Put together your information for Amazon Personalize with Amazon SageMaker Knowledge Wrangler

A advice engine is barely pretty much as good as the information used to arrange it. Remodeling uncooked information right into a format that’s appropriate for a mannequin is essential to getting higher personalised suggestions for end-users.
On this publish, we stroll by means of tips on how to put together and import the MovieLens dataset, a dataset ready by GroupLens analysis on the College of Minnesota, which consists of a wide range of person rankings of assorted motion pictures, into Amazon Personalize utilizing Amazon SageMaker Data Wrangler. [1]
Resolution overview
Amazon Personalize is a managed service whose core worth proposition is its capacity to study person preferences from their previous conduct and rapidly alter these discovered preferences to take account of adjusting person conduct in near-real time. To have the ability to develop this understanding of customers, Amazon Personalize wants to coach on the historic person conduct in order that it will probably discover patterns which are generalizable in the direction of the long run. Particularly, the principle sort of information that Amazon Personalize learns from is what we name an interactions dataset, which is a tabular dataset that consists of at minimal three crucial columns, userID, itemID, and timestamp, representing a optimistic interplay between a person and an merchandise at a selected time. Customers Amazon Personalize must add information containing their very own buyer’s interactions to ensure that the mannequin to have the ability to study these behavioral traits. Though the inner algorithms inside Amazon Personalize have been chosen based mostly on Amazon’s expertise within the machine studying area, a customized mannequin doesn’t come pre-loaded with any form of information and trains fashions on a customer-by-customer foundation.
The MovieLens dataset explored on this walkthrough isn’t on this format, so to arrange it for Amazon Personalize, we use SageMaker Knowledge Wrangler, a purpose-built information aggregation and preparation device for machine studying. It has over 300 preconfigured information transformations in addition to the flexibility to usher in customized code to create customized transformations in PySpark, SQL, and a wide range of information processing libraries, corresponding to pandas.
Stipulations
First, we have to have an Amazon SageMaker Studio area arrange. For particulars on tips on how to set it up, check with Onboard to Amazon SageMaker Domain using Quick setup.
Additionally, we have to set up the right permissions utilizing AWS Identity and Access Management (IAM) for Amazon Personalize and Amazon SageMaker service roles in order that they will entry the wanted functionalities.
You’ll be able to create a new Amazon Personalize dataset group to make use of on this walkthrough or use an current one.
Lastly, we have to download and unzip the MovieLens dataset and place it in an Amazon Simple Storage Service (Amazon S3) bucket.
Launch SageMaker Knowledge Wrangler from Amazon Personalize
To begin with the SageMaker Knowledge Wrangler integration with Amazon Personalize, full the next steps:
- On the Amazon Personalize console, navigate to the Overview web page of your dataset group.
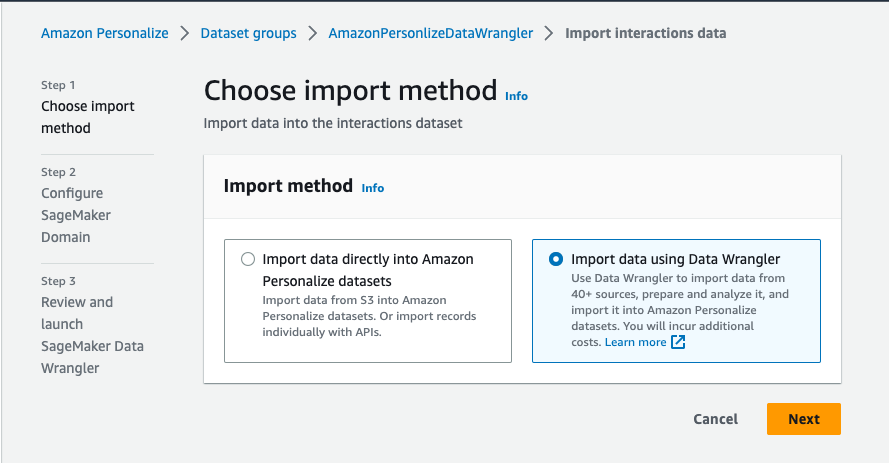
- Select Import interplay information, Import person information, or Import merchandise information, relying on the dataset sort (for this publish, we select Import interplay information).

- For Import technique, choose Import information utilizing Knowledge Wrangler.
- Select Subsequent.
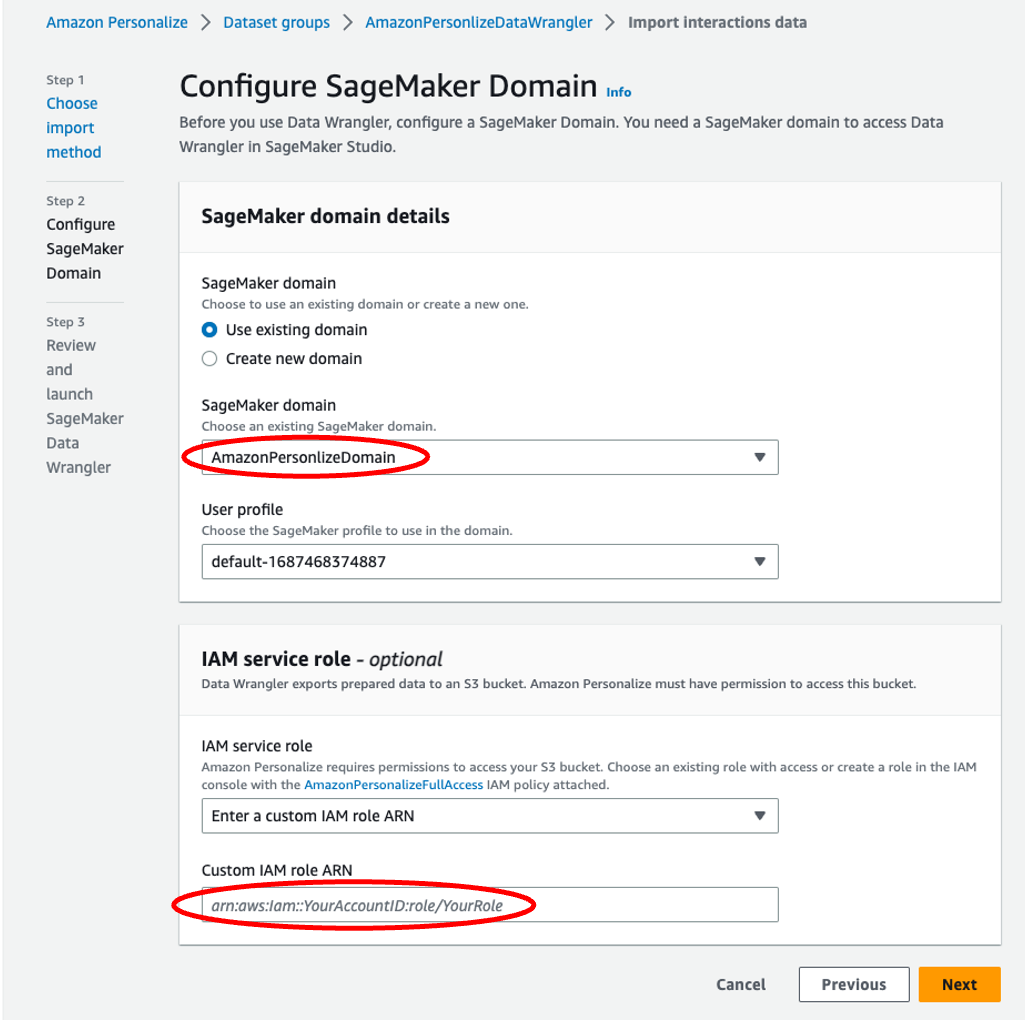
- Specify the SageMaker area, person profile, and IAM service function that you just created earlier as a part of the stipulations.
- Select Subsequent.
- Proceed by means of the steps to launch an occasion of SageMaker Knowledge Wrangler.
Organising the setting for the primary time can take as much as 5 minutes.
Import the uncooked information into SageMaker Knowledge Wrangler
When utilizing SageMaker Knowledge Wrangler to arrange and import information, we use an information move. A information move defines a sequence of transformations and analyses on information to arrange it to create a machine studying mannequin. Every time we add a step to our move, SageMaker Knowledge Wrangler takes an motion on our information, corresponding to becoming a member of it with one other dataset or dropping some rows and columns.
To begin, let’s import the uncooked information.
- On the information move web page, select Import information.
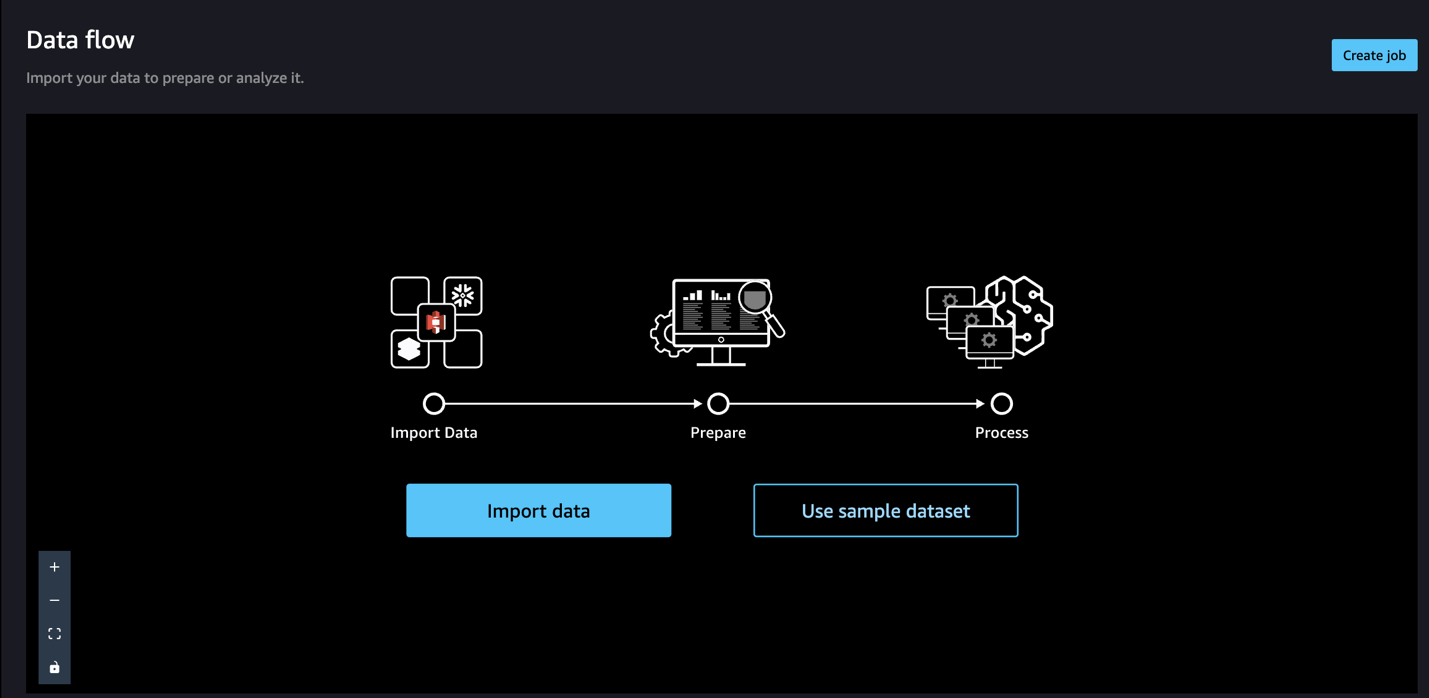
With SageMaker Knowledge Wrangler, we are able to import information from over 50 supported information sources.
