Amazon Comprehend doc classifier provides structure assist for increased accuracy

The flexibility to successfully deal with and course of monumental quantities of paperwork has turn into important for enterprises within the fashionable world. Because of the steady inflow of data that every one enterprises cope with, manually classifying paperwork is not a viable possibility. Doc classification fashions can automate the process and assist organizations save time and sources. Conventional categorization strategies, similar to guide processing and keyword-based searches, turn into much less environment friendly and extra time-consuming as the quantity of paperwork will increase. This inefficiency causes decrease productiveness and better working bills. Moreover, it may stop essential data from being accessible when wanted, which may result in a poor buyer expertise and affect decision-making. At AWS re:Invent 2022, Amazon Comprehend, a pure language processing (NLP) service that makes use of machine studying (ML) to find insights from textual content, launched assist for native doc varieties. This new function gave you the flexibility to categorise paperwork in native codecs (PDF, TIFF, JPG, PNG, DOCX) utilizing Amazon Comprehend.
Immediately, we’re excited to announce that Amazon Comprehend now helps customized classification mannequin coaching with paperwork like PDF, Phrase, and picture codecs. Now you can prepare bespoke doc classification fashions on native paperwork that assist structure along with textual content, rising the accuracy of the outcomes.
On this submit, we offer an outline of how one can get began with coaching an Amazon Comprehend customized doc classification mannequin.
Overview
The capability to know the relative placements of objects inside an outlined house is known as structure consciousness. On this case, it aids the mannequin in understanding how headers, subheadings, tables, and graphics relate to at least one one other inside a doc. The mannequin can extra successfully categorize a doc primarily based on its content material when it’s conscious of the construction and structure of the textual content.
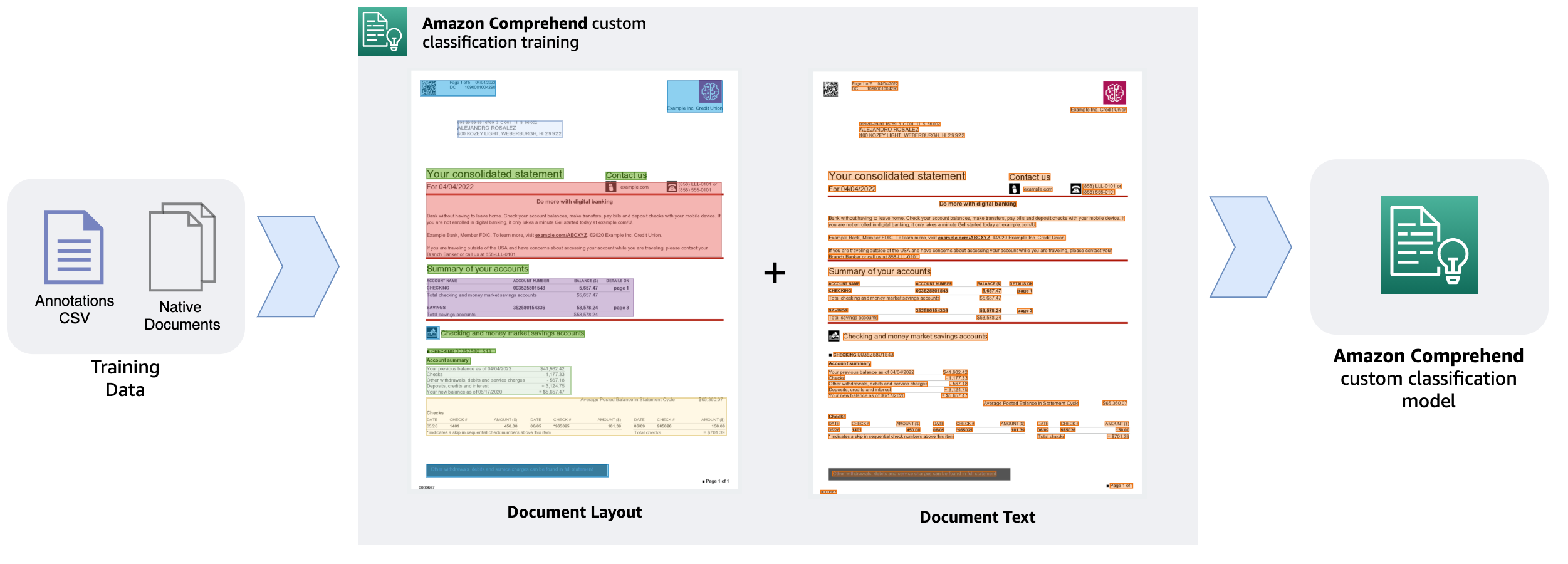
On this submit, we stroll by means of the information preparation steps concerned, exhibit the mannequin coaching course of, and focus on the advantages of utilizing the brand new customized doc classification mannequin in Amazon Comprehend. As a greatest observe, you need to take into account the next factors earlier than you start coaching the customized doc classification mannequin.
