Customise Amazon Textract with business-specific paperwork utilizing Customized Queries

Amazon Textract is a machine studying (ML) service that robotically extracts textual content, handwriting, and knowledge from scanned paperwork. Queries is a function that lets you extract particular items of knowledge from various, complicated paperwork utilizing pure language. Custom Queries gives a method so that you can customise the Queries function on your business-specific, non-standard paperwork reminiscent of auto lending contracts, checks, and pay statements, in a self-service method. By customizing the function to acknowledge the distinctive phrases, buildings, and key info particular to those doc sorts, you possibly can meet your downstream processing wants with higher precision and minimal human intervention. Customized Queries is simple to combine in your present Textract pipeline and also you proceed to profit from the absolutely managed clever doc processing options of Amazon Textract with out having to spend money on ML experience or infrastructure administration.
On this publish, we present how Customized Queries can precisely extract knowledge from checks which are complicated, non-standard paperwork. As well as, we talk about the advantages of Customized Queries and share finest practices for successfully utilizing this function.
Answer overview
When beginning with a brand new use case, you possibly can consider how Textract Queries performs in your paperwork by navigating to the Textract console and utilizing the Analyze Doc Demo or Bulk Doc Uploader. Seek advice from Best Practices for Queries to draft queries relevant to your use case. In the event you determine errors within the question responses because of the nature of your enterprise paperwork, you should use Customized Queries to enhance accuracy. Inside hours, you possibly can annotate your pattern paperwork utilizing the AWS Management Console and prepare an adapter. Adapters are elements that plug in to the Amazon Textract pre-trained deep studying mannequin, customizing its output based mostly in your annotated paperwork. You should utilize the adapter for inference by passing the adapter identifier as a further parameter to the Analyze Document Queries API request.
Let’s look at how Custom Queries can enhance extraction accuracy in a difficult real-world state of affairs reminiscent of extraction of information from checks. The first problem when processing checks arises from their excessive diploma of variation relying on the kind (e.g., private or cashier’s checks), monetary establishment and nation (e.g., MICR line format). . These variations can embrace the location of the payee’s title, the quantity in numbers and phrases, the date, and the signature. Recognizing and adapting to those variations is usually a complicated process throughout knowledge extraction. To enhance knowledge extraction, organizations usually make use of handbook verification and validation processes, which will increase the price and time of the extraction course of.
Customized Queries addresses these challenges by enabling you to customise the pre-trained Queries options on the totally different variations of checks. Customization of the pre-trained function helps you obtain a excessive knowledge extraction accuracy on the particular number of layouts that you just course of.
In our use case, a monetary establishment desires to extract the next fields from a verify: payee title, payer title, account quantity, routing quantity, cost quantity (in numbers), cost quantity (in phrases), verify quantity, date, and memo.
Let’s discover the method of producing an adapter (element that customizes the output) for checks processing. Adapters might be created through the console or programmatically through the API. This publish particulars the console expertise; nonetheless, in the event you’d wish to programmatically create the adapter, confer with the code samples within the custom-queries-checks-blog.ipynb Jupyter pocket book (Choice 2).