- For Knowledge sources¸ select Amazon S3.
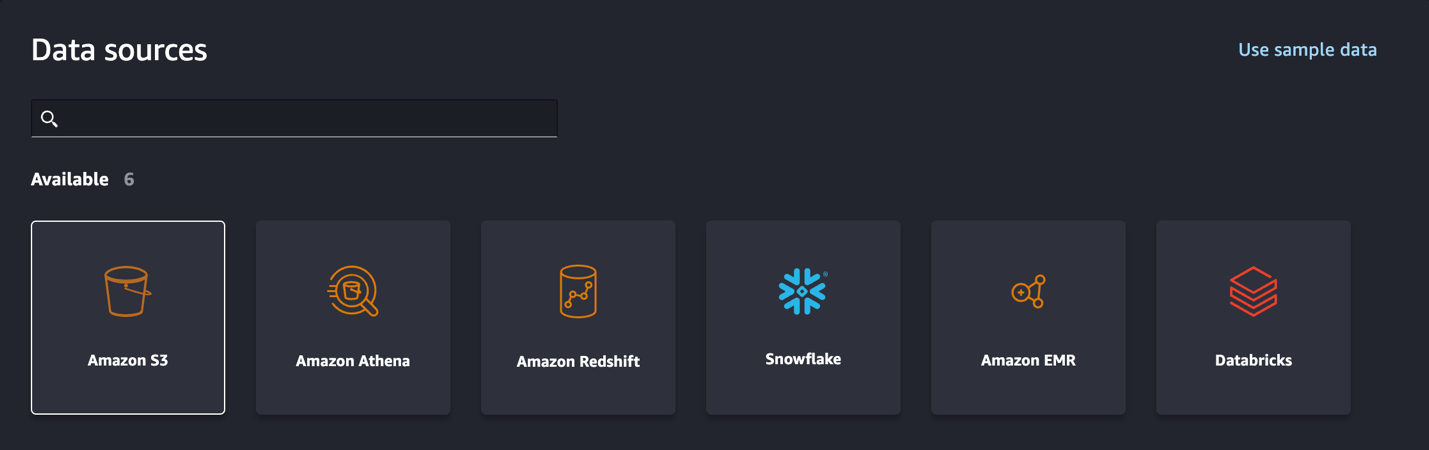
- Select the dataset you uploaded to your S3 bucket.
SageMaker Knowledge Wrangler mechanically shows a preview of the information.
- Preserve the default settings and select Import.
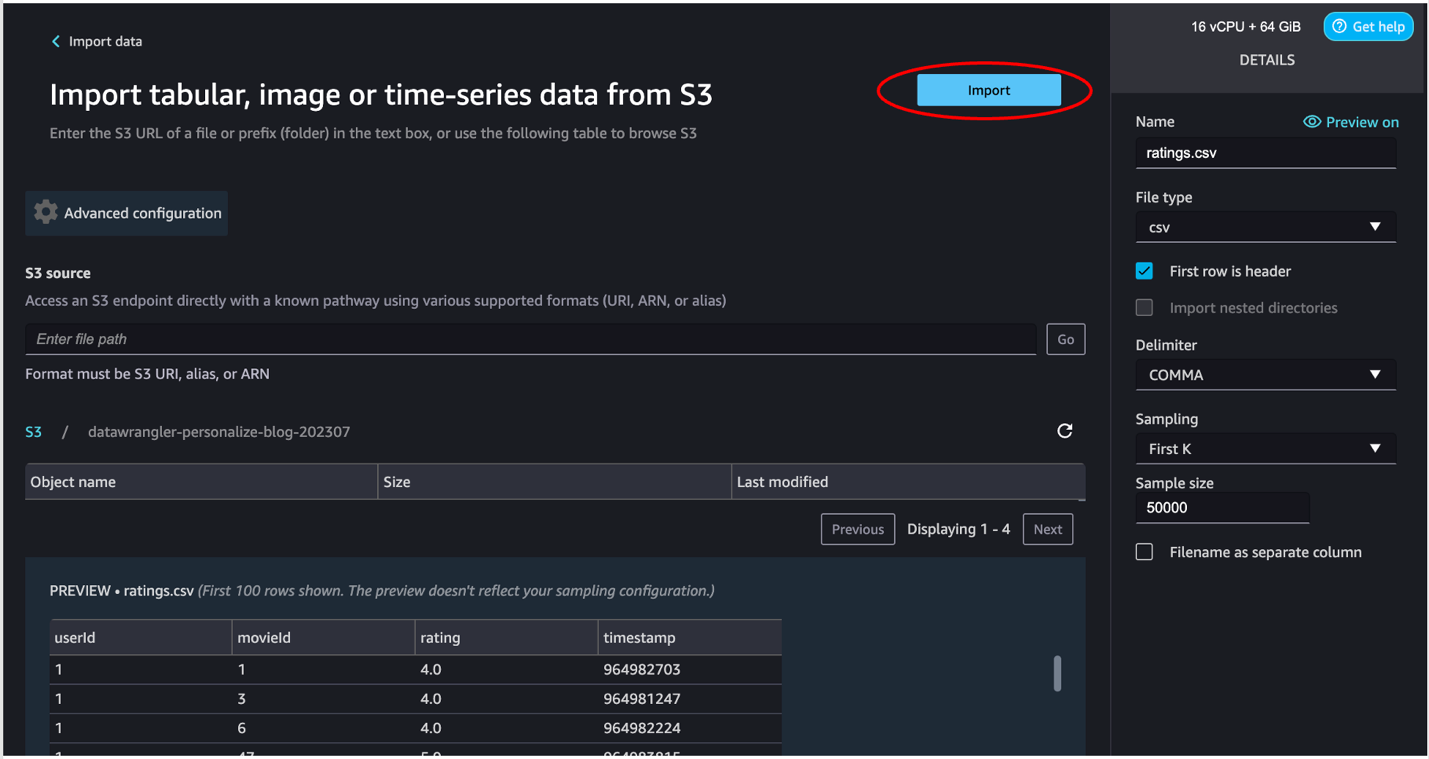
After the information is imported, SageMaker Knowledge Wrangler mechanically validates the datasets and detects the information sorts for all of the columns based mostly on its sampling.
- Select Knowledge move on the prime of the Knowledge sorts web page to view the principle information move earlier than transferring to the subsequent step.
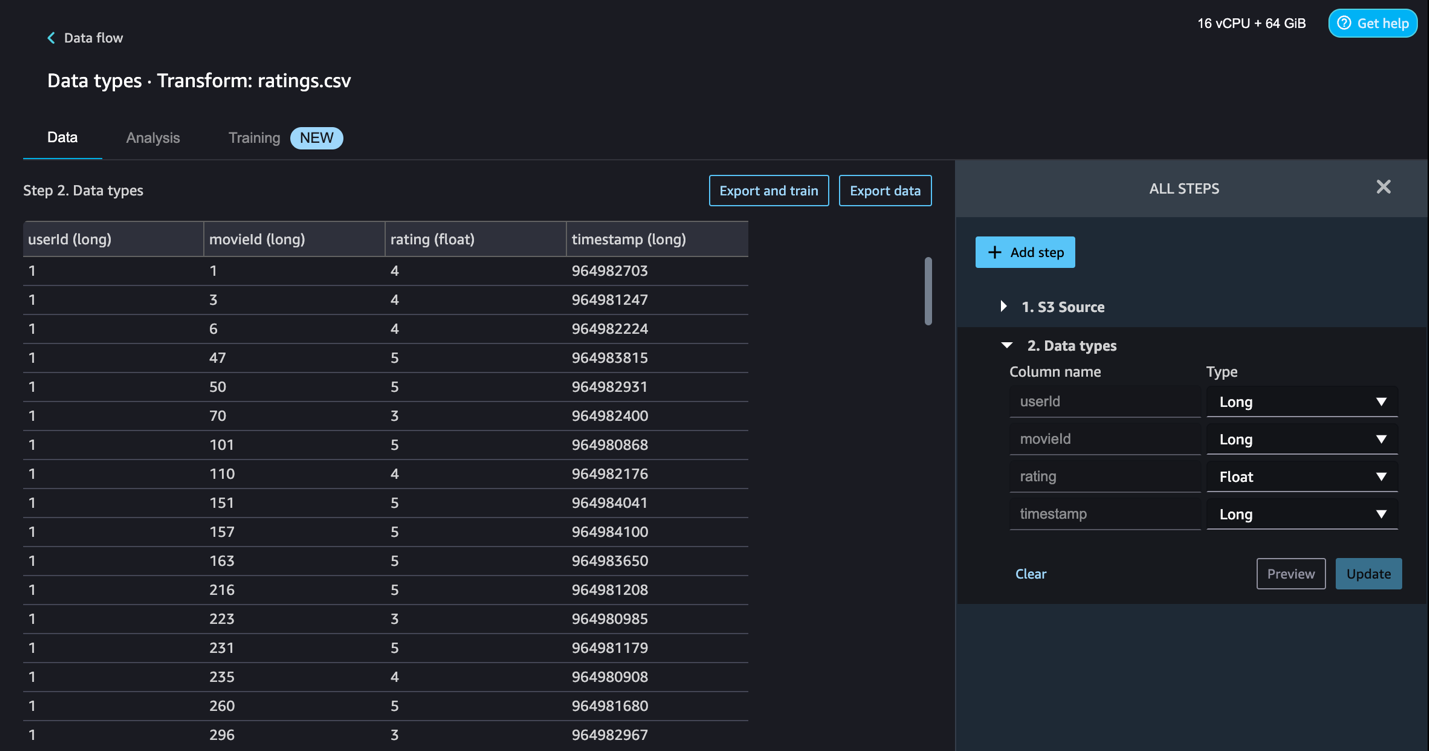
One of many foremost benefits of SageMaker Knowledge Wrangler is the flexibility to run previews of your transformations on a small subset of information earlier than committing to use the transformations on your complete dataset. To run the identical transformation on a number of partitioned recordsdata in Amazon S3, you should utilize parameters.
Rework the information
To remodel information in SageMaker Knowledge Wrangler, you add a Rework step to your information move. SageMaker Knowledge Wrangler contains over 300 transforms that you should utilize to arrange your information, together with a Map columns for Amazon Personalize rework. You should utilize the overall SageMaker Knowledge Wrangler transforms to repair points corresponding to outliers, sort points, and lacking values, or apply information preprocessing steps.
