Enhancing asset well being and grid resilience utilizing machine studying

This publish is co-written with Travis Bronson, and Brian L Wilkerson from Duke Vitality
Machine studying (ML) is remodeling each business, course of, and enterprise, however the path to success shouldn’t be all the time simple. On this weblog publish, we exhibit how Duke Energy, a Fortune 150 firm headquartered in Charlotte, NC., collaborated with the AWS Machine Learning Solutions Lab (MLSL) to make use of pc imaginative and prescient to automate the inspection of picket utility poles and assist stop energy outages, property injury and even accidents.
The electrical grid is made up of poles, traces and energy crops to generate and ship electrical energy to tens of millions of houses and companies. These utility poles are important infrastructure parts and topic to numerous environmental components reminiscent of wind, rain and snow, which might trigger put on and tear on belongings. It’s important that utility poles are repeatedly inspected and maintained to stop failures that may result in energy outages, property injury and even accidents. Most energy utility corporations, together with Duke Vitality, use guide visible inspection of utility poles to identifyanomalies associated to their transmission and distribution community. However this methodology will be costlyand time-consuming, and it requires that energy transmission lineworkers observe rigorous security protocols.
Duke Vitality has used synthetic intelligence previously to create efficiencies in day-to-day operations to nice success. The corporate has used AI to examine technology belongings and important infrastructure and has been exploring alternatives to use AI to the inspection of utility poles as effectively. Over the course of the AWS Machine Studying Options Lab engagement with Duke Vitality, the utility progressed its work to automate the detection of anomalies in wooden poles utilizing superior pc imaginative and prescient methods.
Targets and use case
The aim of this engagement between Duke Vitality and the Machine Studying Options Lab is to leverage machine studying to examine lots of of 1000’s of high-resolution aerial pictures to automate the identification and overview technique of all wooden pole-related points throughout 33,000 miles of transmission traces. This aim will additional assist Duke Vitality to enhance grid resiliency and adjust to authorities laws by figuring out the defects in a well timed method. It’s going to additionally cut back gasoline and labor prices, in addition to cut back carbon emissions by minimizing pointless truck rolls. Lastly, it can additionally enhance security by minimizing miles pushed, poles climbed and bodily inspection dangers related to compromising terrain and climate situations.
Within the following sections, we current the important thing challenges related to creating strong and environment friendly fashions for anomaly detection associated to wooden utility poles. We additionally describe the important thing challenges and suppositions related to varied knowledge preprocessing methods employed to attain the specified mannequin efficiency. Subsequent, we current the important thing metrics used for evaluating the mannequin efficiency together with the analysis of our remaining fashions. And eventually, we examine varied state-of-the-art supervised and unsupervised modeling methods.
Challenges
One of many key challenges related to coaching a mannequin for detecting anomalies utilizing aerial pictures is the non-uniform picture sizes. The next determine exhibits the distribution of picture top and width of a pattern knowledge set from Duke Vitality. It may be noticed that the pictures have a considerable amount of variation by way of dimension. Equally, the scale of pictures additionally pose vital challenges. The scale of enter pictures are 1000’s of pixels broad and 1000’s of pixels lengthy. That is additionally not splendid for coaching a mannequin for identification of the small anomalous areas within the picture.

Distribution of picture top and width for a pattern knowledge set
Additionally, the enter pictures include a considerable amount of irrelevant background info reminiscent of vegetation, vehicles, cattle, and so forth. The background info might lead to suboptimal mannequin efficiency. Based mostly on our evaluation, solely 5% of the picture comprises the wooden poles and the anomalies are even smaller. This a serious problem for figuring out and localizing anomalies within the high-resolution pictures. The variety of anomalies is considerably smaller, in comparison with your entire knowledge set. There are solely 0.12% of anomalous pictures in your entire knowledge set (i.e., 1.2 anomalies out of 1000 pictures). Lastly, there isn’t any labeled knowledge obtainable for coaching a supervised machine studying mannequin. Subsequent, we describe how we tackle these challenges and clarify our proposed methodology.
