Interactively fine-tune Falcon-40B and different LLMs on Amazon SageMaker Studio notebooks utilizing QLoRA

Effective-tuning massive language fashions (LLMs) permits you to modify open-source foundational fashions to realize improved efficiency in your domain-specific duties. On this publish, we talk about the benefits of utilizing Amazon SageMaker notebooks to fine-tune state-of-the-art open-source fashions. We make the most of Hugging Face’s parameter-efficient fine-tuning (PEFT) library and quantization methods via bitsandbytes to assist interactive fine-tuning of extraordinarily massive fashions utilizing a single pocket book occasion. Particularly, we present find out how to fine-tune Falcon-40B utilizing a single ml.g5.12xlarge occasion (4 A10G GPUs), however the identical technique works to tune even bigger fashions on p4d/p4de notebook instances.
Usually, the complete precision representations of those very massive fashions don’t match into reminiscence on a single and even a number of GPUs. To assist an interactive pocket book setting to fine-tune and run inference on fashions of this measurement, we use a brand new approach referred to as Quantized LLMs with Low-Rank Adapters (QLoRA). QLoRA is an environment friendly fine-tuning strategy that reduces reminiscence utilization of LLMs whereas sustaining strong efficiency. Hugging Face and the authors of the paper talked about have revealed a detailed blog post that covers the basics and integrations with the Transformers and PEFT libraries.
Utilizing notebooks to fine-tune LLMs
SageMaker comes with two choices to spin up absolutely managed notebooks for exploring knowledge and constructing machine studying (ML) fashions. The primary choice is quick begin, collaborative notebooks accessible inside Amazon SageMaker Studio, a completely built-in growth setting (IDE) for ML. You may shortly launch notebooks in SageMaker Studio, dial up or down the underlying compute assets with out interrupting your work, and even co-edit and collaborate in your notebooks in actual time. Along with creating notebooks, you possibly can carry out all of the ML growth steps to construct, practice, debug, monitor, deploy, and monitor your fashions in a single pane of glass in SageMaker Studio. The second choice is a SageMaker notebook instance, a single, absolutely managed ML compute occasion working notebooks within the cloud, which gives you extra management over your pocket book configurations.
For the rest of this publish, we use SageMaker Studio notebooks as a result of we need to make the most of SageMaker Studio’s managed TensorBoard experiment monitoring with Hugging Face Transformer’s assist for TensorBoard. Nevertheless, the identical ideas proven all through the instance code will work on pocket book cases utilizing the conda_pytorch_p310 kernel. It’s price noting that SageMaker Studio’s Amazon Elastic File System (Amazon EFS) quantity means you don’t have to provision a preordained Amazon Elastic Block Store (Amazon EBS) quantity measurement, which is beneficial given the massive measurement of mannequin weights in LLMs.
Utilizing notebooks backed by massive GPU cases allows speedy prototyping and debugging with out chilly begin container launches. Nevertheless, it additionally signifies that that you must shut down your pocket book cases whenever you’re accomplished utilizing them to keep away from additional prices. Different choices corresponding to Amazon SageMaker JumpStart and SageMaker Hugging Face containers can be utilized for fine-tuning, and we advocate you confer with the next posts on the aforementioned strategies to decide on the most suitable choice for you and your crew:
Stipulations
If that is your first time working with SageMaker Studio, you first have to create a SageMaker domain. We additionally use a managed TensorBoard instance for experiment tracking, although that’s optionally available for this tutorial.
Moreover, you could have to request a service quota enhance for the corresponding SageMaker Studio KernelGateway apps. For fine-tuning Falcon-40B, we use a ml.g5.12xlarge occasion.
