How Vericast optimized function engineering utilizing Amazon SageMaker Processing
This put up is co-written by Jyoti Sharma and Sharmo Sarkar from Vericast.
For any machine studying (ML) downside, the info scientist begins by working with information. This consists of gathering, exploring, and understanding the enterprise and technical points of the info, together with analysis of any manipulations that could be wanted for the mannequin constructing course of. One side of this information preparation is function engineering.
Characteristic engineering refers back to the course of the place related variables are recognized, chosen, and manipulated to remodel the uncooked information into extra helpful and usable varieties to be used with the ML algorithm used to coach a mannequin and carry out inference towards it. The objective of this course of is to extend the efficiency of the algorithm and ensuing predictive mannequin. The function engineering course of entails a number of levels, together with function creation, information transformation, function extraction, and have choice.
Constructing a platform for generalized function engineering is a typical activity for patrons needing to supply many ML fashions with differing datasets. This type of platform consists of the creation of a programmatically pushed course of to supply finalized, function engineered information prepared for mannequin coaching with little human intervention. Nevertheless, generalizing function engineering is difficult. Every enterprise downside is completely different, every dataset is completely different, information volumes differ wildly from shopper to shopper, and information high quality and infrequently cardinality of a sure column (within the case of structured information) may play a major position within the complexity of the function engineering course of. Moreover, the dynamic nature of a buyer’s information may also end in a big variance of the processing time and sources required to optimally full the function engineering.
AWS buyer Vericast is a advertising options firm that makes data-driven selections to spice up advertising ROIs for its shoppers. Vericast’s inner cloud-based Machine Studying Platform, constructed across the CRISP-ML(Q) course of, makes use of numerous AWS providers, together with Amazon SageMaker, Amazon SageMaker Processing, AWS Lambda, and AWS Step Functions, to supply the absolute best fashions which can be tailor-made to the particular shopper’s information. This platform goals at capturing the repeatability of the steps that go into constructing numerous ML workflows and bundling them into normal generalizable workflow modules inside the platform.
On this put up, we share how Vericast optimized function engineering utilizing SageMaker Processing.
Resolution overview
Vericast’s Machine Studying Platform aids within the faster deployment of recent enterprise fashions based mostly on current workflows or faster activation of current fashions for brand spanking new shoppers. For instance, a mannequin predicting unsolicited mail propensity is kind of completely different from a mannequin predicting low cost coupon sensitivity of the purchasers of a Vericast shopper. They resolve completely different enterprise issues and due to this fact have completely different utilization situations in a advertising marketing campaign design. However from an ML standpoint, each will be construed as binary classification fashions, and due to this fact might share many frequent steps from an ML workflow perspective, together with mannequin tuning and coaching, analysis, interpretability, deployment, and inference.
As a result of these fashions are binary classification issues (in ML phrases), we’re separating the purchasers of an organization into two lessons (binary): those who would reply positively to the marketing campaign and those who wouldn’t. Moreover, these examples are thought of an imbalanced classification as a result of the info used to coach the mannequin wouldn’t include an equal variety of clients who would and wouldn’t reply favorably.
The precise creation of a mannequin corresponding to this follows the generalized sample proven within the following diagram.
