GPT-4: 8 Fashions in One; The Secret is Out
The GPT4 mannequin has been THE groundbreaking mannequin to date, obtainable to most people both without cost or by way of their industrial portal (for public beta use). It has labored wonders in igniting new undertaking concepts and use-cases for a lot of entrepreneurs however the secrecy in regards to the variety of parameters and the mannequin was killing all fans who had been betting on the primary 1 trillion parameter mannequin to 100 trillion parameter claims!
Nicely, the cat is out of the bag (Type of). On June twentieth, George Hotz, founding father of self-driving startup Comma.ai leaked that GPT-4 isn’t a single monolithic dense mannequin (like GPT-3 and GPT-3.5) however a mix of 8 x 220-billion-parameter fashions.
Later that day, Soumith Chintala, co-founder of PyTorch at Meta, reaffirmed the leak.
Simply the day earlier than, Mikhail Parakhin, Microsoft Bing AI lead, had additionally hinted at this.
What do all of the tweets imply? The GPT-4 is just not a single giant mannequin however a union/ensemble of 8 smaller fashions sharing the experience. Every of those fashions is rumored to be 220 Billion parameters.

The methodology known as a mix of specialists’ mannequin paradigms (linked under). It is a well-known methodology additionally referred to as as hydra of mannequin. It jogs my memory of Indian mythology I’ll go together with Ravana.
Please take it with a grain of salt that it isn’t official information however considerably high-ranking members within the AI group have spoken/hinted in the direction of it. Microsoft is but to substantiate any of those.
Now that now we have spoken in regards to the combination of specialists, let’s take a bit of little bit of a dive into what that factor is. The Combination of Consultants is an ensemble studying method developed particularly for neural networks. It differs a bit from the overall ensemble method from the traditional machine studying modeling (that type is a generalized type). So you possibly can contemplate that the Combination of Consultants in LLMs is a particular case for ensemble strategies.
Briefly, on this technique, a activity is split into subtasks, and specialists for every subtask are used to resolve the fashions. It’s a technique to divide and conquer method whereas creating resolution bushes. One might additionally contemplate it as meta-learning on prime of the professional fashions for every separate activity.
A smaller and higher mannequin may be educated for every sub-task or drawback sort. A meta-model learns to make use of which mannequin is healthier at predicting a selected activity. Meta learner/mannequin acts as a visitors cop. The sub-tasks could or could not overlap, which signifies that a mix of the outputs may be merged collectively to give you the ultimate output.
For the concept-descriptions from MOE to Pooling, all credit to the nice weblog by Jason Brownlee (https://machinelearningmastery.com/mixture-of-experts/). In case you like what you learn under, please please subscribe to Jason’s weblog and purchase a guide or two to assist his superb work!
Combination of specialists, MoE or ME for brief, is an ensemble studying method that implements the concept of coaching specialists on subtasks of a predictive modeling drawback.
Within the neural community group, a number of researchers have examined the decomposition methodology. […] Combination–of–Consultants (ME) methodology that decomposes the enter house, such that every professional examines a special a part of the house. […] A gating community is accountable for combining the assorted specialists.
— Web page 73, Pattern Classification Using Ensemble Methods, 2010.
There are 4 components to the method, they’re:
- Division of a activity into subtasks.
- Develop an professional for every subtask.
- Use a gating mannequin to resolve which professional to make use of.
- Pool predictions and gating mannequin output to make a prediction.
The determine under, taken from Web page 94 of the 2012 guide “Ensemble Methods,” gives a useful overview of the architectural components of the tactic.
How Do 8 Smaller Fashions in GPT4 Work?