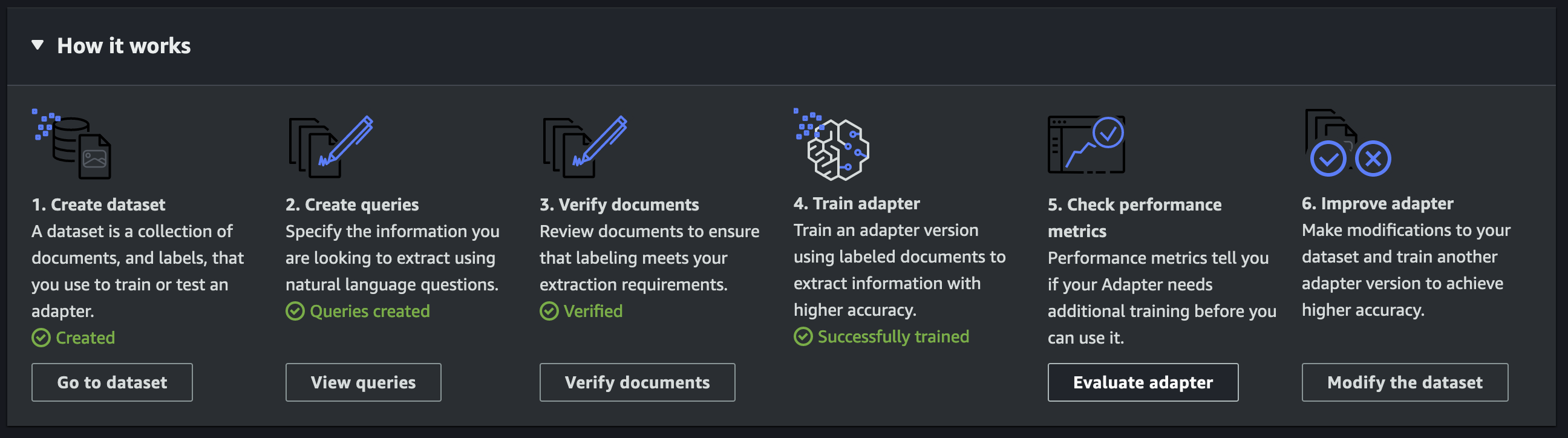
The adapter era course of includes 5 high-level steps: create an adapter, add pattern paperwork, annotate the paperwork, prepare the adapter, and consider efficiency metrics.
Create an adapter
On the Amazon Textract console, create a brand new adapter by offering a reputation, description, and non-compulsory tags that may provide help to determine the adapter. You will have the choice to allow computerized updates, which permits Amazon Textract to replace your adapter when the underlying Queries function is up to date with new capabilities.
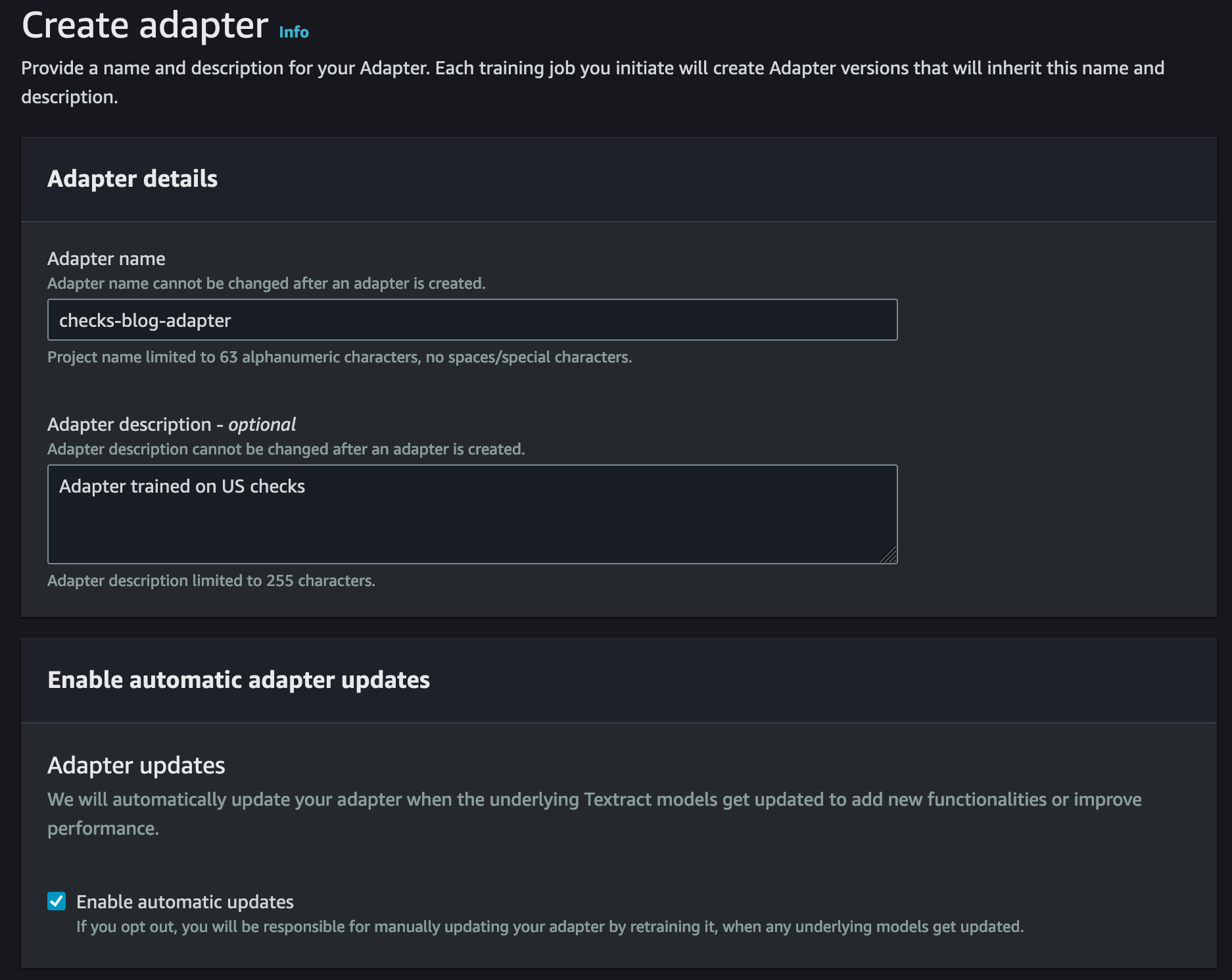
After the adapter is created, you will notice an adapter particulars web page with a listing of steps within the The way it works part. This part will activate your subsequent steps as you full them sequentially.

