Deploy 1000’s of mannequin ensembles with Amazon SageMaker multi-model endpoints on GPU to attenuate your internet hosting prices

Synthetic intelligence (AI) adoption is accelerating throughout industries and use instances. Current scientific breakthroughs in deep studying (DL), massive language fashions (LLMs), and generative AI is permitting prospects to make use of superior state-of-the-art options with virtually human-like efficiency. These complicated fashions typically require {hardware} acceleration as a result of it allows not solely sooner coaching but in addition sooner inference when utilizing deep neural networks in real-time functions. GPUs’ massive variety of parallel processing cores makes them well-suited for these DL duties.
Nonetheless, along with mannequin invocation, these DL utility typically entail preprocessing or postprocessing in an inference pipeline. For instance, enter photographs for an object detection use case may must be resized or cropped earlier than being served to a pc imaginative and prescient mannequin, or tokenization of textual content inputs earlier than being utilized in an LLM. NVIDIA Triton is an open-source inference server that permits customers to outline such inference pipelines as an ensemble of fashions within the type of a Directed Acyclic Graph (DAG). It’s designed to run fashions at scale on each CPU and GPU. Amazon SageMaker helps deploying Triton seamlessly, permitting you to make use of Triton’s options whereas additionally benefiting from SageMaker capabilities: a managed, secured atmosphere with MLOps instruments integration, automated scaling of hosted fashions, and extra.
AWS, in its dedication to assist prospects obtain the best saving, has constantly innovated not solely in pricing options and cost-optimization proactive services, but in addition in launching price financial savings options like multi-model endpoints (MMEs). MMEs are an economical resolution for deploying a lot of fashions utilizing the identical fleet of sources and a shared serving container to host your whole fashions. As an alternative of utilizing a number of single-model endpoints, you possibly can cut back your internet hosting prices by deploying a number of fashions whereas paying just for a single inference atmosphere. Moreover, MMEs cut back deployment overhead as a result of SageMaker manages loading fashions in reminiscence and scaling them primarily based on the visitors patterns to your endpoint.
On this publish, we present how you can run a number of deep studying ensemble fashions on a GPU occasion with a SageMaker MME. To observe together with this instance, you could find the code on the general public SageMaker examples repository.
How SageMaker MMEs with GPU work
With MMEs, a single container hosts a number of fashions. SageMaker controls the lifecycle of fashions hosted on the MME by loading and unloading them into the container’s reminiscence. As an alternative of downloading all of the fashions to the endpoint occasion, SageMaker dynamically hundreds and caches the fashions as they’re invoked.
When an invocation request for a specific mannequin is made, SageMaker does the next:
- It first routes the request to the endpoint occasion.
- If the mannequin has not been loaded, it downloads the mannequin artifact from Amazon Simple Storage Service (Amazon S3) to that occasion’s Amazon Elastic Block Storage quantity (Amazon EBS).
- It hundreds the mannequin to the container’s reminiscence on the GPU-accelerated compute occasion. If the mannequin is already loaded within the container’s reminiscence, invocation is quicker as a result of no additional steps are wanted.
When a further mannequin must be loaded, and the occasion’s reminiscence utilization is excessive, SageMaker will unload unused fashions from that occasion’s container to make sure that there’s sufficient reminiscence. These unloaded fashions will stay on the occasion’s EBS quantity in order that they are often loaded into the container’s reminiscence later, thereby eradicating the necessity to obtain them once more from the S3 bucket. Nonetheless, If the occasion’s storage quantity reaches its capability, SageMaker will delete the unused fashions from the storage quantity. In instances the place the MME receives many invocation requests, and extra situations (or an auto-scaling coverage) are in place, SageMaker routes some requests to different situations within the inference cluster to accommodate for the excessive visitors.
This not solely supplies a value saving mechanism, but in addition allows you to dynamically deploy new fashions and deprecate previous ones. So as to add a brand new mannequin, you add it to the S3 bucket the MME is configured to make use of and invoke it. To delete a mannequin, cease sending requests and delete it from the S3 bucket. Including fashions or deleting them from an MME doesn’t require updating the endpoint itself!