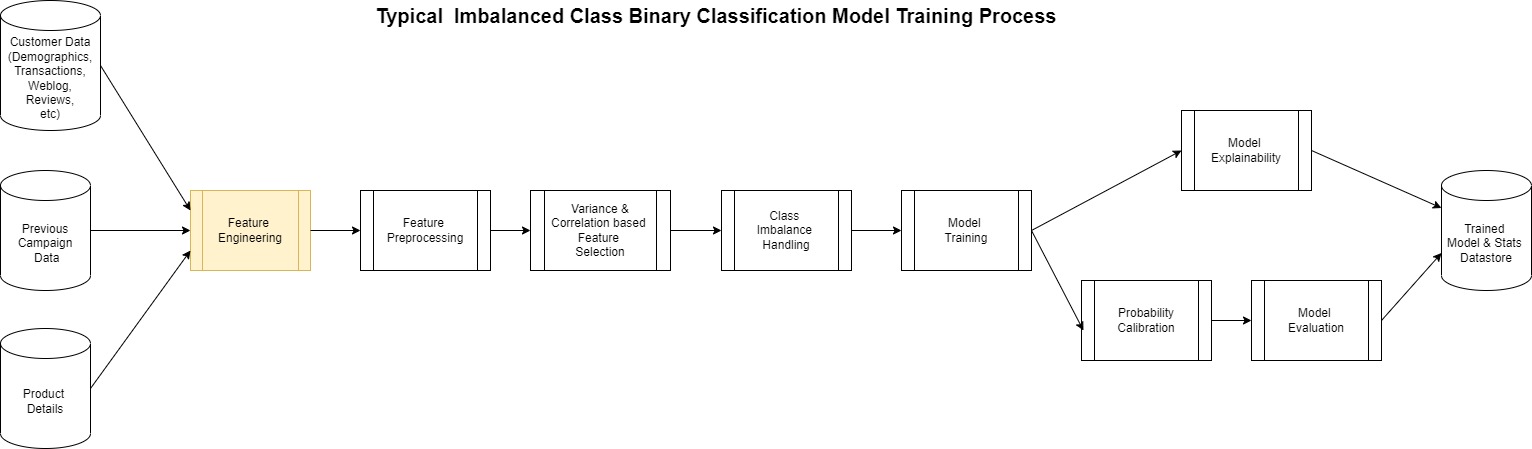
Most of this course of is identical for any binary classification aside from the function engineering step. That is maybe probably the most sophisticated but at instances neglected step within the course of. ML fashions are largely depending on the options used to create it.
Vericast’s cloud-native Machine Studying Platform goals to generalize and automate the function engineering steps for numerous ML workflows and optimize their efficiency on a value vs. time metric through the use of the next options:
- The platform’s function engineering library – This consists of an ever-evolving set of transformations which were examined to yield high-quality generalizable options based mostly on particular shopper ideas (for instance, buyer demographics, product particulars, transaction particulars, and so forth).
- Clever useful resource optimizers – The platform makes use of AWS’s on-demand infrastructure functionality to spin up probably the most optimum sort of processing sources for the actual function engineering job based mostly on the anticipated complexity of the step and the quantity of knowledge it must churn by.
- Dynamic scaling of function engineering jobs – A mix of varied AWS providers is used for this, however most notably SageMaker Processing. This ensures that the platform produces high-quality options in a cost-efficient and well timed method.
This put up is concentrated across the third level on this checklist and exhibits methods to obtain dynamic scaling of SageMaker Processing jobs to attain a extra managed, performant, and cost-effective information processing framework for big information volumes.
SageMaker Processing permits workloads that run steps for information preprocessing or postprocessing, function engineering, information validation, and mannequin analysis on SageMaker. It additionally gives a managed atmosphere and removes the complexity of undifferentiated heavy lifting required to arrange and preserve the infrastructure wanted to run the workloads. Moreover, SageMaker Processing gives an API interface for operating, monitoring, and evaluating the workload.
Operating SageMaker Processing jobs takes place absolutely inside a managed SageMaker cluster, with particular person jobs positioned into occasion containers at run time. The managed cluster, situations, and containers report metrics to Amazon CloudWatch, together with utilization of GPU, CPU, reminiscence, GPU reminiscence, disk metrics, and occasion logging.
These options present advantages to Vericast information engineers and scientists by helping within the improvement of generalized preprocessing workflows and abstracting the issue of sustaining generated environments through which to run them. Technical issues can come up, nonetheless, given the dynamic nature of the info and its diverse options that may be fed into such a common answer. The system should make an informed preliminary guess as to the scale of the cluster and situations that compose it. This guess wants to judge standards of the info and infer the CPU, reminiscence, and disk necessities. This guess could also be wholly applicable and carry out adequately for the job, however in different instances it might not. For a given dataset and preprocessing job, the CPU could also be undersized, leading to maxed out processing efficiency and prolonged instances to finish. Worse but, reminiscence might turn into a problem, leading to both poor efficiency or out of reminiscence occasions inflicting all the job to fail.
With these technical hurdles in thoughts, Vericast got down to create an answer. They wanted to stay common in nature and match into the bigger image of the preprocessing workflow being versatile within the steps concerned. It was additionally essential to unravel for each the potential must scale up the atmosphere in instances the place efficiency was compromised and to gracefully get well from such an occasion or when a job completed prematurely for any cause.