To make use of Amazon Personalize, the information you supplied within the interactions dataset should match your dataset schema. For our film recommender engine, the proposed interactions dataset schema contains:
user_id(string)item_id(string)event_type(string)timestamp(in Unix epoch time format)
To study extra about Amazon Personalize datasets and schemas, check with Datasets and schemas.
The rankings.csv file as proven within the final step within the earlier part contains motion pictures rated from 1–5. We need to construct a film recommender engine based mostly on that. To take action, we should full the next steps:
- Modify the columns information sorts.
- Create two occasion sorts: Click on and Watch.
- Assign all motion pictures rated 2 and above as Click on and flicks rated 4 and above as each Click on and Watch.
- Drop the
rankingscolumn. - Map the columns to the Amazon Personalize interactions dataset schema.
- Validate that our timestamp is in Unix epoch time.
Observe that Step 3 isn’t wanted to make a personalization mannequin. If we need to use one of many Amazon Personalize streamlined video on demand area recommenders, corresponding to Top Picks for You, Click on and Watch can be required occasion sorts. Nonetheless, if we don’t have these, we couldn’t embody an occasion sort subject (or add our personal occasion sorts such because the uncooked person rankings) and use a customized recipe corresponding to User Personalization. No matter what sort of advice engine we use, we have to guarantee our dataset accommodates solely representations of optimistic person intent. So no matter method you select, you might want to drop all one-star rankings (and presumably two-star rankings as nicely).
Now let’s use SageMaker Knowledge Wrangler to carry out the previous steps.
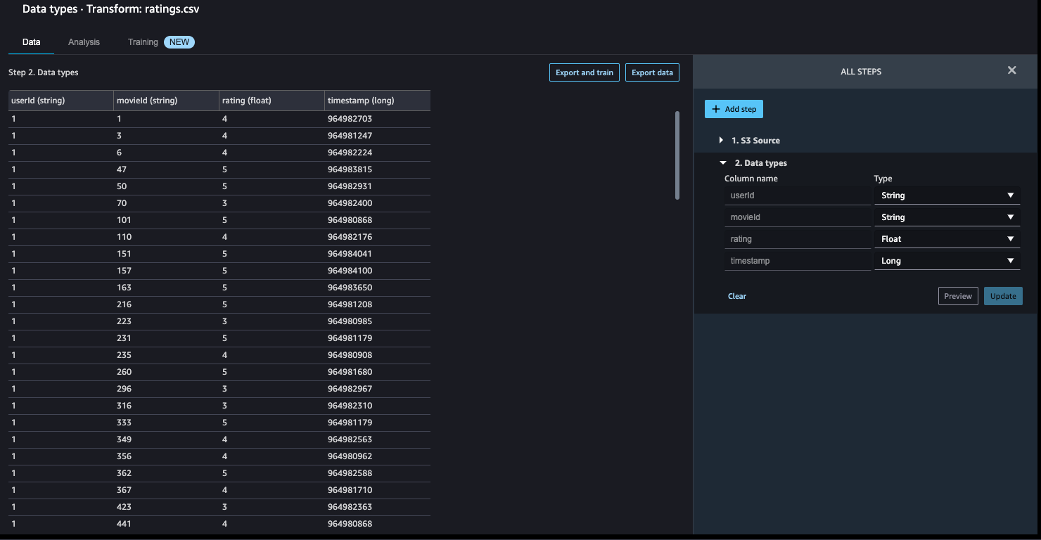
- On the Knowledge move web page, select the primary rework, referred to as Knowledge sorts.
- Replace the kind for every column.
- Select Preview to replicate the modifications, then select Replace.
- So as to add a step within the information move, select the plus signal subsequent to the step you need to carry out the rework on, then select Add rework.
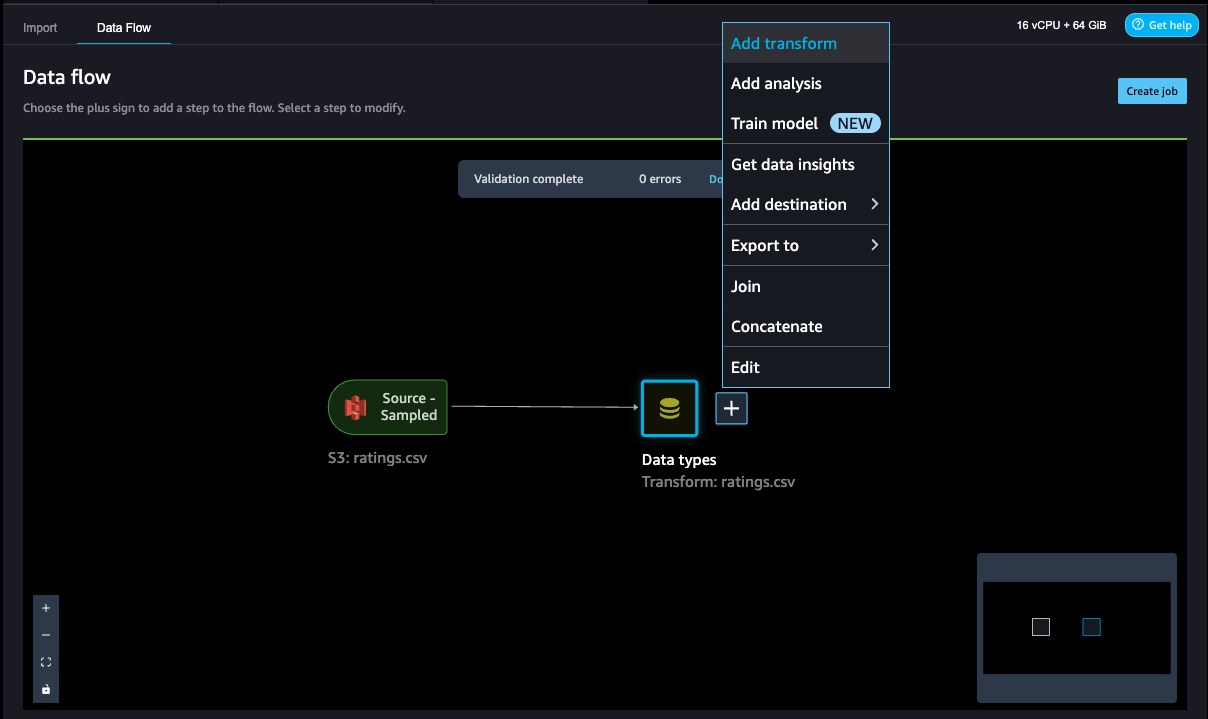
- To filter the occasion Click on out of the film rankings, we add a Filter information step to filter out the flicks rated 2 and above.
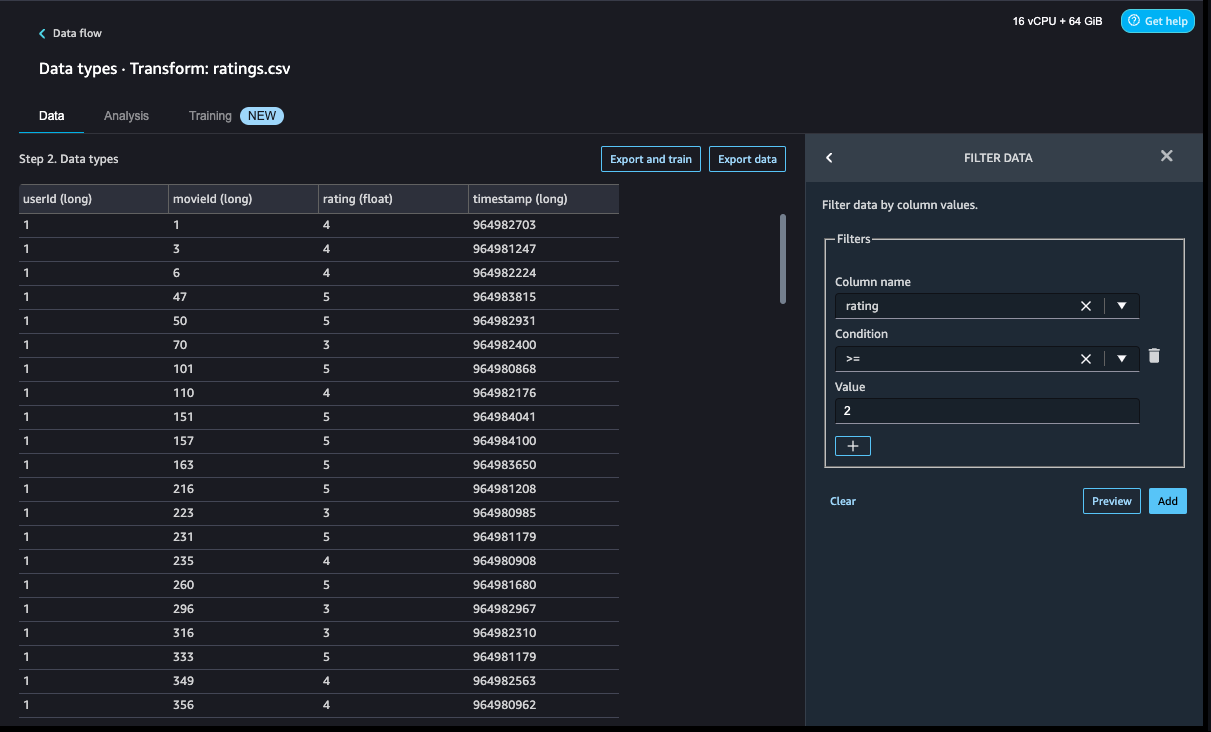
- Add one other customized rework step so as to add a brand new column,
eventType, with Click on as an assigned worth. - Select Preview to overview your transformation to double-check the outcomes are as supposed, then select Add.
- On this case, we write some PySpark code so as to add a column referred to as
eventTypewhose worth might be uniformly Click on for all of our two-star by means of five-star motion pictures:

- For the Watch occasions, repeat the earlier steps for motion pictures rated 4 and above and assign the Watch worth by including the steps to the Knowledge sorts step. Our PySpark code for these steps is as follows:
Up so far, the information move ought to seem like the next screenshot.