Consider your doc classification wants
Determine the assorted forms of paperwork they you could must classify, together with the completely different courses or classes to assist your use case. Decide the acceptable classification construction or taxonomy after evaluating the quantity and forms of paperwork that have to be categorized. Doc varieties might range from PDF, Phrase, photos, and so forth. Guarantee you will have licensed entry to a various set of labeled paperwork both by way of a doc administration system or different storage mechanisms.
Put together your information
Be sure that the doc information you plan to make use of for mannequin coaching aren’t encrypted or locked—for instance, make it possible for your PDF information aren’t encrypted and locked with a password. You should decrypt such information earlier than you should use them for coaching functions. Label a pattern of your paperwork with the suitable classes or labels (courses). Decide whether or not single-label classification (multi-class mode) or multi-label classification is suitable on your use case. Multi-class mode associates solely a single class with every doc, whereas multi-label mode associates a number of class with a doc.
Think about mannequin analysis
Use the labeled dataset to coach the mannequin so it may be taught to categorise new paperwork precisely and consider how the newly educated mannequin model performs by understanding the mannequin metrics. To grasp the metrics offered by Amazon Comprehend post-model coaching, discuss with Custom classifier metrics. After the coaching course of is full, you possibly can start classifying paperwork asynchronously or in actual time. We stroll by means of easy methods to prepare a customized classification mannequin within the following sections.
Put together the coaching information
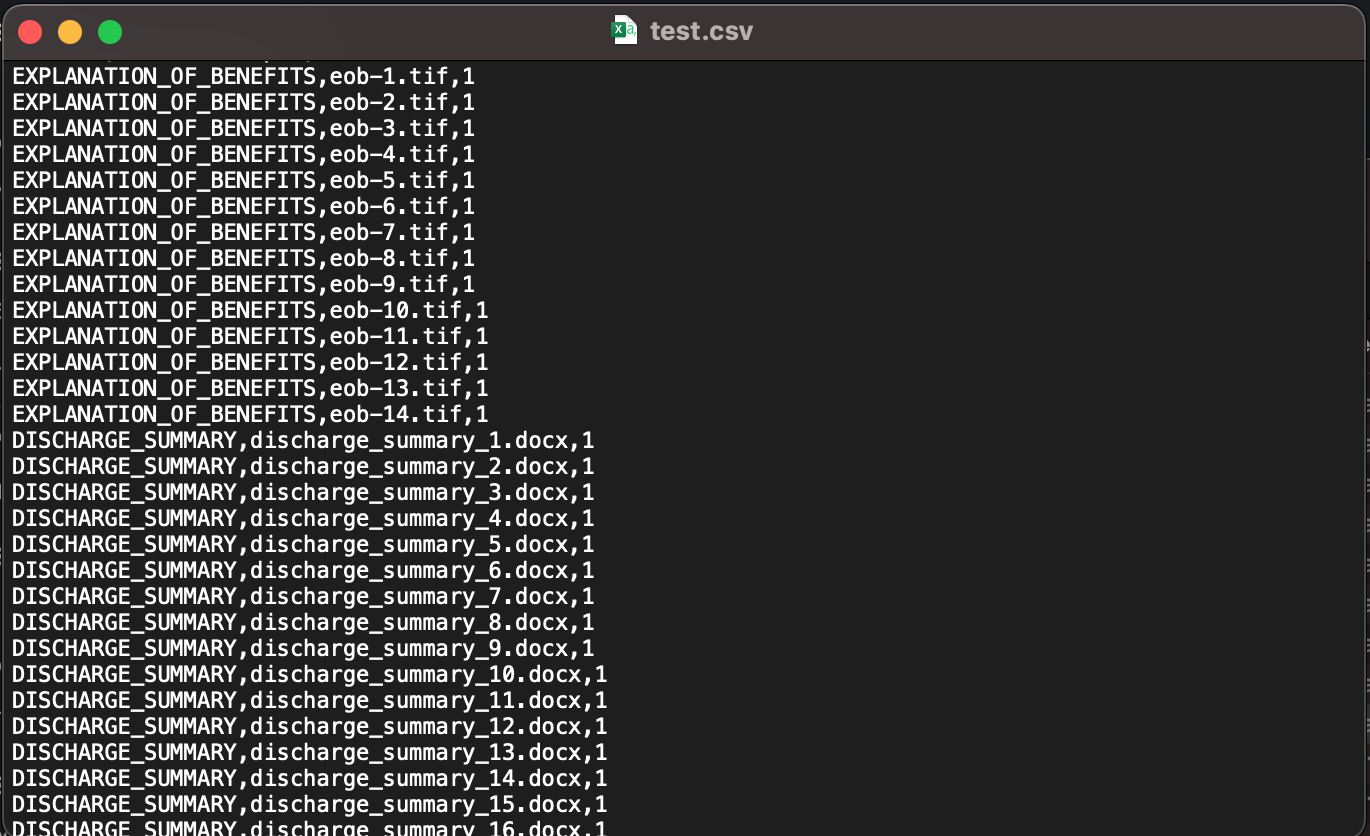
Earlier than we prepare our customized classification mannequin, we have to put together the coaching information. Coaching information is comprised of a set of labeled paperwork, which will be pre-identified paperwork from a doc repository that you have already got entry to. For our instance, we educated a customized classification mannequin with a couple of completely different doc varieties which might be usually present in a medical health insurance declare adjudication course of: affected person discharge abstract, invoices, receipts, and so forth. We additionally want to organize an annotations file in CSV format. Following is an instance of an annotations file CSV information required for the coaching:
The annotations CSV file should comprise three columns. The primary column accommodates the specified class (label) for the doc, the second column is the doc identify (file identify), and the final column is the web page variety of the doc that you just need to embrace within the coaching dataset. As a result of the coaching course of helps native multi-page PDF and DOCX information, it’s essential to specify the web page quantity in case the doc is a multi-page doc. If you wish to embrace all pages of a multi-page doc within the coaching dataset, it’s essential to specify every web page as a separate line within the CSV annotations file. For instance, within the previous annotations file, invoice-1.pdf is a two-page doc, and we need to embrace each pages within the classification dataset. As a result of information like PDF, PNG, and TIFF are picture codecs, the web page quantity (third column) worth should at all times be 1. In case your dataset accommodates multi-frame (multi-page) TIF information, it’s essential to break up them into separate TIF information to be able to use them within the coaching course of.
