Dataset Reset Coverage Optimization (DR-PO): A Machine Studying Algorithm that Exploits a Generative Mannequin’s Potential to Reset from Offline Information to Improve RLHF from Desire-based Suggestions

Reinforcement Studying (RL) repeatedly evolves as researchers discover strategies to refine algorithms that study from human suggestions. This area of studying algorithms offers with challenges in defining and optimizing reward features important for coaching fashions to carry out varied duties starting from gaming to language processing.
A prevalent situation on this space is the inefficient use of pre-collected datasets of human preferences, usually missed within the RL coaching processes. Historically, these fashions are skilled from scratch, ignoring current datasets’ wealthy, informative content material. This disconnect results in inefficiencies and a scarcity of utilization of worthwhile, pre-existing information. Latest developments have launched revolutionary strategies that successfully combine offline information into the RL coaching course of to handle this inefficiency.
Researchers from Cornell College, Princeton College, and Microsoft Analysis launched a brand new algorithm, the Dataset Reset Policy Optimization (DR-PO) technique. This technique ingeniously incorporates preexisting information into the mannequin coaching rule and is distinguished by its means to reset on to particular states from an offline dataset throughout coverage optimization. It contrasts with conventional strategies that start each coaching episode from a generic preliminary state.
The DR-PO technique enhances offline information by permitting the mannequin to ‘reset’ to particular, helpful states already recognized as helpful within the offline information. This course of displays real-world situations the place situations usually are not all the time initiated from scratch however are sometimes influenced by prior occasions or states. By leveraging this information, DR-PO improves the effectivity of the training course of and broadens the applying scope of the skilled fashions.
DR-PO employs a hybrid technique that blends on-line and offline information streams. This technique capitalizes on the informative nature of the offline dataset by resetting the coverage optimizer to states beforehand recognized as worthwhile by human labelers. The mixing of this technique has demonstrated promising enhancements over conventional methods, which regularly disregard the potential insights obtainable in pre-collected information.
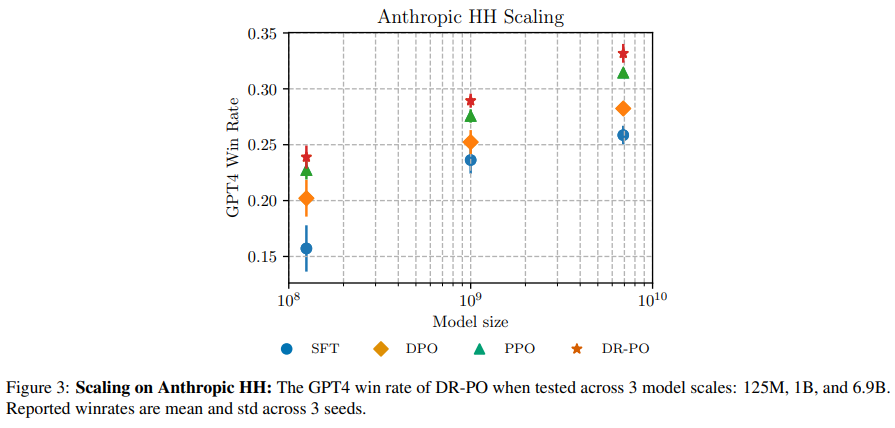
DR-PO has proven excellent leads to research involving duties like TL;DR summarization and the Anthropic Useful Dangerous dataset. DR-PO has outperformed established strategies like Proximal Coverage Optimization (PPO) and Route Desire Optimization (DPO). Within the TL;DR summarization process, DR-PO achieved the next GPT4 win price, enhancing the standard of generated summaries. In head-to-head comparisons, DR-PO’s method to integrating resets and offline information has persistently demonstrated superior efficiency metrics.

In conclusion, DR-PO presents a major breakthrough in RL. DR-PO overcomes conventional inefficiencies by integrating pre-collected, human-preferred information into the RL coaching course of. This technique enhances studying effectivity by using resets to particular states recognized in offline datasets. Empirical proof demonstrates that DR-PO surpasses standard approaches corresponding to Proximal Coverage Optimization and Route Desire Optimization in real-world functions like TL;DR summarization, attaining superior GPT4 win charges. This revolutionary method streamlines the coaching course of and maximizes the utility of current human suggestions, setting a brand new benchmark in adapting offline information for mannequin optimization.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our newsletter..
Don’t Overlook to hitch our 40k+ ML SubReddit
Wish to get in entrance of 1.5 Million AI Viewers? Work with us here
Hey, My title is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Categorical. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m keen about know-how and need to create new merchandise that make a distinction.