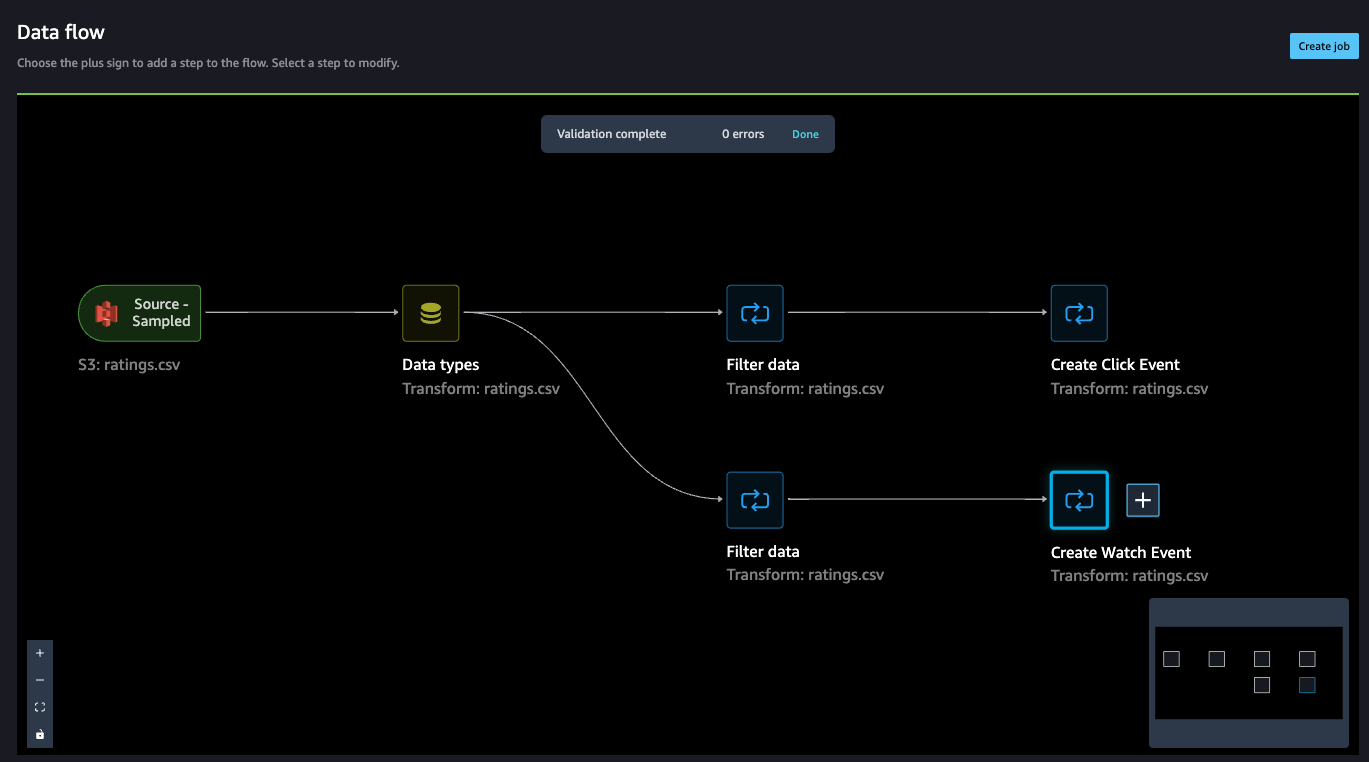
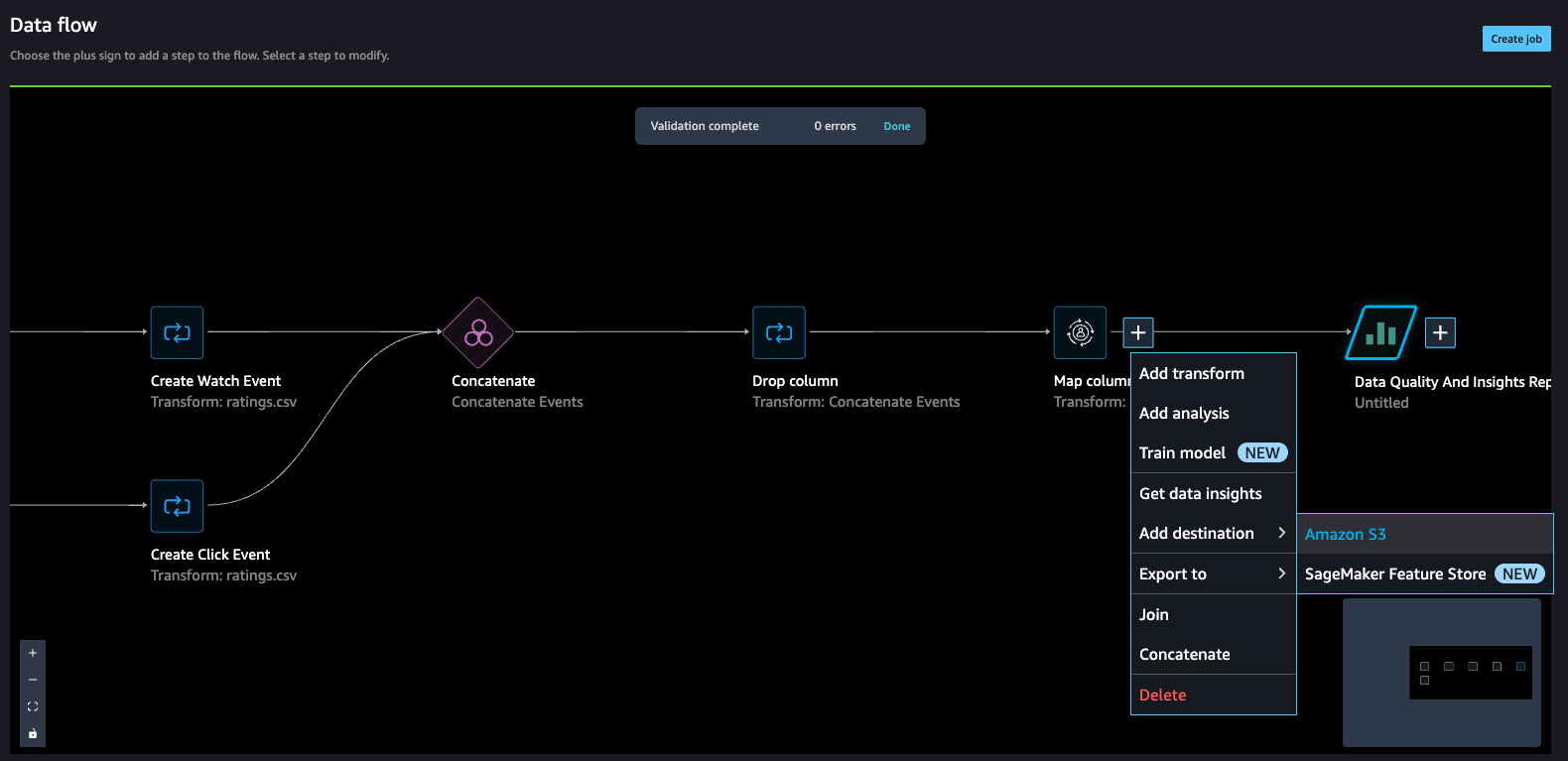
Concatenate datasets
As a result of we have now two datasets for watched and clicked occasions, let’s stroll by means of tips on how to concatenate these into one interactions dataset.
- On the Knowledge move web page, select the plus signal subsequent to Create Watch Occasion and select Concatenate.
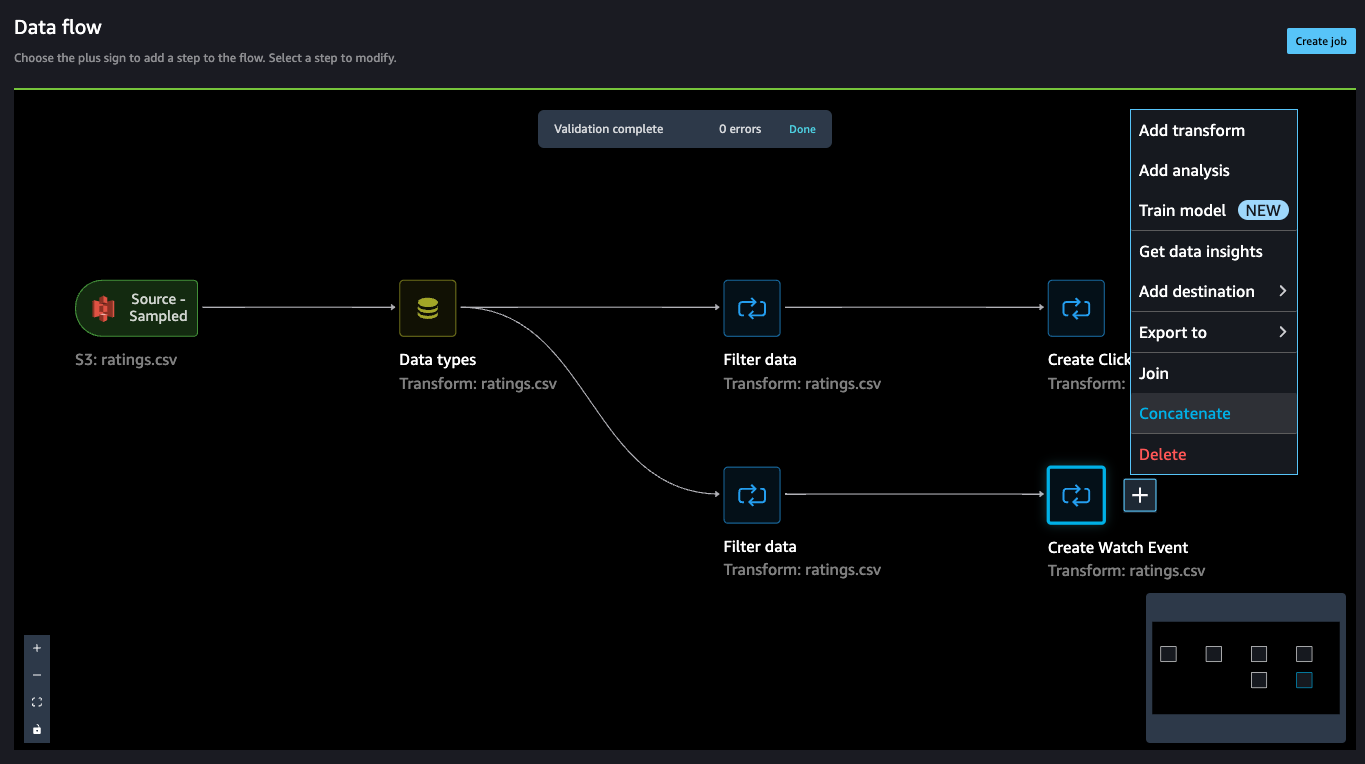
- Select the opposite closing step (Create Click on Occasion), and this could mechanically map (converge) each the units right into a concatenate preview.