The key “Mannequin of Consultants” is out, let’s perceive why GPT4 is so good!
ithinkbot.com
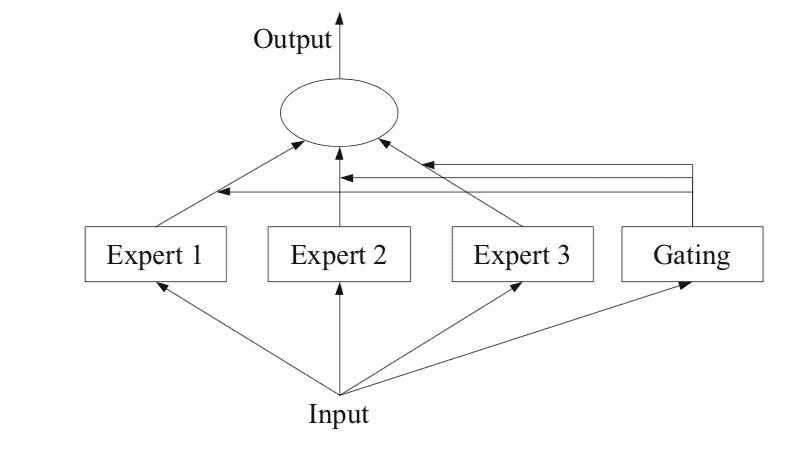
Instance of a Combination of Consultants Mannequin with Skilled Members and a Gating Community
Taken from: Ensemble Strategies
Step one is to divide the predictive modeling drawback into subtasks. This usually includes utilizing area data. For instance, a picture could possibly be divided into separate components akin to background, foreground, objects, colours, traces, and so forth.
… ME works in a divide-and-conquer technique the place a posh activity is damaged up into a number of easier and smaller subtasks, and particular person learners (referred to as specialists) are educated for various subtasks.
— Web page 94, Ensemble Methods, 2012.
For these issues the place the division of the duty into subtasks is just not apparent, an easier and extra generic method could possibly be used. For instance, one might think about an method that divides the enter function house by teams of columns or separates examples within the function house based mostly on distance measures, inliers, and outliers for the standard distribution, and rather more.
… in ME, a key drawback is learn how to discover the pure division of the duty after which derive the general answer from sub-solutions.
— Web page 94, Ensemble Methods, 2012.
Subsequent, an professional is designed for every subtask.
The combination of specialists method was initially developed and explored inside the area of synthetic neural networks, so historically, specialists themselves are neural community fashions used to foretell a numerical worth within the case of regression or a category label within the case of classification.
It must be clear that we are able to “plug in” any mannequin for the professional. For instance, we are able to use neural networks to symbolize each the gating features and the specialists. The outcome is named a mix density community.
— Web page 344, Machine Learning: A Probabilistic Perspective, 2012.
Consultants every obtain the identical enter sample (row) and make a prediction.
A mannequin is used to interpret the predictions made by every professional and to assist in deciding which professional to belief for a given enter. That is referred to as the gating mannequin, or the gating community, provided that it’s historically a neural community mannequin.
The gating community takes as enter the enter sample that was supplied to the professional fashions and outputs the contribution that every professional ought to have in making a prediction for the enter.
… the weights decided by the gating community are dynamically assigned based mostly on the given enter, because the MoE successfully learns which portion of the function house is realized by every ensemble member
— Web page 16, Ensemble Machine Learning, 2012.
The gating community is vital to the method and successfully, the mannequin learns to decide on the sort subtask for a given enter and, in flip, the professional to belief to make a powerful prediction.
Combination-of-experts may also be seen as a classifier choice algorithm, the place particular person classifiers are educated to turn into specialists in some portion of the function house.
— Web page 16, Ensemble Machine Learning, 2012.
When neural community fashions are used, the gating community and the specialists are educated collectively such that the gating community learns when to belief every professional to make a prediction. This coaching process was historically carried out utilizing expectation maximization (EM). The gating community may need a softmax output that offers a probability-like confidence rating for every professional.
Typically, the coaching process tries to realize two targets: for given specialists, to search out the optimum gating operate; for a given gating operate, to coach the specialists on the distribution specified by the gating operate.
— Web page 95, Ensemble Methods, 2012.
Lastly, the combination of professional fashions should make a prediction, and that is achieved utilizing a pooling or aggregation mechanism. This could be so simple as deciding on the professional with the most important output or confidence supplied by the gating community.
