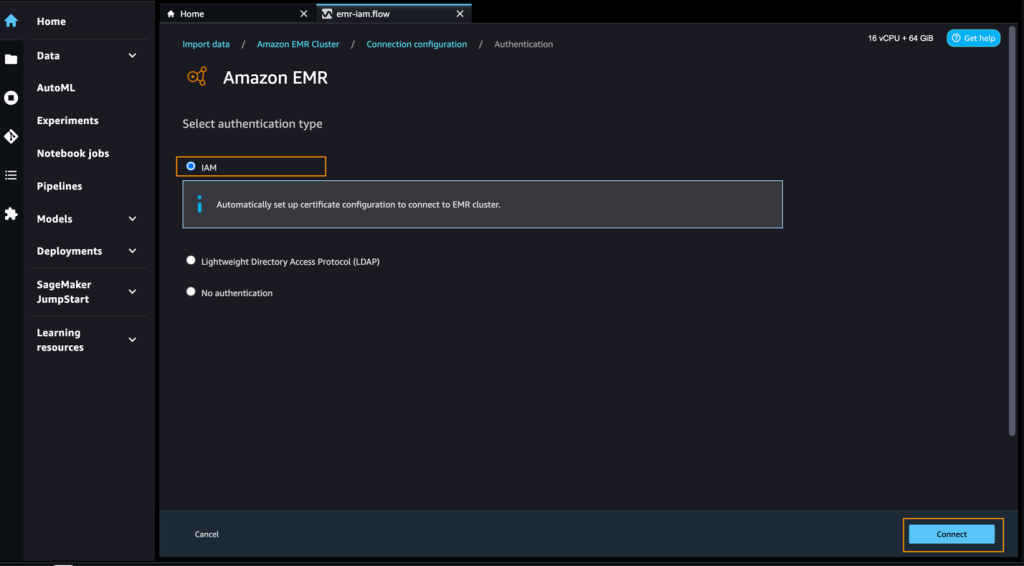
Whenever you’re related, you possibly can interactively view a database tree and desk preview or schema. You may also question, discover, and visualize information from Amazon EMR. For a preview, you see a restrict of 100 information by default. After you present a SQL assertion within the question editor and select Run, the question is run on the Amazon EMR Hive engine to preview the info. Select Cancel question to cancel ongoing queries if they’re taking an unusually very long time.
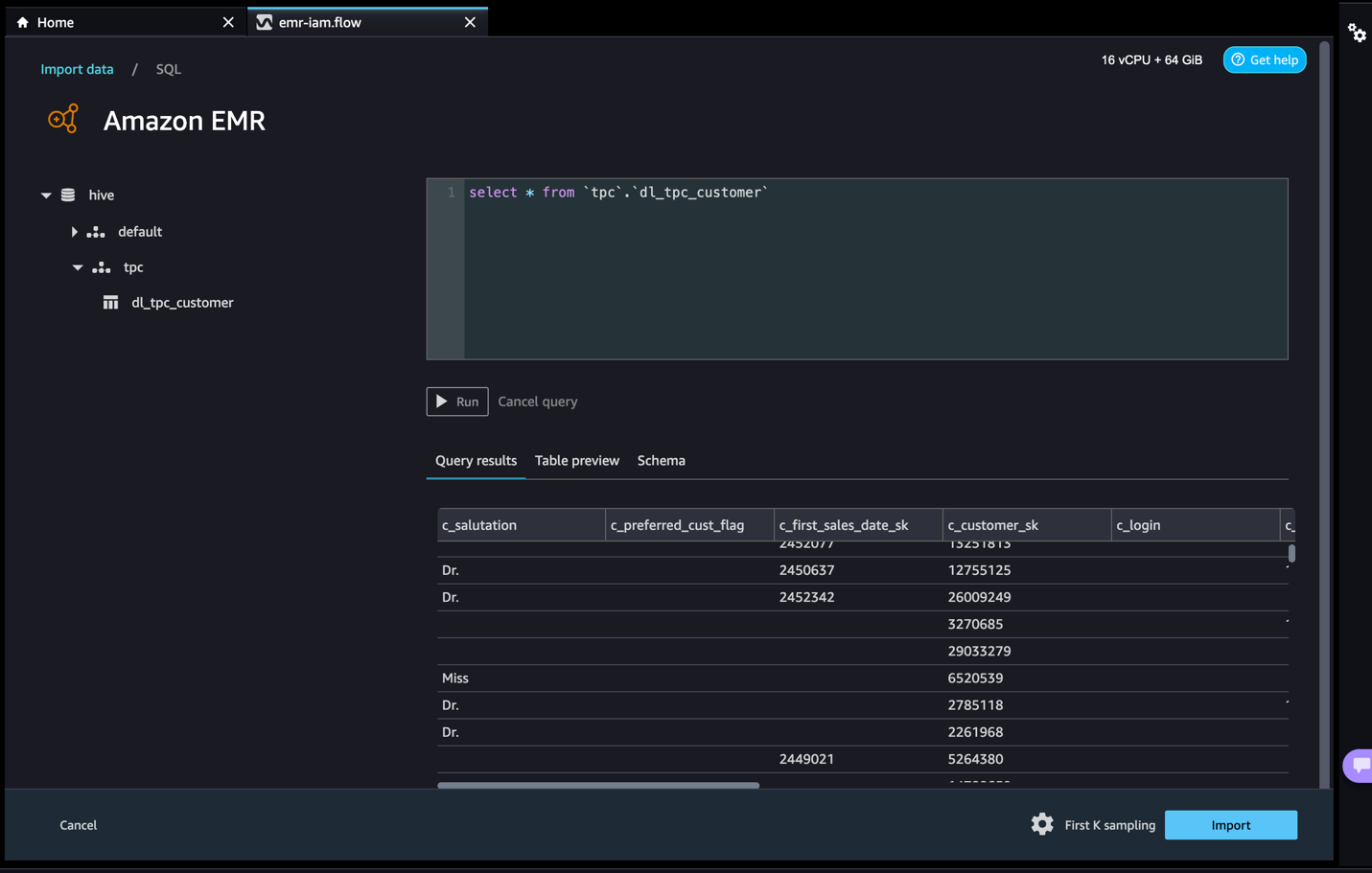
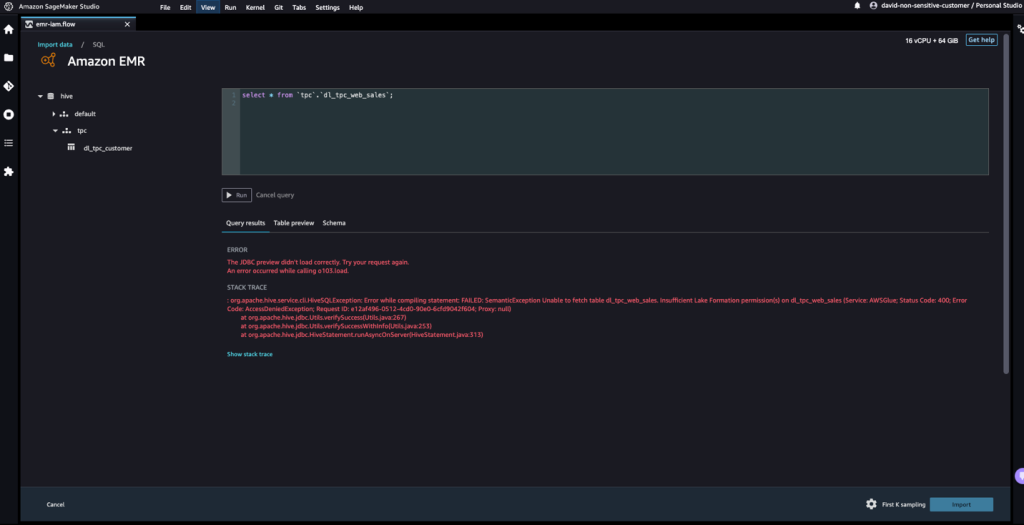
- Let’s entry information from the desk that David doesn’t have permissions to.