Answer overview
Modeling methods
The next determine demonstrates our picture processing and anomaly detection pipeline. We first imported the info into Amazon Simple Storage Service (Amazon S3) utilizing Amazon SageMaker Studio. We additional employed varied knowledge processing methods to deal with a few of the challenges highlighted above to enhance the mannequin efficiency. After knowledge preprocessing, we employed Amazon Rekognition Custom Labels for knowledge labeling. The labeled knowledge is additional used to coach supervised ML fashions reminiscent of Imaginative and prescient Transformer, Amazon Lookout for Vision, and AutoGloun for anomaly detection.

Picture processing and anomaly detection pipeline
The next determine demonstrates the detailed overview of our proposed method that features the info processing pipeline and varied ML algorithms employed for anomaly detection. First, we’ll describe the steps concerned within the knowledge processing pipeline. Subsequent, we’ll clarify the small print and instinct associated to numerous modeling methods employed throughout this engagement to attain the specified efficiency targets.
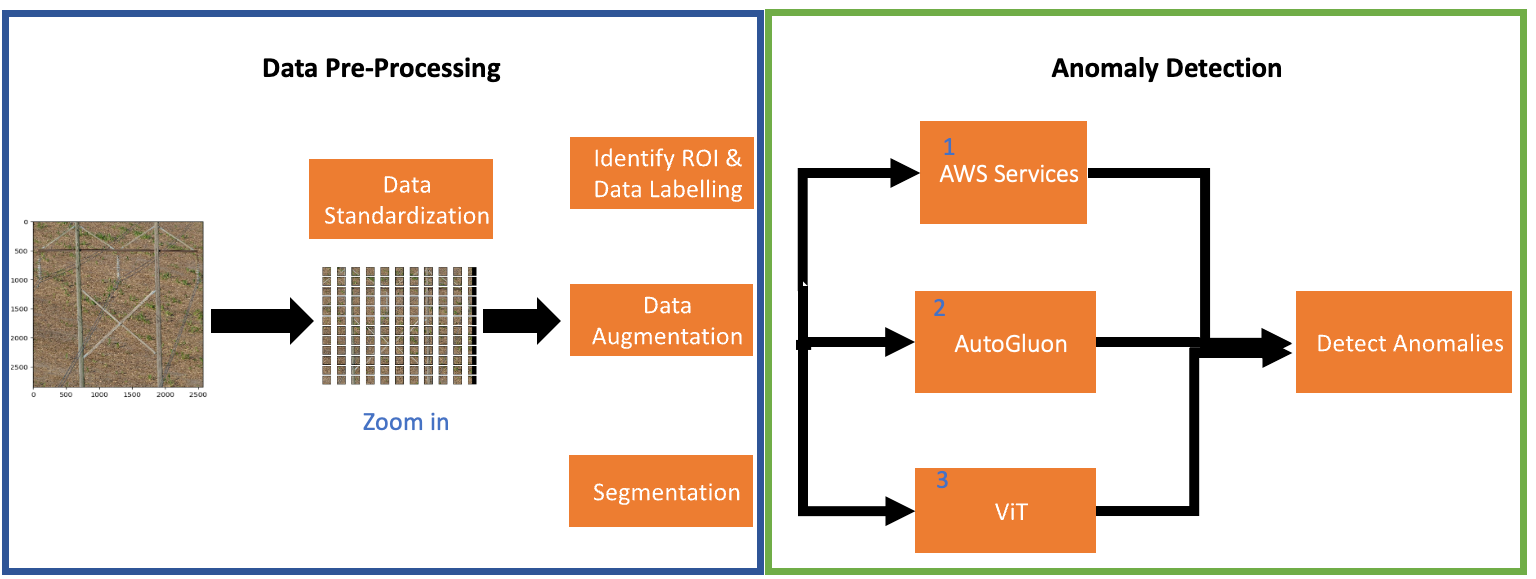
Information preprocessing
The proposed knowledge preprocessing pipeline contains knowledge standardization, identification of area of curiosity (ROI), knowledge augmentation, knowledge segmentation, and lastly knowledge labeling. The aim of every step is described beneath:
Information standardization
Step one in our knowledge processing pipeline contains knowledge standardization. On this step, every picture is cropped and divided into non overlapping patches of dimension 224 X 224 pixels. The aim of this step is to generate patches of uniform sizes that may very well be additional utilized for coaching a ML mannequin and localizing the anomalies in excessive decision pictures.