Triton ensembles
The Triton mannequin ensemble represents a pipeline that consists of 1 mannequin, preprocessing and postprocessing logic, and the connection of enter and output tensors between them. A single inference request to an ensemble triggers the run of the whole pipeline as a collection of steps utilizing the ensemble scheduler. The scheduler collects the output tensors in every step and supplies them as enter tensors for different steps in keeping with the specification. To make clear: the ensemble mannequin continues to be seen as a single mannequin from an exterior view.
Triton server architecture features a model repository: a file system-based repository of the fashions that Triton will make out there for inferencing. Triton can entry fashions from a number of domestically accessible file paths or from distant areas like Amazon S3.
Every mannequin in a mannequin repository should embody a mannequin configuration that gives required and elective details about the mannequin. Usually, this configuration is offered in a config.pbtxt file specified as ModelConfig protobuf. A minimal mannequin configuration should specify the platform or backend (like PyTorch or TensorFlow), the max_batch_size property, and the enter and output tensors of the mannequin.
Triton on SageMaker
SageMaker allows mannequin deployment utilizing Triton server with customized code. This performance is obtainable by means of the SageMaker managed Triton Inference Server Containers. These containers help frequent machine leaning (ML) frameworks (like TensorFlow, ONNX, and PyTorch, in addition to customized mannequin codecs) and helpful atmosphere variables that allow you to optimize efficiency on SageMaker. Utilizing SageMaker Deep Studying Containers (DLC) photographs is really helpful as a result of they’re maintained and usually up to date with safety patches.
Answer walkthrough
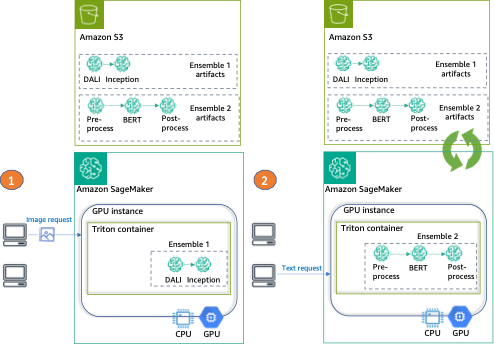
For this publish, we deploy two various kinds of ensembles on a GPU occasion, utilizing Triton and a single SageMaker endpoint.
The primary ensemble consists of two fashions: a DALI mannequin for picture preprocessing and a TensorFlow Inception v3 mannequin for precise inference. The pipeline ensemble takes encoded photographs as an enter, which must be decoded, resized to 299×299 decision, and normalized. This preprocessing might be dealt with by the DALI mannequin. DALI is an open-source library for frequent picture and speech preprocessing duties resembling decoding and knowledge augmentation. Inception v3 is a picture recognition mannequin that consists of symmetric and uneven convolutions, and common and max pooling absolutely related layers (and subsequently is ideal for GPU utilization).
The second ensemble transforms uncooked pure language sentences into embeddings and consists of three fashions. First, a preprocessing mannequin is utilized to the enter textual content tokenization (applied in Python). Then we use a pre-trained BERT (uncased) model from the Hugging Face Model Hub to extract token embeddings. BERT is an English language mannequin that was skilled utilizing a masked language modeling (MLM) goal. Lastly, we apply a postprocessing mannequin the place the uncooked token embeddings from the earlier step are mixed into sentence embeddings.
After we configure Triton to make use of these ensembles, we present how you can configure and run the SageMaker MME.
Lastly, we offer an instance of every ensemble invocation, as may be seen within the following diagram:
- Ensemble 1 – Invoke the endpoint with a picture, specifying DALI-Inception because the goal ensemble
- Ensemble 2 – Invoke the identical endpoint, this time with textual content enter and requesting the preprocess-BERT-postprocess ensemble
Arrange the atmosphere
First, we arrange the wanted atmosphere. This consists of updating AWS libraries (like Boto3 and the SageMaker SDK) and putting in the dependencies required to package deal our ensembles and run inferences utilizing Triton. We additionally use the SageMaker SDK default execution function. We use this function to allow SageMaker to entry Amazon S3 (the place our mannequin artifacts are saved) and the container registry (the place the NVIDIA Triton picture might be used from). See the next code:
Put together ensembles
On this subsequent step, we put together the 2 ensembles: the TensorFlow (TF) Inception with DALI preprocessing and BERT with Python preprocessing and postprocessing.