The question will consequence within the error message “Unable to fetch desk dl_tpc_web_sales. Inadequate Lake Formation permission(s) on dl_tpc_web_sales.”
The final step is to import the info. If you end up prepared with the queried information, you’ve the choice to replace the sampling settings for the info choice based on the sampling sort (FirstK, Random, or Stratified) and the sampling dimension for importing information into Information Wrangler.
- Select Import to import the info.
On the subsequent web page, you possibly can add numerous transformations and important evaluation to the dataset.
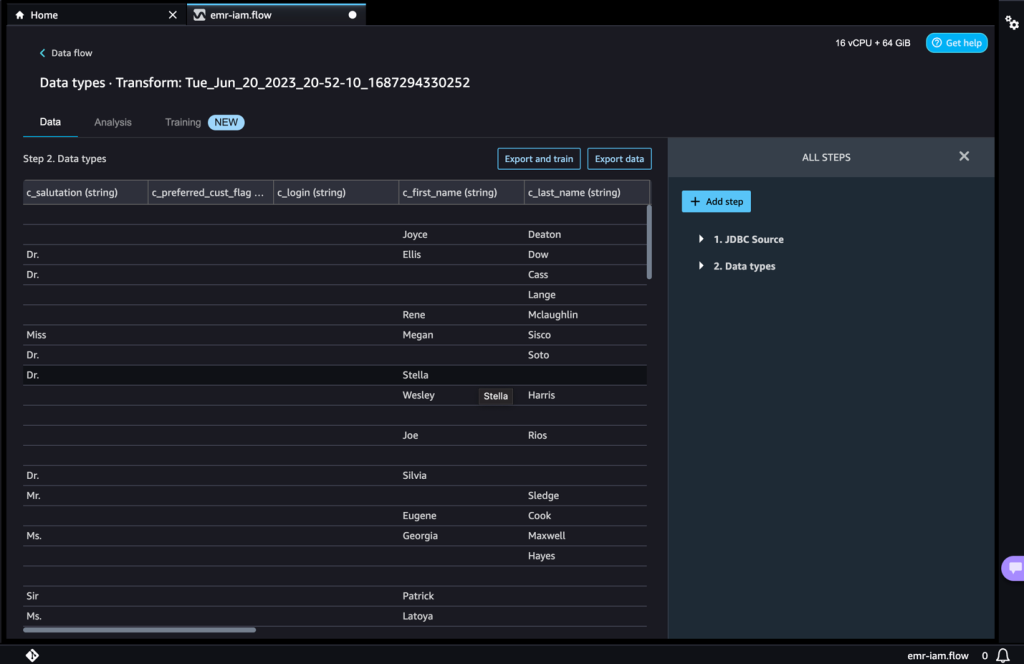
- Navigate to the info stream and add extra steps to the stream as wanted for transformations and evaluation.
