Create high-quality datasets with Amazon SageMaker Floor Reality and FiftyOne

It is a joint put up co-written by AWS and Voxel51. Voxel51 is the corporate behind FiftyOne, the open-source toolkit for constructing high-quality datasets and laptop imaginative and prescient fashions.
A retail firm is constructing a cellular app to assist prospects purchase garments. To create this app, they want a high-quality dataset containing clothes photos, labeled with totally different classes. On this put up, we present learn how to repurpose an current dataset by way of knowledge cleansing, preprocessing, and pre-labeling with a zero-shot classification mannequin in FiftyOne, and adjusting these labels with Amazon SageMaker Ground Truth.
You should use Floor Reality and FiftyOne to speed up your knowledge labeling mission. We illustrate learn how to seamlessly use the 2 purposes collectively to create high-quality labeled datasets. For our instance use case, we work with the Fashion200K dataset, launched at ICCV 2017.
Answer overview
Floor Reality is a totally self-served and managed knowledge labeling service that empowers knowledge scientists, machine studying (ML) engineers, and researchers to construct high-quality datasets. FiftyOne by Voxel51 is an open-source toolkit for curating, visualizing, and evaluating laptop imaginative and prescient datasets with the intention to prepare and analyze higher fashions by accelerating your use circumstances.
Within the following sections, we display learn how to do the next:
- Visualize the dataset in FiftyOne
- Clear the dataset with filtering and picture deduplication in FiftyOne
- Pre-label the cleaned knowledge with zero-shot classification in FiftyOne
- Label the smaller curated dataset with Floor Reality
- Inject labeled outcomes from Floor Reality into FiftyOne and evaluate labeled leads to FiftyOne
Use case overview
Suppose you personal a retail firm and need to construct a cellular utility to present personalised suggestions to assist customers resolve what to put on. Your potential customers are searching for an utility that tells them which articles of clothes of their closet work nicely collectively. You see a possibility right here: if you happen to can determine good outfits, you should use this to advocate new articles of clothes that complement the clothes a buyer already owns.
You need to make issues as simple as potential for the end-user. Ideally, somebody utilizing your utility solely must take photos of the garments of their wardrobe, and your ML fashions work their magic behind the scenes. You may prepare a general-purpose mannequin or fine-tune a mannequin to every consumer’s distinctive type with some type of suggestions.
First, nonetheless, it’s worthwhile to determine what sort of clothes the consumer is capturing. Is it a shirt? A pair of pants? Or one thing else? In spite of everything, you in all probability don’t need to advocate an outfit that has a number of attire or a number of hats.
To handle this preliminary problem, you need to generate a coaching dataset consisting of photos of varied articles of clothes with varied patterns and kinds. To prototype with a restricted funds, you need to bootstrap utilizing an current dataset.
As an example and stroll you thru the method on this put up, we use the Fashion200K dataset launched at ICCV 2017. It’s a longtime and well-cited dataset, but it surely isn’t instantly suited in your use case.
Though articles of clothes are labeled with classes (and subcategories) and include quite a lot of useful tags which might be extracted from the unique product descriptions, the information will not be systematically labeled with sample or type info. Your purpose is to show this current dataset into a sturdy coaching dataset in your clothes classification fashions. You could clear the information, augmenting the labeling schema with type labels. And also you need to achieve this shortly and with as little spend as potential.
Obtain the information domestically
First, obtain the ladies.tar zip file and the labels folder (with all of its subfolders) following the directions supplied within the Fashion200K dataset GitHub repository. After you’ve unzipped them each, create a father or mother listing fashion200k, and transfer the labels and ladies folders into this. Luckily, these photos have already been cropped to the article detection bounding packing containers, so we are able to give attention to classification, slightly than fear about object detection.
Regardless of the “200K” in its moniker, the ladies listing we extracted incorporates 338,339 photos. To generate the official Fashion200K dataset, the dataset’s authors crawled greater than 300,000 merchandise on-line, and solely merchandise with descriptions containing greater than 4 phrases made the reduce. For our functions, the place the product description isn’t important, we are able to use all the crawled photos.