Identification of area of curiosity (ROI)
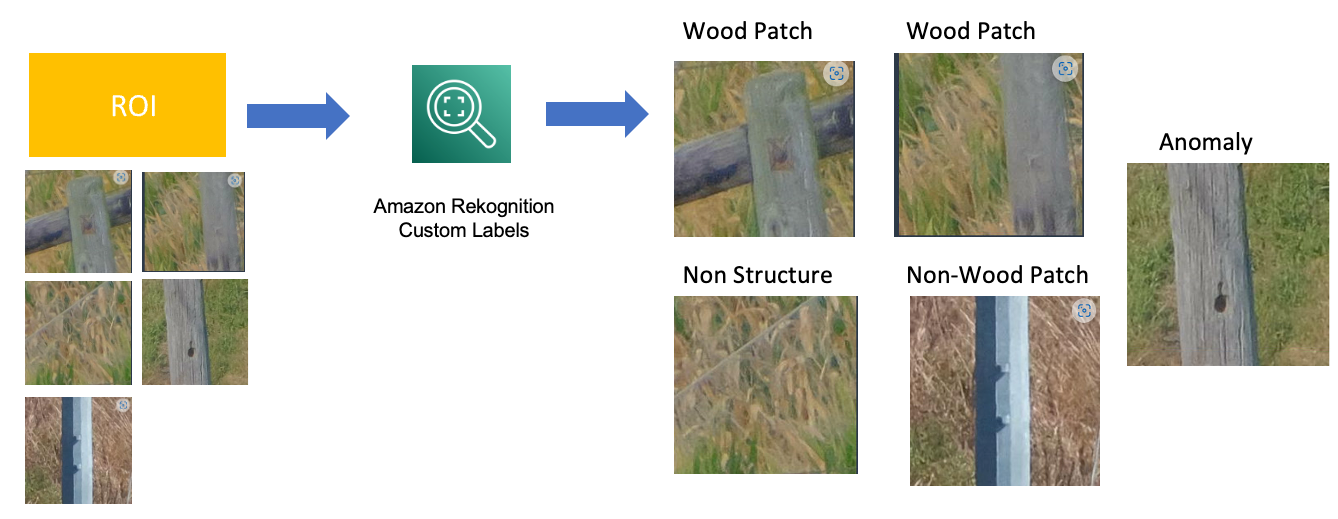
The enter knowledge consists of high-resolution pictures containing great amount of irrelevant background info (i.e., vegetation, homes, vehicles, horses, cows, and so forth.). Our aim is to establish anomalies associated to wooden poles. So as to establish the ROI (i.e., patches containing the wooden pole), we employed Amazon Rekognition customized labeling. We educated an Amazon Rekognition customized label mannequin utilizing 3k labeled pictures containing each ROI and background pictures. The aim of the mannequin is to do a binary classification between the ROI and background pictures. The patches recognized as background info are discarded whereas the crops predicted as ROI are used within the subsequent step. The next determine demonstrates the pipeline that identifies the ROI. We generated a pattern of non-overlapping crops of 1,110 picket pictures that generated 244,673 crops. We additional used these pictures as enter to an Amazon Rekognition customized mannequin that recognized 11,356 crops as ROI. Lastly, we manually verified every of those 11,356 patches. In the course of the guide inspection, we recognized the mannequin was capable of appropriately predict 10,969 wooden patches out of 11,356 as ROI. In different phrases, the mannequin achieved 96% precision.

Identification of area of curiosity
Information labeling
In the course of the guide inspection of the pictures, we additionally labeled every picture with their related labels. The related labels of pictures embody wooden patch, non-wood patch, non-structure, non-wood patch and eventually wooden patches with anomalies. The next determine demonstrates the nomenclature of the pictures utilizing Amazon Rekognition customized labeling.
Information augmentation
Given the restricted quantity of labeled knowledge that was obtainable for coaching, we augmented the coaching knowledge set by making horizontal flips of all the patches. This had the efficient impression of doubling the scale of our knowledge set.
Segmentation
We labeled the objects in 600 pictures (poles, wires, and steel railing) utilizing the bounding field object detection labeling device in Amazon Rekognition Customized Labels and educated a mannequin to detect the three fundamental objects of curiosity. We used the educated mannequin to take away the background from all the pictures, by figuring out and extracting the poles in every picture, whereas eradicating the all different objects in addition to the background. The ensuing dataset had fewer pictures than the unique knowledge set, on account of eradicating all pictures that don’t include wooden poles. As well as, there was additionally a false constructive picture that had been faraway from the dataset.