This entails downloading the pre-trained fashions, offering the Triton configuration information, and packaging the artifacts to be saved in Amazon S3 earlier than deploying.
Put together the TF and DALI ensemble
First, we put together the directories for storing our fashions and configurations: for the TF Inception (inception_graphdef), for DALI preprocessing (dali), and for the ensemble (ensemble_dali_inception). As a result of Triton helps mannequin versioning, we additionally add the mannequin model to the listing path (denoted as 1 as a result of we solely have one model). To be taught extra concerning the Triton model coverage, check with Version Policy. Subsequent, we obtain the Inception v3 mannequin, extract it, and replica to the inception_graphdef mannequin listing. See the next code:
Now, we configure Triton to make use of our ensemble pipeline. In a config.pbtxt file, we specify the enter and output tensor shapes and kinds, and the steps the Triton scheduler must take (DALI preprocessing and the Inception mannequin for picture classification):
Subsequent, we configure every of the fashions. First, the mannequin config for DALI backend:
Subsequent, the mannequin configuration for TensorFlow Inception v3 we downloaded earlier:
As a result of this can be a classification mannequin, we additionally want to repeat the Inception mannequin labels to the inception_graphdef listing within the mannequin repository. These labels embody 1,000 class labels from the ImageNet dataset.
Subsequent, we configure and serialize the DALI pipeline that may deal with our preprocessing to file. The preprocessing consists of studying the picture (utilizing CPU), decoding (accelerated utilizing GPU), and resizing and normalizing the picture.
Lastly, we package deal the artifacts collectively and add them as a single object to Amazon S3:
Put together the TensorRT and Python ensemble
For this instance, we use a pre-trained mannequin from the transformers library.
You will discover all fashions (preprocess and postprocess, together with config.pbtxt information) within the folder ensemble_hf. Our file system construction will embody 4 directories (three for the person mannequin steps and one for the ensemble) in addition to their respective variations:
Within the workspace folder, we offer with two scripts: the primary to transform the mannequin into ONNX format (onnx_exporter.py) and the TensorRT compilation script (generate_model_trt.sh).
Triton natively helps the TensorRT runtime, which allows you to simply deploy a TensorRT engine, thereby optimizing for a particular GPU structure.
To ensure we use the TensorRT model and dependencies which are suitable with those in our Triton container, we compile the mannequin utilizing the corresponding model of NVIDIA’s PyTorch container picture:
We then copy the mannequin artifacts to the listing we created earlier and add a model to the trail:
We use a Conda pack to generate a Conda atmosphere that the Triton Python backend will use in preprocessing and postprocessing:
Lastly, we add the mannequin artifacts to Amazon S3:
Run ensembles on a SageMaker MME GPU occasion
Now that our ensemble artifacts are saved in Amazon S3, we will configure and launch the SageMaker MME.
We begin by retrieving the container picture URI for the Triton DLC image that matches the one in our Region’s container registry (and is used for TensorRT mannequin compilation):
Subsequent, we create the mannequin in SageMaker. Within the create_model request, we describe the container to make use of and the placement of mannequin artifacts, and we specify utilizing the Mode parameter that this can be a multi-model.
To host our ensembles, we create an endpoint configuration with the create_endpoint_config API name, after which create an endpoint with the create_endpoint API. SageMaker then deploys all of the containers that you simply outlined for the mannequin within the internet hosting atmosphere.
Though on this instance we’re setting a single occasion to host our mannequin, SageMaker MMEs absolutely help setting an auto scaling coverage. For extra data on this characteristic, see Run multiple deep learning models on GPU with Amazon SageMaker multi-model endpoints.
Create request payloads and invoke the MME for every mannequin
After our real-time MME is deployed, it’s time to invoke our endpoint with every of the mannequin ensembles we used.
First, we create a payload for the DALI-Inception ensemble. We use the shiba_inu_dog.jpg picture from the SageMaker public dataset of pet photographs. We load the picture as an encoded array of bytes to make use of within the DALI backend (to be taught extra, see Image Decoder examples).
With our encoded picture and payload prepared, we invoke the endpoint.
Be aware that we specify our goal ensemble to be the model_tf_dali.tar.gz artifact. The TargetModel parameter is what differentiates MMEs from single-model endpoints and allows us to direct the request to the suitable mannequin.
