Aim Representations for Instruction Following – The Berkeley Synthetic Intelligence Analysis Weblog
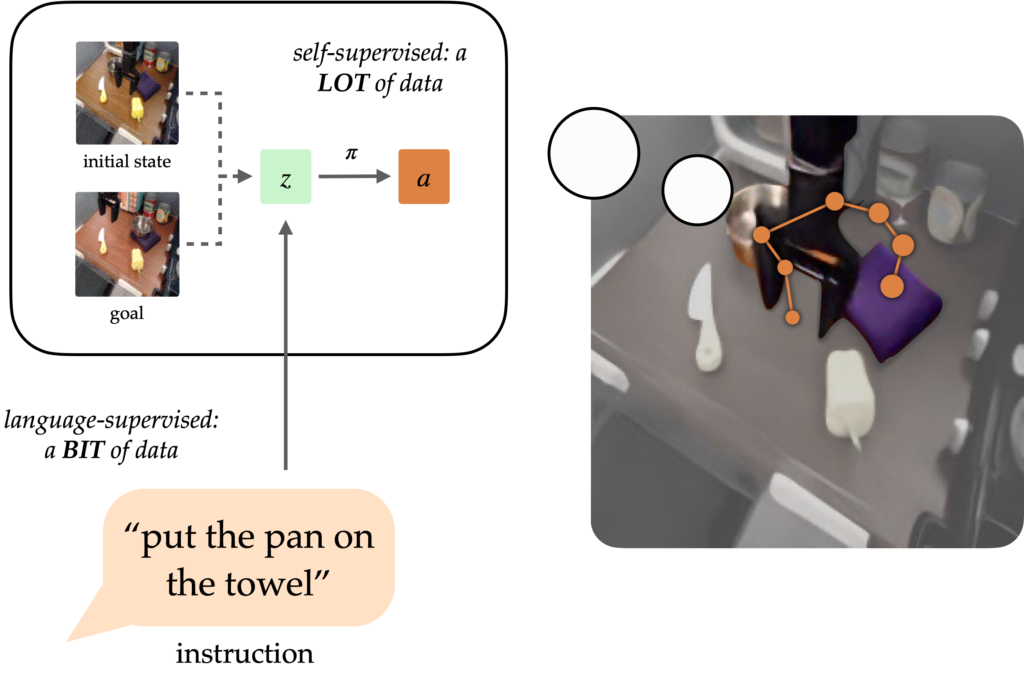
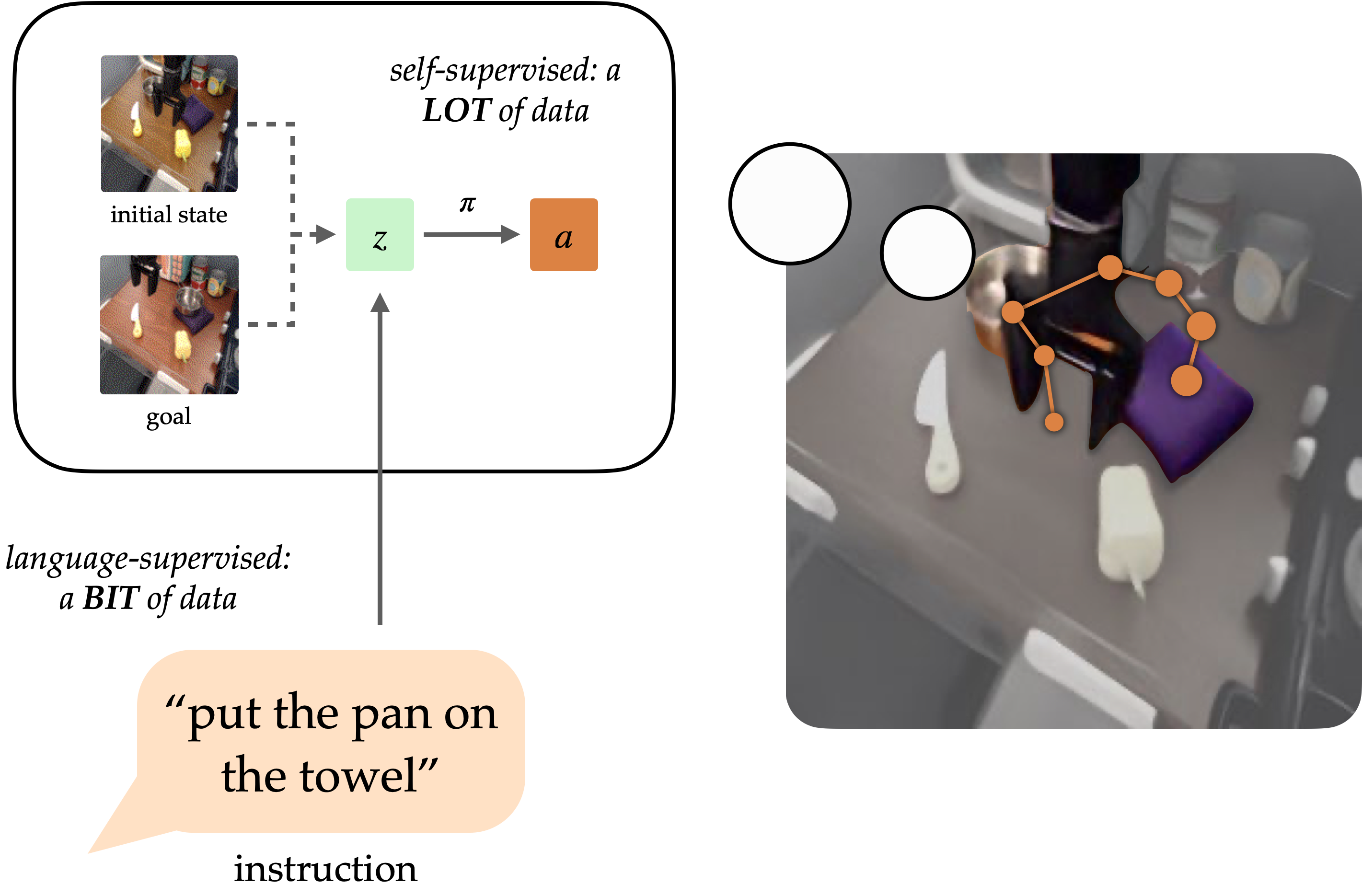
A longstanding objective of the sphere of robotic studying has been to create generalist brokers that may carry out duties for people. Pure language has the potential to be an easy-to-use interface for people to specify arbitrary duties, however it’s tough to coach robots to comply with language directions. Approaches like language-conditioned behavioral cloning (LCBC) practice insurance policies to immediately imitate knowledgeable actions conditioned on language, however require people to annotate all coaching trajectories and generalize poorly throughout scenes and behaviors. In the meantime, latest goal-conditioned approaches carry out significantly better at basic manipulation duties, however don’t allow simple job specification for human operators. How can we reconcile the convenience of specifying duties by means of LCBC-like approaches with the efficiency enhancements of goal-conditioned studying?
Conceptually, an instruction-following robotic requires two capabilities. It must floor the language instruction within the bodily surroundings, after which be capable to perform a sequence of actions to finish the supposed job. These capabilities don’t must be realized end-to-end from human-annotated trajectories alone, however can as an alternative be realized individually from the suitable information sources. Imaginative and prescient-language information from non-robot sources can assist be taught language grounding with generalization to various directions and visible scenes. In the meantime, unlabeled robotic trajectories can be utilized to coach a robotic to succeed in particular objective states, even when they don’t seem to be related to language directions.
