A Mild Introduction to Bayesian Deep Studying | by François Porcher | Jul, 2023
Welcome to the thrilling world of Probabilistic Programming! This text is a delicate introduction to the sector, you solely want a fundamental understanding of Deep Studying and Bayesian statistics.
By the tip of this text, it is best to have a fundamental understanding of the sector, its functions, and the way it differs from extra conventional deep studying strategies.
If, like me, you might have heard of Bayesian Deep Studying, and also you guess it includes bayesian statistics, however you do not know precisely how it’s used, you might be in the proper place.
One of many predominant limitation of Conventional deep studying is that regardless that they’re very highly effective instruments, they don’t present a measure of their uncertainty.
Chat GPT can say false data with blatant confidence. Classifiers output possibilities which are typically not calibrated.
Uncertainty estimation is a vital side of decision-making processes, particularly within the areas resembling healthcare, self-driving automobiles. We would like a mannequin to have the ability to be capable of estimate when its very uncertain about classifying a topic with a mind most cancers, and on this case we require additional prognosis by a medical skilled. Equally we would like autonomous automobiles to have the ability to decelerate when it identifies a brand new setting.
For example how dangerous a neural community can estimates the chance, let’s have a look at a quite simple Classifier Neural Community with a softmax layer in the long run.
The softmax has a really comprehensible title, it’s a Tender Max perform, which means that it’s a “smoother” model of a max perform. The explanation for that’s that if we had picked a “exhausting” max perform simply taking the category with the very best chance, we might have a zero gradient to all the opposite courses.
With a softmax, the chance of a category could be near 1, however by no means precisely 1. And since the sum of possibilities of all courses is 1, there may be nonetheless some gradient flowing to the opposite courses.

Nonetheless, the softmax perform additionally presents a difficulty. It outputs possibilities which are poorly calibrated. Small modifications within the values earlier than making use of the softmax perform are squashed by the exponential, inflicting minimal modifications to the output possibilities.
This typically leads to overconfidence, with the mannequin giving excessive possibilities for sure courses even within the face of uncertainty, a attribute inherent to the ‘max’ nature of the softmax perform.
Evaluating a conventional Neural Community (NN) with a Bayesian Neural Community (BNN) can spotlight the significance of uncertainty estimation. A BNN’s certainty is excessive when it encounters acquainted distributions from coaching information, however as we transfer away from recognized distributions, the uncertainty will increase, offering a extra practical estimation.
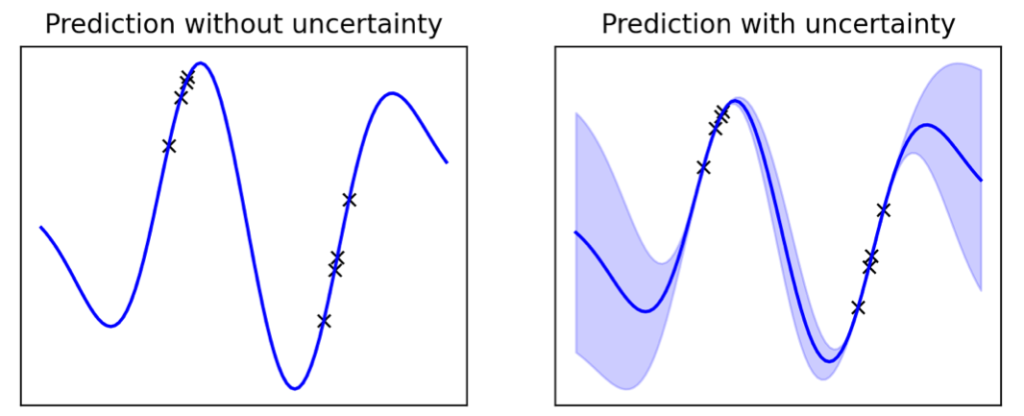
Here’s what an estimation of uncertainty can seem like:

You’ll be able to see that after we are near the distribution we now have noticed throughout coaching, the mannequin may be very sure, however as we transfer farther from the recognized distribution, the uncertainty will increase.
There’s one central Theorem to know in Bayesian statistics: The Bayes Theorem.

- The prior is the distribution of theta we predict is the most probably earlier than any remark. For a coin toss for instance we may assume that the chance of getting a head is a gaussian round p = 0.5
- If we wish to put as little inductive bias as attainable, we may additionally say p is uniform between [0,1].
- The probability is given a parameter theta, how doubtless is that we acquired our observations X, Y
- The marginal probability is the probability built-in over all theta attainable. It’s known as “marginal” as a result of we marginalized theta by averaging it over all possibilities.
The important thing thought to know in Bayesian Statistics is that you just begin from a previous, it is your finest guess of what the parameter might be (it’s a distribution). And with the observations you make, you regulate your guess, and also you acquire a posterior distribution.
Be aware that the prior and posterior are usually not a punctual estimations of theta however a chance distribution.
For example this:

On this picture you may see that the prior is shifted to the proper, however the probability rebalances our previous to the left, and the posterior is someplace in between.
Bayesian Deep Studying is an method that marries two highly effective mathematical theories: Bayesian statistics and Deep Studying.
The important distinction from conventional Deep Studying resides within the therapy of the mannequin’s weights:
In conventional Deep Studying, we prepare a mannequin from scratch, we randomly initialize a set of weights, and prepare the mannequin till it converges to a brand new set of parameters. We be taught a single set of weights.
Conversely, Bayesian Deep Studying adopts a extra dynamic method. We start with a previous perception in regards to the weights, typically assuming they observe a traditional distribution. As we expose our mannequin to information, we regulate this perception, thus updating the posterior distribution of the weights. In essence, we be taught a chance distribution over the weights, as an alternative of a single set.
Throughout inference, we common predictions from all fashions, weighting their contributions primarily based on the posterior. This implies, if a set of weights is very possible, its corresponding prediction is given extra weight.
Let’s formalize all of that:

