UC Berkeley And Meta AI Researchers Suggest A Lagrangian Motion Recognition Mannequin By Fusing 3D Pose And Contextualized Look Over Tracklets
It’s customary in fluid mechanics to differentiate between the Lagrangian and Eulerian move discipline formulations. In line with Wikipedia, “Lagrangian specification of the move discipline is an strategy to learning fluid movement the place the observer follows a discrete fluid parcel because it flows by way of house and time. The pathline of a parcel could also be decided by graphing its location over time. This is likely to be pictured as floating alongside a river whereas seated in a ship. The Eulerian specification of the move discipline is a technique of analyzing fluid movement that locations explicit emphasis on the areas within the house by way of which the fluid flows as time passes. Sitting on a riverbank and observing the water move a hard and fast level will enable you visualize this.
These concepts are essential to understanding how they study recordings of human motion. In line with the Eulerian perspective, they’d think about characteristic vectors at sure locations, resembling (x, y) or (x, y, z), and think about historic evolution whereas remaining stationary in house on the spot. In line with the Lagrangian perspective, they’d comply with, let’s say, a human throughout spacetime and the associated characteristic vector. For instance, older analysis for exercise recognition continuously employed the Lagrangian viewpoint. Nevertheless, with the event of neural networks primarily based on 3D spacetime convolution, the Eulerian viewpoint has turn into the norm in cutting-edge strategies like SlowFast Networks. The Eulerian perspective has been maintained even after the changeover to transformer methods.
That is vital as a result of it gives us an opportunity to reexamine the question, “What ought to be the counterparts of phrases in video evaluation?” in the course of the tokenization course of for transformers. Picture patches had been beneficial by Dosovitskiy et al. as an excellent possibility, and the extension of that idea to video implies that spatiotemporal cuboids is likely to be appropriate for video as properly. As an alternative, they undertake the Lagrangian perspective for analyzing human conduct of their work. This makes it clear that they consider an entity’s course throughout time. On this case, the entity is likely to be high-level, like a human, or low-level, like a pixel or patch. They decide to perform on the extent of “humans-as-entities” as a result of they’re interested by comprehending human conduct.
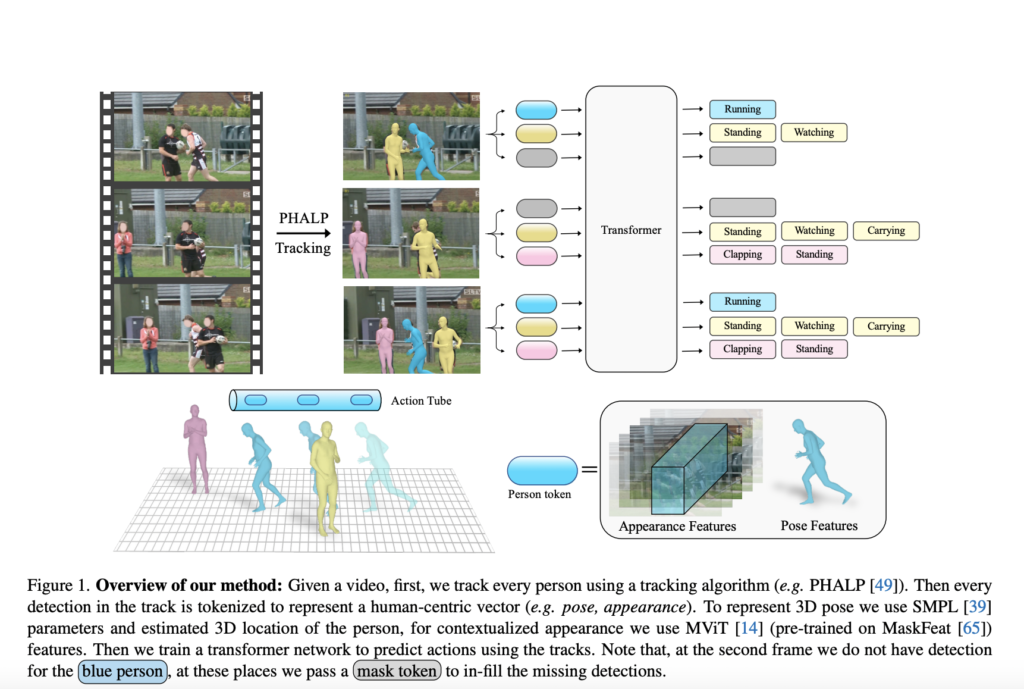
To do that, they use a method that analyses an individual’s motion in a video and makes use of it to establish their exercise. They’ll retrieve these trajectories utilizing the not too long ago launched 3D monitoring methods PHALP and HMR 2.0. Determine 1 illustrates how PHALP recovers individual tracks from video by elevating people to 3D, permitting them to hyperlink folks throughout a number of frames and entry their 3D illustration. They make use of these 3D representations of individuals—their 3D poses and areas—as the elemental components of every token. This permits us to assemble a versatile system the place the mannequin, on this case, a transformer, accepts tokens belonging to numerous people with entry to their id, 3D posture, and 3D location as enter. We could study interpersonal interactions through the use of the 3D areas of the individuals within the situation.
