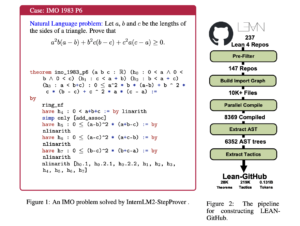
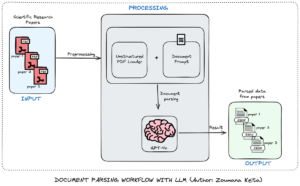
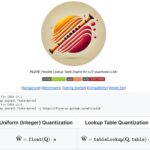
 FLUTE: A CUDA Kernel Designed for Fused Quantized Matrix Multiplications to Speed up LLM Inference
FLUTE: A CUDA Kernel Designed for Fused Quantized Matrix Multiplications to Speed up LLM Inference  Radical Simplicity in Knowledge Engineering | by Cai Parry-Jones | Jul, 2024
Radical Simplicity in Knowledge Engineering | by Cai Parry-Jones | Jul, 2024  Discover solutions precisely and shortly utilizing Amazon Q Enterprise with the SharePoint On-line connector
Discover solutions precisely and shortly utilizing Amazon Q Enterprise with the SharePoint On-line connector  Amazon SageMaker inference launches sooner auto scaling for generative AI fashions
Amazon SageMaker inference launches sooner auto scaling for generative AI fashions 





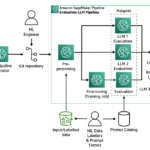






FLUTE: A CUDA Kernel Designed for Fused Quantized Matrix Multiplications to Speed up LLM Inference
Massive Language Fashions (LLMs) face deployment challenges because of latency points brought on by reminiscence bandwidth constraints. Researchers use weight-only...