Meet XTREME-UP: A Benchmark for Evaluating Multilingual Fashions with Scarce Information Analysis, Specializing in Underneath-Represented Languages
The fields of Synthetic Intelligence and Machine Studying are solely dependent upon information. Everyone seems to be deluged with information from totally different sources like social media, healthcare, finance, and so forth., and this information is of nice use to functions involving Pure Language Processing. However even with a lot information, readily usable information is scarce for coaching an NLP mannequin for a specific activity. Discovering high-quality information with usefulness and good-quality filters is a tough activity. Particularly speaking about growing NLP fashions for various languages, the dearth of knowledge for many languages comes as a limitation that hinders progress in NLP for under-represented languages (ULs).
The rising duties like information summarization, sentiment evaluation, query answering, or the event of a digital assistant all closely depend on information availability in high-resource languages. These duties are dependent upon applied sciences like language identification, computerized speech recognition (ASR), or optical character recognition (OCR), that are largely unavailable for under-represented languages, to beat which it is very important construct datasets and consider fashions on duties that will be useful for UL audio system.
Not too long ago, a crew of researchers from GoogleAI has proposed a benchmark known as XTREME-UP (Underneath-Represented and Consumer-Centric with Paucal Information) that evaluates multilingual fashions on user-centric duties in a few-shot studying setting. It primarily focuses on actions that know-how customers typically carry out of their day-to-day lives, reminiscent of data entry and enter/output actions that allow different applied sciences. The three principal options that distinguish XTREME-UP are – its use of scarce information, its user-centric design, and its give attention to under-represented languages.
With XTREME-UP, the researchers have launched a standardized multilingual in-language fine-tuning setting rather than the traditional cross-lingual zero-shot choice. This technique considers the quantity of knowledge that may be generated or annotated in an 8-hour interval for a specific language, thus aiming to present the ULs a extra helpful analysis setup.
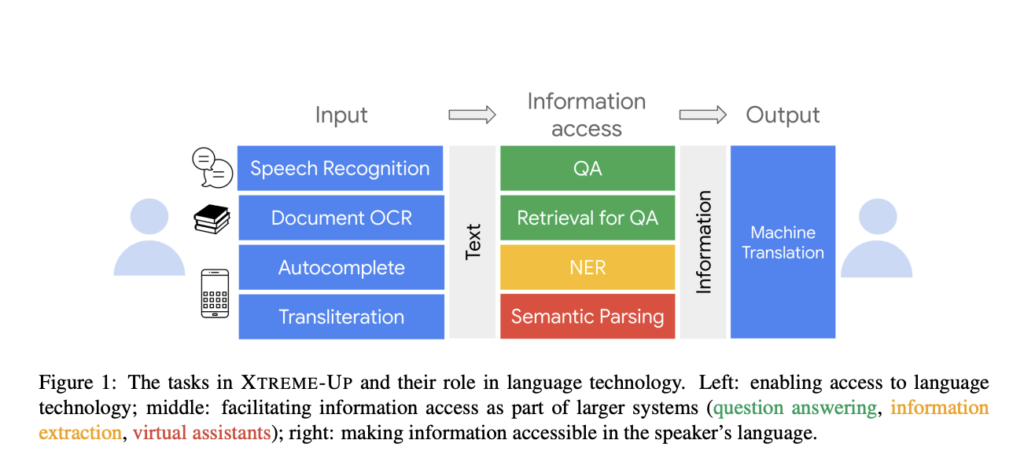
XTREME-UP assesses the efficiency of language fashions throughout 88 under-represented languages in 9 important user-centric applied sciences, a few of which embody Computerized Speech Recognition (ASR), Optical Character Recognition (OCR), Machine Translation (MT), and data entry duties which have common utility. The researchers have developed new datasets particularly for operations like OCR, autocomplete, semantic parsing, and transliteration as a way to consider the capabilities of the language fashions. They’ve additionally improved and polished the at the moment current datasets for different duties in the identical benchmark.
XTREME-UP has considered one of its key talents to evaluate numerous modeling conditions, together with each text-only and multi-modal eventualities with visible, audio, and textual content inputs. It additionally presents strategies for supervised parameter adjustment and in-context studying, permitting for a radical evaluation of assorted modeling approaches. The duties in XTREME-UP contain enabling entry to language know-how, enabling data entry as half of a bigger system reminiscent of query answering, data extraction, and digital assistants, adopted by making data accessible within the speaker’s language.
Consequently, XTREME-UP is a good benchmark that addresses the info shortage problem in extremely multilingual NLP techniques. It’s a standardized analysis framework for under-represented language and appears actually helpful for future NLP analysis and developments.
Try the Paper and Github. Don’t neglect to affix our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI tasks, and extra. If in case you have any questions concerning the above article or if we missed something, be happy to e-mail us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
Tanya Malhotra is a ultimate 12 months undergrad from the College of Petroleum & Power Research, Dehradun, pursuing BTech in Laptop Science Engineering with a specialization in Synthetic Intelligence and Machine Studying.
She is a Information Science fanatic with good analytical and important considering, together with an ardent curiosity in buying new expertise, main teams, and managing work in an organized method.