We ready an annotations file referred to as take a look at.csv with the suitable information to coach a customized classification mannequin. For every pattern doc, the CSV file accommodates the category that doc belongs to, the situation of the doc in Amazon Simple Storage Service (Amazon S3), similar to path/to/prefix/doc.pdf, and the web page quantity (if relevant). As a result of most of our paperwork are both single-page DOCX, PDF information, or TIF, JPG, or PNG information, the web page quantity assigned is 1. As a result of our annotations CSV and pattern paperwork are all below the identical Amazon S3 prefix, we don’t must explicitly specify the prefix within the second column. We additionally put together no less than 10 doc samples or extra for every class, and we used a mixture of JPG, PNG, DOCX, PDF, and TIF information for coaching the mannequin. Observe that it’s often really helpful to have a various set of pattern paperwork for mannequin coaching to keep away from overfitting of the mannequin, which impacts its means to acknowledge new paperwork. It’s additionally really helpful that the variety of samples per class is balanced, though it’s not required to have an very same variety of samples per class. Subsequent, we add the take a look at.csv annotations file and all of the paperwork into Amazon S3. The next picture exhibits a part of our annotations CSV file.
Practice a customized classification mannequin
Now that we now have the annotations file and all our pattern paperwork prepared, we arrange a customized classification mannequin and prepare it. Earlier than you start establishing customized classification mannequin coaching, make it possible for the annotations CSV and pattern paperwork exist in an Amazon S3 location.
- On the Amazon Comprehend console, select Customized classification within the navigation pane.
- Select Create new mannequin.

- For Mannequin identify, enter a novel identify.
- For Model identify, enter a novel model identify.

- For Coaching mannequin sort, choose Native paperwork.
This tells Amazon Comprehend that you just intend to make use of native doc varieties to coach the mannequin as an alternative of serialized textual content.
- For Classifier mode, choose Utilizing single-label mode.
This mode tells the classifier that we intend to categorise paperwork right into a single class. If it is advisable prepare a mannequin with multi-label mode, that means a doc might belong to at least one or multiple class, it’s essential to arrange the annotations file appropriately by specifying the courses of the doc separated by a particular character within the annotations CSV file. In that case, you would choose the Utilizing multi-label mode possibility.
- For Annotation location on S3, enter the trail of the annotations CSV file.
- For Coaching information location on S3, enter the Amazon S3 location the place your paperwork reside.
- Go away all different choices as default on this part.

- Within the Output information part, specify an Amazon S3 location on your output.