Conditioning on visible targets (i.e. objective pictures) gives complementary advantages for coverage studying. As a type of job specification, targets are fascinating for scaling as a result of they are often freely generated hindsight relabeling (any state reached alongside a trajectory could be a objective). This permits insurance policies to be educated through goal-conditioned behavioral cloning (GCBC) on giant quantities of unannotated and unstructured trajectory information, together with information collected autonomously by the robotic itself. Targets are additionally simpler to floor since, as pictures, they are often immediately in contrast pixel-by-pixel with different states.
Nonetheless, targets are much less intuitive for human customers than pure language. Generally, it’s simpler for a consumer to explain the duty they need carried out than it’s to offer a objective picture, which might probably require performing the duty in any case to generate the picture. By exposing a language interface for goal-conditioned insurance policies, we are able to mix the strengths of each goal- and language- job specification to allow generalist robots that may be simply commanded. Our methodology, mentioned under, exposes such an interface to generalize to various directions and scenes utilizing vision-language information, and enhance its bodily abilities by digesting giant unstructured robotic datasets.
Aim Representations for Instruction Following
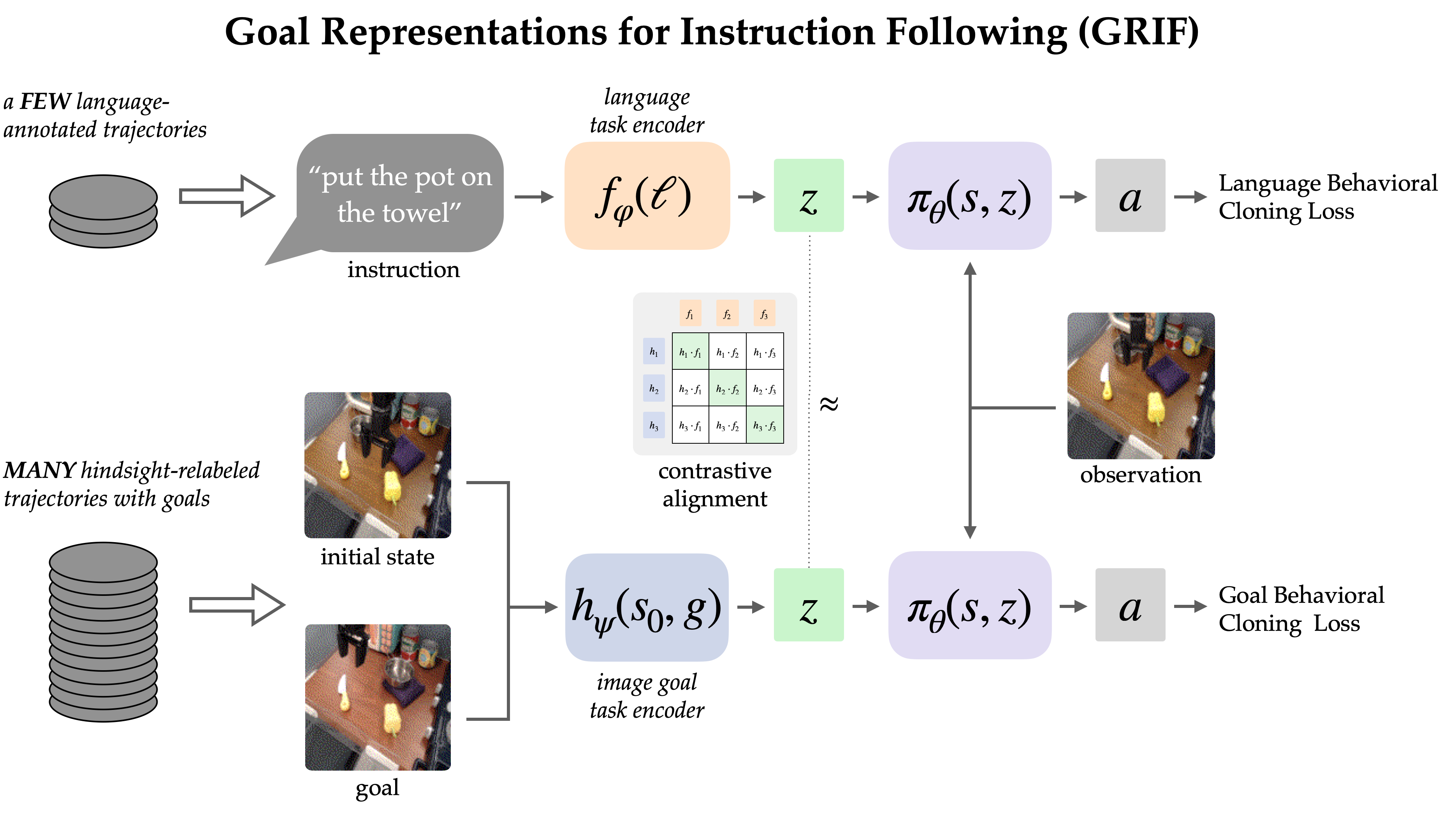
The GRIF mannequin consists of a language encoder, a objective encoder, and a coverage community. The encoders respectively map language directions and objective pictures right into a shared job illustration area, which situations the coverage community when predicting actions. The mannequin can successfully be conditioned on both language directions or objective pictures to foretell actions, however we’re primarily utilizing goal-conditioned coaching as a manner to enhance the language-conditioned use case.