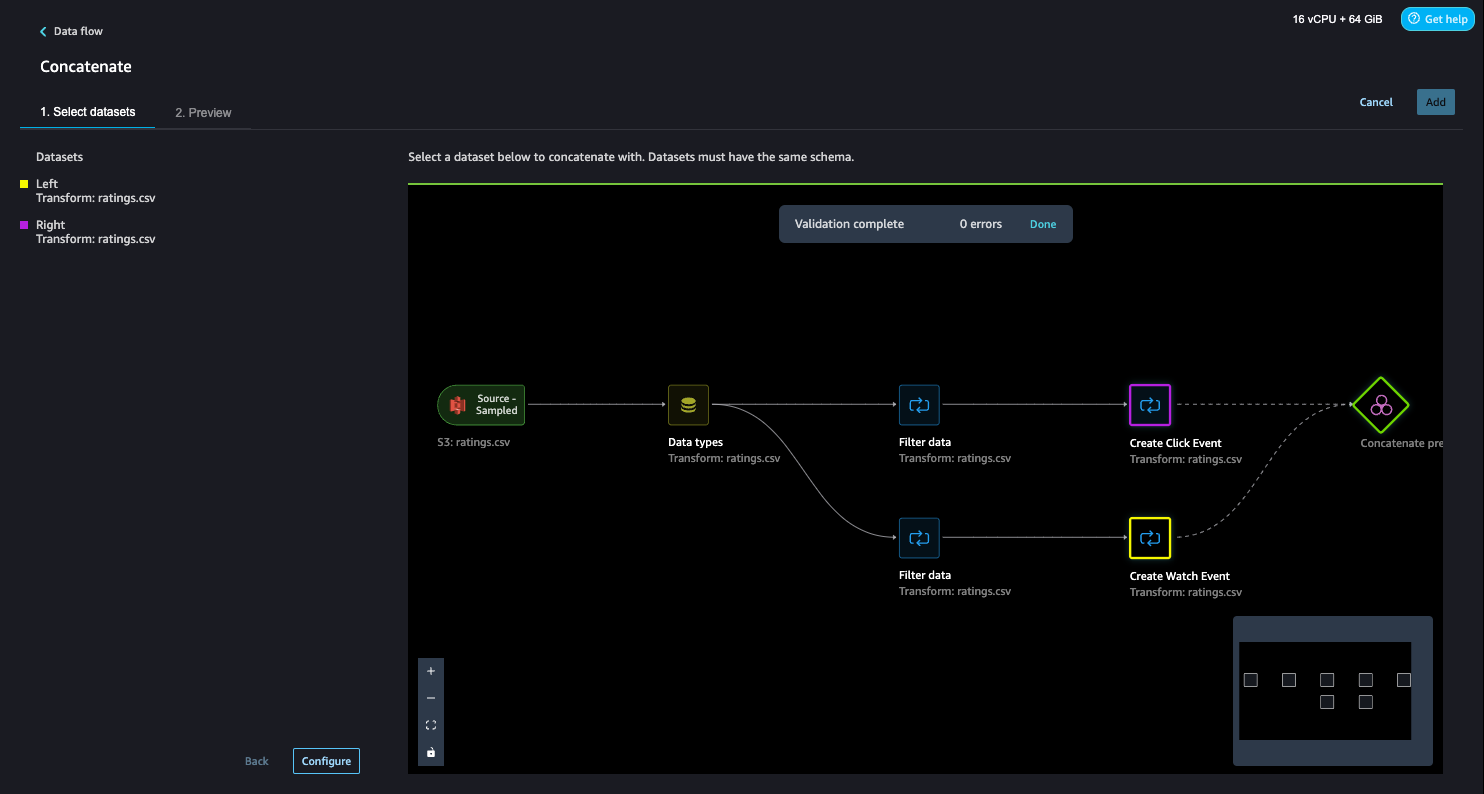
- Select Configure to view a preview of the concatenated datasets.
- Add a reputation to the step.
- Select Add so as to add the step.
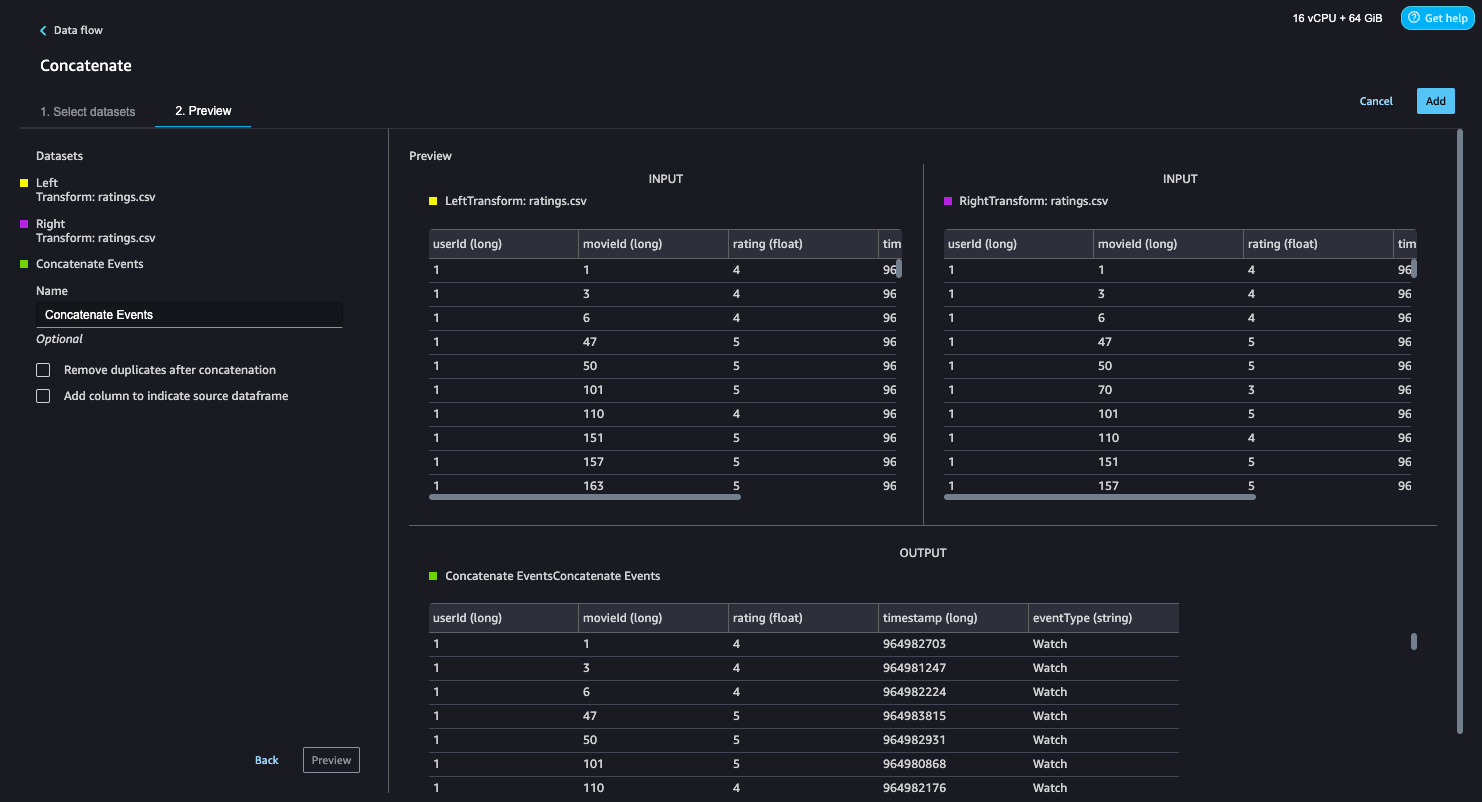
The info move now appears to be like like the next screenshot.
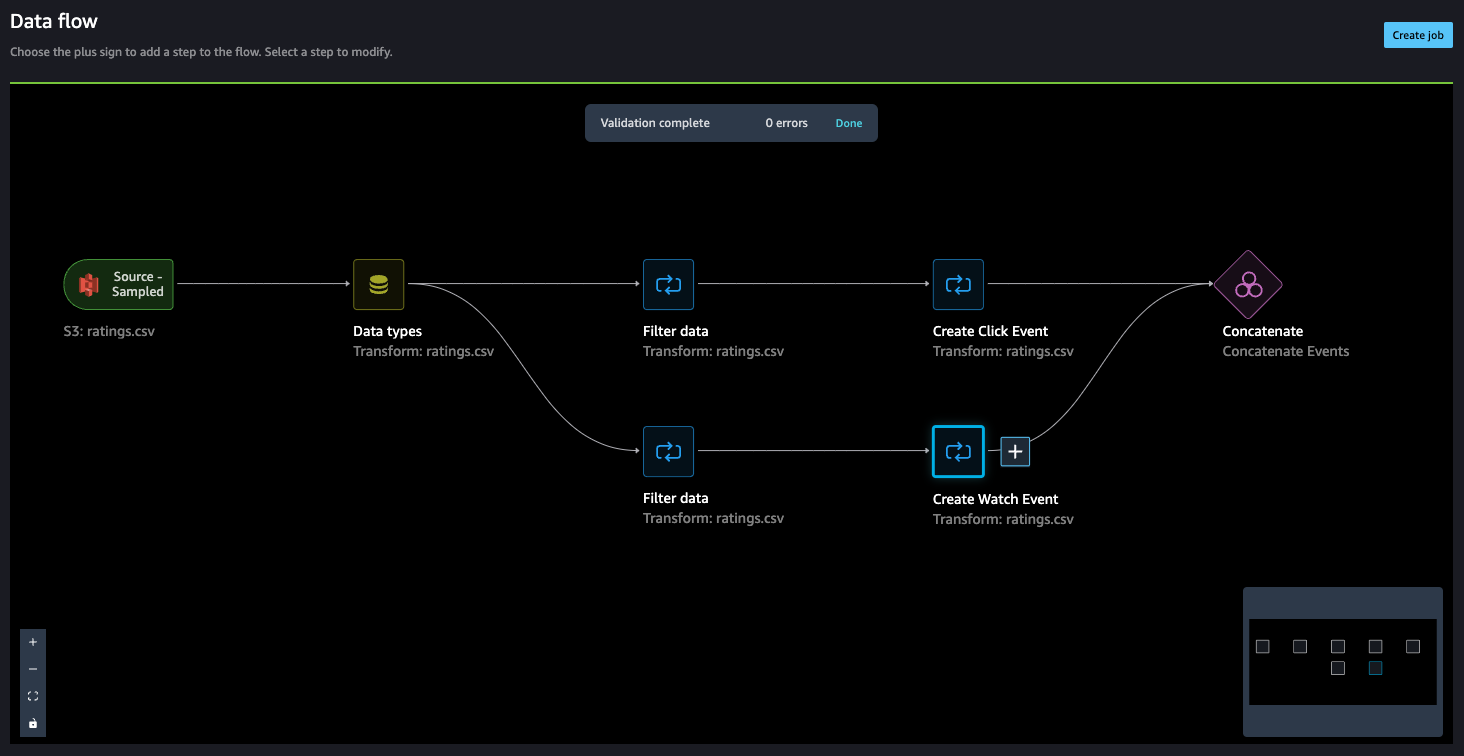
- Now, let’s add a Handle columns step to drop the unique score column.

Amazon Personalize has default column names for customers, gadgets, and timestamps. These default column names are user_id, item_id, and timestamp.
- Let’s add a Rework for Amazon Personalize step to exchange the present column headers with the default headers.
- In our case, we additionally use the
event_typesubject, so let’s map that as nicely.