Let’s have a look at how this knowledge is organized: inside the girls folder, photos are organized by top-level article sort (skirts, tops, pants, jackets, and attire), and article sort subcategory (blouses, t-shirts, long-sleeved tops).

Throughout the subcategory directories, there’s a subdirectory for every product itemizing. Every of those incorporates a variable variety of photos. The cropped_pants subcategory, as an illustration, incorporates the next product listings and related photos.
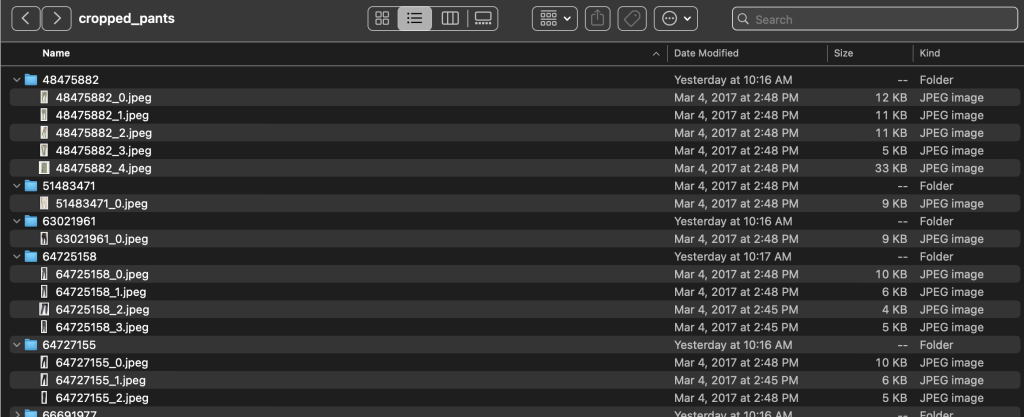
The labels folder incorporates a textual content file for every top-level article sort, for each prepare and take a look at splits. Inside every of those textual content recordsdata is a separate line for every picture, specifying the relative file path, a rating, and tags from the product description.
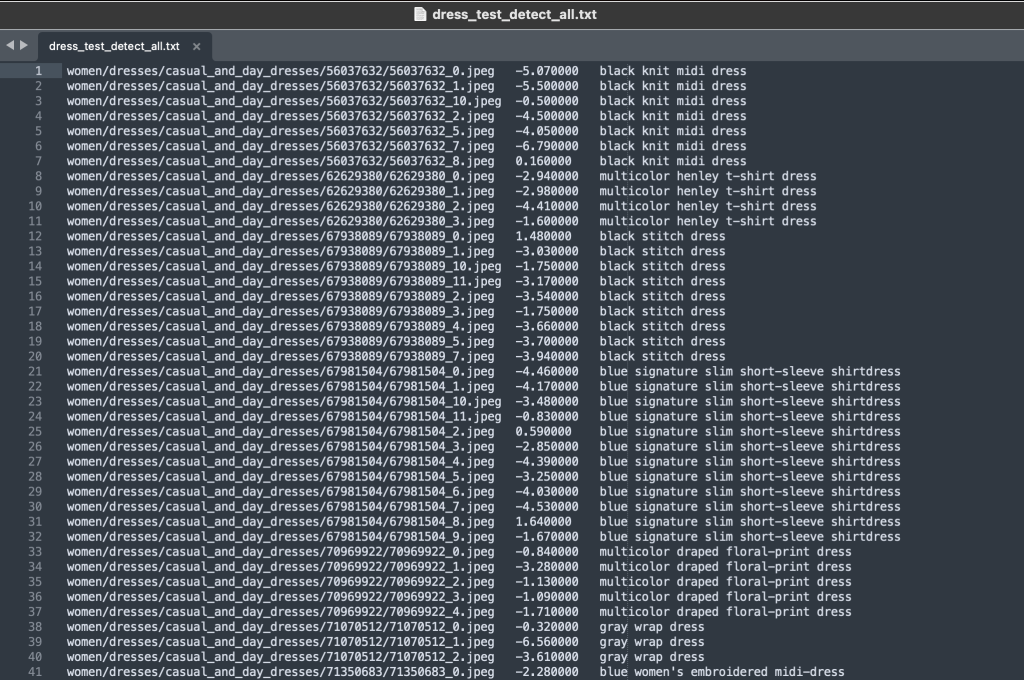
As a result of we’re repurposing the dataset, we mix all the prepare and take a look at photos. We use these to generate a high-quality application-specific dataset. After we full this course of, we are able to randomly break up the ensuing dataset into new prepare and take a look at splits.
