Meet NerfDiff: An AI Framework To Allow Excessive-High quality and Constant A number of Views Synthesis From a Single Picture
The synthesis of latest views is a sizzling matter in laptop graphics and imaginative and prescient purposes, comparable to digital and augmented actuality, immersive pictures, and the event of digital replicas. The target is to generate further views of an object or a scene primarily based on restricted preliminary viewpoints. This process is especially demanding as a result of the newly synthesized views should think about occluded areas and beforehand unseen areas.
Lately, neural radiance fields (NeRF) have demonstrated distinctive leads to producing high-quality novel views. Nonetheless, NeRF depends on a major variety of photos, starting from tens to tons of, to successfully seize the scene, making it prone to overfitting and missing the power to generalize to new scenes.
Earlier makes an attempt have launched generalizable NeRF fashions that situation the NeRF illustration primarily based on the projection of 3D factors and extracted picture options. These approaches yield passable outcomes, significantly for views near the enter picture. Nonetheless, when the goal views considerably differ from the enter, these strategies produce blurry outcomes. The problem lies in resolving the uncertainty related to massive unseen areas within the novel views.
An alternate method to sort out the uncertainty downside in single-image view synthesis entails using 2D generative fashions that predict novel views whereas conditioning on the enter view. Nonetheless, the danger for these strategies is the shortage of consistency in picture era with the underlying 3D construction.
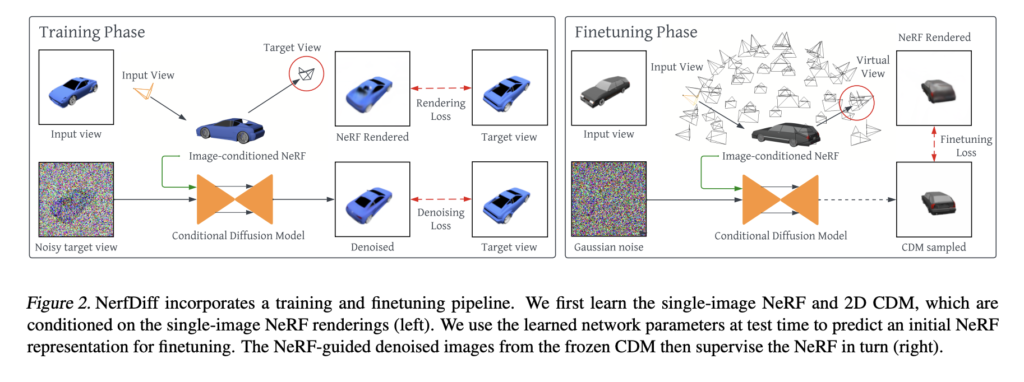
For this objective, a brand new method referred to as NerfDiff has been introduced. NerfDiff is a framework designed for synthesizing high-quality multi-view constant photos primarily based on single-view enter. An summary of the workflow is introduced within the determine beneath.

The proposed method consists of two phases: coaching and finetuning.
Through the coaching stage, a camera-space triplane-based NeRF mannequin and a 3D-aware conditional diffusion mannequin (CDM) are collectively skilled on a group of scenes. The NeRF illustration is initialized utilizing the enter picture on the finetuning stage. Then, the parameters of the NeRF mannequin are adjusted primarily based on a set of digital photos generated by the CDM, which is conditioned on the NeRF-rendered outputs. Nonetheless, a simple finetuning technique that optimizes the NeRF parameters instantly utilizing the CDM outputs produces low-quality renderings as a result of multi-view inconsistency of the CDM outputs. To handle this subject, the researchers suggest NeRF-guided distillation, an alternating course of that updates the NeRF illustration and guides the multi-view diffusion course of. Particularly, this method permits the decision of uncertainty in single-image view synthesis by leveraging the extra info offered by the CDM. Concurrently, the NeRF mannequin guides the CDM to make sure multi-view consistency throughout the diffusion course of.
A number of the outcomes obtained by NerfDiff are reported right here beneath (the place NGD stands for Nerf-Guided Distillation).

This was the abstract of NerfDiff, a novel AI framework to allow high-quality and constant a number of views from a single enter picture. In case you are , you’ll be able to study extra about this method within the hyperlinks beneath.
Try the Paper and Project. Don’t overlook to affix our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra. In case you have any questions concerning the above article or if we missed something, be at liberty to electronic mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Daniele Lorenzi acquired his M.Sc. in ICT for Web and Multimedia Engineering in 2021 from the College of Padua, Italy. He’s a Ph.D. candidate on the Institute of Data Know-how (ITEC) on the Alpen-Adria-Universität (AAU) Klagenfurt. He’s at the moment working within the Christian Doppler Laboratory ATHENA and his analysis pursuits embrace adaptive video streaming, immersive media, machine studying, and QoS/QoE analysis.