The answer constructed by Vericast to unravel this subject makes use of a number of AWS providers working collectively to achieve their enterprise goals. It was designed to restart and scale up the SageMaker Processing cluster based mostly on efficiency metrics noticed utilizing Lambda features monitoring the roles. To not lose work when a scaling occasion takes place or to get well from a job unexpectedly stopping, a checkpoint-based service was put in place that makes use of Amazon DynamoDB and shops the partially processed information in Amazon Simple Storage Service (Amazon S3) buckets as steps full. The ultimate final result is an auto scaling, strong, and dynamically monitored answer.
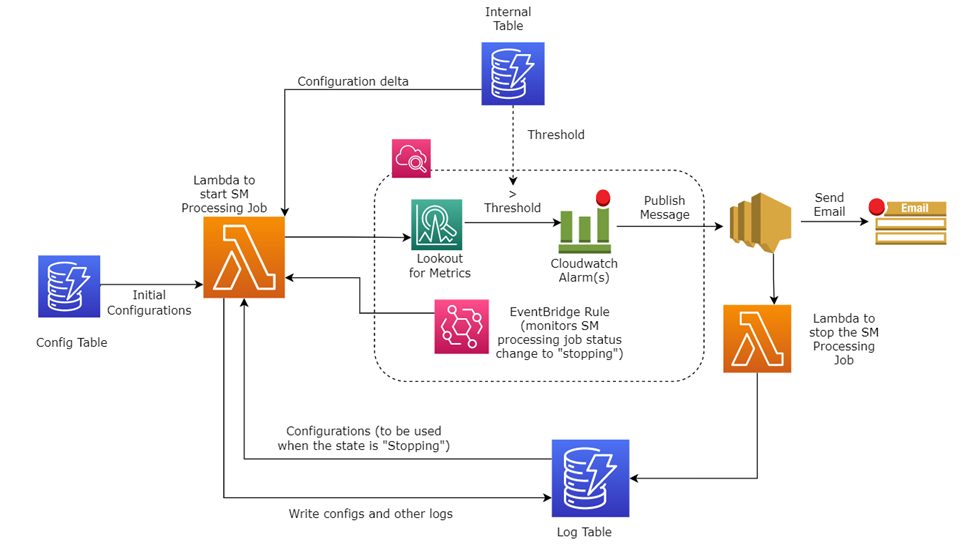
The next diagram exhibits a high-level overview of how the system works.

Within the following sections, we focus on the answer parts in additional element.
Initializing the answer
The system assumes {that a} separate course of initiates the answer. Conversely, this design isn’t designed to work alone as a result of it gained’t yield any artifacts or output, however reasonably acts as a sidecar implementation to one of many programs that use SageMaker Processing jobs. In Vericast’s case, the answer is initiated by means of a name from a Step Features step began in one other module of the bigger system.
As soon as the answer initiated and a primary run is triggered, a base normal configuration is learn from a DynamoDB desk. This configuration is used to set parameters for the SageMaker Processing job and has the preliminary assumptions of infrastructure wants. The SageMaker Processing job is now began.
Monitoring metadata and output
When the job begins, a Lambda operate writes the job processing metadata (the present job configuration and different log data) into the DynamoDB log desk. This metadata and log data maintains a historical past of the job, its preliminary and ongoing configuration, and different essential information.
At sure factors, as steps full within the job, checkpoint information is added to the DynamoDB log desk. Processed output information is moved to Amazon S3 for fast restoration if wanted.
This Lambda operate additionally units up an Amazon EventBridge rule that screens the operating job for its state. Particularly, this rule is watching the job to watch if the job standing modifications to stopping or is in a stopped state. This EventBridge rule performs an essential half in restarting a job if there’s a failure or a deliberate auto scaling occasion happens.
Monitoring CloudWatch metrics
The Lambda operate additionally units a CloudWatch alarm based mostly on a metric math expression on the processing job, which screens the metrics of all of the situations for CPU utilization, reminiscence utilization, and disk utilization. Any such alarm (metric) makes use of CloudWatch alarm thresholds. The alarm generates occasions based mostly on the worth of the metric or expression relative to the thresholds over various time durations.