That is non-obligatory, nevertheless it’s a superb observe to offer an output location as a result of Amazon Comprehend will generate the post-model coaching analysis metrics on this location. This information is helpful to guage mannequin efficiency, iterate, and enhance the accuracy of your mannequin.
- Within the IAM function part, select an acceptable AWS Identity and Access Management (IAM) function that enables Amazon Comprehend to entry the Amazon S3 location and write and skim from it.
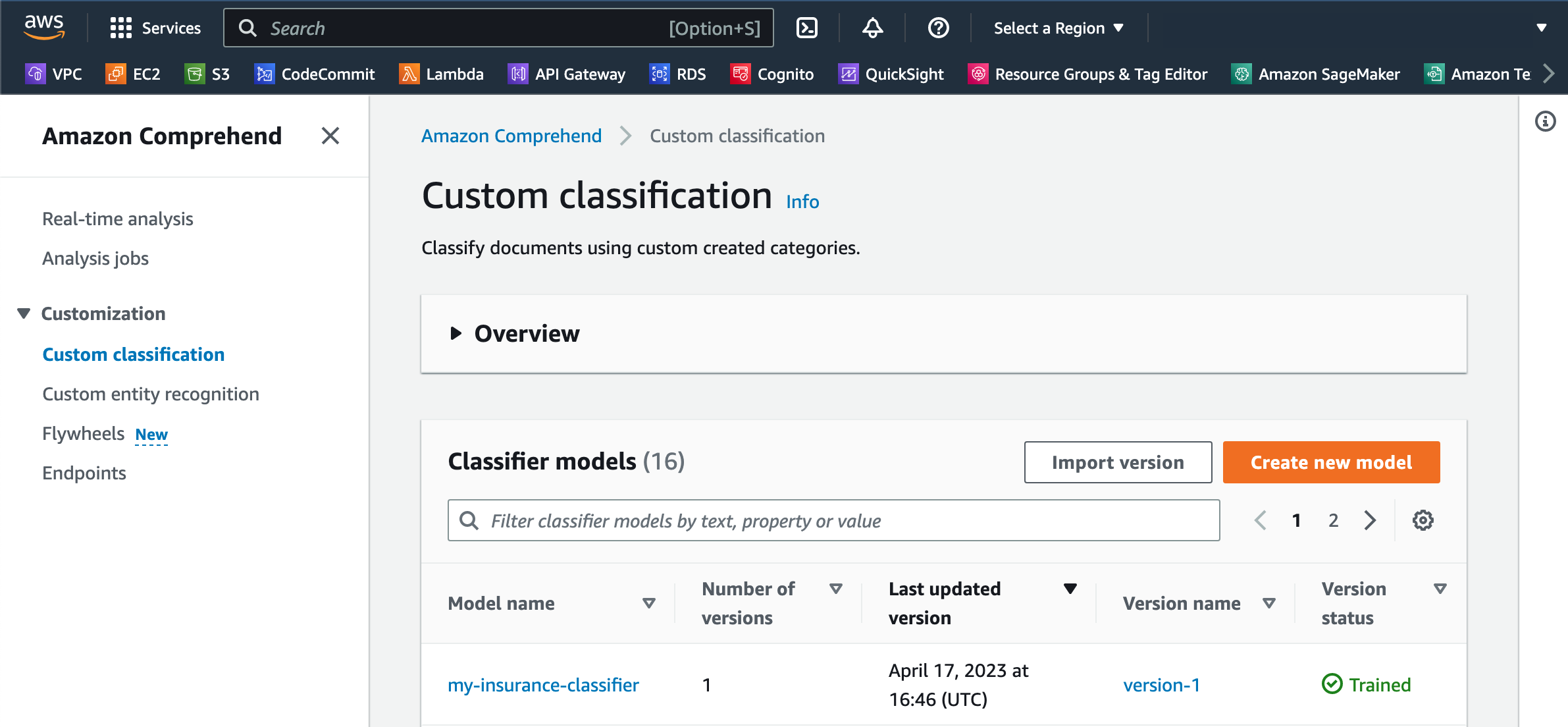
- Select Create to provoke the mannequin coaching.

The mannequin might take a number of minutes to coach, relying on the variety of courses and the dataset dimension. You possibly can overview the coaching standing on the Customized classification web page. The coaching course of will show a Submitted standing proper after the coaching course of begins and can change to Coaching standing when the coaching course of begins. After your mannequin is educated, the Model standing will change to Skilled. If Amazon Comprehend finds inconsistencies in your coaching information, the standing will present In error together with an alert that exhibits the suitable error message in an effort to take corrective motion and restart the coaching course of with the corrected information.