To request a service quota enhance, on the AWS Service Quotas console, navigate to AWS companies, Amazon SageMaker, and choose Studio KernelGateway Apps working on ml.g5.12xlarge cases. 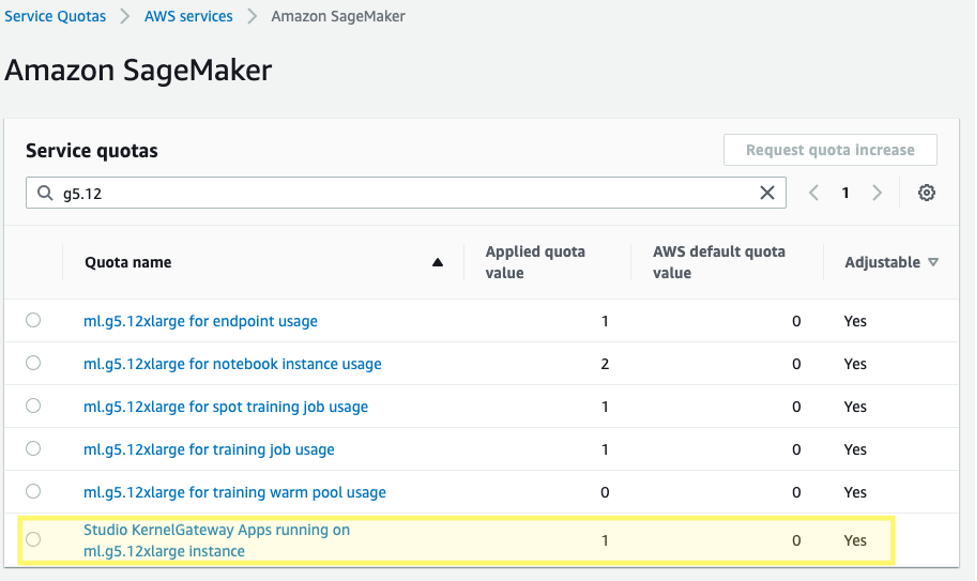
Get began
The code pattern for this publish will be discovered within the following GitHub repository. To start, we select the Knowledge Science 3.0 picture and Python 3 kernel from SageMaker Studio in order that now we have a latest Python 3.10 setting to put in our packages.

We set up PyTorch and the required Hugging Face and bitsandbytes libraries:
Subsequent, we set the CUDA setting path utilizing the put in CUDA that was a dependency of PyTorch set up. This can be a required step for the bitsandbytes library to accurately discover and cargo the proper CUDA shared object binary.
Load the pre-trained foundational mannequin
We use bitsandbytes to quantize the Falcon-40B mannequin into 4-bit precision in order that we will load the mannequin into reminiscence on 4 A10G GPUs utilizing Hugging Face Speed up’s naive pipeline parallelism. As described within the beforehand talked about Hugging Face post, QLoRA tuning is proven to match 16-bit fine-tuning strategies in a variety of experiments as a result of mannequin weights are saved as 4-bit NormalFloat, however are dequantized to the computation bfloat16 on ahead and backward passes as wanted.
When loading the pretrained weights, we specify device_map=”auto" in order that Hugging Face Speed up will mechanically decide which GPU to place every layer of the mannequin on. This course of is named mannequin parallelism.
With Hugging Face’s PEFT library, you possibly can freeze a lot of the authentic mannequin weights and change or prolong mannequin layers by coaching a further, a lot smaller, set of parameters. This makes coaching a lot inexpensive by way of required compute. We set the Falcon modules that we need to fine-tune as target_modules within the LoRA configuration:
Discover that we’re solely fine-tuning 0.26% of the mannequin’s parameters, which makes this possible in an affordable period of time.
Load a dataset
We use the samsum dataset for our fine-tuning. Samsum is a group of 16,000 messenger-like conversations with labeled summaries. The next is an instance of the dataset:
In observe, you’ll need to use a dataset that has particular information to the duty you’re hoping to tune your mannequin on. The method of constructing such a dataset will be accelerated by utilizing Amazon SageMaker Ground Truth Plus, as described in High-quality human feedback for your generative AI applications from Amazon SageMaker Ground Truth Plus.