Inference in Bayesian Deep Studying integrates over all potential values of theta (weights) utilizing the posterior distribution.
We will additionally see that in Bayesian Statistics, integrals are in all places. That is truly the principal limitation of the Bayesian framework. These integrals are typically intractable (we do not all the time know a primitive of the posterior). So we now have to do very computationally costly approximations.
Benefit 1: Uncertainty estimation
- Arguably probably the most outstanding good thing about Bayesian Deep Studying is its capability for uncertainty estimation. In lots of domains together with healthcare, autonomous driving, language fashions, pc imaginative and prescient, and quantitative finance, the power to quantify uncertainty is essential for making knowledgeable selections and managing danger.
Benefit 2: Improved coaching effectivity
- Carefully tied to the idea of uncertainty estimation is improved coaching effectivity. Since Bayesian fashions are conscious of their very own uncertainty, they’ll prioritize studying from information factors the place the uncertainty — and therefore, potential for studying — is highest. This method, often called Lively Studying, results in impressively efficient and environment friendly coaching.

As demonstrated within the graph beneath, a Bayesian Neural Community utilizing Lively Studying achieves 98% accuracy with simply 1,000 coaching pictures. In distinction, fashions that don’t exploit uncertainty estimation are inclined to be taught at a slower tempo.
Benefit 3: Inductive Bias
One other benefit of Bayesian Deep Studying is the efficient use of inductive bias by priors. The priors permit us to encode our preliminary beliefs or assumptions in regards to the mannequin parameters, which could be notably helpful in situations the place area information exists.
Contemplate generative AI, the place the concept is to create new information (like medical pictures) that resemble the coaching information. For instance, for those who’re producing mind pictures, and also you already know the overall format of a mind — white matter inside, gray matter outdoors — this data could be included in your prior. This implies you may assign a better chance to the presence of white matter within the heart of the picture, and gray matter in direction of the perimeters.
In essence, Bayesian Deep Studying not solely empowers fashions to be taught from information but additionally permits them to begin studying from a degree of data, relatively than ranging from scratch. This makes it a potent device for a variety of functions.

Plainly Bayesian Deep Studying is unbelievable! So why is it that this subject is so underrated? Certainly we regularly discuss Generative AI, Chat GPT, SAM, or extra conventional neural networks, however we virtually by no means hear about Bayesian Deep Studying, why is that?
Limitation 1: Bayesian Deep Studying is slooooow
The important thing to know Bayesian Deep Studying is that we “common” the predictions of the mannequin, and at any time when there may be a mean, there may be an integral over the set of parameters.
However computing an integral is usually intractable, because of this there isn’t a closed or express kind that makes the computation of this integral fast. So we are able to’t compute it instantly, we now have to approximate the integral by sampling some factors, and this makes the inference very gradual.
Think about that for every information level x we now have to common out the prediction of 10,000 fashions, and that every prediction can take 1s to run, we find yourself with a mannequin that’s not scalable with a considerable amount of information.
In a lot of the enterprise instances, we want quick and scalable inference, because of this Bayesian Deep Studying just isn’t so standard.
Limitation 2: Approximation Errors
In Bayesian Deep Studying, it’s typically obligatory to make use of approximate strategies, resembling Variational Inference, to compute the posterior distribution of weights. These approximations can result in errors within the ultimate mannequin. The standard of the approximation will depend on the selection of the variational household and the divergence measure, which could be difficult to decide on and tune correctly.
Limitation 3: Elevated Mannequin Complexity and Interpretability
Whereas Bayesian strategies supply improved measures of uncertainty, this comes at the price of elevated mannequin complexity. BNNs could be troublesome to interpret as a result of as an alternative of a single set of weights, we now have a distribution over attainable weights. This complexity would possibly result in challenges in explaining the mannequin’s selections, particularly in fields the place interpretability is essential.
There’s a rising curiosity for XAI (Explainable AI), and Conventional Deep Neural Networks are already difficult to interpret as a result of it’s troublesome to make sense of the weights, Bayesian Deep Studying is much more difficult.
Whether or not you might have suggestions, concepts to share, wanna work with me, or just wish to say hiya, please fill out the shape beneath, and let’s begin a dialog.
Do not hesitate to go away a clap or observe me for extra!
- Ghahramani, Z. (2015). Probabilistic machine studying and synthetic intelligence. Nature, 521(7553), 452–459. Link
- Blundell, C., Cornebise, J., Kavukcuoglu, Okay., & Wierstra, D. (2015). Weight uncertainty in neural networks. arXiv preprint arXiv:1505.05424. Link
- Gal, Y., & Ghahramani, Z. (2016). Dropout as a Bayesian approximation: Representing mannequin uncertainty in deep studying. In worldwide convention on machine studying (pp. 1050–1059). Link
- Louizos, C., Welling, M., & Kingma, D. P. (2017). Studying sparse neural networks by L0 regularization. arXiv preprint arXiv:1712.01312. Link
- Neal, R. M. (2012). Bayesian studying for neural networks (Vol. 118). Springer Science & Enterprise Media. Link