You may run a data insight report to determine information high quality points and get suggestions to repair these points. Let’s take a look at some instance transforms.
- Within the Information stream view, it is best to see that we’re utilizing Amazon EMR as an information supply utilizing the Hive connector.
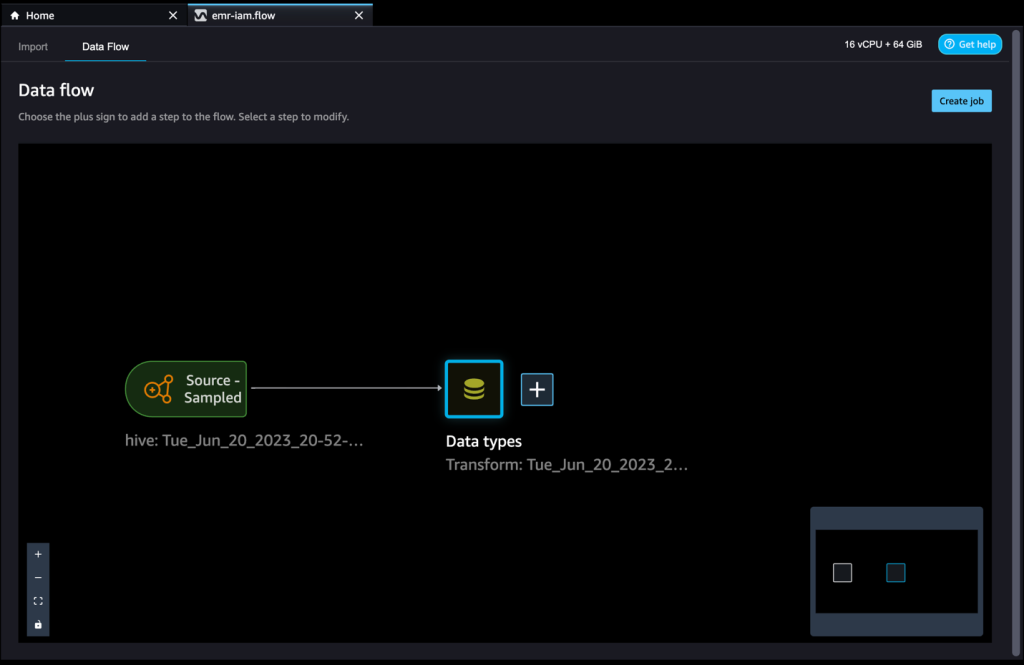
- Select the plus signal subsequent to Information varieties and select Add rework.
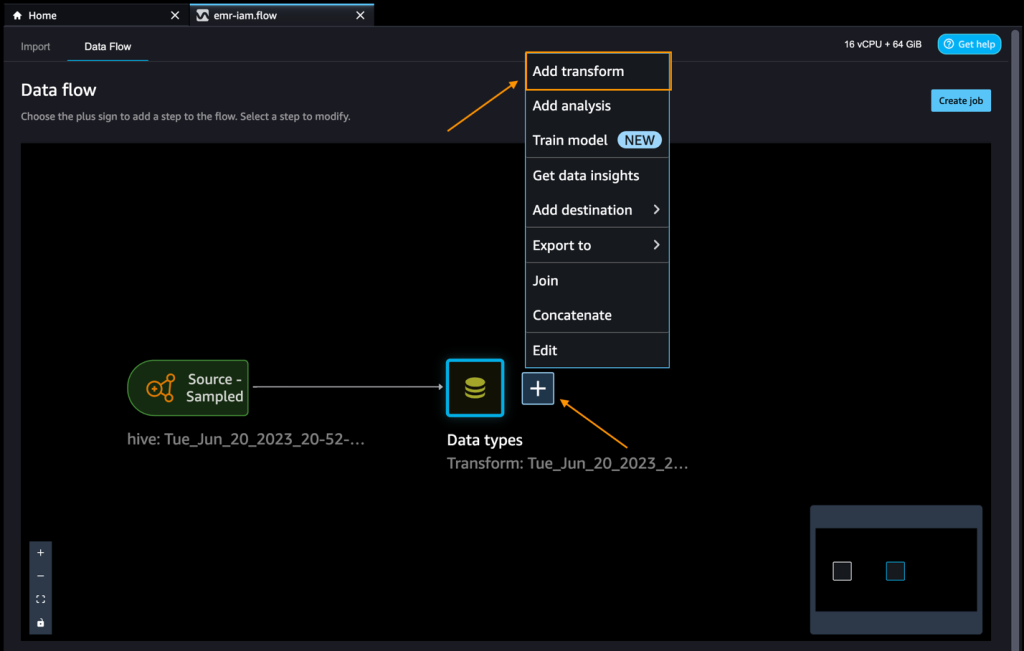
Let’s discover the info and apply a metamorphosis. For instance, the c_login column is empty and it’ll not add worth as a function. Let’s delete the column.