Our method, Aim Representations for Instruction Following (GRIF), collectively trains a language- and a goal- conditioned coverage with aligned job representations. Our key perception is that these representations, aligned throughout language and objective modalities, allow us to successfully mix the advantages of goal-conditioned studying with a language-conditioned coverage. The realized insurance policies are then in a position to generalize throughout language and scenes after coaching on largely unlabeled demonstration information.
We educated GRIF on a model of the Bridge-v2 dataset containing 7k labeled demonstration trajectories and 47k unlabeled ones inside a kitchen manipulation setting. Since all of the trajectories on this dataset needed to be manually annotated by people, having the ability to immediately use the 47k trajectories with out annotation considerably improves effectivity.
To be taught from each forms of information, GRIF is educated collectively with language-conditioned behavioral cloning (LCBC) and goal-conditioned behavioral cloning (GCBC). The labeled dataset comprises each language and objective job specs, so we use it to oversee each the language- and goal-conditioned predictions (i.e. LCBC and GCBC). The unlabeled dataset comprises solely targets and is used for GCBC. The distinction between LCBC and GCBC is only a matter of choosing the duty illustration from the corresponding encoder, which is handed right into a shared coverage community to foretell actions.
By sharing the coverage community, we are able to count on some enchancment from utilizing the unlabeled dataset for goal-conditioned coaching. Nonetheless,GRIF allows a lot stronger switch between the 2 modalities by recognizing that some language directions and objective pictures specify the identical habits. Particularly, we exploit this construction by requiring that language- and goal- representations be comparable for a similar semantic job. Assuming this construction holds, unlabeled information may also profit the language-conditioned coverage for the reason that objective illustration approximates that of the lacking instruction.