Add pattern paperwork
The preliminary part in adapter era includes the cautious number of an applicable set of pattern paperwork for annotation, coaching, and testing. We’ve an choice to auto cut up the paperwork into check and prepare datasets; nonetheless, for this course of, we manually cut up the dataset.
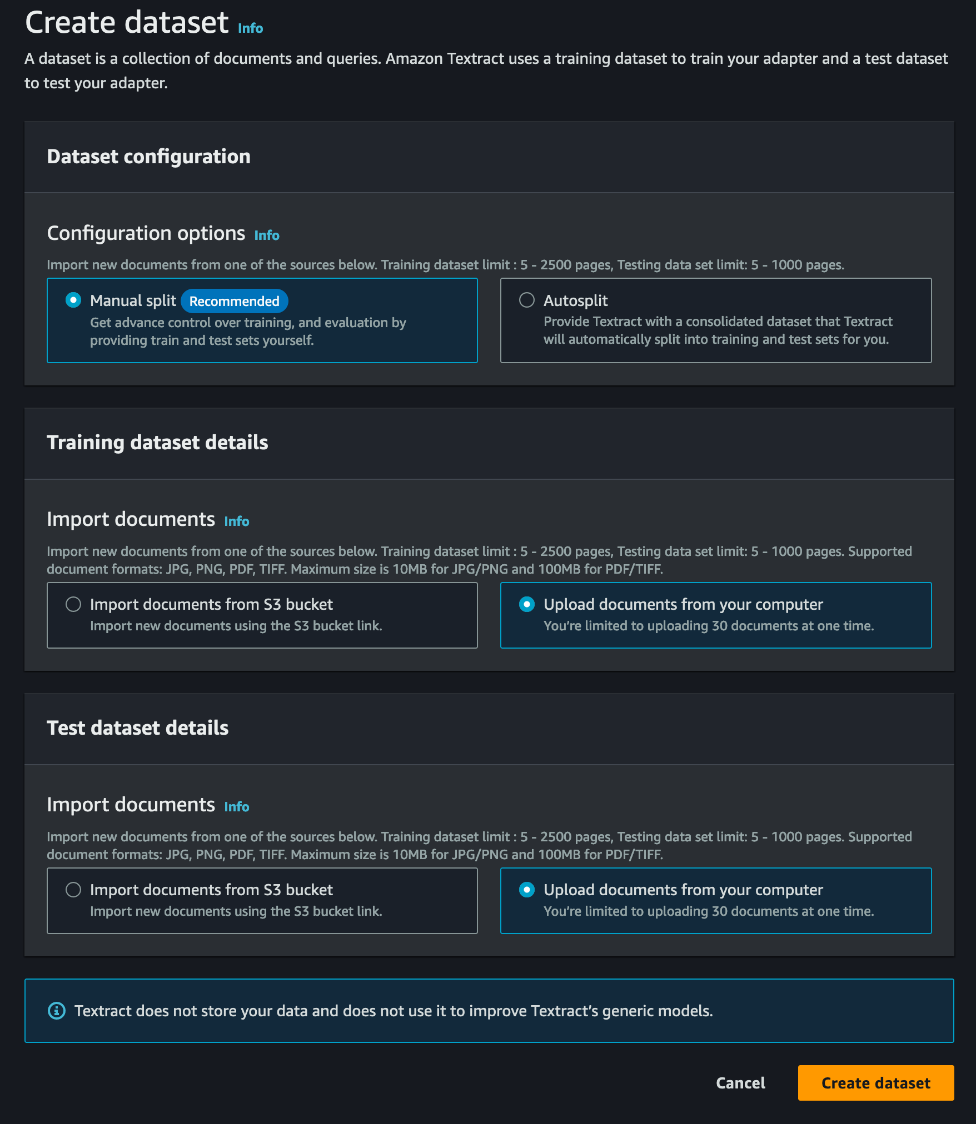
It’s necessary to notice which you could assemble an adapter with as few as 5 check and 5 coaching samples, but it surely’s important to make sure that this pattern set is various and consultant of the workload encountered in a manufacturing setting.
