Discovering Temporal Patterns in Twitter Posts: Exploratory Information Evaluation with Python | by Dmitrii Eliuseev | Could, 2023
Clustering of Twitter knowledge with Python, Ok-Means, and t-SNE

Within the article “What People Write about Climate” I analyzed Twitter posts utilizing pure language processing, vectorization, and clustering. Utilizing this method, it’s doable to search out distinct teams in unstructured textual content knowledge, for instance, to extract messages about ice melting or about electrical transport from hundreds of tweets about local weather. Through the processing of this knowledge, one other query arose: what if we might apply the identical algorithm to not the messages themselves however to the time when these messages had been printed? It will permit us to research when and how usually totally different individuals make posts on social media. It may be vital not solely from sociological or psychological views however, as we’ll see later, additionally for detecting bots or customers sending spam. Final however not least, nearly all people is utilizing social platforms these days, and it’s simply fascinating to be taught one thing new about us. Clearly, the identical algorithm can be utilized not just for Twitter posts however for any media platform.
Methodology
I’ll use principally the identical method as described within the first half about Twitter knowledge evaluation. Our knowledge processing pipeline will include a number of steps:
- Gathering tweets together with the precise hashtag and saving them in a CSV file. This was already carried out within the earlier article, so I’ll skip the small print right here.
- Discovering the overall properties of the collected knowledge.
- Calculating embedding vectors for every person primarily based on the time of their posts.
- Clustering the info utilizing the Ok-Means algorithm.
- Analyzing the outcomes.
Let’s get began.
1. Loading the info
I will probably be utilizing the Tweepy library to gather Twitter posts. Extra particulars might be discovered within the first part; right here I’ll solely publish the supply code:
import tweepyapi_key = "YjKdgxk..."
api_key_secret = "Qa6ZnPs0vdp4X...."
auth = tweepy.OAuth2AppHandler(api_key, api_key_secret)
api = tweepy.API(auth, wait_on_rate_limit=True)
hashtag = "#local weather"
language = "en"
def text_filter(s_data: str) -> str:
""" Take away further characters from textual content """
return s_data.change("&", "and").change(";", " ").change(",", " ")
.change('"', " ").change("n", " ").change(" ", " ")
def get_hashtags(tweet) -> str:
""" Parse retweeted knowledge """
hash_tags = ""
if 'hashtags' in tweet.entities:
hash_tags = ','.be part of(map(lambda x: x["text"], tweet.entities['hashtags']))
return hash_tags
def get_csv_header() -> str:
""" CSV header """
return "id;created_at;user_name;user_location;user_followers_count;user_friends_count;retweets_count;favorites_count;retweet_orig_id;retweet_orig_user;hash_tags;full_text"
def tweet_to_csv(tweet):
""" Convert a tweet knowledge to the CSV string """
if not hasattr(tweet, 'retweeted_status'):
full_text = text_filter(tweet.full_text)
hasgtags = get_hashtags(tweet)
retweet_orig_id = ""
retweet_orig_user = ""
favs, retweets = tweet.favorite_count, tweet.retweet_count
else:
retweet = tweet.retweeted_status
retweet_orig_id = retweet.id
retweet_orig_user = retweet.person.screen_name
full_text = text_filter(retweet.full_text)
hasgtags = get_hashtags(retweet)
favs, retweets = retweet.favorite_count, retweet.retweet_count
s_out = f"{tweet.id};{tweet.created_at};{tweet.person.screen_name};{addr_filter(tweet.person.location)};{tweet.person.followers_count};{tweet.person.friends_count};{retweets};{favs};{retweet_orig_id};{retweet_orig_user};{hasgtags};{full_text}"
return s_out
if __name__ == "__main__":
pages = tweepy.Cursor(api.search_tweets, q=hashtag, tweet_mode='prolonged',
result_type="latest",
depend=100,
lang=language).pages(restrict)
with open("tweets.csv", "a", encoding="utf-8") as f_log:
f_log.write(get_csv_header() + "n")
for ind, web page in enumerate(pages):
for tweet in web page:
# Get knowledge per tweet
str_line = tweet_to_csv(tweet)
# Save to CSV
f_log.write(str_line + "n")
Utilizing this code, we are able to get all Twitter posts with a particular hashtag, made inside the final 7 days. A hashtag is definitely our search question, we are able to discover posts about local weather, politics, or some other matter. Optionally, a language code permits us to go looking posts in several languages. Readers are welcome to do further analysis on their very own; for instance, it may be fascinating to check the outcomes between English and Spanish tweets.
After the CSV file is saved, let’s load it into the dataframe, drop the undesirable columns, and see what sort of knowledge now we have:
import pandas as pddf = pd.read_csv("local weather.csv", sep=';', dtype={'id': object, 'retweet_orig_id': object, 'full_text': str, 'hash_tags': str}, parse_dates=["created_at"], lineterminator='n')
df.drop(["retweet_orig_id", "user_friends_count", "retweets_count", "favorites_count", "user_location", "hash_tags", "retweet_orig_user", "user_followers_count"], inplace=True, axis=1)
df = df.drop_duplicates('id')
with pd.option_context('show.max_colwidth', 80):
show(df)
In the identical approach, as within the first half, I used to be getting Twitter posts with the hashtag “#local weather”. The end result appears like this:

We really don’t want the textual content or person id, however it may be helpful for “debugging”, to see how the unique tweet appears. For future processing, we might want to know the day, time, and hour of every tweet. Let’s add columns to the dataframe:
def get_time(dt: datetime.datetime):
""" Get time and minute from datetime """
return dt.time()def get_date(dt: datetime.datetime):
""" Get date from datetime """
return dt.date()
def get_hour(dt: datetime.datetime):
""" Get time and minute from datetime """
return dt.hour
df["date"] = df['created_at'].map(get_date)
df["time"] = df['created_at'].map(get_time)
df["hour"] = df['created_at'].map(get_hour)
We are able to simply confirm the outcomes:
show(df[["user_name", "date", "time", "hour"]])

Now now we have all of the wanted data, and we’re able to go.
2. Normal Insights
As we might see from the final screenshot, 199,278 messages had been loaded; these are messages with a “#Local weather” hashtag, which I collected inside a number of weeks. As a warm-up, let’s reply a easy query: what number of messages per day about local weather had been individuals posting on common?
First, let’s calculate the overall variety of days and the overall variety of customers:
days_total = df['date'].distinctive().form[0]
print(days_total)
# > 46users_total = df['user_name'].distinctive().form[0]
print(users_total)
# > 79985
As we are able to see, the info was collected over 46 days, and in complete, 79,985 Twitter customers posted (or reposted) at the very least one message with the hashtag “#Local weather” throughout that point. Clearly, we are able to solely depend customers who made at the very least one submit; alas, we can’t get the variety of readers this manner.
Let’s discover the variety of messages per day for every person. First, let’s group the dataframe by person title:
gr_messages_per_user = df.groupby(['user_name'], as_index=False).measurement().sort_values(by=['size'], ascending=False)
gr_messages_per_user["size_per_day"] = gr_messages_per_user['size'].div(days_total)
The “measurement” column offers us the variety of messages each person despatched. I additionally added the “size_per_day” column, which is simple to calculate by dividing the overall variety of messages by the overall variety of days. The end result appears like this:

We are able to see that probably the most lively customers are posting as much as 18 messages per day, and probably the most inactive customers posted only one message inside this 46-day interval (1/46 = 0,0217). Let’s draw a histogram utilizing NumPy and Bokeh:
import numpy as np
from bokeh.io import present, output_notebook, export_png
from bokeh.plotting import determine, output_file
from bokeh.fashions import ColumnDataSource, LabelSet, Whisker
from bokeh.remodel import factor_cmap, factor_mark, cumsum
from bokeh.palettes import *
output_notebook()customers = gr_messages_per_user['user_name']
quantity = gr_messages_per_user['size_per_day']
hist_e, edges_e = np.histogram(quantity, density=False, bins=100)
# Draw
p = determine(width=1600, top=500, title="Messages per day distribution")
p.quad(prime=hist_e, backside=0, left=edges_e[:-1], proper=edges_e[1:], line_color="darkblue")
p.x_range.begin = 0
# p.x_range.finish = 150000
p.y_range.begin = 0
p.xaxis[0].ticker.desired_num_ticks = 20
p.left[0].formatter.use_scientific = False
p.beneath[0].formatter.use_scientific = False
p.xaxis.axis_label = "Messages per day, avg"
p.yaxis.axis_label = "Quantity of customers"
present(p)
The output appears like this:

Apparently, we are able to see just one bar. Of all 79,985 customers who posted messages with the “#Local weather” hashtag, nearly all of them (77,275 customers) despatched, on common, lower than a message per day. It appears stunning at first look, however really, how usually will we submit tweets in regards to the local weather? Actually, I by no means did it in all my life. We have to zoom the graph rather a lot to see different bars on the histogram:

Solely with this zoom degree can we see that amongst all 79,985 Twitter customers who posted one thing about “#Local weather”, there are lower than 100 “activists”, posting messages on daily basis! Okay, perhaps “local weather” shouldn’t be one thing individuals are making posts about each day, however is it the identical with different subjects? I created a helper perform, returning the share of “lively” customers who posted greater than N messages per day:
def get_active_users_percent(df_in: pd.DataFrame, messages_per_day_threshold: int):
""" Get share of lively customers with a messages-per-day threshold """
days_total = df_in['date'].distinctive().form[0]
users_total = df_in['user_name'].distinctive().form[0]
gr_messages_per_user = df_in.groupby(['user_name'], as_index=False).measurement()
gr_messages_per_user["size_per_day"] = gr_messages_per_user['size'].div(days_total)
users_active = gr_messages_per_user[gr_messages_per_user['size_per_day'] >= messages_per_day_threshold].form[0]
return 100*users_active/users_total
Then, utilizing the identical Tweepy code, I downloaded knowledge frames for six subjects from totally different domains. We are able to draw outcomes with Bokeh:
labels = ['#Climate', '#Politics', '#Cats', '#Humour', '#Space', '#War']
counts = [get_active_users_percent(df_climate, messages_per_day_threshold=1),
get_active_users_percent(df_politics, messages_per_day_threshold=1),
get_active_users_percent(df_cats, messages_per_day_threshold=1),
get_active_users_percent(df_humour, messages_per_day_threshold=1),
get_active_users_percent(df_space, messages_per_day_threshold=1),
get_active_users_percent(df_war, messages_per_day_threshold=1)]palette = Spectral6
supply = ColumnDataSource(knowledge=dict(labels=labels, counts=counts, shade=palette))
p = determine(width=1200, top=400, x_range=labels, y_range=(0,9),
title="Share of Twitter customers posting 1 or extra messages per day",
toolbar_location=None, instruments="")
p.vbar(x='labels', prime='counts', width=0.9, shade='shade', supply=supply)
p.xgrid.grid_line_color = None
p.y_range.begin = 0
present(p)
The outcomes are fascinating:

The preferred hashtag right here is “#Cats”. On this group, about 6.6% of customers make posts each day. Are their cats simply lovable, and so they can’t resist the temptation? Quite the opposite, “#Humour” is a well-liked matter with numerous messages, however the quantity of people that submit a couple of message per day is minimal. On extra severe subjects like “#Warfare” or “#Politics”, about 1.5% of customers make posts each day. And surprisingly, far more individuals are making each day posts about “#Area” in comparison with “#Humour”.
To make clear these digits in additional element, let’s discover the distribution of the variety of messages per person; it’s not straight related to message time, however it’s nonetheless fascinating to search out the reply:
def get_cumulative_percents_distribution(df_in: pd.DataFrame, steps=200):
""" Get a distribution of complete p.c of messages despatched by p.c of customers """
# Group dataframe by person title and kind by quantity of messages
df_messages_per_user = df_in.groupby(['user_name'], as_index=False).measurement().sort_values(by=['size'], ascending=False)
users_total = df_messages_per_user.form[0]
messages_total = df_messages_per_user["size"].sum()# Get cumulative messages/customers ratio
messages = []
share = np.arange(0, 100, 0.05)
for perc in share:
msg_count = df_messages_per_user[:int(perc*users_total/100)]["size"].sum()
messages.append(100*msg_count/messages_total)
return share, messages
This methodology calculates the overall variety of messages posted by probably the most lively customers. The quantity itself can strongly fluctuate for various subjects, so I take advantage of percentages as each outputs. With this perform, we are able to evaluate outcomes for various hashtags:
# Calculate
share, messages1 = get_cumulative_percent(df_climate)
_, messages2 = get_cumulative_percent(df_politics)
_, messages3 = get_cumulative_percent(df_cats)
_, messages4 = get_cumulative_percent(df_humour)
_, messages5 = get_cumulative_percent(df_space)
_, messages6 = get_cumulative_percent(df_war)labels = ['#Climate', '#Politics', '#Cats', '#Humour', '#Space', '#War']
messages = [messages1, messages2, messages3, messages4, messages5, messages6]
# Draw
palette = Spectral6
p = determine(width=1200, top=400,
title="Twitter messages per person share ratio",
x_axis_label='Share of customers',
y_axis_label='Share of messages')
for ind in vary(6):
p.line(share, messages[ind], line_width=2, shade=palette[ind], legend_label=labels[ind])
p.x_range.finish = 100
p.y_range.begin = 0
p.y_range.finish = 100
p.xaxis.ticker.desired_num_ticks = 10
p.legend.location = 'bottom_right'
p.toolbar_location = None
present(p)
As a result of each axes are “normalized” to 0..100%, it’s simple to check outcomes for various subjects:

Once more, the end result appears fascinating. We are able to see that the distribution is strongly skewed: 10% of probably the most lively customers are posting 50–60% of the messages (spoiler alert: as we’ll see quickly, not all of them are people;).
This graph was made by a perform that’s solely about 20 traces of code. This “evaluation” is fairly easy, however many further questions can come up. There’s a distinct distinction between totally different subjects, and discovering the reply to why it’s so is clearly not simple. Which subjects have the most important variety of lively customers? Are there cultural or regional variations, and is the curve the identical in several nations, just like the US, Russia, or Japan? I encourage readers to do some checks on their very own.
Now that we’ve received some primary insights, it’s time to do one thing more difficult. Let’s cluster all customers and attempt to discover some frequent patterns. To do that, first, we might want to convert the person’s knowledge into embedding vectors.
3. Making Person Embeddings
An embedded vector is an inventory of numbers that represents the info for every person. Within the earlier article, I received embedding vectors from tweet phrases and sentences. Now, as a result of I wish to discover patterns within the “temporal” area, I’ll calculate embeddings primarily based on the message time. However first, let’s discover out what the info appears like.
As a reminder, now we have a dataframe with all tweets, collected for a particular hashtag. Every tweet has a person title, creation date, time, and hour:

Let’s create a helper perform to indicate all tweet instances for a particular person:
def draw_user_timeline(df_in: pd.DataFrame, user_name: str):
""" Draw cumulative messages time for particular person """
df_u = df_in[df_in["user_name"] == user_name]
days_total = df_u['date'].distinctive().form[0]# Group messages by time of the day
messages_per_day = df_u.groupby(['time'], as_index=False).measurement()
msg_time = messages_per_day['time']
msg_count = messages_per_day['size']
# Draw
p = determine(x_axis_type='datetime', width=1600, top=150, title=f"Cumulative tweets timeline throughout {days_total} days: {user_name}")
p.vbar(x=msg_time, prime=msg_count, width=datetime.timedelta(seconds=30), line_color='black')
p.xaxis[0].ticker.desired_num_ticks = 30
p.xgrid.grid_line_color = None
p.toolbar_location = None
p.x_range.begin = datetime.time(0,0,0)
p.x_range.finish = datetime.time(23,59,0)
p.y_range.begin = 0
p.y_range.finish = 1
present(p)
draw_user_timeline(df, user_name="UserNameHere")
...
The end result appears like this:

Right here we are able to see messages made by some customers inside a number of weeks, displayed on the 00–24h timeline. We could already see some patterns right here, however because it turned out, there may be one drawback. The Twitter API doesn’t return a time zone. There’s a “timezone” area within the message physique, however it’s at all times empty. Perhaps after we see tweets within the browser, we see them in our native time; on this case, the unique timezone is simply not vital. Or perhaps it’s a limitation of the free account. Anyway, we can’t cluster the info correctly if one person from the US begins sending messages at 2 AM UTC and one other person from India begins sending messages at 13 PM UTC; each timelines simply won’t match collectively.
As a workaround, I attempted to “estimate” the timezone myself by utilizing a easy empirical rule: most individuals are sleeping at night time, and extremely doubtless, they aren’t posting tweets at the moment 😉 So, we are able to discover the 9-hour interval, the place the typical variety of messages is minimal, and assume that it is a “night time” time for that person.
def get_night_offset(hours: Record):
""" Estimate the night time place by calculating the rolling common minimal """
night_len = 9
min_pos, min_avg = 0, 99999
# Discover the minimal place
knowledge = np.array(hours + hours)
for p in vary(24):
avg = np.common(knowledge[p:p + night_len])
if avg <= min_avg:
min_avg = avg
min_pos = p# Transfer the place proper if doable (in case of lengthy sequence of comparable numbers)
for p in vary(min_pos, len(knowledge) - night_len):
avg = np.common(knowledge[p:p + night_len])
if avg <= min_avg:
min_avg = avg
min_pos = p
else:
break
return min_pos % 24
def normalize(hours: Record):
""" Transfer the hours array to the precise, protecting the 'night time' time on the left """
offset = get_night_offset(hours)
knowledge = hours + hours
return knowledge[offset:offset+24]
Virtually, it really works nicely in circumstances like this, the place the “night time” interval might be simply detected:

In fact, some individuals get up at 7 AM and a few at 10 AM, and with no time zone, we can’t discover it. Anyway, it’s higher than nothing, and as a “baseline”, this algorithm can be utilized.
Clearly, the algorithm doesn’t work in circumstances like that:

On this instance, we simply don’t know if this person was posting messages within the morning, within the night, or after lunch; there isn’t a details about that. However it’s nonetheless fascinating to see that some customers are posting messages solely at a particular time of the day. On this case, having a “digital offset” remains to be useful; it permits us to “align” all person timelines, as we’ll see quickly within the outcomes.
Now let’s calculate the embedding vectors. There might be alternative ways of doing this. I made a decision to make use of vectors within the type of [SumTotal, Sum00,.., Sum23], the place SumTotal is the overall quantity of messages made by a person, and Sum00..Sum23 are the overall variety of messages made by every hour of the day. We are able to use Panda’s groupby methodology with two parameters “user_name” and “hour”, which does nearly all of the wanted calculations for us:
def get_vectorized_users(df_in: pd.DataFrame):
""" Get embedding vectors for all customers
Embedding format: [total hours, total messages per hour-00, 01, .. 23]
"""
gr_messages_per_user = df_in.groupby(['user_name', 'hour'], as_index=True).measurement()vectors = []
customers = gr_messages_per_user.index.get_level_values('user_name').distinctive().values
for ind, person in enumerate(customers):
if ind % 10000 == 0:
print(f"Processing {ind} of {customers.form[0]}")
hours_all = [0]*24
for hr, worth in gr_messages_per_user[user].objects():
hours_all[hr] = worth
hours_norm = normalize(hours_all)
vectors.append([sum(hours_norm)] + hours_norm)
return customers, np.asarray(vectors)
all_users, vectorized_users = get_vectorized_users(df)
Right here, the “get_vectorized_users” methodology is doing the calculation. After calculating every 00..24h vector, I take advantage of the “normalize” perform to use the “timezone” offset, as was described earlier than.
Virtually, the embedding vector for a comparatively lively person could appear like this:
[120 0 0 0 0 0 0 0 0 0 1 2 0 2 2 1 0 0 0 0 0 18 44 50 0]
Right here 120 is the overall variety of messages, and the remainder is a 24-digit array with the variety of messages made inside each hour (as a reminder, in our case, the info was collected inside 46 days). For the inactive person, the embedding could appear like this:
[4 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 1 1 1 0 0 0 0]
Completely different embedding vectors may also be created, and a extra difficult scheme can present higher outcomes. For instance, it might be fascinating so as to add a complete variety of “lively” hours per day or to incorporate a day of the week into the vector to see how the person’s exercise varies between working days and weekends, and so forth.
4. Clustering
As within the previous article, I will probably be utilizing the Ok-Means algorithm to search out the clusters. First, let’s discover the optimum Ok-value utilizing the Elbow method:
import matplotlib.pyplot as plt
%matplotlib inlinedef graw_elbow_graph(x: np.array, k1: int, k2: int, k3: int):
k_values, inertia_values = [], []
for okay in vary(k1, k2, k3):
print("Processing:", okay)
km = KMeans(n_clusters=okay).match(x)
k_values.append(okay)
inertia_values.append(km.inertia_)
plt.determine(figsize=(12,4))
plt.plot(k_values, inertia_values, 'o')
plt.title('Inertia for every Ok')
plt.xlabel('Ok')
plt.ylabel('Inertia')
graw_elbow_graph(vectorized_users, 2, 20, 1)
The end result appears like this:

Let’s write the strategy to calculate the clusters and draw the timelines for some customers:
def get_clusters_kmeans(x, okay):
""" Get clusters utilizing Ok-Means """
km = KMeans(n_clusters=okay).match(x)
s_score = silhouette_score(x, km.labels_)
print(f"Ok={okay}: Silhouette coefficient {s_score:0.2f}, inertia:{km.inertia_}")sample_silhouette_values = silhouette_samples(x, km.labels_)
silhouette_values = []
for i in vary(okay):
cluster_values = sample_silhouette_values[km.labels_ == i]
silhouette_values.append((i, cluster_values.form[0], cluster_values.imply(), cluster_values.min(), cluster_values.max()))
silhouette_values = sorted(silhouette_values, key=lambda tup: tup[2], reverse=True)
for s in silhouette_values:
print(f"Cluster {s[0]}: Measurement:{s[1]}, avg:{s[2]:.2f}, min:{s[3]:.2f}, max: {s[4]:.2f}")
print()
# Create new dataframe
data_len = x.form[0]
cdf = pd.DataFrame({
"id": all_users,
"vector": [str(v) for v in vectorized_users],
"cluster": km.labels_,
})
# Present prime clusters
for cl in silhouette_values[:10]:
df_c = cdf[cdf['cluster'] == cl[0]]
# Present cluster
print("Cluster:", cl[0], cl[2])
with pd.option_context('show.max_colwidth', None):
show(df_c[["id", "vector"]][:20])
# Present first customers
for person in df_c["id"].values[:10]:
draw_user_timeline(df, user_name=person)
print()
return km.labels_
clusters = get_clusters_kmeans(vectorized_users, okay=5)
This methodology is generally the identical as within the earlier half; the one distinction is that I draw person timelines for every cluster as an alternative of a cloud of phrases.
5. Outcomes
Lastly, we’re able to see the outcomes. Clearly, not all teams had been completely separated, however a number of the classes are fascinating to say. As a reminder, I used to be analyzing all tweets of customers who made posts with the “#Local weather” hashtag inside 46 days. So, what clusters can we see in posts about local weather?
“Inactive” customers, who despatched only one–2 messages inside a month. This group is the most important; as was mentioned above, it represents greater than 95% of all customers. And the Ok-Means algorithm was capable of detect this cluster as the most important one. Timelines for these customers appear like this:

“” customers. These customers posted tweets each 2–5 days, so I can assume that they’ve at the very least some form of curiosity on this matter.

“Lively” customers. These customers are posting greater than a number of messages per day:

We don’t know if these individuals are simply “activists” or in the event that they recurrently submit tweets as part of their job, however at the very least we are able to see that their on-line exercise is fairly excessive.
“Bots”. These customers are extremely unlikely to be people in any respect. Not surprisingly, they’ve the best variety of posted messages. In fact, I’ve no 100% proof that each one these accounts belong to bots, however it’s unlikely that any human can submit messages so recurrently with out relaxation and sleep:

The second “person”, for instance, is posting tweets on the identical time of day with 1-second accuracy; its tweets can be utilized as an NTP server 🙂
By the way in which, another “customers” should not actually lively, however their datetime sample appears suspicious. This “person” has not so many messages, and there’s a seen “day/night time” sample, so it was not clustered as a “bot”. However for me, it appears unrealistic that an strange person can publish messages strictly initially of every hour:

Perhaps the auto-correlation perform can present good ends in detecting all customers with suspiciously repetitive exercise.
“Clones”. If we run a Ok-Means algorithm with greater values of Ok, we are able to additionally detect some “clones”. These clusters have similar time patterns and the best silhouette values. For instance, we are able to see a number of accounts with similar-looking nicknames that solely differ within the final characters. Most likely, the script is posting messages from a number of accounts in parallel:

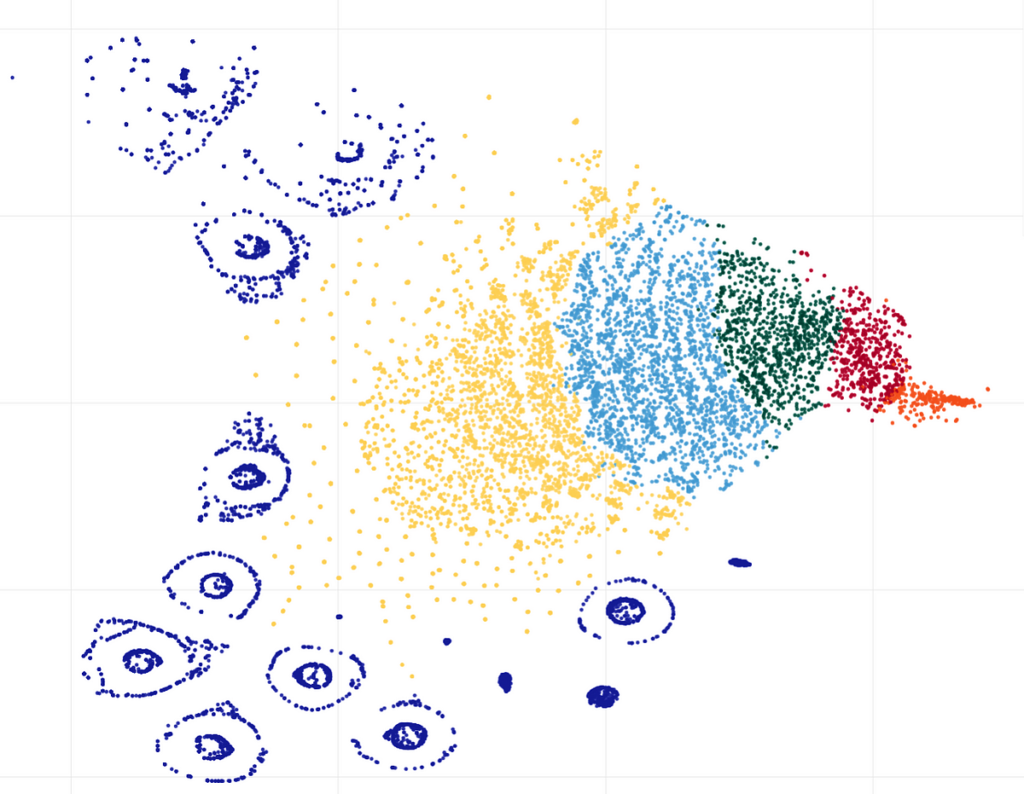
As a final step, we are able to see clusters visualization, made by the t-SNE (t-distributed Stochastic Neighbor Embedding) algorithm, which appears fairly lovely:

Right here we are able to see numerous smaller clusters that weren’t detected by the Ok-Means with Ok=5. On this case, it is sensible to strive greater Ok values; perhaps one other algorithm like DBSCAN (Density-based spatial clustering of functions with noise) may also present good outcomes.
Conclusion
Utilizing knowledge clustering, we had been capable of finding distinctive patterns in tens of hundreds of tweets about “#Local weather”, made by totally different customers. The evaluation itself was made solely by utilizing the time of tweet posts. This may be helpful in sociology or cultural anthropology research; for instance, we are able to evaluate the web exercise of various customers on totally different subjects, work out how usually they make social community posts, and so forth. Time evaluation is language-agnostic, so it is usually doable to check outcomes from totally different geographical areas, for instance, on-line exercise between English- and Japanese-speaking customers. Time-based knowledge may also be helpful in psychology or drugs; for instance, it’s doable to determine what number of hours individuals are spending on social networks or how usually they make pauses. And as was demonstrated above, discovering patterns in customers “habits” might be helpful not just for analysis functions but in addition for purely “sensible” duties like detecting bots, “clones”, or customers posting spam.
Alas, not all evaluation was profitable as a result of the Twitter API doesn’t present timezone knowledge. For instance, it will be fascinating to see if individuals are posting extra messages within the morning or within the night, however with out having a correct time, it’s inconceivable; all messages returned by the Twitter API are in UTC time. However anyway, it’s nice that the Twitter API permits us to get massive quantities of information even with a free account. And clearly, the concepts described on this submit can be utilized not just for Twitter however for different social networks as nicely.
When you loved this story, be at liberty to subscribe to Medium, and you’re going to get notifications when my new articles will probably be printed, in addition to full entry to hundreds of tales from different authors.
Thanks for studying.