This Synthetic Intelligence-Centered Chip Redefines Effectivity: Doubling Down on Power Financial savings by Unifying Processing and Reminiscence
In a world the place the demand for data-centric native intelligence is on the rise, the problem of enabling gadgets to research information on the edge autonomously turns into more and more important. This transition in direction of edge-AI gadgets, encompassing wearables, sensors, smartphones, and vehicles, signifies the following progress section within the semiconductor trade. These gadgets help real-time studying, autonomy, and embedded intelligence.
Nonetheless, these edge-AI gadgets encounter a major roadblock referred to as the von Neumann bottleneck, whereby memory-bound computational duties, notably these associated to deep studying and AI, result in an amazing want for information entry, outstripping the capabilities of native computation inside conventional algorithmic logic items.
The journey in direction of fixing this computational conundrum has led to architectural improvements, together with in-memory computing (IMC). IMC, by performing Multiply and Accumulate (MAC) operations straight inside the reminiscence array, affords the potential to revolutionize AI programs. Current implementations of IMC usually contain binary logical operations, limiting their efficacy in additional advanced computations.
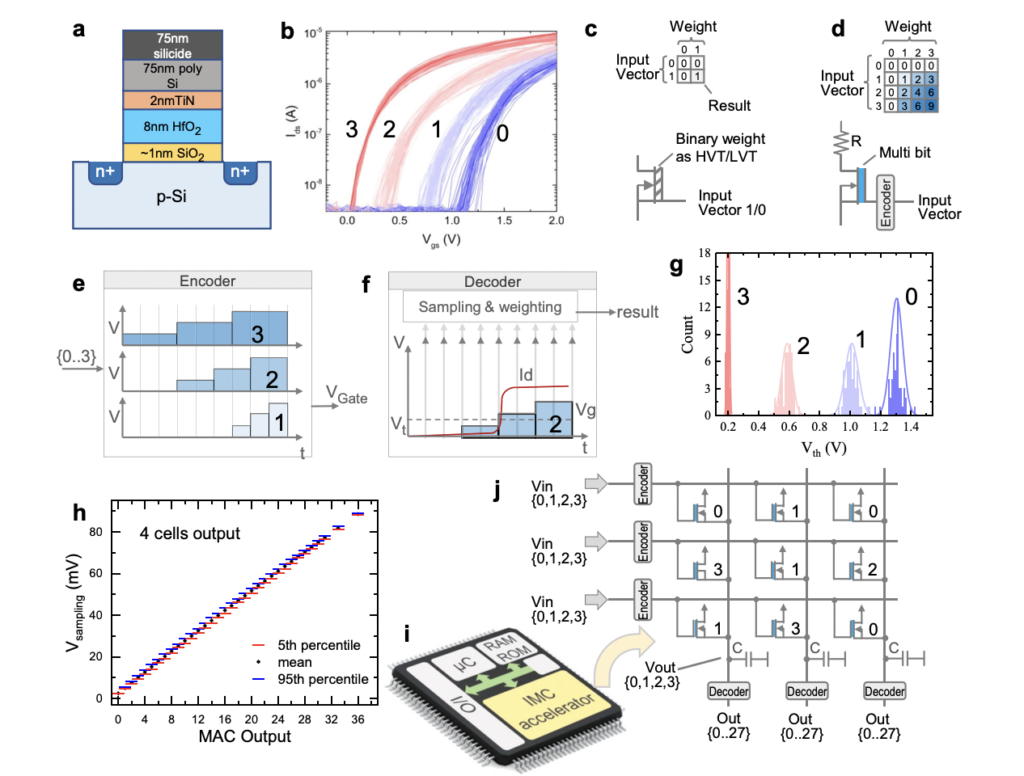
Enter the novel in-memory computing (IMC) crossbar macro that includes a multi-level ferroelectric field-effect transistor (FeFET) cell for multi-bit MAC operations. This innovation transcends the boundaries of conventional binary operations, using {the electrical} traits of saved information inside reminiscence cells to derive MAC operation outcomes encoded in activation time and collected present.
The exceptional efficiency metrics achieved are nothing wanting astounding. With 96.6% accuracy in handwriting recognition and 91.5% accuracy in picture classification, all with out extra coaching, this answer is poised to rework the AI panorama. Its power effectivity, rated at 885.4 TOPS/W, almost doubles that of present designs, additional underscoring its potential to drive the trade ahead.
In conclusion, this groundbreaking research represents a major leap ahead in AI and in-memory computing. By addressing the von Neumann bottleneck and introducing a novel strategy to multi-bit MAC operations, this answer not solely affords a recent perspective on AI {hardware} but in addition guarantees to unlock new horizons for native intelligence on the edge, finally shaping the way forward for computing.
Try the Paper and Blog. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t overlook to hitch our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
We’re additionally on Telegram and WhatsApp.

Niharika is a Technical consulting intern at Marktechpost. She is a 3rd yr undergraduate, at present pursuing her B.Tech from Indian Institute of Expertise(IIT), Kharagpur. She is a extremely enthusiastic particular person with a eager curiosity in Machine studying, Knowledge science and AI and an avid reader of the most recent developments in these fields.