- Within the All steps pane, select Add step.
- Select Handle columns.
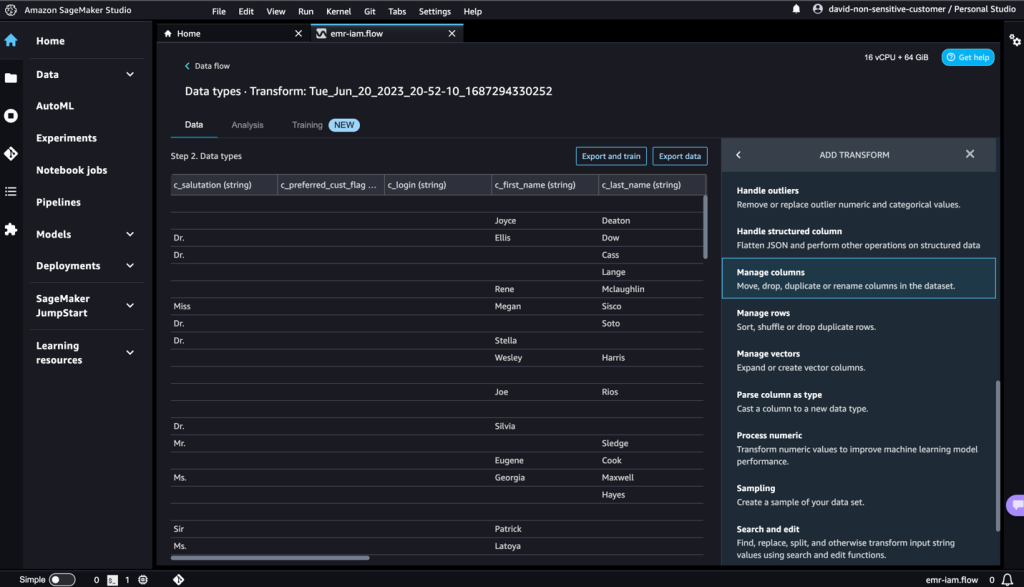
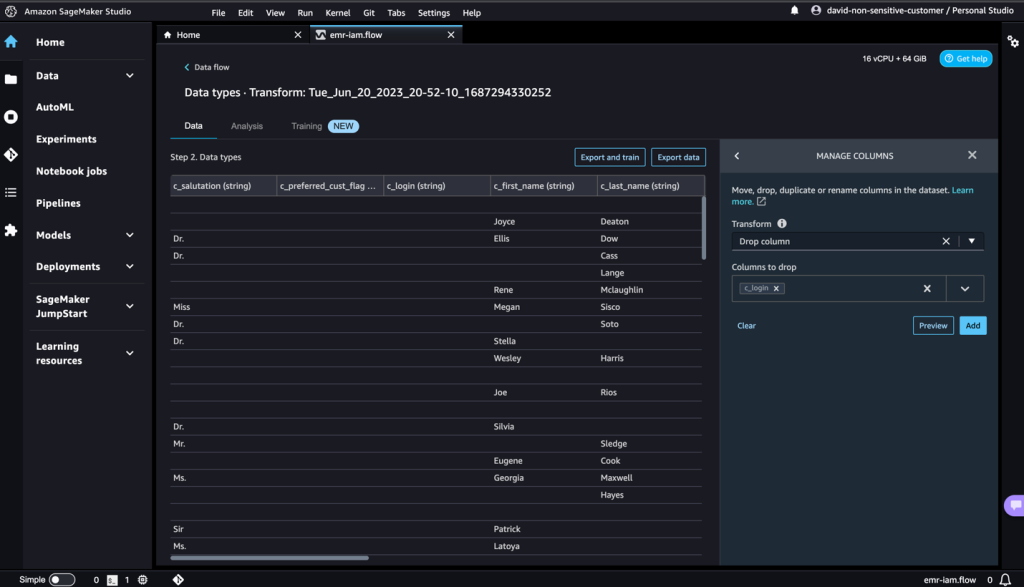
- For Rework, select Drop column.