Inject, view, and curate a dataset in FiftyOne
Should you haven’t already executed so, set up open-source FiftyOne utilizing pip:
A finest apply is to take action inside a brand new digital (venv or conda) setting. Then import the related modules. Import the bottom library, fiftyone, the FiftyOne Mind, which has built-in ML strategies, the FiftyOne Zoo, from which we are going to load a mannequin that may generate zero-shot labels for us, and the ViewField, which lets us effectively filter the information in our dataset:
You additionally need to import the glob and os Python modules, which is able to assist us work with paths and sample match over listing contents:
Now we’re able to load the dataset into FiftyOne. First, we create a dataset named fashion200k and make it persistent, which permits us to avoid wasting the outcomes of computationally intensive operations, so we solely have to compute mentioned portions as soon as.
We will now iterate via all subcategory directories, including all the pictures inside the product directories. We add a FiftyOne classification label to every pattern with the sector identify article_type, populated by the picture’s top-level article class. We additionally add each class and subcategory info as tags:
At this level, we are able to visualize our dataset within the FiftyOne app by launching a session:
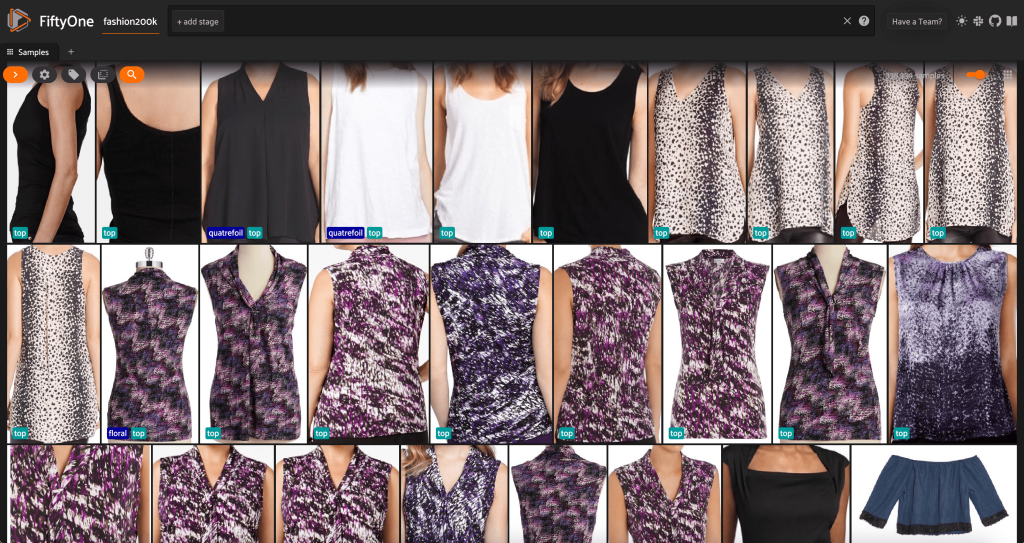
We will additionally print out a abstract of the dataset in Python by working print(dataset):
We will additionally add the tags from the labels listing to the samples in our dataset:
Wanting on the knowledge, a couple of issues grow to be clear:
- Among the photos are pretty grainy, with low decision. That is doubtless as a result of these photos had been generated by cropping preliminary photos in object detection bounding packing containers.