Anomaly detection
Subsequent, we use the preprocessed knowledge for coaching the machine studying mannequin for anomaly detection. We employed three totally different strategies for anomaly detection which incorporates AWS Managed Machine Studying Providers (Amazon Lookout for Imaginative and prescient [L4V], Amazon Rekognition), AutoGluon, and Imaginative and prescient Transformer based mostly self-distillation methodology.
AWS Providers
Amazon Lookout for Imaginative and prescient (L4V)
Amazon Lookout for Imaginative and prescient is a managed AWS service that allows swift coaching and deployment of ML fashions and gives anomaly detection capabilities. It requires absolutely labelled knowledge, which we offered by pointing to the picture paths in Amazon S3. Coaching the mannequin is as a easy as a single API (Utility programming interface) name or console button click on and L4V takes care of mannequin choice and hyperparameter tuning beneath the hood.
Amazon Rekognition
Amazon Rekognition is a managed AI/ML service much like L4V, which hides modelling particulars and gives many capabilities reminiscent of picture classification, object detection, customized labelling, and extra. It gives the power to make use of the built-in fashions to use to beforehand identified entities in pictures (e.g., from ImageNet or different massive open datasets). Nonetheless, we used Amazon Rekognition’s Customized Labels performance to coach the ROI detector, in addition to an anomaly detector on the particular pictures that Duke Vitality has. We additionally used the Amazon Rekognition’s Customized Labels to coach a mannequin to place bounding bins round wooden poles in every picture.
AutoGloun
AutoGluon is an open-source machine studying method developed by Amazon. AutoGluon features a multi-modal element which permits straightforward coaching on picture knowledge. We used AutoGluon Multi-modal to coach fashions on the labelled picture patches to ascertain a baseline for figuring out anomalies.
Imaginative and prescient Transformer
Lots of the most enjoyable new AI breakthroughs have come from two latest improvements: self-supervised studying, which permits machines to be taught from random, unlabeled examples; and Transformers, which allow AI fashions to selectively deal with sure elements of their enter and thus purpose extra successfully. Each strategies have been a sustained focus for the Machine studying neighborhood, and we’re happy to share that we used them on this engagement.
Specifically, working in collaboration with researchers at Duke Vitality, we used pre-trained self-distillation ViT (Imaginative and prescient Transformer) fashions as function extractors for the downstream anomaly detection utility utilizing Amazon Sagemaker. The pre-trained self-distillation imaginative and prescient transformer fashions are educated on great amount of coaching knowledge saved on Amazon S3 in a self-supervised method utilizing Amazon SageMaker. We leverage the switch studying capabilities of ViT fashions pre-trained on massive scale datasets (e.g., ImageNet). This helped us obtain a recall of 83% on an analysis set utilizing just a few 1000’s of labeled pictures for coaching.
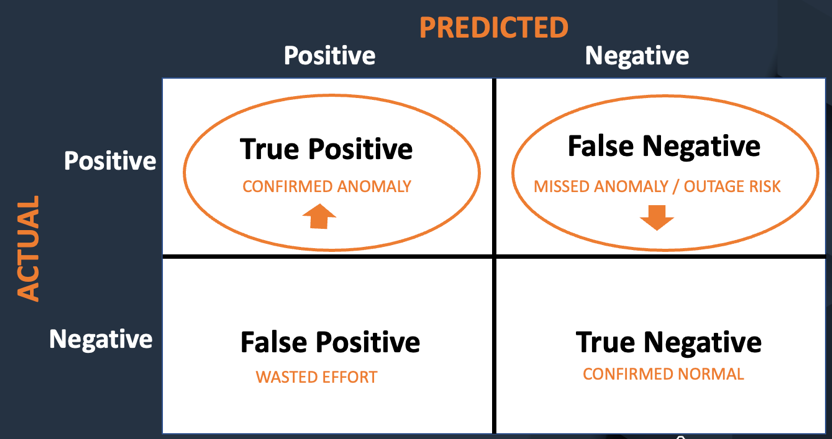
Analysis metrics
The next determine exhibits the important thing metrics used to judge mannequin efficiency and its impacts. The important thing aim of the mannequin is to maximise anomaly detection (i.e. true positives) and decrease the variety of false negatives, or occasions when the anomalies that would result in outages are beingmisclassified.