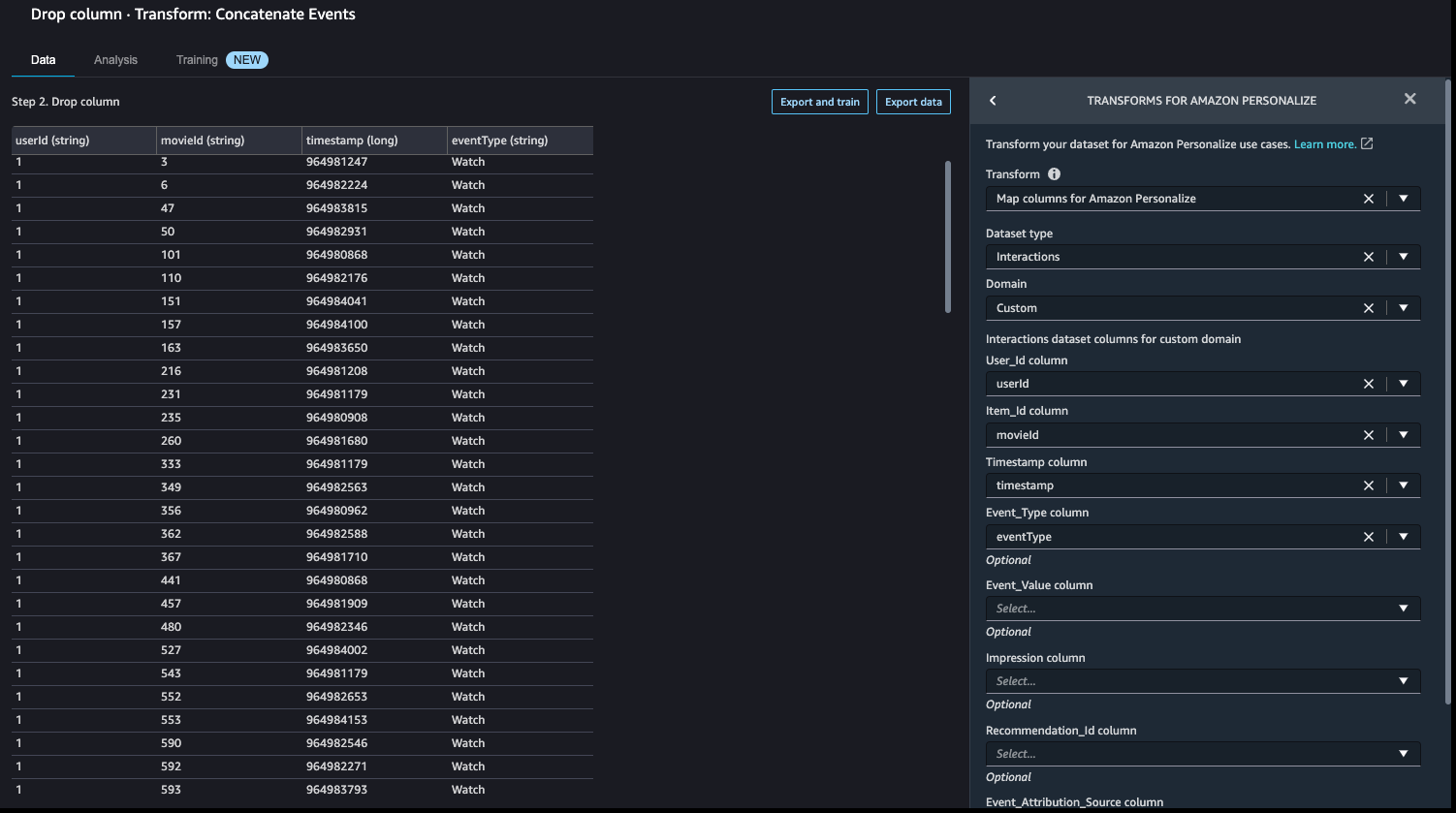
With this step, the information transformation exercise is full and the interactions dataset is prepared for the subsequent step.

Subsequent, let’s validate our timestamps.
- We will do that by including a Customized rework step. For this publish, we select Python (Consumer-Outlined Perform).
- Select timestamp because the enter column and because the output, create a brand new column referred to as
readable_timestamp. - Select Python because the mode for the transformation and insert the next code for the Python perform:
- Select Preview to overview the modifications.

On this case, we see dates within the 2000s—as a result of MovieLens began accumulating information in 1996, this aligns with what is predicted. If we don’t select Add, this transformation received’t be added to our information move.
- As a result of this was merely a sanity examine, you’ll be able to navigate again to the information move by selecting Knowledge move within the higher left nook.

Lastly, we add an evaluation step to create a abstract report in regards to the dataset. This step performs an evaluation to evaluate the suitability of the dataset for Amazon Personalize.
- Select the plus signal subsequent to the ultimate step on the information move and select Add evaluation.
- For Evaluation sort¸ select Knowledge High quality And Insights Report for Amazon Personalize.
- For Dataset sort¸ select Interactions.
- Select Create.
The MovieLens dataset is sort of clear, so the evaluation reveals no points. If some points had been recognized, you’ll be able to iterate on the dataset and rerun the evaluation till you’ll be able to tackle them.
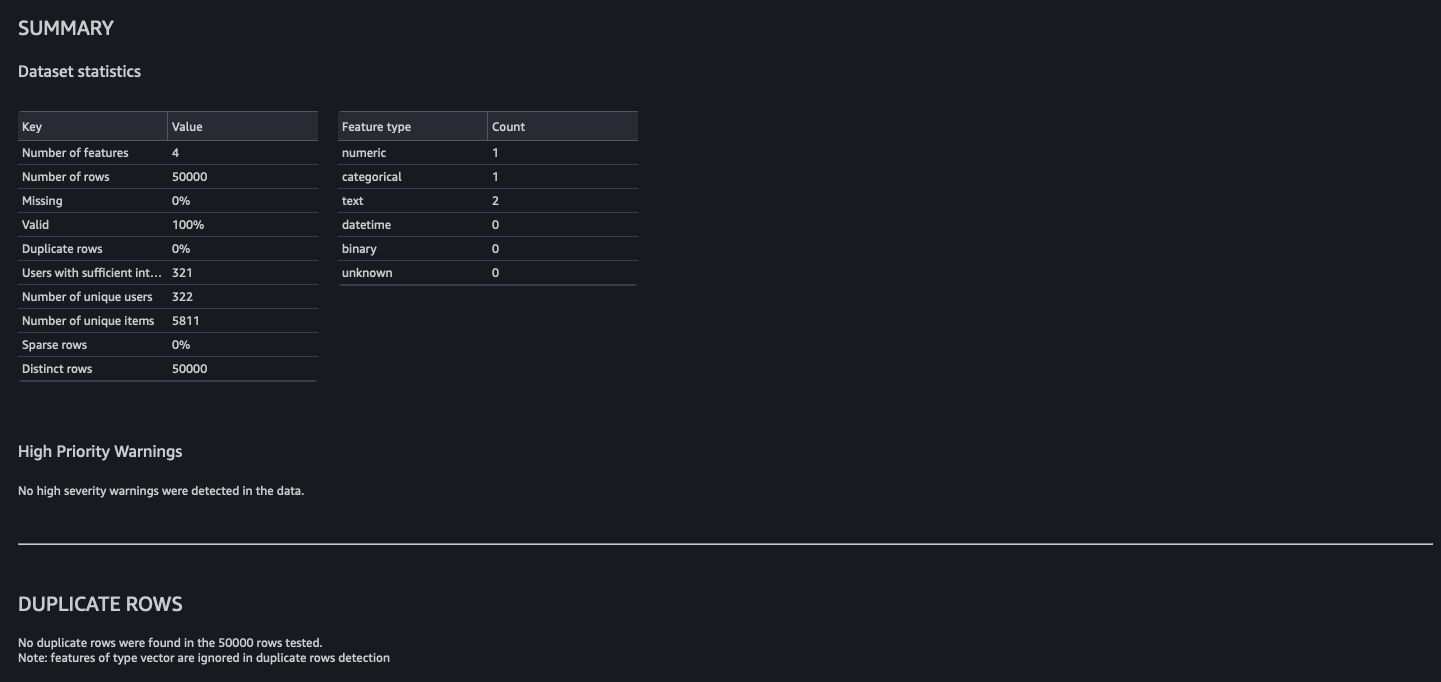
Observe the evaluation by default runs on a pattern of fifty,000 rows.
Import the dataset to Amazon Personalize
At this level, our uncooked information has been reworked and we’re able to import the reworked interactions dataset to Amazon Personalize. SageMaker Knowledge Wrangler offers you the flexibility to export your information to a location inside an S3 bucket. You’ll be able to specify the situation utilizing one of many following strategies:
- Vacation spot node – The place SageMaker Knowledge Wrangler shops the information after it has processed it
- Export to – Exports the information ensuing from a change to Amazon S3
- Export information – For small datasets, you’ll be able to rapidly export the information that you just’ve reworked
With the Vacation spot node technique, to export your information, you create vacation spot nodes and a SageMaker Knowledge Wrangler job. Making a SageMaker Knowledge Wrangler job begins a SageMaker Processing job to export your move. You’ll be able to select the vacation spot nodes that you just need to export after you’ve created them.
- Select the plus signal subsequent to the node that represents the transformations you need to export.
- Select Export to after which select Amazon S3 (by way of Jupyter Pocket book).
Observe we may have additionally chosen to export the information to Amazon Personalize by way of a Jupyter pocket book obtainable in SageMaker Knowledge Wrangler.