- For Columns to drop, select the
c_logincolumn. - Select Preview, then select Add.
- Confirm the step by increasing the Drop column part.
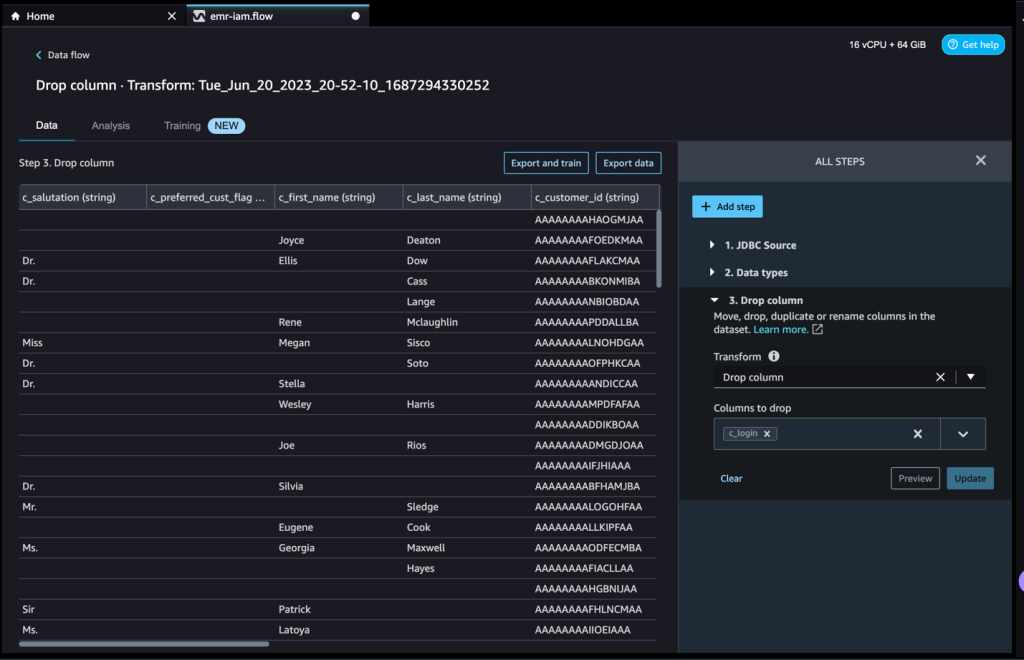
You may proceed including steps based mostly on the completely different transformations required on your dataset. Let’s return to our information stream. Now you can see the Drop column block exhibiting the rework we carried out.
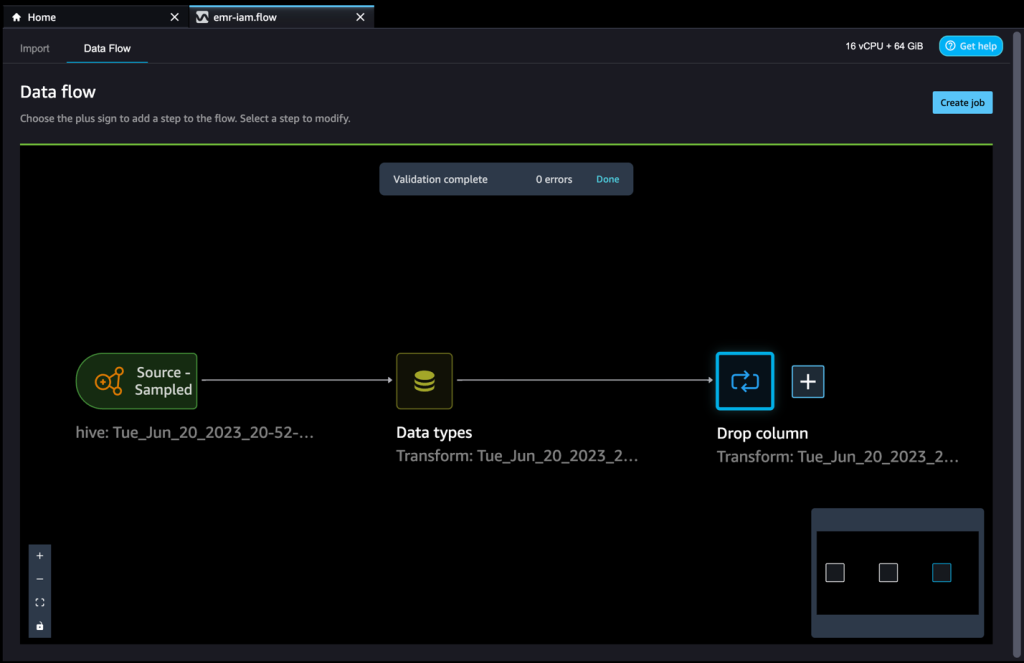
ML practitioners spend lots of time crafting function engineering code, making use of it to their preliminary datasets, coaching fashions on the engineered datasets, and evaluating mannequin accuracy. Given the experimental nature of this work, even the smallest undertaking will result in a number of iterations. The identical function engineering code is usually run time and again, losing time and compute sources on repeating the identical operations. In massive organizations, this could trigger a fair larger lack of productiveness as a result of completely different groups usually run an identical jobs and even write duplicate function engineering code as a result of they don’t have any information of prior work. To keep away from the reprocessing of options, we are able to export our remodeled options to Amazon SageMaker Feature Store. For extra data, check with New – Store, Discover, and Share Machine Learning Features with Amazon SageMaker Feature Store.