As soon as the anomalies are recognized, technicians can tackle them, stopping future outages and making certain compliance with authorities laws. There’s one other profit to minimizing false positives: you keep away from the pointless effort of going via pictures once more.
Conserving these metrics in thoughts, we monitor the mannequin efficiency by way of following metrics, which encapsulates all 4 metrics outlined above.
Precision
The p.c of anomalies detected which can be precise anomalies for objects of curiosity. Precision measures how effectively our algorithm identifies solely anomalies. For this use case, excessive precision means low false alarms (i.e., the algorithm falsely identifies a woodpecker gap whereas there isn’t any within the picture).
![]()
Recall
The p.c of all anomalies which can be recovered for every object of curiosity. Recall measures how effectively we establish all anomalies. This set captures some proportion of the total set of anomalies, and that proportion is the recall. For this use case, excessive recall signifies that we’re good at catching woodpecker holes after they happen. Recall is due to this fact the fitting metric to deal with on this POC as a result of false alarms are at greatest annoying whereas missed anomalies might result in severe consequence if left unattended.
![]()
Decrease recall can result in outages and authorities regulation violations. Whereas decrease precision results in wasted human effort. The first aim of this engagement is to establish all of the anomalies to adjust to authorities regulation and keep away from any outage, therefore we prioritize bettering recall over precision.
Analysis and mannequin comparability
Within the following part, we exhibit the comparability of assorted modeling methods employed throughout this engagement. We evaluated the efficiency of two AWS companies Amazon Rekognition and Amazon Lookout for Imaginative and prescient. We additionally evaluated varied modeling methods utilizing AutoGluon. Lastly, we examine the efficiency with state-of-the-art ViT based mostly self-distillation methodology.
The next determine exhibits the mannequin enchancment for the AutoGluon utilizing totally different knowledge processing methods over the interval of this engagement. The important thing remark is as we enhance the info high quality and amount the efficiency of the mannequin by way of recall improved from beneath 30% to 78%.
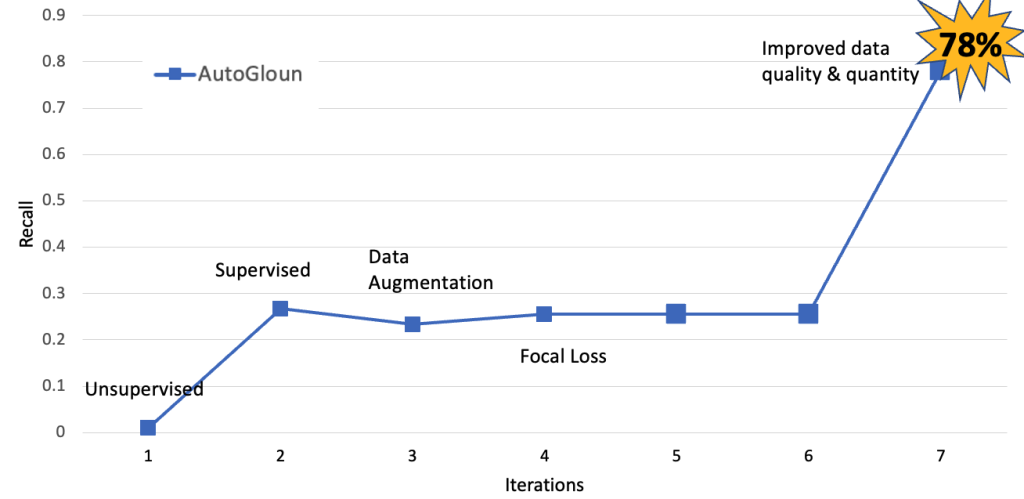
Subsequent, we examine the efficiency of AutoGluon with AWS companies. We additionally employed varied knowledge processing methods that helped enhance the efficiency. Nonetheless, the main enchancment got here from growing the info amount and high quality. We enhance the dataset dimension from 11 Okay pictures in complete to 60 Okay pictures.
