Alternating updates for environment friendly transformers – Google Analysis Weblog

Up to date deep studying fashions have been remarkably profitable in lots of domains, starting from pure language to laptop imaginative and prescient. Transformer neural networks (transformers) are a preferred deep studying structure that right this moment comprise the inspiration for many duties in pure language processing and in addition are beginning to prolong to functions in different domains, akin to computer vision, robotics, and autonomous driving. Furthermore, they kind the spine of all the present state-of-the-art language models.
Rising scale in Transformer networks has led to improved efficiency and the emergence of behavior not current in smaller networks. Nevertheless, this enhance in scale usually comes with prohibitive will increase in compute price and inference latency. A pure query is whether or not we will reap the advantages of bigger fashions with out incurring the computational burden.
In “Alternating Updates for Efficient Transformers”, accepted as a Highlight at NeurIPS 2023, we introduce AltUp, a way to make the most of elevated token illustration with out growing the computation price. AltUp is straightforward to implement, extensively relevant to any transformer structure, and requires minimal hyperparameter tuning. As an example, utilizing a variant of AltUp on a 770M parameter T5-Giant mannequin, the addition of ~100 parameters yields a mannequin with a considerably higher high quality.
Background
To know how we will obtain this, we dig into how transformers work. First, they partition the enter right into a sequence of tokens. Every token is then mapped to an embedding vector (through the technique of an embedding desk) known as the token embedding. We name the dimension of this vector the token illustration dimension. The Transformer then operates on this sequence of token embeddings by making use of a collection of computation modules (known as layers) utilizing its community parameters. The variety of parameters in every transformer layer is a operate of the layer’s width, which is set by the token illustration dimension.
To realize advantages of scale with out incurring the compute burden, prior works akin to sparse mixture-of-experts (Sparse MoE) fashions (e.g., Switch Transformer, Expert Choice, V-MoE) have predominantly centered on effectively scaling up the community parameters (within the self-attention and feedforward layers) by conditionally activating a subset primarily based on the enter. This permits us to scale up community dimension with out considerably growing compute per enter. Nevertheless, there’s a analysis hole on scaling up the token illustration dimension itself by conditionally activating components of the token illustration vector.
Latest works (for instance, scaling laws and infinite-width networks) have empirically and theoretically established {that a} wider token illustration helps in studying extra sophisticated features. This phenomenon can also be evident in fashionable architectures of accelerating functionality. As an example, the illustration dimension grows from 512 (small) to 768 (base) and 1024 (similar to fashions with 770M, 3B, and 11B parameters respectively) in T5 models, and from 4096 (8B) to 8192 (64B) and 18432 (540B) in PaLM models. A widened illustration dimension additionally considerably improves efficiency for twin encoder retrieval fashions. Nevertheless, naïvely widening the illustration vector requires one to enhance the mannequin dimension accordingly, which quadratically1 will increase the quantity of computation within the feedforward computation.