- Some garments are worn by an individual, and a few are photographed on their very own. These particulars are encapsulated by the
viewpointproperty. - A number of the pictures of the identical product are very comparable, so no less than initially, together with multiple picture per product might not add a lot predictive energy. For probably the most half, the primary picture of every product (ending in
_0.jpeg) is the cleanest.
Initially, we would need to prepare our clothes type classification mannequin on a managed subset of those photos. To this finish, we use high-resolution photos of our merchandise, and restrict our view to at least one consultant pattern per product.
First, we filter out the low-resolution photos. We use the compute_metadata() technique to compute and retailer picture width and peak, in pixels, for every picture within the dataset. We then make use of the FiftyOne ViewField to filter out photos based mostly on the minimal allowed width and peak values. See the next code:
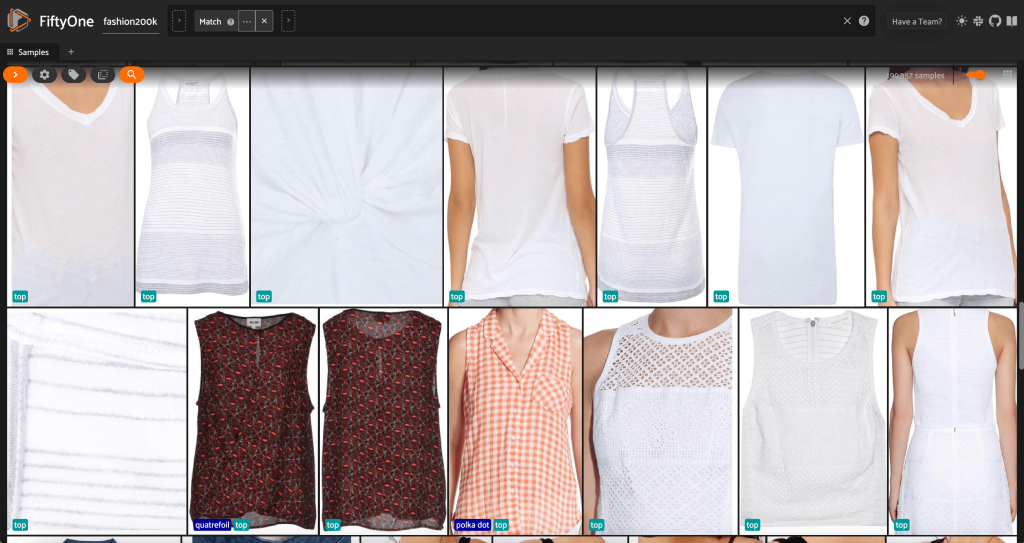
This high-resolution subset has slightly below 200,000 samples.
From this view, we are able to create a brand new view into our dataset containing just one consultant pattern (at most) for every product. We use the ViewField as soon as once more, sample matching for file paths that finish with _0.jpeg:
Let’s view a randomly shuffled ordering of photos on this subset:
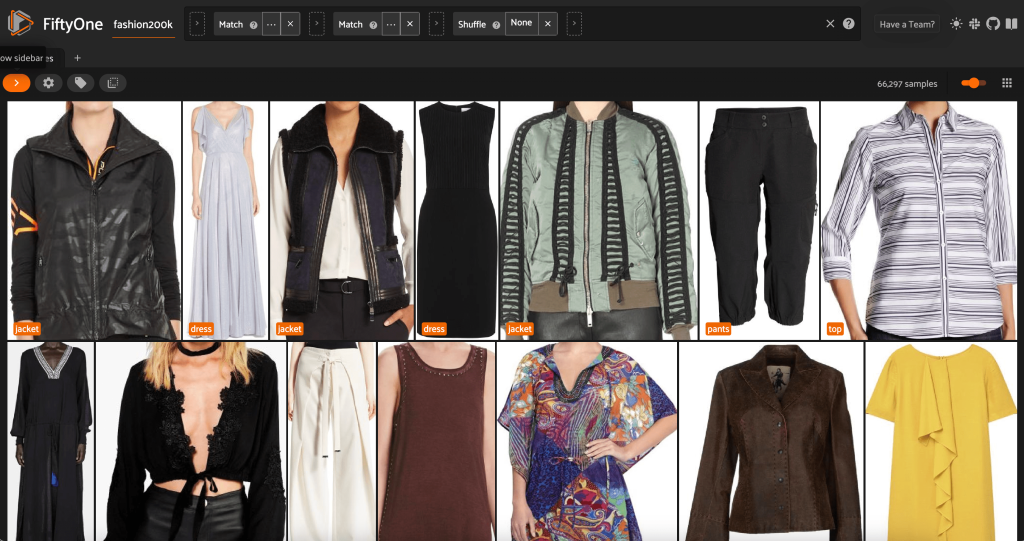
Take away redundant photos within the dataset
This view incorporates 66,297 photos, or simply over 19% of the unique dataset. Once we have a look at the view, nonetheless, we see that there are numerous very comparable merchandise. Maintaining all of those copies will doubtless solely add price to our labeling and mannequin coaching, with out noticeably bettering efficiency. As a substitute, let’s do away with the close to duplicates to create a smaller dataset that also packs the identical punch.