For this tutorial, we now have curated pattern verify datasets which you could download. Our dataset consists of variations reminiscent of private checks, cashier’s checks, stimulus checks and checks embedded inside pay stubs. We additionally included handwritten and printed checks; together with variations in fields such because the memo line.
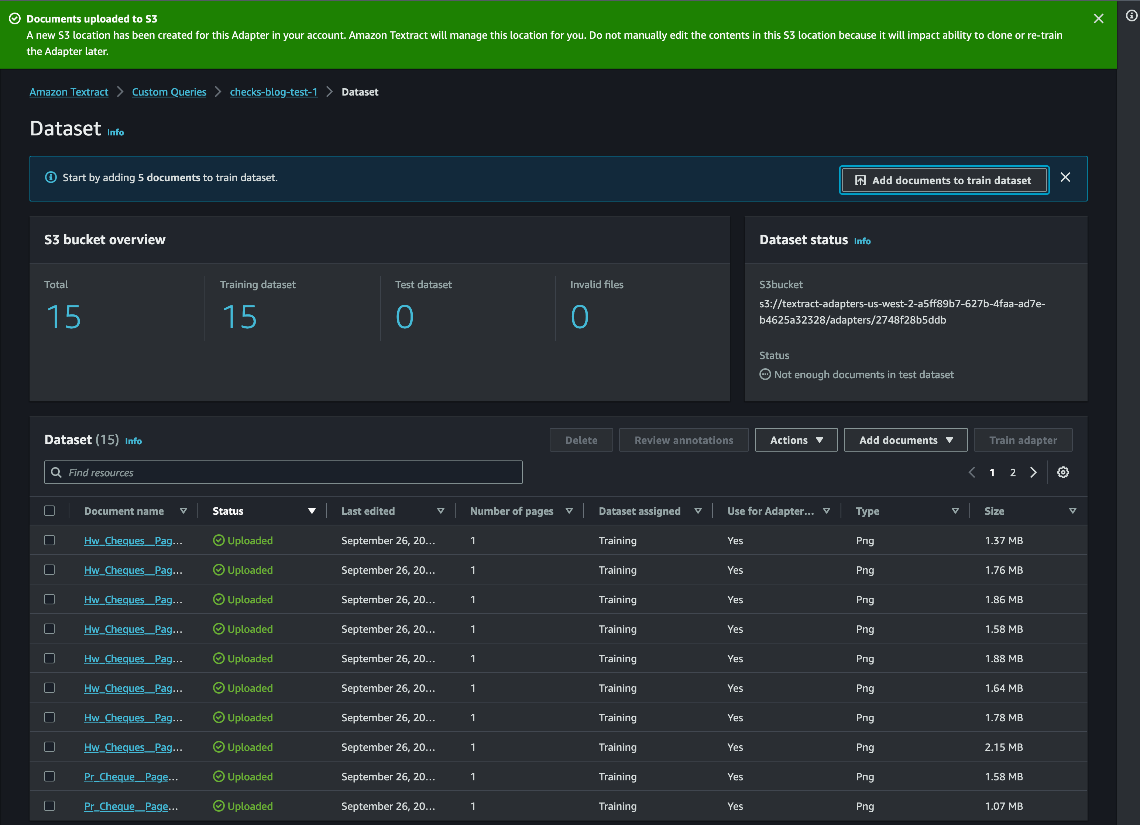
Annotate pattern paperwork
As a subsequent step, you annotate the pattern paperwork by associating queries with their corresponding solutions through the console. You possibly can provoke annotation through auto labeling or handbook labeling. Auto labeling makes use of Amazon Textract Queries to pre-label the dataset. We suggest utilizing auto labeling to fast-track the annotation course of.