Alignment by means of Contrastive Studying
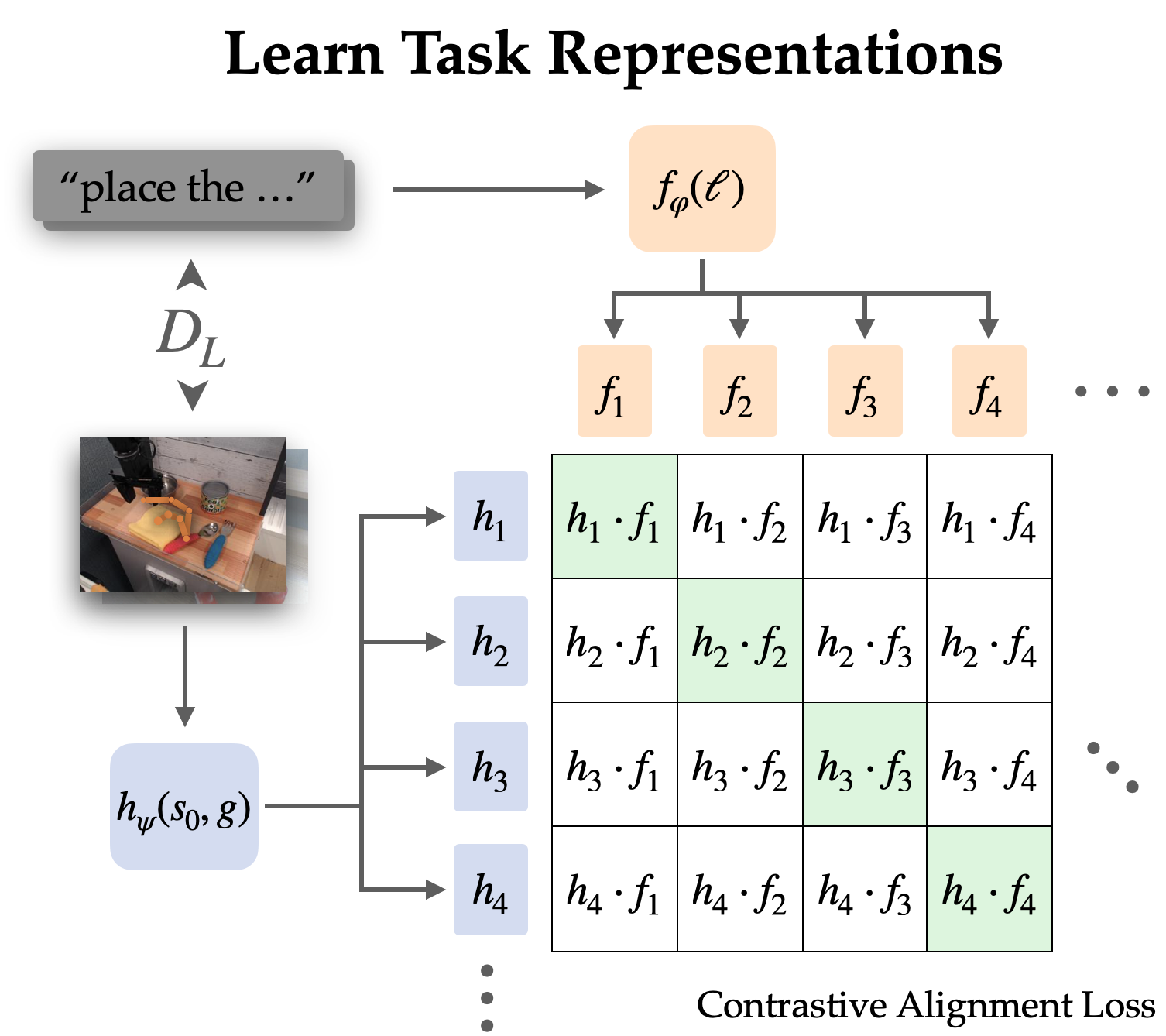
We explicitly align representations between goal-conditioned and language-conditioned duties on the labeled dataset by means of contrastive studying.
Since language usually describes relative change, we select to align representations of state-goal pairs with the language instruction (versus simply objective with language). Empirically, this additionally makes the representations simpler to be taught since they’ll omit most data within the pictures and concentrate on the change from state to objective.
We be taught this alignment construction by means of an infoNCE goal on directions and pictures from the labeled dataset. We practice twin picture and textual content encoders by doing contrastive studying on matching pairs of language and objective representations. The target encourages excessive similarity between representations of the identical job and low similarity for others, the place the destructive examples are sampled from different trajectories.
When utilizing naive destructive sampling (uniform from the remainder of the dataset), the realized representations usually ignored the precise job and easily aligned directions and targets that referred to the identical scenes. To make use of the coverage in the actual world, it isn’t very helpful to affiliate language with a scene; slightly we want it to disambiguate between totally different duties in the identical scene. Thus, we use a tough destructive sampling technique, the place as much as half the negatives are sampled from totally different trajectories in the identical scene.