As a result of these photos usually are not actual duplicates, we are able to’t test for pixel-wise equality. Luckily, we are able to use the FiftyOne Mind to assist us clear our dataset. Particularly, we’ll compute an embedding for every picture—a lower-dimensional vector representing the picture—after which search for photos whose embedding vectors are shut to one another. The nearer the vectors, the extra comparable the pictures.
We use a CLIP mannequin to generate a 512-dimensional embedding vector for every picture, and retailer these embeddings within the area embeddings on the samples in our dataset:
Then we compute the closeness between embeddings, utilizing cosine similarity, and assert that any two vectors whose similarity is bigger than some threshold are more likely to be close to duplicates. Cosine similarity scores lie within the vary [0, 1], and looking out on the knowledge, a threshold rating of thresh=0.5 appears to be about proper. Once more, this doesn’t have to be excellent. A couple of near-duplicate photos usually are not more likely to spoil our predictive energy, and throwing away a couple of non-duplicate photos doesn’t materially affect mannequin efficiency.
We will view the purported duplicates to confirm that they’re certainly redundant:
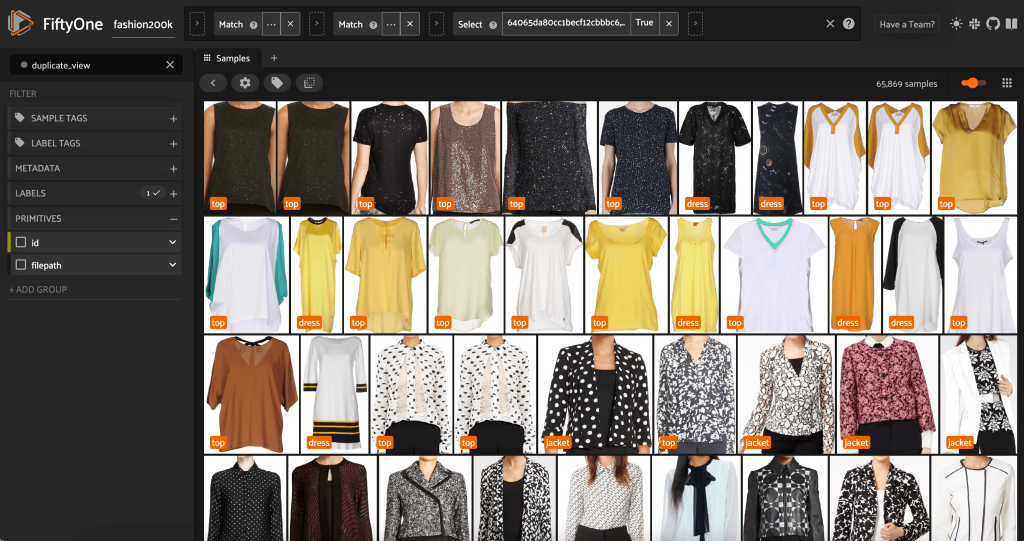
Once we’re pleased with the outcome and consider these photos are certainly close to duplicates, we are able to choose one pattern from every set of comparable samples to maintain, and ignore the others:
Now this view has 3,729 photos. By cleansing the information and figuring out a high-quality subset of the Fashion200K dataset, FiftyOne lets us prohibit our focus from greater than 300,000 photos to simply beneath 4,000, representing a discount by 98%. Utilizing embeddings to take away near-duplicate photos alone introduced our complete variety of photos into consideration down by greater than 90%, with little if any impact on any fashions to be educated on this knowledge.