Alternatively, a weighted sum prediction could possibly be made that explicitly combines the predictions made by every professional and the arrogance estimated by the gating community. You may think different approaches to creating efficient use of the predictions and gating community output.
The pooling/combining system could then select a single classifier with the best weight, or calculate a weighted sum of the classifier outputs for every class, and decide the category that receives the best weighted sum.
— Web page 16, Ensemble Machine Learning, 2012.
We also needs to briefly talk about the swap routing method differs from the MoE paper. I’m bringing it up because it looks like Microsoft has used a swap routing than a Mannequin of Consultants to avoid wasting computational complexity, however I’m completely happy to be confirmed incorrect. When there are a couple of professional’s fashions, they could have a non-trivial gradient for the routing operate (which mannequin to make use of when). This resolution boundary is managed by the swap layer.
The advantages of the swap layer are threefold.
- Routing computation is lowered if the token is being routed solely to a single professional mannequin
- The batch measurement (professional capability) may be a minimum of halved since a single token goes to a single mannequin
- The routing implementation is simplified and communications are lowered.
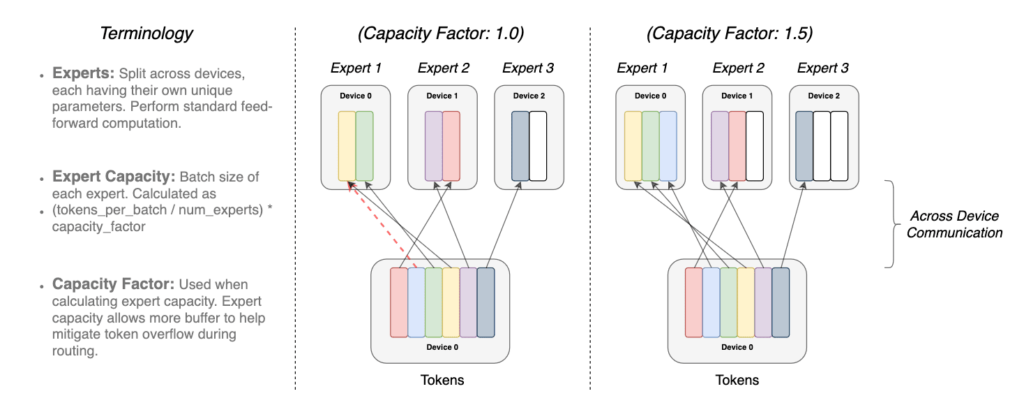
The overlap of the identical token to greater than 1 professional mannequin known as because the Capability issue. Following is a conceptual depiction of how routing with totally different professional capability elements works
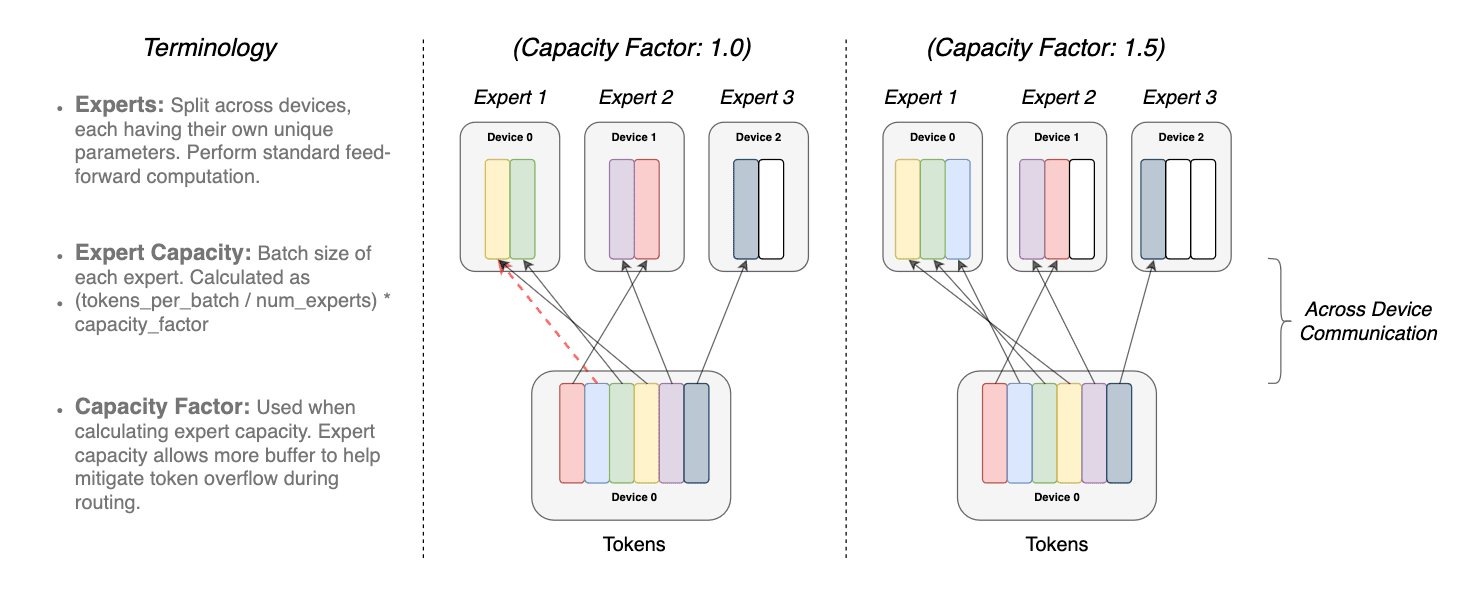 illustration of token routing dynamics. Every professional processes a set batch-size
illustration of token routing dynamics. Every professional processes a set batch-size
of tokens modulated by the capability issue. Every token is routed to the professional
with the best router likelihood, however every professional has a set batch measurement of
(complete tokens/num specialists) × capability issue. If the tokens are inconsistently dis-
patched, then sure specialists will overflow (denoted by dotted crimson traces), ensuing
in these tokens not being processed by this layer. A bigger capability issue allevi-
