New Google AI Report Exhibits Knowledge Enhancements And Scaling Insights That Have Enabled Its New Palm2 Massive Language Mannequin
For a very long time, the next-word prediction was the go-to methodology for estimating the linguistic data current, making language modeling a significant research space. Over the previous few years, massive language fashions (LLMs) have demonstrated spectacular efficiency in reasoning, math, science, and language issues because of higher scale and the Transformer structure. Increasing the mannequin measurement and knowledge amount has performed important roles in these breakthroughs. Most LLMs nonetheless keep on with a tried-and-true components, together with primarily monolingual corpora and a language modeling objective.
Latest Google analysis presents PaLM 2, an up to date model of the PaLM language mannequin that includes new modeling, knowledge, and scaling developments. PaLM 2 integrates all kinds of latest findings from a number of fields of research, together with:
- Rationalization by computation: Knowledge measurement has lately been proven to be a minimum of as related as mannequin measurement by means of compute-optimal scaling. This research debunks the standard knowledge that it’s higher to scale the mannequin 3 times as shortly because the dataset if customers need optimum efficiency for his or her coaching computation.
- The mixing of information units improved: Many of the textual content in earlier massive pre-trained language fashions was in English. With a whole bunch of languages and domains in thoughts (reminiscent of programming, arithmetic, and parallel multilingual texts), the crew has developed a extra multilingual and various pretraining combination. The findings show that extra complicated fashions can successfully cope with extra various non-English datasets and make use of deduplication to lower reminiscence with out negatively impacting English language understanding skill.
- Up to now, LLMs have sometimes relied on both a single causal or hid objective. The proposed mannequin structure relies on the Transformer, which has been proven to enhance each structure and goal metrics. The researchers used a rigorously balanced mixture of pretraining aims to coach this mannequin to understand a variety of linguistic sides.
The findings reveal that PaLM 2 fashions carry out a lot better than PaLM on a variety of duties, reminiscent of producing pure language, translating it, and reasoning. Although it requires extra coaching compute than the most important PaLM mannequin, the PaLM 2-L mannequin, the most important within the PaLM 2 household, is far smaller. These findings level to options to mannequin scaling for enhancing efficiency, reminiscent of rigorously deciding on the information and having environment friendly structure/aims that may unlock efficiency. Having a smaller mannequin that’s however prime quality improves inference effectivity, decreases serving prices, and opens the door for the mannequin for use in additional downstream purposes and by extra customers.
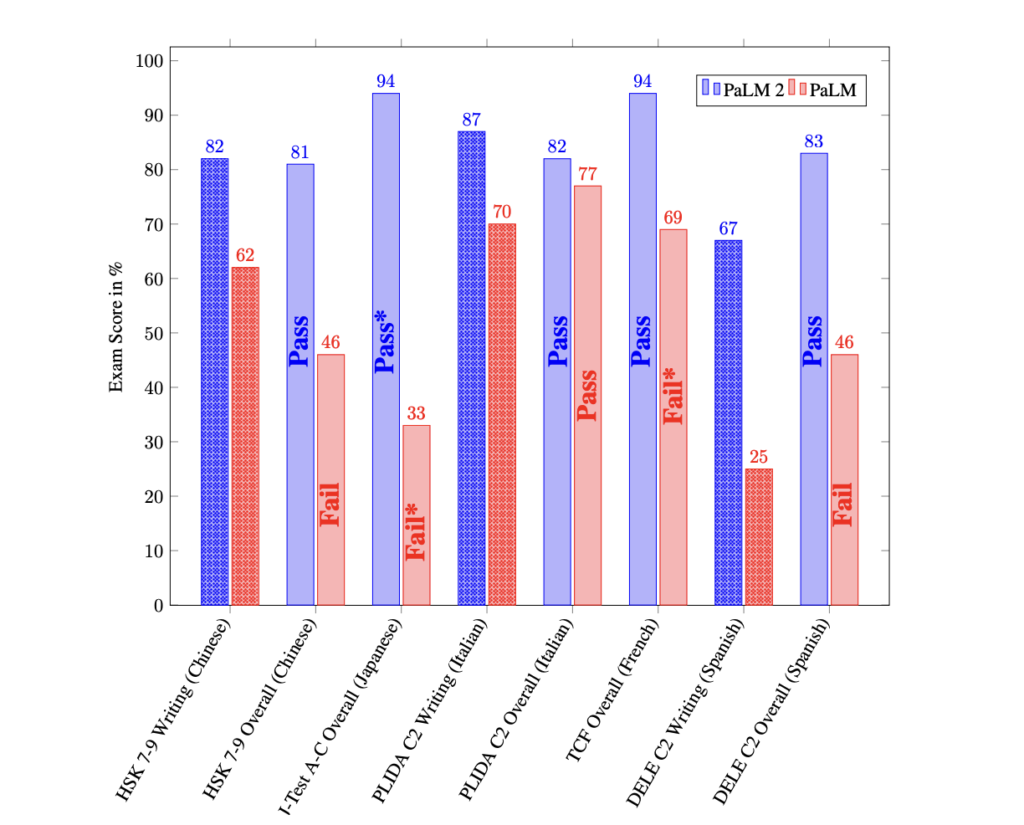
The language, code manufacturing, and reasoning skills of PaLM 2 throughout languages are spectacular. It outperforms its predecessor on superior language proficiency exams within the wild by a large margin.
By altering solely a subset of pretraining, PaLM 2 permits inference-time management over toxicity by means of management tokens. PaLM 2’s pretraining knowledge had been augmented with novel ‘canary’ token sequences to facilitate higher cross-lingual reminiscence evaluations. After evaluating PaLM and PaLM 2, the researchers discovered that the latter has decrease common charges of verbatim memorization. For tail languages, memorizing charges solely improve above English when knowledge is repeated quite a few instances all through texts. The group demonstrates that PaLM 2 has enhanced multilingual toxicity classification capabilities and assesses the dangers and biases related to a number of potential purposes.
The crew believes that modifications to the structure and goal, in addition to further scaling of mannequin parameters and dataset measurement and high quality, can proceed to generate developments in language interpretation and era.
Try the Paper. Don’t overlook to affix our 22k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra. If in case you have any questions concerning the above article or if we missed something, be happy to electronic mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Tanushree Shenwai is a consulting intern at MarktechPost. She is at the moment pursuing her B.Tech from the Indian Institute of Expertise(IIT), Bhubaneswar. She is a Knowledge Science fanatic and has a eager curiosity within the scope of utility of synthetic intelligence in numerous fields. She is keen about exploring the brand new developments in applied sciences and their real-life utility.