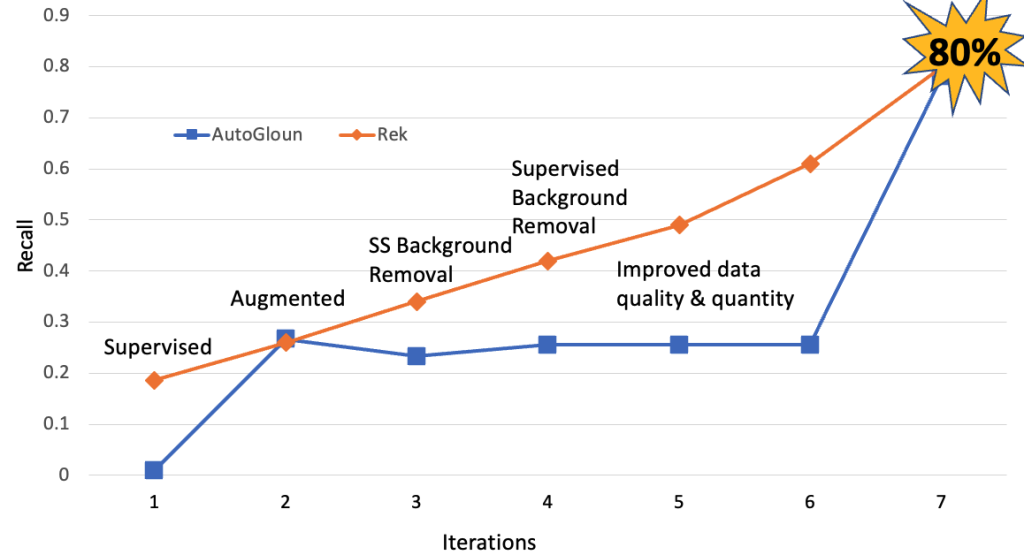
Subsequent, we examine the efficiency of AutoGluon and AWS companies with ViT based mostly methodology. The next determine demonstrates that ViT-based methodology, AutoGluon and AWS companies carried out on par by way of recall. One key remark is, past a sure level, enhance in knowledge high quality and amount doesn’t assist enhance the efficiency by way of recall. Nonetheless, we observe enhancements by way of precision.
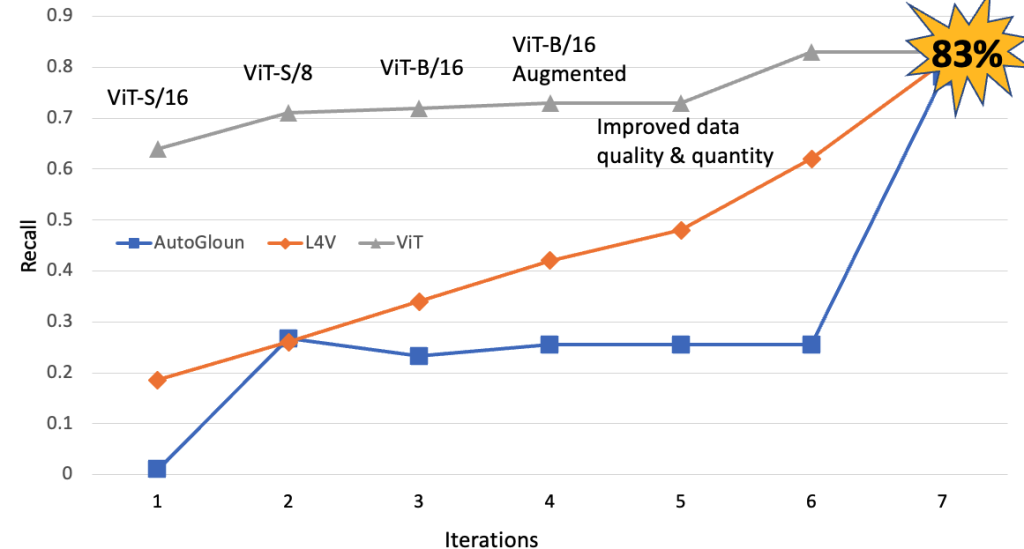
Precision versus recall comparability
| Amazon AutoGluon | Predicted anomalies | Predicted regular |
| Anomalies | 15600 | 4400 |
| Regular | 3659 | 38341 |
Subsequent, we current the confusion matrix for AutoGluon and Amazon Rekognition and ViT based mostly methodology utilizing our dataset that comprises 62 Okay samples. Out of 62K samples, 20 Okay samples are anomalous whereas remaining 42 Okay pictures are regular. It may be noticed that ViT based mostly strategies captures largest variety of anomalies (16,600) adopted by Amazon Rekognition (16,000) and Amazon AutoGluon (15600). Equally, Amazon AutoGluon has least variety of false positives (3659 pictures) adopted by Amazon Rekognition (5918) and ViT (15323). These outcomes demonstrates that Amazon Rekognition achieves the very best AUC (space beneath the curve).