ates this overflow subject but additionally will increase computation and communication prices
(depicted by padded white/empty slots). (supply https://arxiv.org/pdf/2101.03961.pdf)
In comparison with the MoE, findings from the MoE and Swap paper recommend that
- Swap transformers outperform rigorously tuned dense fashions and MoE transformers on a speed-quality foundation.
- Swap transformers have a smaller compute futprint than MoE
- Swap transformers carry out higher at decrease capability elements (1–1.25).

Two caveats, first, that that is all coming from rumour, and second, my understanding of those ideas is pretty feeble, so I urge readers to take it with a boulder of salt.
However what did Microsoft obtain by conserving this structure hidden? Nicely, they created a buzz, and suspense round it. This may need helped them to craft their narratives higher. They stored innovation to themselves and prevented others catching as much as them sooner. The entire thought was probably a common Microsoft gameplan of thwarting competitors whereas they make investments 10B into an organization.
GPT-4 efficiency is nice, nevertheless it was not an revolutionary or breakthrough design. It was an amazingly intelligent implementation of the strategies developed by engineers and researchers topped up by an enterprise/capitalist deployment. OpenAI has neither denied or agreed to those claims (https://thealgorithmicbridge.substack.com/p/gpt-4s-secret-has-been-revealed), which makes me assume that this structure for GPT-4 is greater than probably the truth (which is nice!). Simply not cool! All of us wish to know and be taught.
An enormous credit score goes to Alberto Romero for bringing this information to the floor and investigating it additional by reaching out to OpenAI (who didn’t reply as per the final replace. I noticed his article on Linkedin however the identical has been printed on Medium too.
Dr. Mandar Karhade, MD. PhD. Sr. Director of Superior Analytics and Knowledge Technique @Avalere Well being. Mandar is an skilled Doctor Scientist engaged on the leading edge implementations of the AI to the Life Sciences and Well being Care trade for 10+ years. Mandar can be a part of AFDO/RAPS serving to to control implantations of AI to the Healthcare.
Original. Reposted with permission.