Technique
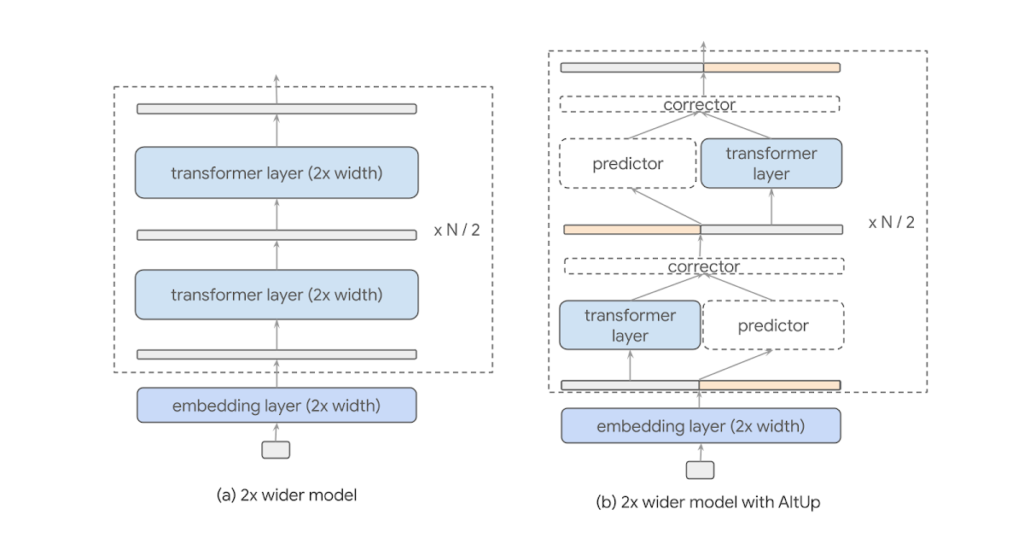
AltUp works by partitioning a widened illustration vector into equal sized blocks, processing solely a single block at every layer, and utilizing an environment friendly prediction-correction mechanism to deduce the outputs of the opposite blocks (proven under on the precise). This permits AltUp to concurrently preserve the mannequin dimension, therefore the computation price, roughly fixed and make the most of utilizing an elevated token dimension. The elevated token dimension permits the mannequin to pack extra data into every token’s embedding. By maintaining the width of every transformer layer fixed, AltUp avoids incurring the quadratic enhance in computation price that will in any other case be current with a naïve growth of the illustration.
 |
| An illustration of widening the token illustration with out (left) and with AltUp (proper). This widening causes a near-quadratic enhance in computation in a vanilla transformer as a result of elevated layer width. In distinction, Alternating Updates retains the layer width fixed and effectively computes the output by working on a sub-block of the illustration at every layer. |
Extra particularly, the enter to every layer is 2 or extra blocks, certainly one of which is handed into the 1x width transformer layer (see determine under). We discuss with this block because the “activated” block. This computation ends in the precise output for the activated block. In parallel, we invoke a light-weight predictor that computes a weighted mixture of all of the enter blocks. The anticipated values, together with the computed worth of the activated block, are handed on to a light-weight corrector that updates the predictions primarily based on the noticed values. This correction mechanism permits the inactivated blocks to be up to date as a operate of the activated one. Each the prediction and correction steps solely contain a restricted variety of vector additions and multiplications and therefore are a lot sooner than an everyday transformer layer. We observe that this process may be generalized to an arbitrary variety of blocks.
 |
| The predictor and corrector computations: The predictor mixes sub-blocks with trainable scalar coefficients; the corrector returns a weighted common of the predictor output and the transformer output. The predictor and corrector carry out scalar-vector multiplications and incur negligible computation price in comparison with the transformer. The predictor outputs a linear mixing of blocks with scalar mixing coefficients pi, j , and the corrector combines predictor output and transformer output with weights gi. |
At the next stage, AltUp is just like sparse MoE in that it’s a technique so as to add capability to a mannequin within the type of conditionally accessed (exterior) parameters. In sparse MoE, the extra parameters take the type of feed ahead community (FFN) consultants and the conditionality is with respect to the enter. In AltUp, the exterior parameters come from the widened embedding desk and the conditionality takes the type of alternating block-wise activation of the illustration vector, as within the determine above. Therefore, AltUp has the identical underpinning as sparse MoE fashions.
A bonus of AltUp over sparse MoE is that it doesn’t necessitate sharding because the variety of extra parameters launched is an element2 of the embedding desk dimension, which generally makes up a small fraction of the general mannequin dimension. Furthermore, since AltUp focuses on conditionally activating components of a wider token illustration, it may be utilized synergistically with orthogonal methods like MoE to acquire complementary efficiency good points.
