Microsoft Analysis Suggest LLMA: An LLM Accelerator To Losslessly Pace Up Massive Language Mannequin (LLM) Inference With References
Excessive deployment prices are a rising fear as large basis fashions (e.g., GPT-3.5/GPT-4) (OpenAI, 2023) are deployed in lots of sensible contexts. Though quantization, pruning, compression, and distillation are helpful common strategies for reducing LLMs’ serving prices, the inference effectivity bottleneck of transformer-based generative fashions (e.g., GPT) is primarily related to autoregressive decoding. It is because, at check time, output tokens have to be decoded (sequentially) one after the other. This presents severe difficulties for deploying LLMs at scale.
Based on research, an LLM’s context is commonly the supply of its output tokens in real-world purposes. An LLM’s context sometimes consists of paperwork related to a question and retrieved from an exterior corpus as a reference. The LLM’s output sometimes consists of a number of textual content spans found within the reference.
In mild of this realization, a bunch of Microsoft researchers suggests LLMA. This inference-with-reference decoding approach can pace up LLM inference by capitalizing on the overlap between an LLM’s output and a reference in lots of real-world settings. This work geared toward dashing up inference in LLM by enhancing the efficiency of autoregressive decoding.
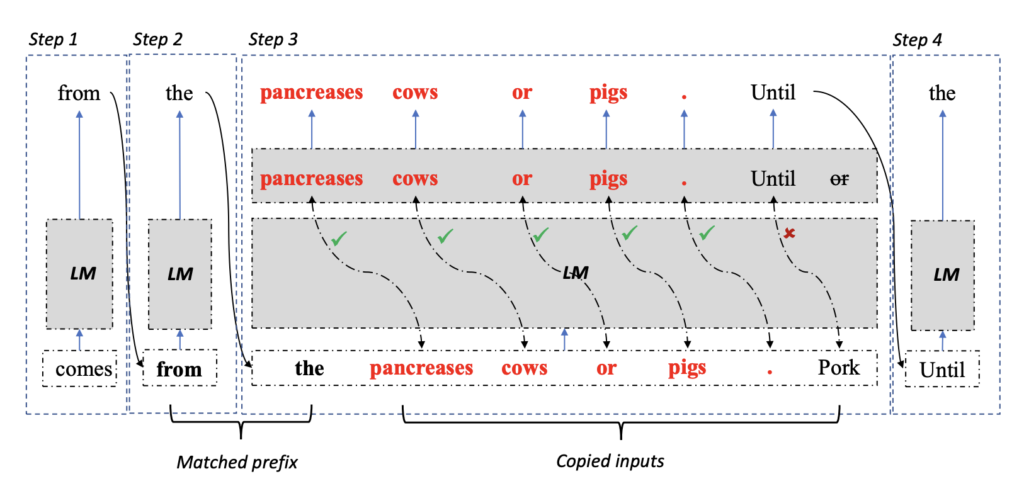
Deciding on a textual content span from the reference, copying its tokens to the LLM decoder, after which performing an environment friendly parallel test primarily based on the output token chances is how LLMA works. Doing so ensures that the technology outcomes are indistinguishable from the vanilla grasping decoding technique outcomes whereas dashing up decoding by offering improved parallelism on vector accelerators like GPUs.
In distinction to earlier environment friendly decoding algorithms like Speculative Decoding and Speculative Sampling, LLMA doesn’t require an extra mannequin to generate a draft for checking.
Experiments on varied mannequin sizes and sensible utility situations, together with retrieval augmentation and cache-assisted creation, reveal that the proposed LLMA strategy achieves over a two-factor speedup in comparison with grasping decoding.
Try the Paper and Github. Don’t neglect to affix our 19k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra. When you’ve got any questions concerning the above article or if we missed something, be happy to e-mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Tanushree Shenwai is a consulting intern at MarktechPost. She is at present pursuing her B.Tech from the Indian Institute of Know-how(IIT), Bhubaneswar. She is a Information Science fanatic and has a eager curiosity within the scope of utility of synthetic intelligence in varied fields. She is enthusiastic about exploring the brand new developments in applied sciences and their real-life utility.