In Vericast’s use case, the edge expression is designed to think about the driving force and the executor situations as separate, with metrics monitored individually for every. By having them separate, Vericast is aware of which is inflicting the alarm. That is essential to resolve methods to scale accordingly:
- If the executor metrics are passing the edge, it’s good to scale horizontally
- If the driving force metrics cross the edge, scaling horizontally will in all probability not assist, so we should scale vertically
Alarm metrics expression
Vericast can entry the next metrics in its analysis for scaling and failure:
- CPUUtilization – The sum of every particular person CPU core’s utilization
- MemoryUtilization – The share of reminiscence that’s utilized by the containers on an occasion
- DiskUtilization – The share of disk house utilized by the containers on an occasion
- GPUUtilization – The share of GPU models which can be utilized by the containers on an occasion
- GPUMemoryUtilization – The share of GPU reminiscence utilized by the containers on an occasion
As of this writing, Vericast solely considers CPUUtilization, MemoryUtilization, and DiskUtilization. Sooner or later, they intend to think about GPUUtilization and GPUMemoryUtilization as properly.
The next code is an instance of a CloudWatch alarm based mostly on a metric math expression for Vericast auto scaling:
This expression illustrates that the CloudWatch alarm is contemplating DriverMemoryUtilization (memoryDriver), CPUUtilization (cpuDriver), DiskUtilization (diskDriver), ExecutorMemoryUtilization (memoryExec), CPUUtilization (cpuExec), and DiskUtilization (diskExec) as monitoring metrics. The quantity 80 within the previous expression stands for the edge worth.
Right here, IF((cpuDriver) > 80, 1, 0 implies that if the driving force CPU utilization goes past 80%, 1 is assigned as the edge else 0. IF(AVG(METRICS("memoryExec")) > 80, 1, 0 implies that every one the metrics with string memoryExec in it are thought of and a median is calculated on that. If that common reminiscence utilization proportion goes past 80, 1 is assigned as the edge else 0.
The logical operator OR is used within the expression to unify all of the utilizations within the expression—if any of the utilizations attain its threshold, set off the alarm.
For extra data on utilizing CloudWatch metric alarms based mostly on metric math expressions, discuss with Creating a CloudWatch alarm based on a metric math expression.
CloudWatch alarm limitations
CloudWatch limits the variety of metrics per alarm to 10. This will trigger limitations if that you must contemplate extra metrics than this.
To beat this limitation, Vericast has set alarms based mostly on the general cluster dimension. One alarm is created per three situations (for 3 situations, there shall be one alarm as a result of that will add as much as 9 metrics). Assuming the driving force occasion is to be thought of individually, one other separate alarm is created for the driving force occasion. Due to this fact, the overall variety of alarms which can be created are roughly equal to 1 third the variety of executor nodes and a further one for the driving force occasion. In every case, the variety of metrics per alarm is underneath the ten metric limitation.
What occurs when in an alarm state
If a predetermined threshold is met, the alarm goes to an alarm state, which makes use of Amazon Simple Notification Service (Amazon SNS) to ship out notifications. On this case, it sends out an e mail notification to all subscribers with the main points concerning the alarm within the message.
Amazon SNS can be used as a set off to a Lambda operate that stops the at the moment operating SageMaker Processing job as a result of we all know that the job will in all probability fail. This operate additionally information logs to the log desk associated to the occasion.
The EventBridge rule arrange at job begin will discover that the job has gone right into a stopping state a number of seconds later. This rule then reruns the primary Lambda operate to restart the job.
The dynamic scaling course of
The primary Lambda operate after operating two or extra instances will know {that a} earlier job had already began and now has stopped. The operate will undergo an analogous means of getting the bottom configuration from the unique job within the log DynamoDB desk and also will retrieve up to date configuration from the inner desk. This up to date configuration is a sources delta configuration that’s set based mostly on the scaling sort. The scaling sort is decided from the alarm metadata as described earlier.
The unique configuration plus the sources delta are used as a result of a brand new configuration and a brand new SageMaker Processing job are began with the elevated sources.
This course of continues till the job completes efficiently and can lead to a number of restarts as wanted, including extra sources every time.
Vericast’s final result
This tradition auto scaling answer has been instrumental in making Vericast’s Machine Studying Platform extra strong and fault tolerant. The platform can now gracefully deal with workloads of various information volumes with minimal human intervention.