Naturally, this contrastive studying setup teases at pre-trained vision-language fashions like CLIP. They reveal efficient zero-shot and few-shot generalization functionality for vision-language duties, and supply a approach to incorporate information from internet-scale pre-training. Nonetheless, most vision-language fashions are designed for aligning a single static picture with its caption with out the power to know modifications within the surroundings, they usually carry out poorly when having to concentrate to a single object in cluttered scenes.
To handle these points, we devise a mechanism to accommodate and fine-tune CLIP for aligning job representations. We modify the CLIP structure in order that it may function on a pair of pictures mixed with early fusion (stacked channel-wise). This seems to be a succesful initialization for encoding pairs of state and objective pictures, and one which is especially good at preserving the pre-training advantages from CLIP.
Robotic Coverage Outcomes
For our fundamental outcome, we consider the GRIF coverage in the actual world on 15 duties throughout 3 scenes. The directions are chosen to be a mixture of ones which can be well-represented within the coaching information and novel ones that require some extent of compositional generalization. One of many scenes additionally options an unseen mixture of objects.
We examine GRIF towards plain LCBC and stronger baselines impressed by prior work like LangLfP and BC-Z. LLfP corresponds to collectively coaching with LCBC and GCBC. BC-Z is an adaptation of the namesake methodology to our setting, the place we practice on LCBC, GCBC, and a easy alignment time period. It optimizes the cosine distance loss between the duty representations and doesn’t use image-language pre-training.
The insurance policies have been vulnerable to 2 fundamental failure modes. They will fail to know the language instruction, which leads to them making an attempt one other job or performing no helpful actions in any respect. When language grounding shouldn’t be strong, insurance policies would possibly even begin an unintended job after having achieved the appropriate job, for the reason that unique instruction is out of context.
Examples of grounding failures