Earlier than pre-labeling this subset, we are able to higher perceive the information by visualizing the embeddings we’ve already computed. We will use the FiftyOne Mind’s built-in compute_visualization() technique, which employs the uniform manifold approximation (UMAP) method to mission the 512-dimensional embedding vectors into two-dimensional area so we are able to visualize them:
We open a brand new Embeddings panel within the FiftyOne app and coloring by article sort, and we are able to see that these embeddings roughly encode a notion of article sort (amongst different issues!).
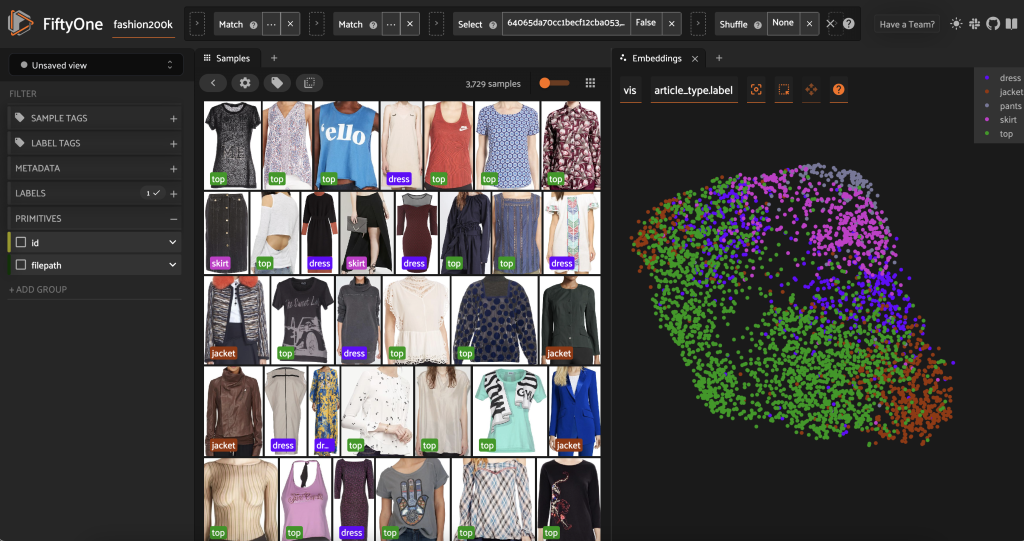
Now we’re able to pre-label this knowledge.
Inspecting these extremely distinctive, high-resolution photos, we are able to generate a good preliminary listing of kinds to make use of as courses in our pre-labeling zero-shot classification. Our purpose in pre-labeling these photos is to not essentially label every picture accurately. Fairly, our purpose is to supply a great place to begin for human annotators so we are able to cut back labeling time and price.
We will then instantiate a zero-shot classification mannequin for this utility. We use a CLIP mannequin, which is a general-purpose mannequin educated on each photos and pure language. We instantiate a CLIP mannequin with the textual content immediate “Clothes within the type,” in order that given a picture, the mannequin will output the category for which “Clothes within the type [class]” is the very best match. CLIP will not be educated on retail or fashion-specific knowledge, so this gained’t be excellent, however it could possibly prevent in labeling and annotation prices.