Earlier than implementing this answer, estimating the useful resource necessities for all of the Spark-based modules within the pipeline was one of many greatest bottlenecks of the brand new shopper onboarding course of. Workflows would fail if the shopper information quantity elevated, or the fee can be unjustifiable if the info quantity decreased in manufacturing.
With this new module in place, workflow failures as a consequence of useful resource constraints have been diminished by virtually 80%. The few remaining failures are principally as a consequence of AWS account constraints and past the auto scale course of. Vericast’s greatest win with this answer is the benefit with which they will onboard new shoppers and workflows. Vericast expects to hurry up the method by a minimum of 60–70%, with information nonetheless to be gathered for a last quantity.
Although that is considered as a hit by Vericast, there’s a price that comes with it. Based mostly on the character of this module and the idea of dynamic scaling as a complete, the workflows are likely to take round 30% longer (common case) than a workflow with a custom-tuned cluster for every module within the workflow. Vericast continues to optimize on this space, seeking to enhance the answer by incorporating heuristics-based useful resource initialization for every shopper module.
Sharmo Sarkar, Senior Supervisor, Machine Studying Platform at Vericast, says, “As we proceed to develop our use of AWS and SageMaker, I wished to take a second to focus on the unimaginable work of our AWS Consumer Providers Group, devoted AWS Options Architects, and AWS Skilled Providers that we work with. Their deep understanding of AWS and SageMaker allowed us to design an answer that met all of our wants and offered us with the flexibleness and scalability we required. We’re so grateful to have such a proficient and educated assist group on our aspect.”
Conclusion
On this put up, we shared how SageMaker and SageMaker Processing have enabled Vericast to construct a managed, performant, and cost-effective information processing framework for big information volumes. By combining the facility and suppleness of SageMaker Processing with different AWS providers, they will simply monitor the generalized function engineering course of. They’ll routinely detect potential points generated from lack of compute, reminiscence, and different elements, and routinely implement vertical and horizontal scaling as wanted.
SageMaker and its instruments may help your group meet its ML objectives as properly. To be taught extra about SageMaker Processing and the way it can help in your information processing workloads, discuss with Process Data. When you’re simply getting began with ML and are searching for examples and steerage, Amazon SageMaker JumpStart can get you began. JumpStart is an ML hub from which you’ll entry built-in algorithms with pre-trained basis fashions that will help you carry out duties corresponding to article summarization and picture era and pre-built options to unravel frequent use instances.
Lastly, if this put up helps you or conjures up you to unravel an issue, we’d love to listen to about it! Please share your feedback and suggestions.
Concerning the Authors
 Anthony McClure is a Senior Associate Options Architect with the AWS SaaS Manufacturing facility group. Anthony additionally has a powerful curiosity in machine studying and synthetic intelligence working with the AWS ML/AI Technical Subject Group to help clients in bringing their machine studying options to actuality.
Anthony McClure is a Senior Associate Options Architect with the AWS SaaS Manufacturing facility group. Anthony additionally has a powerful curiosity in machine studying and synthetic intelligence working with the AWS ML/AI Technical Subject Group to help clients in bringing their machine studying options to actuality.
 Jyoti Sharma is a Information Science Engineer with the machine studying platform group at Vericast. She is enthusiastic about all points of knowledge science and targeted on designing and implementing a extremely scalable and distributed Machine Studying Platform.
Jyoti Sharma is a Information Science Engineer with the machine studying platform group at Vericast. She is enthusiastic about all points of knowledge science and targeted on designing and implementing a extremely scalable and distributed Machine Studying Platform.
 Sharmo Sarkar is a Senior Supervisor at Vericast. He leads the Cloud Machine Studying Platform and the Advertising Platform ML R&D Groups at Vericast. He has in depth expertise in Large Information Analytics, Distributed Computing, and Pure Language Processing. Outdoors work, he enjoys motorcycling, mountaineering, and biking on mountain trails.
Sharmo Sarkar is a Senior Supervisor at Vericast. He leads the Cloud Machine Studying Platform and the Advertising Platform ML R&D Groups at Vericast. He has in depth expertise in Large Information Analytics, Distributed Computing, and Pure Language Processing. Outdoors work, he enjoys motorcycling, mountaineering, and biking on mountain trails.