The response consists of metadata concerning the invocation (resembling mannequin identify and model) and the precise inference response within the knowledge a part of the output object. On this instance, we get an array of 1,001 values, the place every worth is the likelihood of the category the picture belongs to (1,000 lessons and 1 further for others).
Subsequent, we invoke our MME once more, however this time goal the second ensemble. Right here the info is simply two easy textual content sentences:
To simplify communication with Triton, the Triton mission supplies a number of client libraries. We use that library to arrange the payload in our request:
Now we’re able to invoke the endpoint—this time, the goal mannequin is the model_trt_python.tar.gz ensemble:
The response is the sentence embeddings that can be utilized in quite a lot of pure language processing (NLP) functions.
Clear up
Lastly, we clear up and delete the endpoint, endpoint configuration, and mannequin:
Conclusion
On this publish, we confirmed how you can configure, deploy, and invoke a SageMaker MME with Triton ensembles on a GPU-accelerated occasion. We hosted two ensembles on a single real-time inference atmosphere, which diminished our price by 50% (for a g4dn.4xlarge occasion, which represents over $13,000 in yearly financial savings). Though this instance used solely two pipelines, SageMaker MMEs can help 1000’s of mannequin ensembles, making it a rare price financial savings mechanism. Moreover, you should utilize SageMaker MMEs’ dynamic capability to load (and unload) fashions to attenuate the operational overhead of managing mannequin deployments in manufacturing.
Concerning the authors
 Saurabh Trikande is a Senior Product Supervisor for Amazon SageMaker Inference. He’s captivated with working with prospects and is motivated by the objective of democratizing machine studying. He focuses on core challenges associated to deploying complicated ML functions, multi-tenant ML fashions, price optimizations, and making deployment of deep studying fashions extra accessible. In his spare time, Saurabh enjoys mountain climbing, studying about progressive applied sciences, following TechCrunch, and spending time along with his household.
Saurabh Trikande is a Senior Product Supervisor for Amazon SageMaker Inference. He’s captivated with working with prospects and is motivated by the objective of democratizing machine studying. He focuses on core challenges associated to deploying complicated ML functions, multi-tenant ML fashions, price optimizations, and making deployment of deep studying fashions extra accessible. In his spare time, Saurabh enjoys mountain climbing, studying about progressive applied sciences, following TechCrunch, and spending time along with his household.
 Nikhil Kulkarni is a software program developer with AWS Machine Studying, specializing in making machine studying workloads extra performant on the cloud, and is a co-creator of AWS Deep Studying Containers for coaching and inference. He’s captivated with distributed Deep Studying Methods. Outdoors of labor, he enjoys studying books, twiddling with the guitar, and making pizza.
Nikhil Kulkarni is a software program developer with AWS Machine Studying, specializing in making machine studying workloads extra performant on the cloud, and is a co-creator of AWS Deep Studying Containers for coaching and inference. He’s captivated with distributed Deep Studying Methods. Outdoors of labor, he enjoys studying books, twiddling with the guitar, and making pizza.
 Uri Rosenberg is the AI & ML Specialist Technical Supervisor for Europe, Center East, and Africa. Based mostly out of Israel, Uri works to empower enterprise prospects to design, construct, and function ML workloads at scale. In his spare time, he enjoys biking, backpacking, and backpropagating.
Uri Rosenberg is the AI & ML Specialist Technical Supervisor for Europe, Center East, and Africa. Based mostly out of Israel, Uri works to empower enterprise prospects to design, construct, and function ML workloads at scale. In his spare time, he enjoys biking, backpacking, and backpropagating.
 Eliuth Triana Isaza is a Developer Relations Supervisor on the NVIDIA-AWS crew. He connects Amazon and AWS product leaders, builders, and scientists with NVIDIA technologists and product leaders to speed up Amazon ML/DL workloads, EC2 merchandise, and AWS AI companies. As well as, Eliuth is a passionate mountain biker, skier, and poker participant.
Eliuth Triana Isaza is a Developer Relations Supervisor on the NVIDIA-AWS crew. He connects Amazon and AWS product leaders, builders, and scientists with NVIDIA technologists and product leaders to speed up Amazon ML/DL workloads, EC2 merchandise, and AWS AI companies. As well as, Eliuth is a passionate mountain biker, skier, and poker participant.