Effective-tune the mannequin
Previous to fine-tuning, we outline the hyperparameters we need to use and practice the mannequin. We are able to additionally log our metrics to TensorBoard by defining the parameter logging_dir and requesting the Hugging Face transformer to report_to="tensorboard":
Monitor the fine-tuning
With the previous setup, we will monitor our fine-tuning in actual time. To watch GPU utilization in actual time, we will run nvidia-smi straight from the kernel’s container. To launch a terminal working on the picture container, merely select the terminal icon on the prime of your pocket book.

From right here, we will use the Linux watch command to repeatedly run nvidia-smi each half second:
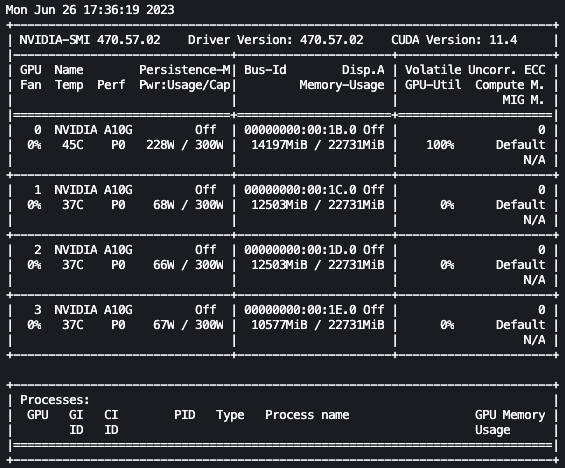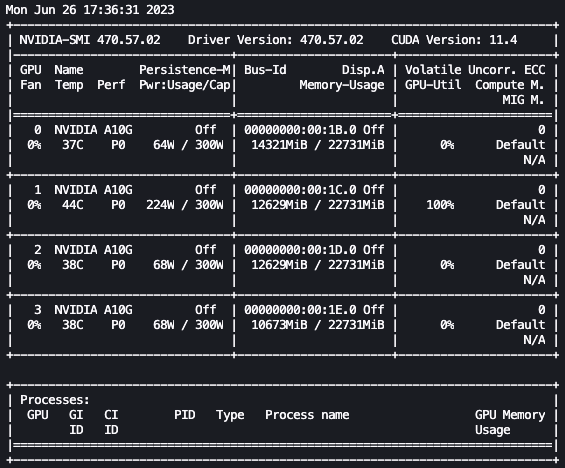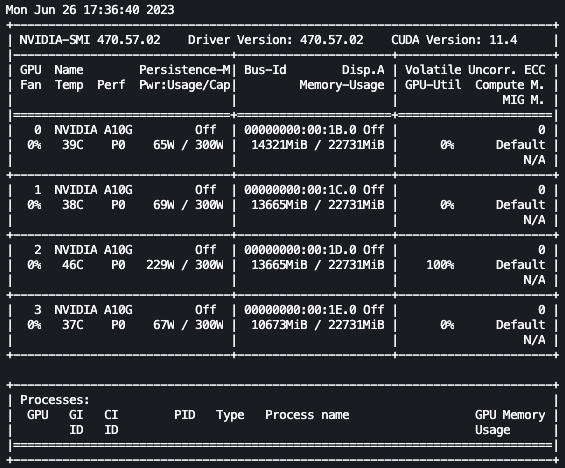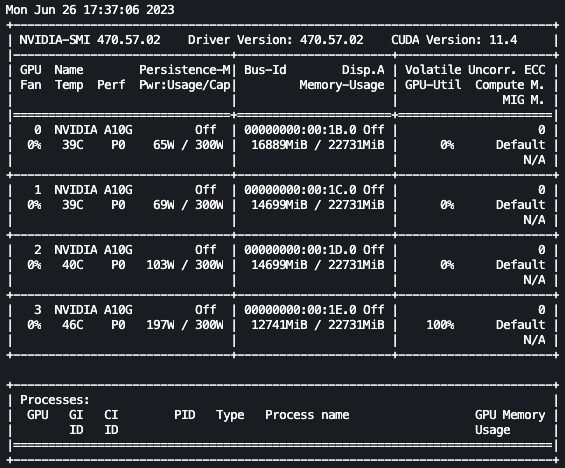
Within the previous animation, we will see that the mannequin weights are distributed throughout the 4 GPUs and computation is being distributed throughout them as layers are processed serially.