Their tokenization-based mannequin surpasses earlier baselines that simply had entry to posture knowledge and may use 3D monitoring. Though the evolution of an individual’s place by way of time is a robust sign, some actions want extra background data concerning the environment and the individual’s look. Because of this, it’s essential to mix stance with knowledge about individual and scene look that’s derived immediately from pixels. To do that, they moreover make use of cutting-edge motion recognition fashions to produce supplementary knowledge primarily based on the contextualized look of the folks and the setting in a Lagrangian framework. They particularly document the contextualized look attributes localized round every monitor by intensively operating such fashions throughout the route of every monitor.
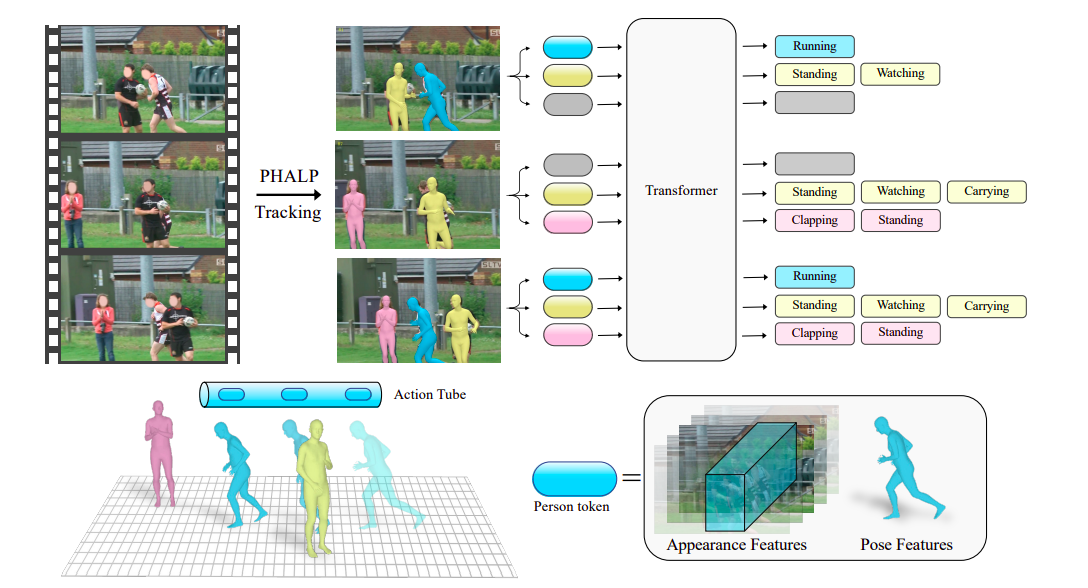
Their tokens, that are processed by motion recognition backbones, comprise express info on the 3D stance of the people in addition to extremely sampled look knowledge from the pixels. On the tough AVA v2.2 dataset, their entire system exceeds the prior cutting-edge by a major margin of two.8 mAP. Total, their key contribution is the introduction of a strategy that emphasizes the advantages of monitoring and 3D poses for comprehending human motion. Researchers from UC Berkeley and Meta AI counsel a Lagrangian Motion Recognition with Monitoring (LART) methodology that makes use of folks’s tracks to forecast their actions. Their baseline model outperforms earlier baselines that used posture info utilizing trackless trajectories and 3D pose representations of the individuals within the video. Moreover, they present that the usual baselines that solely think about look and context from the video could also be readily built-in with the steered Lagrangian viewpoint of motion detection, yielding notable enhancements over the predominant paradigm.
Examine Out The Paper, Github, and Project Page. Don’t overlook to affix our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra. When you’ve got any questions concerning the above article or if we missed something, be at liberty to e mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Aneesh Tickoo is a consulting intern at MarktechPost. He’s presently pursuing his undergraduate diploma in Knowledge Science and Synthetic Intelligence from the Indian Institute of Expertise(IIT), Bhilai. He spends most of his time engaged on initiatives geared toward harnessing the facility of machine studying. His analysis curiosity is picture processing and is captivated with constructing options round it. He loves to attach with folks and collaborate on attention-grabbing initiatives.