For this checks processing use case, we use the next queries. In case your use case includes different doc sorts, confer with Best Practices for Queries to draft queries relevant to your use case.
- Who’s the payee?
- What’s the verify#?
- What’s the payee handle?
- What’s the date?
- What’s the account#?
- What’s the verify quantity in phrases?
- What’s the account title/payer/drawer title?
- What’s the greenback quantity?
- What’s the financial institution title/drawee title?
- What’s the financial institution routing quantity?
- What’s the MICR line?
- What’s the memo?
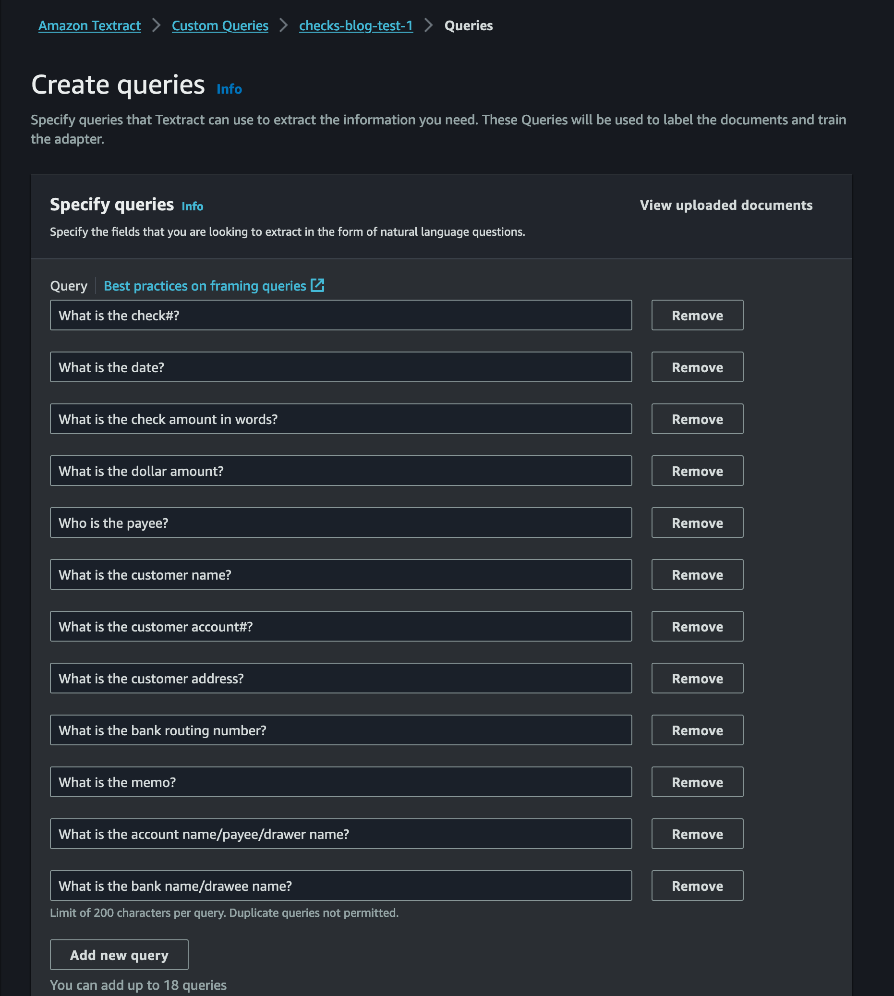
When the auto labeling course of is full, you’ve got the choice to overview and make edits to the solutions offered for every doc. Select Begin reviewing to overview the annotations in opposition to every picture.

If the response to a question is lacking or mistaken, you possibly can add or edit the response both by drawing a bounding field or getting into the response manually.