To watch the coaching metrics, we make the most of the TensorBoard logs that we write to the desired Amazon Simple Storage Service (Amazon S3) bucket. We are able to launch our SageMaker Studio area person’s TensorBoard from the AWS SageMaker console:
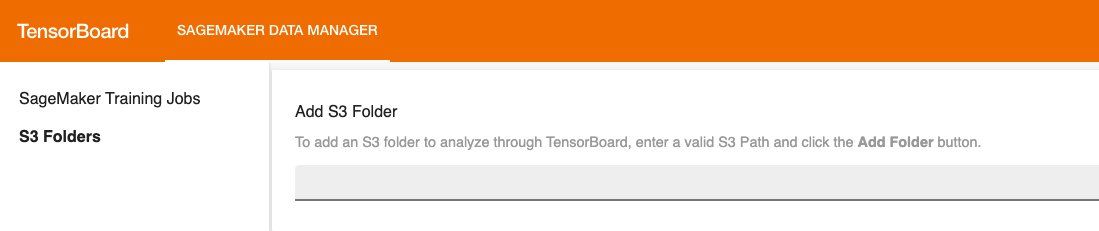
After loading, you possibly can specify the S3 bucket that you just instructed the Hugging Face transformer to log to so as to view coaching and analysis metrics.
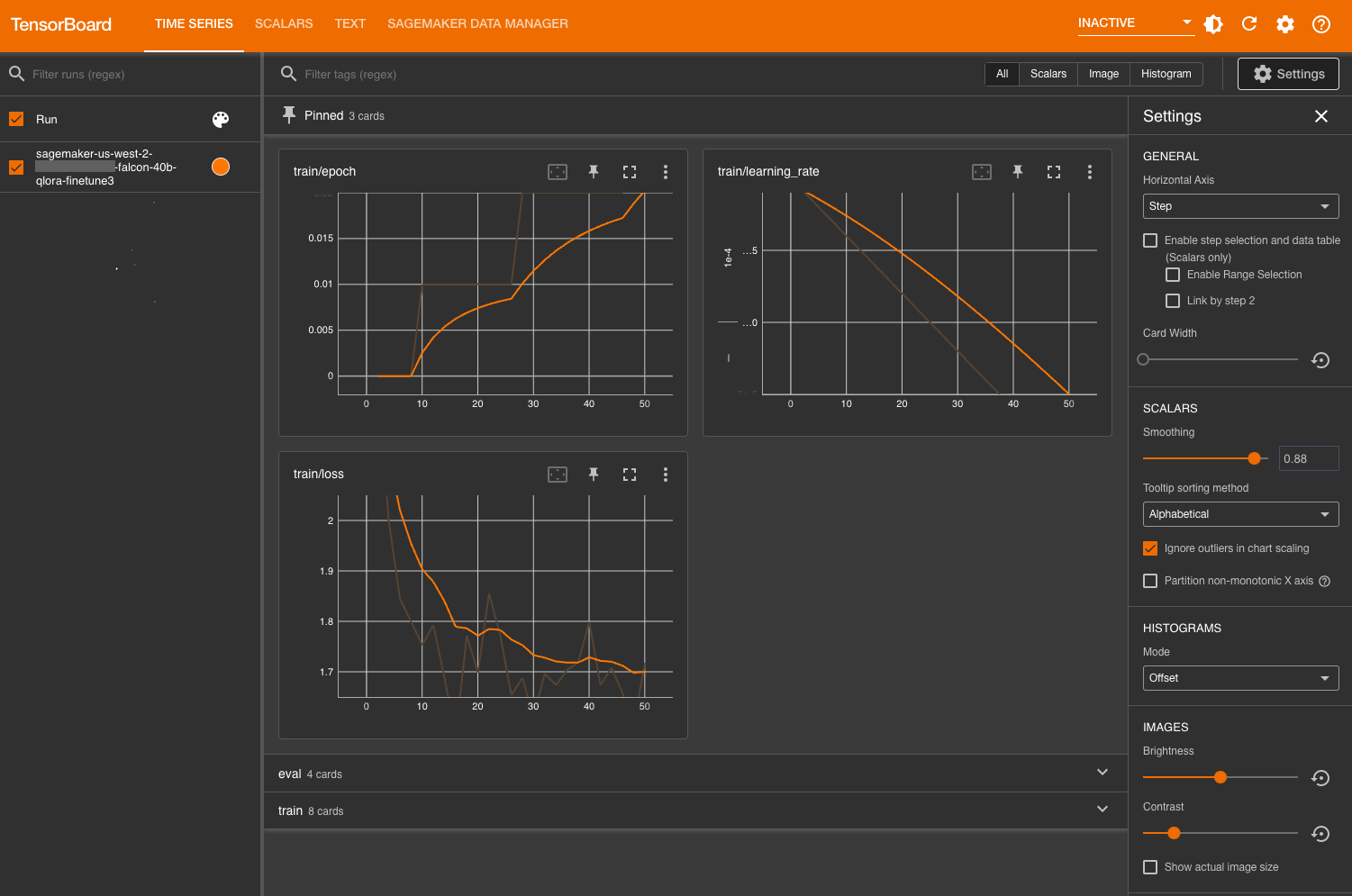
Consider the mannequin
After our mannequin is completed coaching, we will run systematic evaluations or just generate responses:
After you’re glad with the mannequin’s efficiency, it can save you the mannequin:
You can even select to host it in a dedicated SageMaker endpoint.
Clear up
Full the next steps to wash up your assets:
- Shut down the SageMaker Studio instances to keep away from incurring extra prices.
- Shut down your TensorBoard application.
- Clear up your EFS listing by clearing the Hugging Face cache listing:
Conclusion
SageMaker notebooks assist you to fine-tune LLMs in a fast and environment friendly method in an interactive setting. On this publish, we confirmed how you should use Hugging Face PEFT with bitsandbtyes to fine-tune Falcon-40B fashions utilizing QLoRA on SageMaker Studio notebooks. Attempt it out, and tell us your ideas within the feedback part!
We additionally encourage you to study extra about Amazon generative AI capabilities by exploring SageMaker JumpStart, Amazon Titan fashions, and Amazon Bedrock.
Concerning the Authors
 Sean Morgan is a Senior ML Options Architect at AWS. He has expertise within the semiconductor and tutorial analysis fields, and makes use of his expertise to assist clients attain their objectives on AWS. In his free time, Sean is an lively open-source contributor and maintainer, and is the particular curiosity group lead for TensorFlow Addons.