“put the mushroom within the steel pot”

“put the spoon on the towel”

“put the yellow bell pepper on the fabric”

“put the yellow bell pepper on the fabric”
The opposite failure mode is failing to govern objects. This may be as a consequence of lacking a grasp, shifting imprecisely, or releasing objects on the incorrect time. We word that these usually are not inherent shortcomings of the robotic setup, as a GCBC coverage educated on the complete dataset can persistently achieve manipulation. Slightly, this failure mode usually signifies an ineffectiveness in leveraging goal-conditioned information.
Examples of manipulation failures

“transfer the bell pepper to the left of the desk”

“put the bell pepper within the pan”

“transfer the towel subsequent to the microwave”
Evaluating the baselines, they every suffered from these two failure modes to totally different extents. LCBC depends solely on the small labeled trajectory dataset, and its poor manipulation functionality prevents it from finishing any duties. LLfP collectively trains the coverage on labeled and unlabeled information and exhibits considerably improved manipulation functionality from LCBC. It achieves affordable success charges for frequent directions, however fails to floor extra complicated directions. BC-Z’s alignment technique additionally improves manipulation functionality, probably as a result of alignment improves the switch between modalities. Nonetheless, with out exterior vision-language information sources, it nonetheless struggles to generalize to new directions.
GRIF exhibits one of the best generalization whereas additionally having sturdy manipulation capabilities. It is ready to floor the language directions and perform the duty even when many distinct duties are potential within the scene. We present some rollouts and the corresponding directions under.
Coverage Rollouts from GRIF

“transfer the pan to the entrance”

“put the bell pepper within the pan”

“put the knife on the purple material”

“put the spoon on the towel”
Conclusion
GRIF allows a robotic to make the most of giant quantities of unlabeled trajectory information to be taught goal-conditioned insurance policies, whereas offering a “language interface” to those insurance policies through aligned language-goal job representations. In distinction to prior language-image alignment strategies, our representations align modifications in state to language, which we present results in vital enhancements over normal CLIP-style image-language alignment goals. Our experiments reveal that our method can successfully leverage unlabeled robotic trajectories, with giant enhancements in efficiency over baselines and strategies that solely use the language-annotated information
Our methodology has a variety of limitations that could possibly be addressed in future work. GRIF shouldn’t be well-suited for duties the place directions say extra about the best way to do the duty than what to do (e.g., “pour the water slowly”)—such qualitative directions would possibly require different forms of alignment losses that take into account the intermediate steps of job execution. GRIF additionally assumes that every one language grounding comes from the portion of our dataset that’s totally annotated or a pre-trained VLM. An thrilling course for future work could be to increase our alignment loss to make the most of human video information to be taught wealthy semantics from Web-scale information. Such an method might then use this information to enhance grounding on language outdoors the robotic dataset and allow broadly generalizable robotic insurance policies that may comply with consumer directions.
This submit relies on the next paper:
If GRIF evokes your work, please cite it with:
@misc{myers2023goal,
title={Aim Representations for Instruction Following: A Semi-Supervised Language Interface to Management},
writer={Vivek Myers and Andre He and Kuan Fang and Homer Walke and Philippe Hansen-Estruch and Ching-An Cheng and Mihai Jalobeanu and Andrey Kolobov and Anca Dragan and Sergey Levine},
yr={2023},
eprint={2307.00117},
archivePrefix={arXiv},
primaryClass={cs.RO}
}