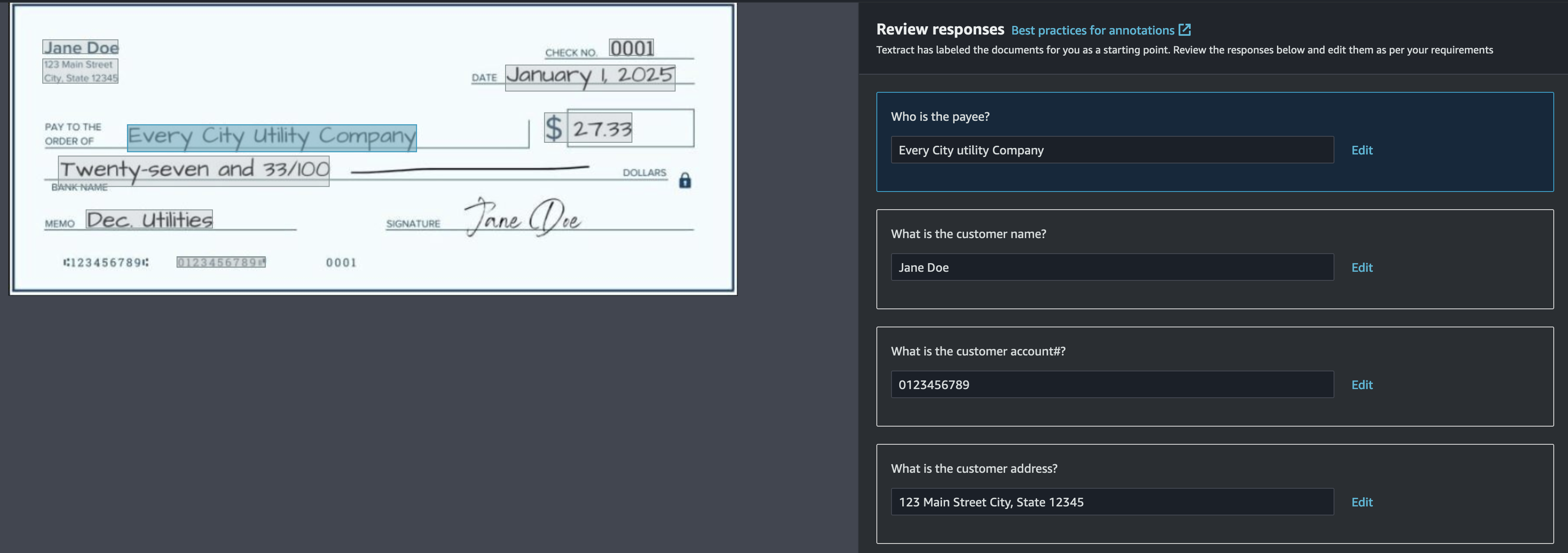
To speed up your walkthrough, we now have pre-annotated the checks samples so that you can copy to your AWS account. Run the custom-queries-checks-blog.ipynb Jupyter pocket book throughout the Amazon Textract code samples library to robotically replace your annotations.
Prepare the adapter
After you’ve reviewed all of the pattern paperwork to make sure the accuracy of the annotations, you possibly can start the adapter coaching course of. Throughout this step, you should designate a storage location the place the adapter needs to be saved. The length of the coaching course of will differ relying on the scale of the dataset utilized for coaching. The coaching API will also be invoked programmatically in the event you select to make use of an annotation device of your individual selection and go the related enter information to the API. Seek advice from Custom Queries for extra particulars.

Consider efficiency metrics
After the adapter has accomplished coaching, you possibly can assess its efficiency by inspecting analysis metrics reminiscent of F1 score, precision, and recall. You possibly can analyze these metrics both collectively or on a per-document foundation. Utilizing our pattern checks dataset, you will notice the accuracy metric (F1 rating) enhance from 68% to 92% with the educated adapter.

Moreover, you possibly can check the adapter’s output on new paperwork by selecting Strive Adapter.

Following the analysis, you possibly can select to reinforce the adapter’s efficiency by both incorporating further pattern paperwork into the coaching dataset or by re-annotating paperwork with scores which are decrease than your threshold. To re-annotate paperwork, select Confirm paperwork on the adapter particulars web page, choose the doc, and select Overview annotations.
Programmatically check the adapter
With the coaching efficiently accomplished, now you can use the adapter in your AnalyzeDocument API calls. The API request is just like the Amazon Textract Queries API request, with the addition of the AdaptersConfig object.
