
Dolly 2.0: ChatGPT Open Supply Various for Industrial Use
Picture from Creator | Bing Picture Creator Dolly 2.0 is an open-source, instruction-followed, massive language mannequin (LLM) that was...
Picture from Creator | Bing Picture Creator Dolly 2.0 is an open-source, instruction-followed, massive language mannequin (LLM) that was...
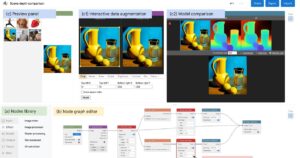
Posted by Ruofei Du, Interactive Notion & Graphics Lead, Google Augmented Actuality, and Na Li, Tech Lead Supervisor, Google CoreML...

Bard is still an early experiment, and should generally present inaccurate, deceptive or false info whereas presenting it confidently. Relating...

Batch inference is a standard sample the place prediction requests are batched collectively on enter, a job runs to course...

Photograph by Tima Miroshnichenko Information Science and Machine Studying are more and more gaining reputation in varied fields equivalent...
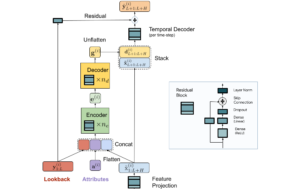
Posted by Rajat Sen and Abhimanyu Das, Analysis Scientists, Google Analysis Time-series forecasting is a crucial analysis space that's important...

With over 3 years of expertise in designing, constructing, and deploying computer vision (CV) models, I’ve realized individuals don’t focus...
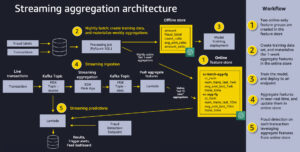
Companies are more and more utilizing machine studying (ML) to make near-real-time selections, akin to inserting an advert, assigning a...

Picture by Creator The world of expertise is advancing at an unprecedented tempo, and corporations are consistently striving to...

Giant language fashions (LLMs) with billions of parameters are at present on the forefront of pure language processing (NLP). These...

Picture by Creator Completely different Languages are used for communication functions however it's thought of one of the...

As an MLOps engineer in your crew, you might be typically tasked with enhancing the workflow of your information scientists...

Amazon SageMaker Studio will help you construct, prepare, debug, deploy, and monitor your fashions and handle your machine studying (ML)...

Picture by Editor Certainly one of our clients – Ubicquia – A Supplier of Clever IoT-based Good Metropolis Options,...

This can be a visitor weblog put up co-written with Hussain Jagirdar from Games24x7. Games24x7 is certainly one of India’s...