Analysis
AltUp was evaluated on T5 fashions on varied benchmark language duties. Fashions augmented with AltUp are uniformly sooner than the extrapolated dense fashions on the similar accuracy. For instance, we observe {that a} T5 Giant mannequin augmented with AltUp results in a 27%, 39%, 87%, and 29% speedup on GLUE, SuperGLUE, SQuAD, and Trivia-QA benchmarks, respectively.
 |
| Evaluations of AltUp on T5 fashions of varied sizes and fashionable benchmarks. AltUp persistently results in sizable speedups relative to baselines on the similar accuracy. Latency is measured on TPUv3 with 8 cores. Speedup is outlined because the change in latency divided by the AltUp latency (B = T5 Base, L = T5 Giant, XL = T5 XL fashions). |
AltUp’s relative efficiency improves as we apply it to bigger fashions — examine the relative speedup of T5 Base + AltUp to that of T5 Giant + AltUp. This demonstrates the scalability of AltUp and its improved efficiency on even bigger fashions. Total, AltUp persistently results in fashions with higher predictive efficiency than the corresponding baseline fashions with the identical velocity on all evaluated mannequin sizes and benchmarks.
Extensions: Recycled AltUp
The AltUp formulation provides an insignificant quantity of per-layer computation, nevertheless, it does require utilizing a wider embedding desk. In sure situations the place the vocabulary dimension (i.e., the variety of distinct tokens the tokenizer can produce) may be very massive, this will result in a non-trivial quantity of added computation for the preliminary embedding lookup and the ultimate linear + softmax operation. A really massive vocabulary can also result in an undesirable quantity of added embedding parameters. To handle this, Recycled-AltUp is an extension of AltUp that avoids these computational and parameter prices by maintaining the embedding desk’s width the identical.
 |
| Illustration of the Structure for Recycled-AltUp with Ok = 2. |
In Recycled-AltUp, as a substitute of widening the preliminary token embeddings, we replicate the embeddings Ok occasions to kind a wider token illustration. Therefore, Recycled-AltUp provides nearly no extra parameters relative to the baseline transformer, whereas benefiting from a wider token illustration.
 |
| Recycled-AltUp on T5-B/L/XL in comparison with baselines. Recycled-AltUp results in strict enhancements in pre-training efficiency with out incurring any perceptible slowdown. |
We additionally consider the light-weight extension of AltUp, Recycled-AltUp, with Ok = 2 on T5 base, massive, and XL fashions and examine its pre-trained accuracy and velocity to these of baselines. Since Recycled-AltUp doesn’t require an growth within the embedding desk dimension, the fashions augmented with it have nearly the identical variety of trainable parameters because the baseline fashions. We once more observe constant enhancements in comparison with the dense baselines.
Why does AltUp work?
AltUp will increase a mannequin’s capability by including and effectively leveraging auxiliary parameters to the embedding desk, and sustaining the upper dimensional illustration throughout the layers. We imagine {that a} key ingredient on this computation lies in AltUp’s prediction mechanism that performs an ensemble of the totally different blocks. This weighted mixture permits steady message passing to all the vector regardless of activating solely sub-blocks of it in every layer. Recycled-AltUp, however, doesn’t add any extra parameters to the token embeddings. Nevertheless, it nonetheless confers the good thing about simulating computation in the next dimensional illustration house since the next dimensional illustration vector is maintained when transferring from one transformer layer to a different. We conjecture that this aids the coaching by augmenting the circulate of data by the community. An fascinating analysis path is to discover whether or not the advantages of Recycled-AltUp may be defined totally by extra favorable coaching dynamics.
Acknowledgements
We thank our collaborators Cenk Baykal, Dylan Cutler, and Rina Panigrahy at Google Analysis, and Nikhil Ghosh at College of California, Berkeley (work carried out throughout analysis internship at Google).
1It’s because the feedforward layers of a Transformer are sometimes scaled quadratically with the mannequin dimension. ↩
2This issue relies on the user-specified growth issue, however is often 1, i.e., we double the embedding desk dimension. ↩