- Select the plus signal subsequent to Drop column.
- Select Export to and SageMaker Function Retailer (through Jupyter pocket book).
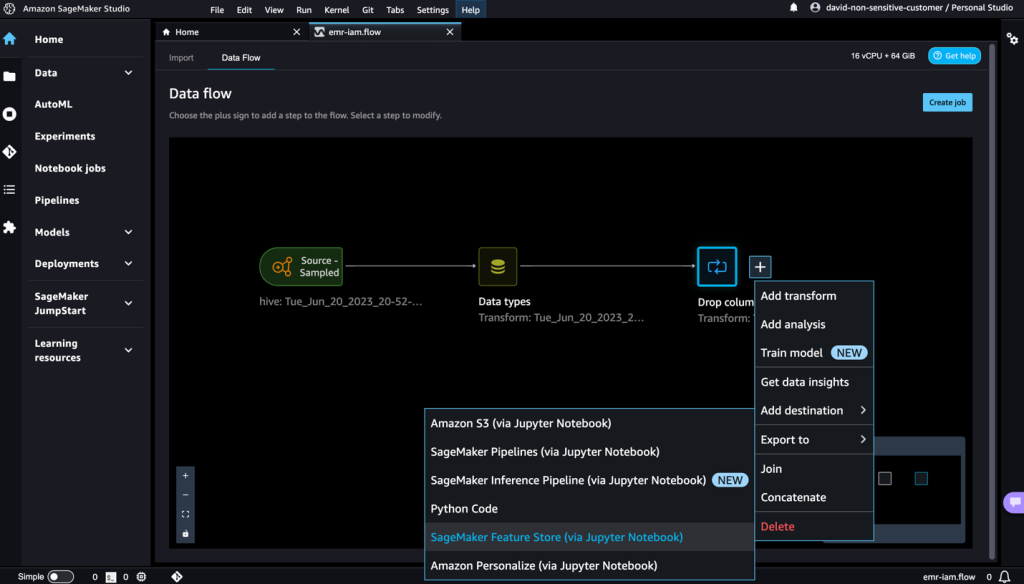
You may simply export your generated options to SageMaker Function Retailer by specifying it because the vacation spot. It can save you the options into an current function group or create a brand new one. For extra data, check with Easily create and store features in Amazon SageMaker without code.
We’ve got now created options with SageMaker Information Wrangler and saved these options in SageMaker Function Retailer. We confirmed an instance workflow for function engineering within the SageMaker Information Wrangler UI.
Clear up
In case your work with SageMaker Information Wrangler is full, delete the sources you created to keep away from incurring extra charges.
- In SageMaker Studio, shut all of the tabs, then on the File menu, select Shut Down.
- When prompted, select Shutdown All.
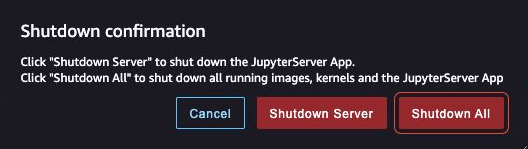
Shutdown would possibly take a couple of minutes based mostly on the occasion sort. Be certain that all of the apps related to every consumer profile obtained deleted. In the event that they weren’t deleted, manually delete the app related beneath every consumer profile created utilizing the CloudFormation template.