You possibly can run the next pattern code or instantly run it throughout the custom-queries-checks-blog.ipynb Jupyter pocket book. The pattern pocket book additionally gives code to match outcomes between Amazon Textract Queries and Amazon Textract Customized Queries.
Create an AdaptersConfig object with the adapter ID and adapter model, and optionally embrace the pages you need the adapter to be utilized to:
Create a QueriesConfig object with the queries you educated the adapter with and name the Amazon Textract API. Observe which you could additionally embrace further queries that the adapter has not been educated on. Amazon Textract will robotically use the Queries function for these questions and never Customized Queries, thereby offering you with the flexibleness of utilizing Customized Queries solely the place wanted.
Lastly, we tabulate our outcomes for higher readability:
Clear up
To scrub up your assets, full the next steps:
- On the Amazon Textract console, select Customized Queries within the navigation pane.
- Choose the adaptor you wish to delete.
- Select Delete.
Adapter administration
You possibly can frequently enhance your adapters by creating new variations of a beforehand generated adapter. To create a brand new model of an adapter, you add new pattern paperwork to an present adapter, label the paperwork, and carry out coaching. You possibly can concurrently preserve a number of variations of an adapter to be used in your growth pipelines. To replace your adapters seamlessly, don’t make adjustments to or delete your Amazon Simple Storage Service (Amazon S3) bucket the place the information wanted for adapter era are saved.
Finest practices
When utilizing Customized Queries in your paperwork, confer with Best practices for Amazon Textract Custom Queries for added issues and finest practices.
Advantages of Customized Queries
Customized Queries presents the next advantages:
- Enhanced doc understanding – By means of its capacity to extract and normalize knowledge with excessive accuracy, Customized Queries reduces reliance on handbook critiques, and audits, and lets you construct extra dependable automation on your clever doc processing workflows.
- Quicker time to worth – While you encounter new doc sorts the place you want larger accuracy, you should use Customized Queries to generate an adapter in a self-service method inside just a few hours. You don’t have to attend for a pre-trained mannequin replace whenever you encounter new doc sorts or variations of present ones in your workflow. You will have full management over your pipeline and don’t must rely on Amazon Textract to assist your new doc sorts.
- Information privateness – Customized Queries doesn’t retain or use the info employed in producing adapters to reinforce our common pretrained fashions obtainable to all prospects. The adapter is restricted to the client’s account or different accounts explicitly designated by the client, making certain that solely such accounts can entry the enhancements made utilizing the client’s knowledge.
- Comfort –Customized Queries gives a completely managed inference expertise just like Queries. The adapter coaching is free and you’ll solely pay for inference. Customized Queries saves you the overhead and bills of coaching and working customized fashions.
Conclusion
On this publish, we mentioned the advantages of Customized Queries, confirmed how Customized Queries can precisely extract knowledge from checks, and shared finest practices for successfully using this function. In just some hours, you possibly can create an adapter utilizing the console and use it within the AnalyzeDocument API on your knowledge extraction wants. For extra info, confer with Custom Queries.
In regards to the authors
 Shibin Michaelraj is a Sr. Product Supervisor with the Amazon Textract crew. He’s targeted on constructing AI/ML-based merchandise for AWS prospects. He’s excited serving to prospects resolve their complicated enterprise challenges by leveraging AI and ML applied sciences. In his spare time, he enjoys operating, tuning into podcasts, and refining his newbie tennis abilities.
Shibin Michaelraj is a Sr. Product Supervisor with the Amazon Textract crew. He’s targeted on constructing AI/ML-based merchandise for AWS prospects. He’s excited serving to prospects resolve their complicated enterprise challenges by leveraging AI and ML applied sciences. In his spare time, he enjoys operating, tuning into podcasts, and refining his newbie tennis abilities.
 Keith Mascarenhas is a Sr. Options Architect with the Amazon Textract service crew. He’s obsessed with fixing enterprise issues at scale utilizing machine studying, and at present helps our worldwide prospects automate their doc processing to realize quicker time to market with lowered operational prices.
Keith Mascarenhas is a Sr. Options Architect with the Amazon Textract service crew. He’s obsessed with fixing enterprise issues at scale utilizing machine studying, and at present helps our worldwide prospects automate their doc processing to realize quicker time to market with lowered operational prices.