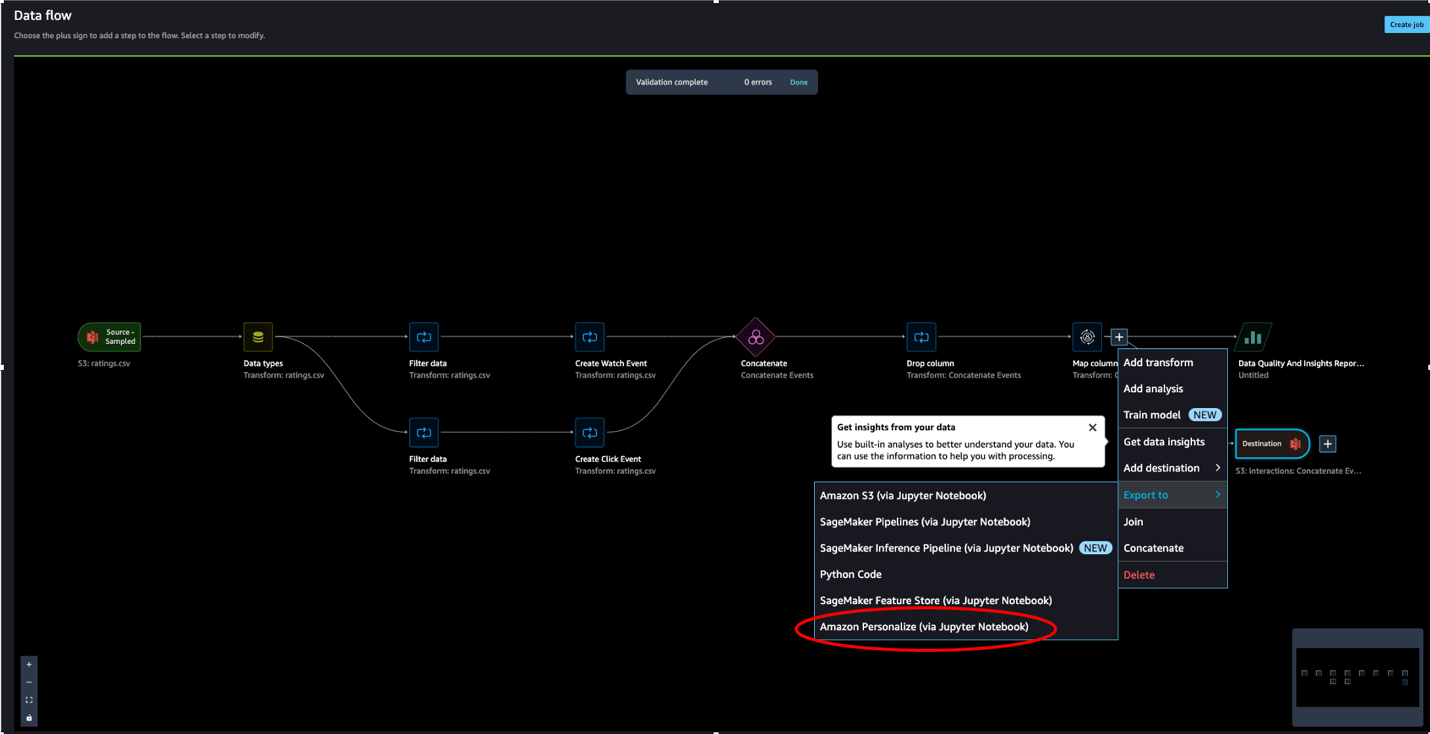
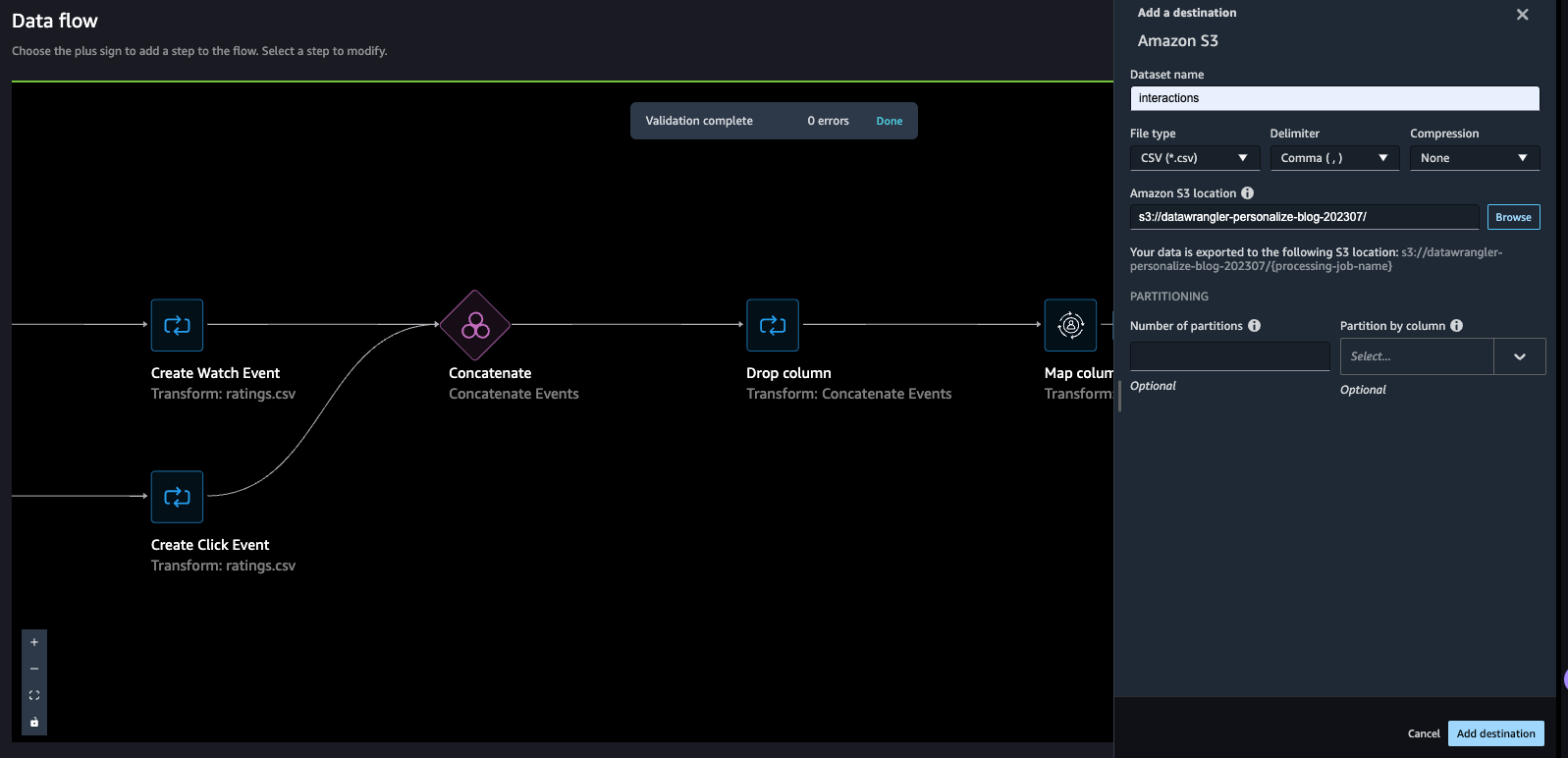
- For Dataset title, enter a reputation, which might be used as a folder title within the S3 bucket supplied as a vacation spot.
- You’ll be able to specify the file sort, subject delimiter, and compression technique.
- Optionally, specify the variety of partitions and column to partition by.
- Select Add vacation spot.
The info move ought to seem like the next screenshot.
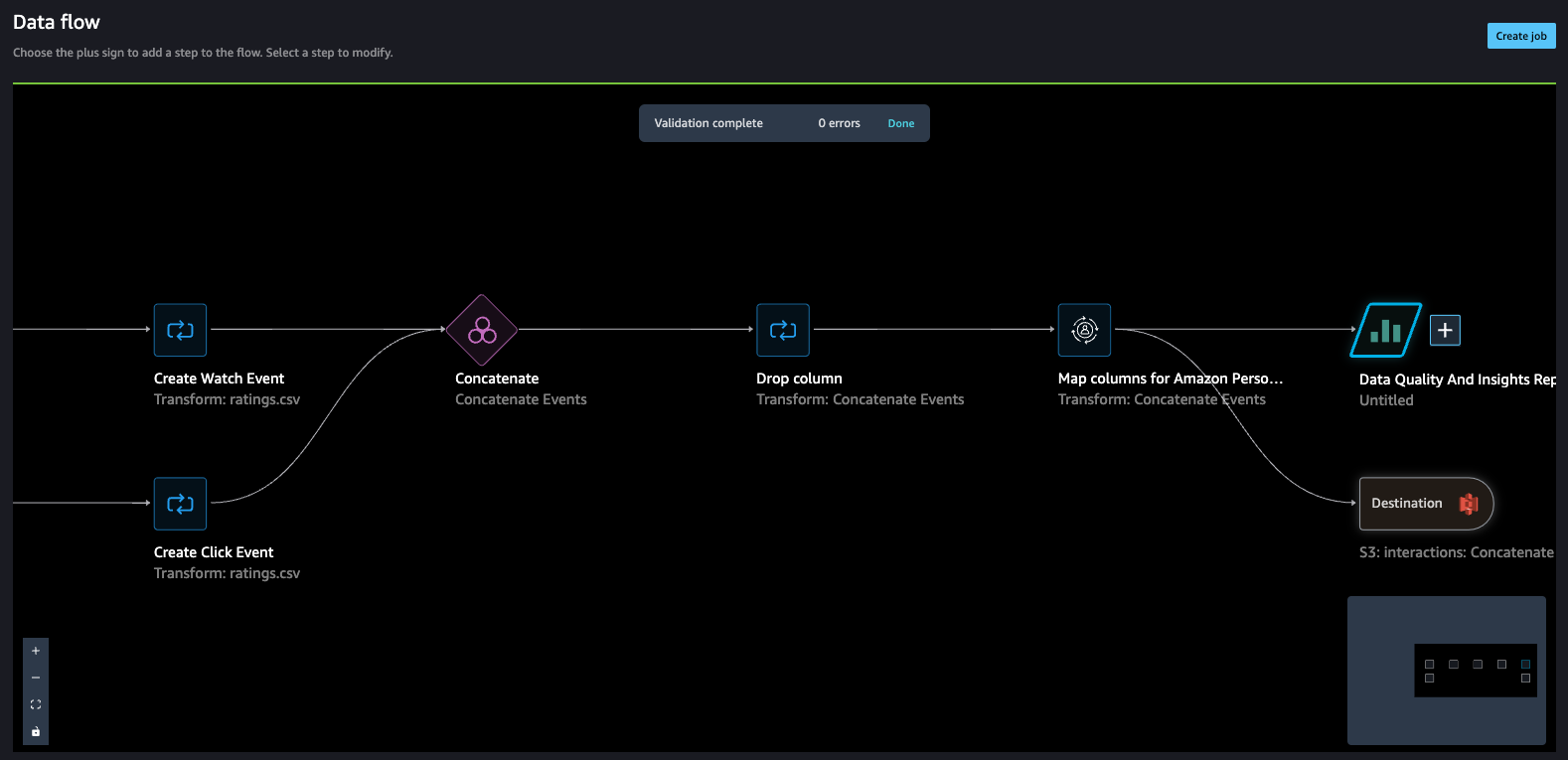
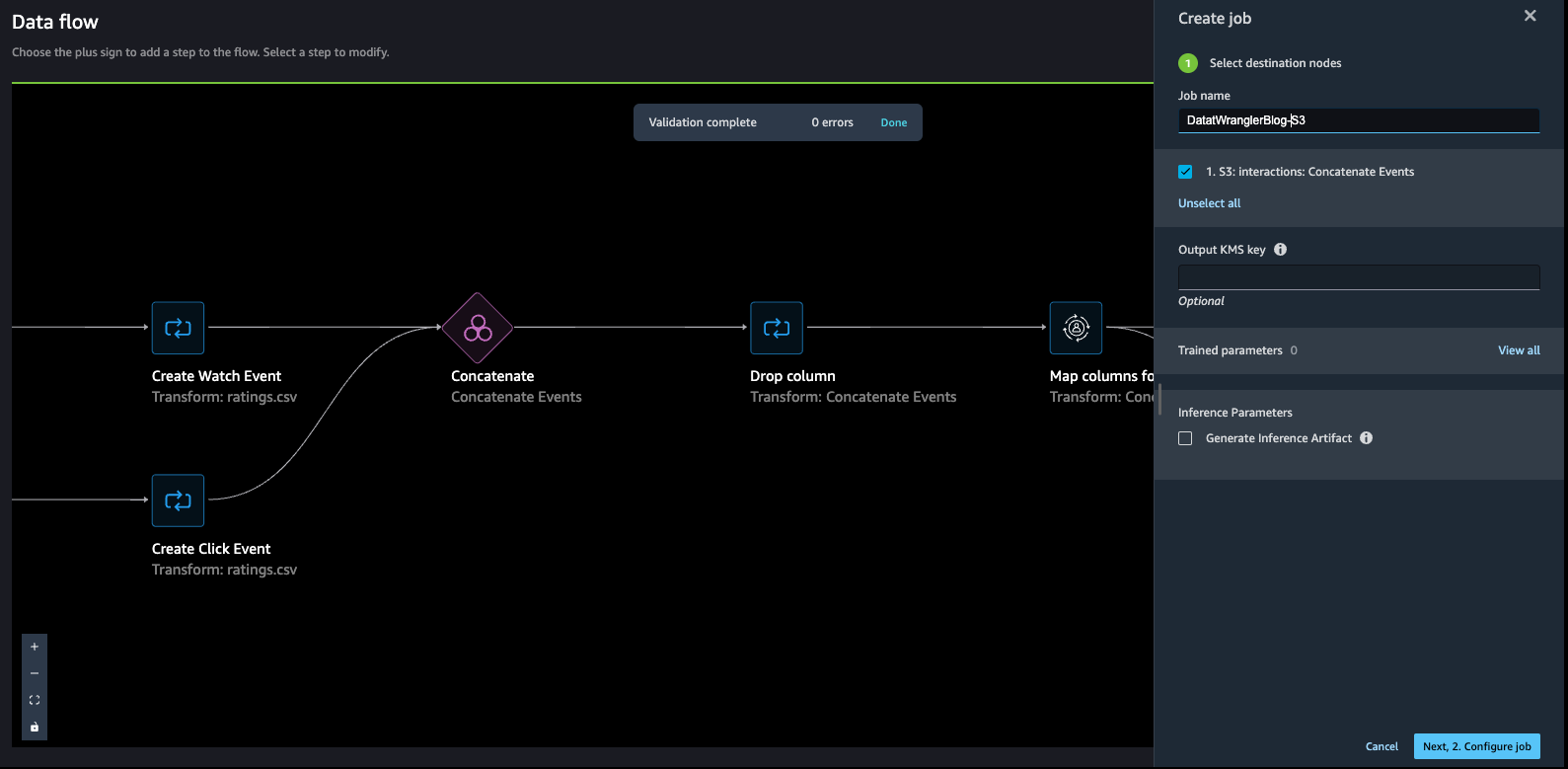
- Create a job to course of the information move and retailer the information within the vacation spot (S3 bucket) that we configured within the earlier step.