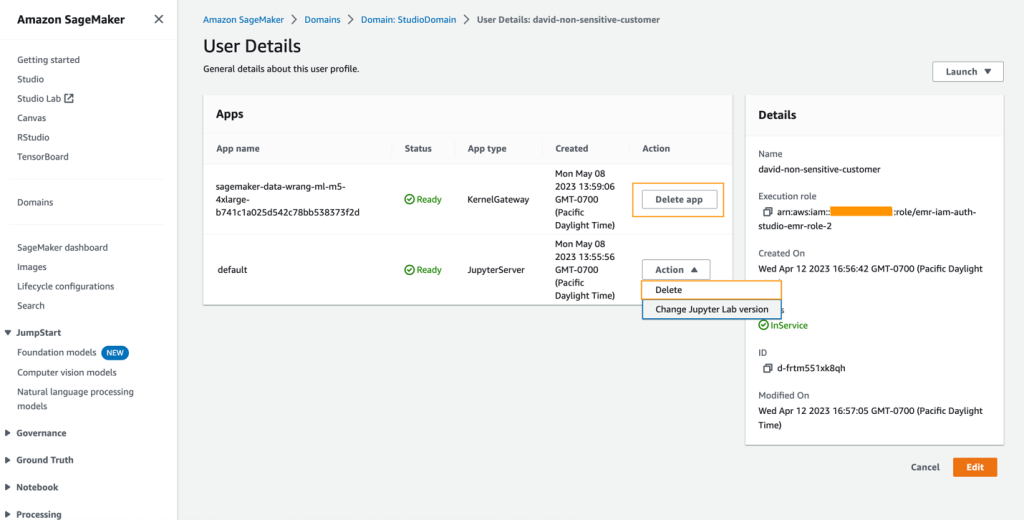
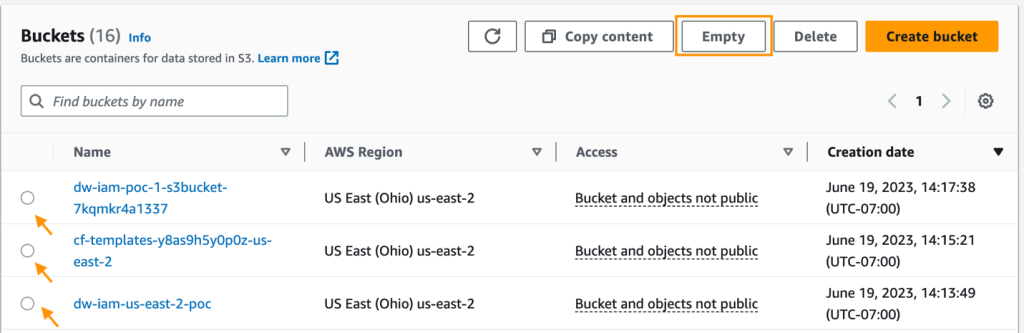
- On the Amazon S3 console, empty any S3 buckets that have been created from the CloudFormation template when provisioning clusters.
The buckets ought to have the identical prefix because the CloudFormation launch stack title and cf-templates-.
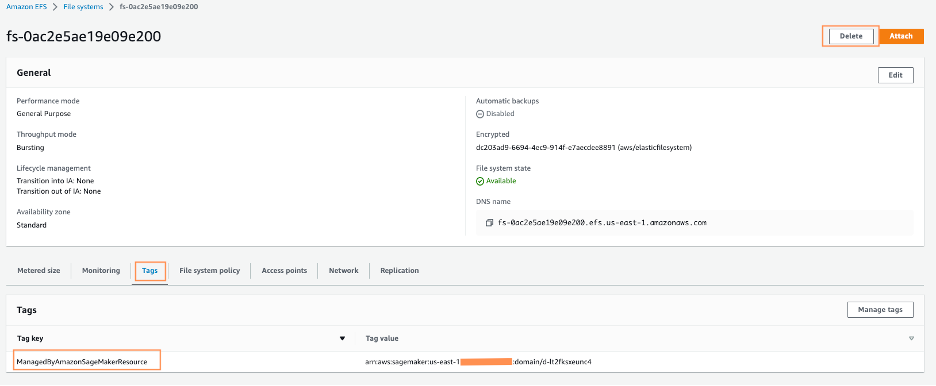
- On the Amazon EFS console, delete the SageMaker Studio file system.
You may verify that you’ve got the proper file system by selecting the file system ID and confirming the tag ManagedByAmazonSageMakerResource on the Tags tab.
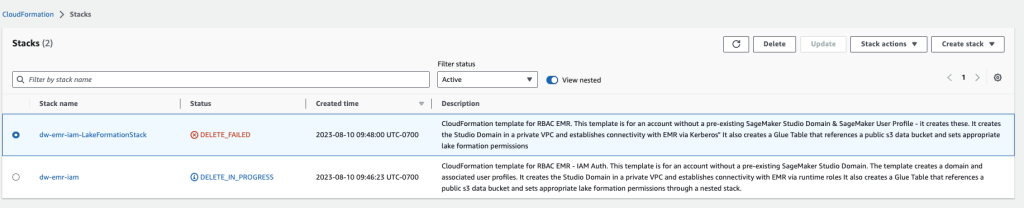
- On the AWS CloudFormation console, choose the stack you created and select Delete.

You’ll obtain an error message, which is predicted. We’ll come again to this and clear it up within the subsequent steps.
- Determine the VPC that was created by the CloudFormation stack, named dw-emr-, and comply with the prompts to delete the VPC.