Sean Morgan is a Senior ML Options Architect at AWS. He has expertise within the semiconductor and tutorial analysis fields, and makes use of his expertise to assist clients attain their objectives on AWS. In his free time, Sean is an lively open-source contributor and maintainer, and is the particular curiosity group lead for TensorFlow Addons.
 Lauren Mullennex is a Senior AI/ML Specialist Options Architect at AWS. She has a decade of expertise in DevOps, infrastructure, and ML. She can also be the writer of a e-book on laptop imaginative and prescient. Her different areas of focus embrace MLOps and generative AI.
Lauren Mullennex is a Senior AI/ML Specialist Options Architect at AWS. She has a decade of expertise in DevOps, infrastructure, and ML. She can also be the writer of a e-book on laptop imaginative and prescient. Her different areas of focus embrace MLOps and generative AI.
 Philipp Schmid is a Technical Lead at Hugging Face with the mission to democratize good machine studying via open supply and open science. Philipp is captivated with productionizing cutting-edge and generative AI machine studying fashions. He likes to share his information on AI and NLP at varied meetups corresponding to Knowledge Science on AWS, and on his technical blog.
Philipp Schmid is a Technical Lead at Hugging Face with the mission to democratize good machine studying via open supply and open science. Philipp is captivated with productionizing cutting-edge and generative AI machine studying fashions. He likes to share his information on AI and NLP at varied meetups corresponding to Knowledge Science on AWS, and on his technical blog.