- Enter a job title, then select Configure job.
SageMaker Knowledge Wrangler supplies the flexibility to configure the occasion sort, occasion depend, and job configuration, and the flexibility to create a schedule to course of the job. For steerage on how to decide on an occasion depend, check with Create and Use a Data Wrangler Flow.
To observe the standing of the job, navigate to the Dashboard web page on the SageMaker console. The Processing part reveals the variety of accomplished and created jobs. You’ll be able to drill right down to get extra particulars in regards to the accomplished job.
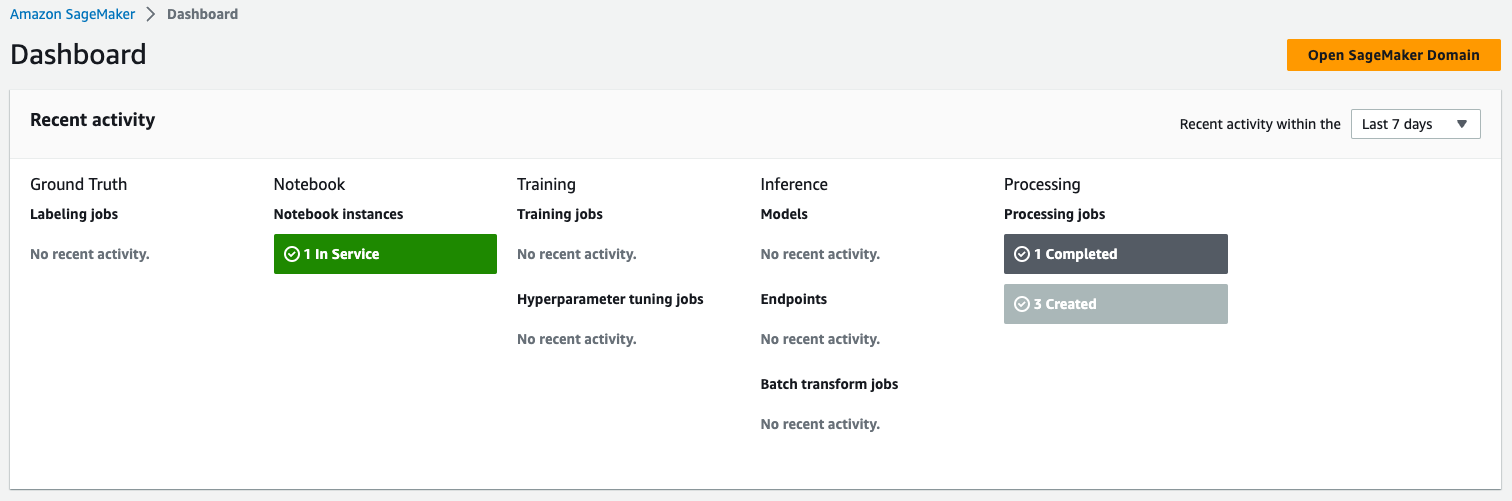
When the job is full, a brand new file of the reworked information is created within the vacation spot specified.
- Return to the Amazon Personalize console and navigate to the dataset group to import one other dataset.
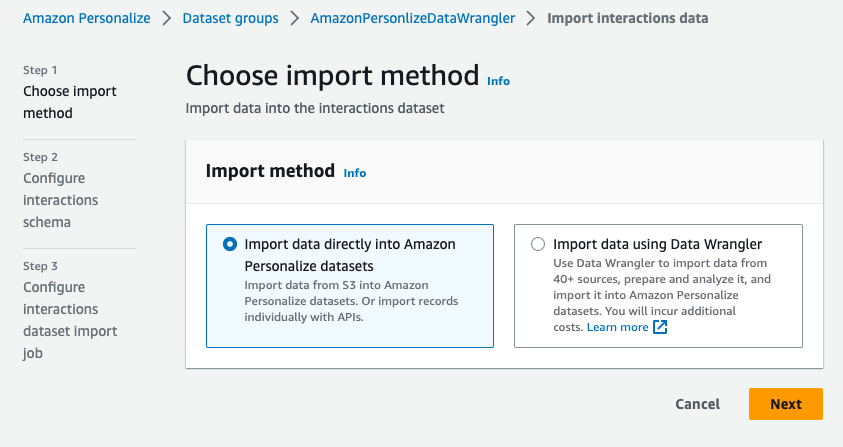
- Select Import interplay information.

- Choose Import information immediately into Amazon Personalize datasets to import the reworked dataset immediately from Amazon S3, then select Subsequent.
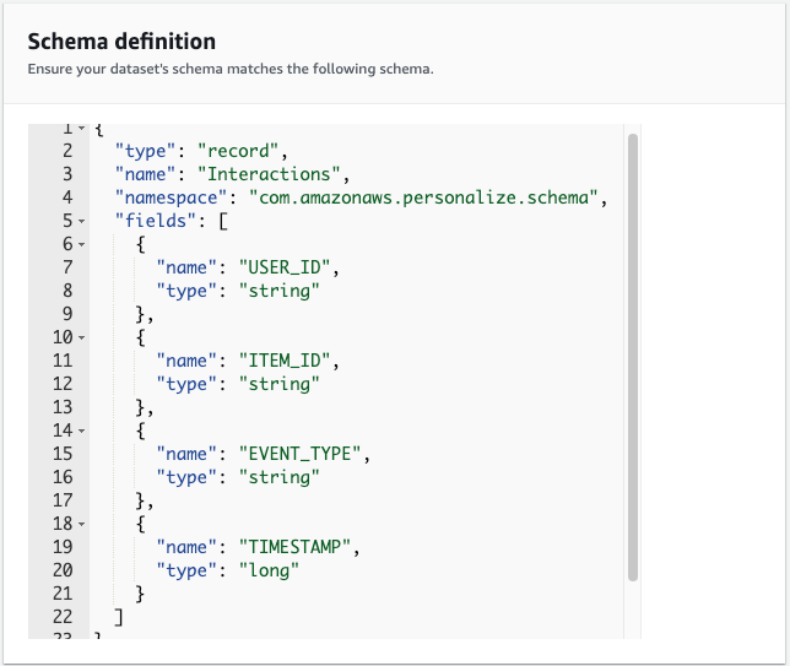
- Outline the schema. For this publish, our case our dataset consists of the
user_id(string),item_id(string),event_type(string), andtimestamp(lengthy) fields.
At this level, you’ll be able to create a video on demand area recommender or a customized resolution. To take action, observe the steps in Preparing and importing data
Conclusion
On this publish, we described tips on how to use SageMaker Knowledge Wrangler to arrange a pattern dataset for Amazon Personalize. SageMaker Knowledge Wrangler affords over 300 transformations. These transformations and the flexibility so as to add customized person transformations can assist streamline the method of making a high quality dataset to supply hyper-personalized content material to end-users.
Though we solely explored tips on how to put together an interactions dataset on this publish, you should utilize SageMaker Knowledge Wrangler to arrange person and merchandise datasets as nicely. For extra data on the varieties of information that can be utilized with Amazon Personalize, check with Datasets and schemas.
If you happen to’re new to Amazon Personalize or SageMaker Knowledge Wrangler, check with Get Started with Amazon Personalize or Get Started with SageMaker Data Wrangler, respectively. When you’ve got any questions associated to this publish, please add them within the feedback part.
Concerning the Authors
 Maysara Hamdan is a Companion Options Architect based mostly in Atlanta, Georgia. Maysara has over 15 years of expertise in constructing and architecting Software program Purposes and IoT Related Merchandise in Telecom and Automotive Industries. In AWS, Maysara helps companions in constructing their cloud practices and rising their companies. Maysara is obsessed with new applied sciences and is at all times searching for methods to assist companions innovate and develop.
Maysara Hamdan is a Companion Options Architect based mostly in Atlanta, Georgia. Maysara has over 15 years of expertise in constructing and architecting Software program Purposes and IoT Related Merchandise in Telecom and Automotive Industries. In AWS, Maysara helps companions in constructing their cloud practices and rising their companies. Maysara is obsessed with new applied sciences and is at all times searching for methods to assist companions innovate and develop.
 Eric Bolme is a Specialist Resolution Architect with AWS based mostly on the East Coast of the US. He has 8 years of expertise constructing out a wide range of deep studying and different AI use circumstances and focuses on Personalization and Advice use circumstances with AWS.
Eric Bolme is a Specialist Resolution Architect with AWS based mostly on the East Coast of the US. He has 8 years of expertise constructing out a wide range of deep studying and different AI use circumstances and focuses on Personalization and Advice use circumstances with AWS.
References
[1] Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: Historical past and Context. ACM Transactions on Interactive Clever Methods (TiiS) 5, 4, Article 19 (December 2015), 19 pages. DOI=http://dx.doi.org/10.1145/2827872