On this submit, we demonstrated the steps to coach a customized classifier mannequin utilizing the Amazon Comprehend console. You can even use the AWS SDK in any language (for instance, Boto3 for Python) or the AWS Command Line Interface (AWS CLI) to provoke a customized classification mannequin coaching. With both the SDK or AWS CLI, you should use the CreateDocumentClassifier API to provoke the mannequin coaching, and subsequently use the DescribeDocumentClassifier API to test the standing of the mannequin.
After the mannequin is educated, you possibly can carry out both real-time analysis or asynchronous (batch) analysis jobs on new paperwork. To carry out real-time classification on paperwork, it’s essential to deploy an Amazon Comprehend real-time endpoint with the educated customized classification mannequin. Actual-time endpoints are greatest suited to use circumstances that require low-latency, real-time inference outcomes, whereas for classifying a big set of paperwork, an asynchronous evaluation job is extra acceptable. To be taught how one can carry out asynchronous inference on new paperwork utilizing a educated classification mannequin, discuss with Introducing one-step classification and entity recognition with Amazon Comprehend for intelligent document processing.
Advantages of the layout-aware customized classification mannequin
The brand new classifier mannequin provides a variety of enhancements. It’s not solely simpler to coach the brand new mannequin, however you can too prepare a brand new mannequin with only a few samples for every class. Moreover, you not need to extract serialized plain textual content out of scanned or digital paperwork similar to photos or PDFs to organize the coaching dataset. The next are some extra noteworthy enhancements you can count on from the brand new classification mannequin:
- Improved accuracy – The mannequin now takes under consideration the structure and construction of paperwork, which results in a greater understanding of the construction and content material of the paperwork. This helps distinguish between paperwork with comparable textual content however completely different layouts or constructions, leading to elevated classification accuracy.
- Robustness – The mannequin now handles variations in doc construction and formatting. This makes it higher suited to classifying paperwork from completely different sources with various layouts or formatting types, which is a typical problem in real-world doc classification duties. It’s appropriate with a number of doc varieties natively, making it versatile and relevant to completely different industries and use circumstances.
- Decreased guide intervention – Larger accuracy results in much less guide intervention within the classification course of. This could save time and sources, and improve operational effectivity in your doc processing workload.
Conclusion
The brand new Amazon Comprehend doc classification mannequin, which includes structure consciousness, is a game-changer for companies coping with massive volumes of paperwork. By understanding the construction and structure of paperwork, this mannequin provides improved classification accuracy and effectivity. Implementing a strong and correct doc classification answer utilizing a layout-aware mannequin can assist your online business save time, scale back operational prices, and improve decision-making processes.
As a subsequent step, we encourage you to attempt the brand new Amazon Comprehend customized classification mannequin by way of the Amazon Comprehend console. We additionally advocate revisiting our customized classification mannequin enchancment bulletins from last year and go to the GitHub repository for code samples.
In regards to the authors
 Anjan Biswas is a Senior AI Providers Options Architect with a deal with AI/ML and Knowledge Analytics. Anjan is a part of the world-wide AI companies crew and works with prospects to assist them perceive and develop options to enterprise issues with AI and ML. Anjan has over 14 years of expertise working with world provide chain, manufacturing, and retail organizations, and is actively serving to prospects get began and scale on AWS AI companies.
Anjan Biswas is a Senior AI Providers Options Architect with a deal with AI/ML and Knowledge Analytics. Anjan is a part of the world-wide AI companies crew and works with prospects to assist them perceive and develop options to enterprise issues with AI and ML. Anjan has over 14 years of expertise working with world provide chain, manufacturing, and retail organizations, and is actively serving to prospects get began and scale on AWS AI companies.
 Godwin Sahayaraj Vincent is an Enterprise Options Architect at AWS who’s obsessed with Machine Studying and offering steerage to prospects to design, deploy and handle their AWS workloads and architectures. In his spare time, he likes to play cricket together with his buddies and tennis together with his three youngsters.
Godwin Sahayaraj Vincent is an Enterprise Options Architect at AWS who’s obsessed with Machine Studying and offering steerage to prospects to design, deploy and handle their AWS workloads and architectures. In his spare time, he likes to play cricket together with his buddies and tennis together with his three youngsters.
 Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service crew. He works with AWS prospects to assist them undertake machine studying on a big scale. Outdoors of labor, he enjoys studying and images.
Wrick Talukdar is a Senior Architect with the Amazon Comprehend Service crew. He works with AWS prospects to assist them undertake machine studying on a big scale. Outdoors of labor, he enjoys studying and images.