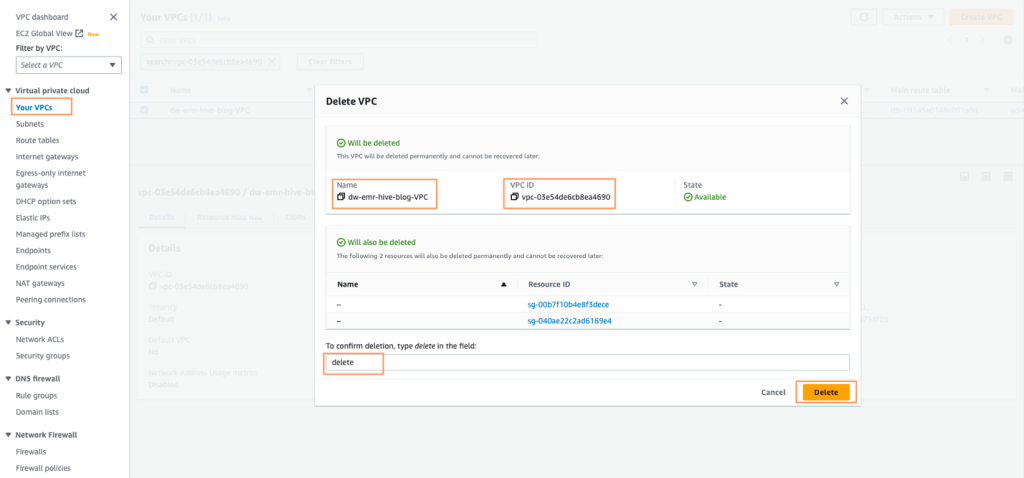
- Return to the AWS CloudFormation console and retry the stack deletion for dw-emr-.
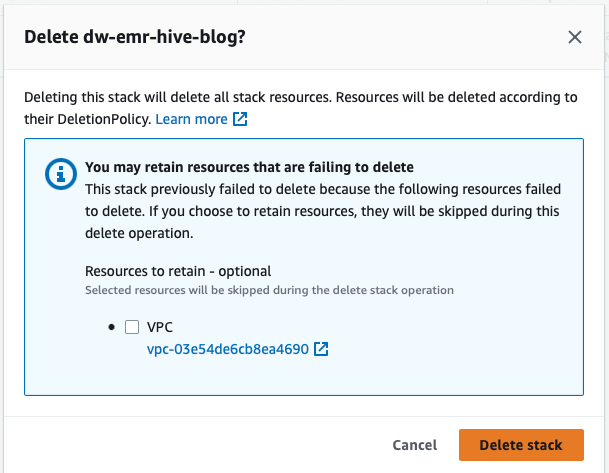
All of the sources provisioned by the CloudFormation template described on this publish have now been eliminated out of your account.
Conclusion
On this publish, we went over the best way to apply fine-grained entry management with Lake Formation and entry the info utilizing Amazon EMR as an information supply in SageMaker Information Wrangler, the best way to rework and analyze a dataset, and the best way to export the outcomes to a knowledge stream to be used in a Jupyter pocket book. After visualizing our dataset utilizing SageMaker Information Wrangler’s built-in analytical options, we additional enhanced our information stream. The truth that we created an information preparation pipeline with out writing a single line of code is critical.
To get began with SageMaker Information Wrangler, check with Prepare ML Data with Amazon SageMaker Data Wrangler.
In regards to the Authors
 Ajjay Govindaram is a Senior Options Architect at AWS. He works with strategic clients who’re utilizing AI/ML to resolve complicated enterprise issues. His expertise lies in offering technical path in addition to design help for modest to large-scale AI/ML utility deployments. His information ranges from utility structure to large information, analytics, and machine studying. He enjoys listening to music whereas resting, experiencing the outside, and spending time together with his family members.
Ajjay Govindaram is a Senior Options Architect at AWS. He works with strategic clients who’re utilizing AI/ML to resolve complicated enterprise issues. His expertise lies in offering technical path in addition to design help for modest to large-scale AI/ML utility deployments. His information ranges from utility structure to large information, analytics, and machine studying. He enjoys listening to music whereas resting, experiencing the outside, and spending time together with his family members.
 Isha Dua is a Senior Options Architect based mostly within the San Francisco Bay Space. She helps AWS enterprise clients develop by understanding their targets and challenges, and guides them on how they’ll architect their purposes in a cloud-native method whereas making certain resilience and scalability. She’s keen about machine studying applied sciences and environmental sustainability.
Isha Dua is a Senior Options Architect based mostly within the San Francisco Bay Space. She helps AWS enterprise clients develop by understanding their targets and challenges, and guides them on how they’ll architect their purposes in a cloud-native method whereas making certain resilience and scalability. She’s keen about machine studying applied sciences and environmental sustainability.
 Parth Patel is a Senior Options Architect at AWS within the San Francisco Bay Space. Parth guides enterprise clients to speed up their journey to the cloud and assist them undertake and develop on the AWS Cloud efficiently. He’s keen about machine studying applied sciences, environmental sustainability, and utility modernization.
Parth Patel is a Senior Options Architect at AWS within the San Francisco Bay Space. Parth guides enterprise clients to speed up their journey to the cloud and assist them undertake and develop on the AWS Cloud efficiently. He’s keen about machine studying applied sciences, environmental sustainability, and utility modernization.