| Amazon Rekognition | Predicted anomalies | Predicted regular |
| Anomalies | 16,000 | 4000 |
| Regular | 5918 | 36082 |
| ViT | Predicted anomalies | Predicted regular |
| Anomalies | 16,600 | 3400 |
| Regular | 15,323 | 26,677 |
Conclusion
On this publish, we confirmed you ways the MLSL and Duke Vitality groups labored collectively to develop a pc vision-based resolution to automate anomaly detection in wooden poles utilizing excessive decision pictures collected by way of helicopter flights. The proposed resolution employed an information processing pipeline to crop the high-resolution picture for dimension standardization. The cropped pictures are additional processed utilizing Amazon Rekognition Customized Labels to establish the area of curiosity (i.e., crops containing the patches with poles). Amazon Rekognition achieved 96% precision by way of appropriately figuring out the patches with poles. The ROI crops are additional used for anomaly detection utilizing ViT based mostly self-distillation mdoel AutoGluon and AWS companies for anomaly detection. We used an ordinary knowledge set to judge the efficiency of all three strategies. The ViT based mostly mannequin achieved 83% recall and 52% precision. AutoGluon achieved 78% recall and 81% precision. Lastly, Amazon Rekognition achieves 80% recall and 73% precision. The aim of utilizing three totally different strategies is to match the efficiency of every methodology with totally different variety of coaching samples, coaching time, and deployment time. All these strategies take lower than 2 hours to coach a and deploy utilizing a single A100 GPU occasion or managed companies on Amazon AWS. Subsequent, steps for additional enchancment in mannequin efficiency embody including extra coaching knowledge for bettering mannequin precision.
Total, the end-to-end pipeline proposed on this publish assist obtain vital enhancements in anomaly detection whereas minimizing operations price, security incident, regulatory dangers, carbon emissions, and potential energy outages.
The answer developed will be employed for different anomaly detection and asset health-related use instances throughout transmission and distribution networks, together with defects in insulators and different tools. For additional help in creating and customizing this resolution, please be happy to get in contact with the MLSL workforce.
In regards to the Authors
 Travis Bronson is a Lead Synthetic Intelligence Specialist with 15 years of expertise in expertise and eight years particularly devoted to synthetic intelligence. Over his 5-year tenure at Duke Vitality, Travis has superior the applying of AI for digital transformation by bringing distinctive insights and artistic thought management to his firm’s vanguard. Travis at present leads the AI Core Staff, a neighborhood of AI practitioners, lovers, and enterprise companions centered on advancing AI outcomes and governance. Travis gained and refined his expertise in a number of technological fields, beginning within the US Navy and US Authorities, then transitioning to the non-public sector after greater than a decade of service.
Travis Bronson is a Lead Synthetic Intelligence Specialist with 15 years of expertise in expertise and eight years particularly devoted to synthetic intelligence. Over his 5-year tenure at Duke Vitality, Travis has superior the applying of AI for digital transformation by bringing distinctive insights and artistic thought management to his firm’s vanguard. Travis at present leads the AI Core Staff, a neighborhood of AI practitioners, lovers, and enterprise companions centered on advancing AI outcomes and governance. Travis gained and refined his expertise in a number of technological fields, beginning within the US Navy and US Authorities, then transitioning to the non-public sector after greater than a decade of service.
 Brian Wilkerson is an completed skilled with 20 years of expertise at Duke Vitality. With a level in pc science, he has spent the previous 7 years excelling within the discipline of Synthetic Intelligence. Brian is a co-founder of Duke Vitality’s MADlab (Machine Studying, AI and Deep studying workforce). Hecurrently holds the place of Director of Synthetic Intelligence & Transformation at Duke Vitality, the place he’s captivated with delivering enterprise worth via the implementation of AI.
Brian Wilkerson is an completed skilled with 20 years of expertise at Duke Vitality. With a level in pc science, he has spent the previous 7 years excelling within the discipline of Synthetic Intelligence. Brian is a co-founder of Duke Vitality’s MADlab (Machine Studying, AI and Deep studying workforce). Hecurrently holds the place of Director of Synthetic Intelligence & Transformation at Duke Vitality, the place he’s captivated with delivering enterprise worth via the implementation of AI.
 Ahsan Ali is an Utilized Scientist on the Amazon Generative AI Innovation Heart, the place he works with prospects from totally different domains to resolve their pressing and costly issues utilizing Generative AI.
Ahsan Ali is an Utilized Scientist on the Amazon Generative AI Innovation Heart, the place he works with prospects from totally different domains to resolve their pressing and costly issues utilizing Generative AI.
 Tahin Syed is an Utilized Scientist with the Amazon Generative AI Innovation Heart, the place he works with prospects to assist understand enterprise outcomes with generative AI options. Outdoors of labor, he enjoys attempting new meals, touring, and instructing taekwondo.
Tahin Syed is an Utilized Scientist with the Amazon Generative AI Innovation Heart, the place he works with prospects to assist understand enterprise outcomes with generative AI options. Outdoors of labor, he enjoys attempting new meals, touring, and instructing taekwondo.
 Dr. Nkechinyere N. Agu is an Utilized Scientist within the Generative AI Innovation Heart at AWS. Her experience is in Pc Imaginative and prescient AI/ML strategies, Functions of AI/ML to healthcare, in addition to the mixing of semantic applied sciences (Information Graphs) in ML options. She has a Masters and a Doctorate in Pc Science.
Dr. Nkechinyere N. Agu is an Utilized Scientist within the Generative AI Innovation Heart at AWS. Her experience is in Pc Imaginative and prescient AI/ML strategies, Functions of AI/ML to healthcare, in addition to the mixing of semantic applied sciences (Information Graphs) in ML options. She has a Masters and a Doctorate in Pc Science.
 Aldo Arizmendi is a Generative AI Strategist within the AWS Generative AI Innovation Heart based mostly out of Austin, Texas. Having acquired his B.S. in Pc Engineering from the College of Nebraska-Lincoln, over the past 12 years, Mr. Arizmendi has helped lots of of Fortune 500 corporations and start-ups rework their enterprise utilizing superior analytics, machine studying, and generative AI.
Aldo Arizmendi is a Generative AI Strategist within the AWS Generative AI Innovation Heart based mostly out of Austin, Texas. Having acquired his B.S. in Pc Engineering from the College of Nebraska-Lincoln, over the past 12 years, Mr. Arizmendi has helped lots of of Fortune 500 corporations and start-ups rework their enterprise utilizing superior analytics, machine studying, and generative AI.
 Stacey Jenks is a Principal Analytics Gross sales Specialist at AWS, with greater than 20 years of expertise in Analytics and AI/ML. Stacey is captivated with diving deep on buyer initiatives and driving transformational, measurable enterprise outcomes with knowledge. She is very enthusiastic concerning the mark that utilities will make on society, by way of their path to a greener planet with inexpensive, dependable, clear vitality.
Stacey Jenks is a Principal Analytics Gross sales Specialist at AWS, with greater than 20 years of expertise in Analytics and AI/ML. Stacey is captivated with diving deep on buyer initiatives and driving transformational, measurable enterprise outcomes with knowledge. She is very enthusiastic concerning the mark that utilities will make on society, by way of their path to a greener planet with inexpensive, dependable, clear vitality.
 Mehdi Noor is an Utilized Science Supervisor at Generative Ai Innovation Heart. With a ardour for bridging expertise and innovation, he assists AWS prospects in unlocking the potential of Generative AI, turning potential challenges into alternatives for speedy experimentation and innovation by specializing in scalable, measurable, and impactful makes use of of superior AI applied sciences, and streamlining the trail to manufacturing.
Mehdi Noor is an Utilized Science Supervisor at Generative Ai Innovation Heart. With a ardour for bridging expertise and innovation, he assists AWS prospects in unlocking the potential of Generative AI, turning potential challenges into alternatives for speedy experimentation and innovation by specializing in scalable, measurable, and impactful makes use of of superior AI applied sciences, and streamlining the trail to manufacturing.