We then apply this mannequin to our lowered subset and retailer the leads to an article_style area:
Launching the FiftyOne App as soon as once more, we are able to visualize the pictures with these predicted type labels. We type by prediction confidence so we view probably the most assured type predictions first:

We will see that the best confidence predictions appear to be for “jersey,” “animal print,” “polka dot,” and “lettered” kinds. This is smart, as a result of these kinds are comparatively distinct. It additionally looks as if, for probably the most half, the expected type labels are correct.
We will additionally have a look at the lowest-confidence type predictions:
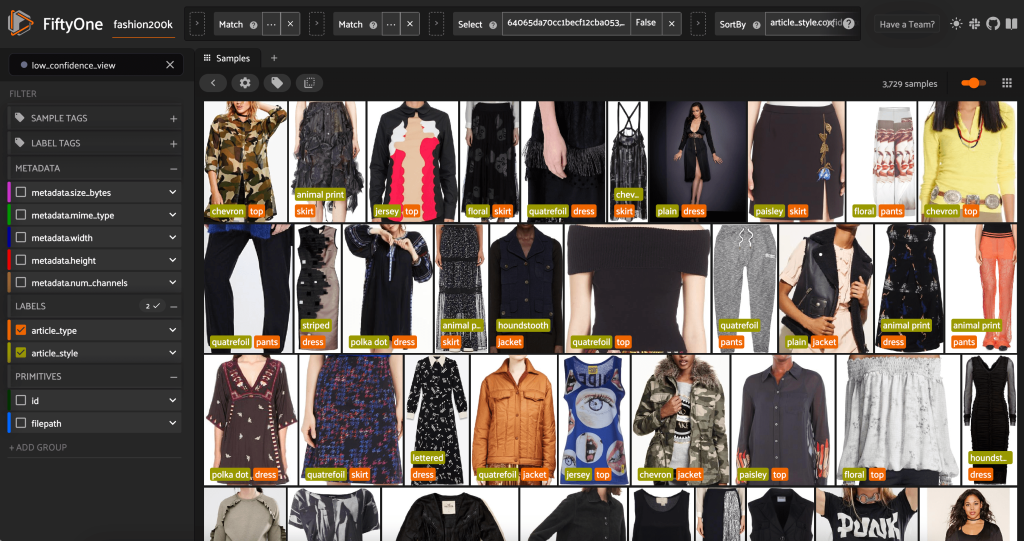
For a few of these photos, the suitable type class is within the supplied listing, and the article of clothes is incorrectly labeled. The primary picture within the grid, as an illustration, ought to clearly be “camouflage” and never “chevron.” In different circumstances, nonetheless, the merchandise don’t match neatly into the type classes. The costume within the second picture within the second row, for instance, will not be precisely “striped,” however given the identical labeling choices, a human annotator may additionally have been conflicted. As we construct out our dataset, we have to resolve whether or not to take away edge circumstances like these, add new type classes, or increase the dataset.
Export the ultimate dataset from FiftyOne
Export the ultimate dataset with the next code:
We will export a smaller dataset, for instance, 16 photos, to the folder 200kFashionDatasetExportResult-16Images. We create a Floor Reality adjustment job utilizing it:
Add the revised dataset, convert the label format to Floor Reality, add to Amazon S3, and create a manifest file for the adjustment job
We will convert the labels within the dataset to match the output manifest schema of a Floor Reality bounding field job, and add the pictures to an Amazon Simple Storage Service (Amazon S3) bucket to launch a Ground Truth adjustment job:
Add the manifest file to Amazon S3 with the next code:
Create corrected styled labels with Floor Reality
To annotate your knowledge with type labels utilizing Floor Reality, full the required steps to begin a bounding field labeling job by following the process outlined within the Getting Started with Ground Truth information with the dataset in the identical S3 bucket.
- On the SageMaker console, create a Floor Reality labeling job.
- Set the Enter dataset location to be the manifest that we created within the previous steps.

- Specify an S3 path for Output dataset location.
- For IAM Position, select Enter a customized IAM position ARN, then enter the position ARN.

- For Job class, select Picture and choose Bounding field.
- Select Subsequent.
- Within the Employees part, select the kind of workforce you want to use.
You may choose a workforce via Amazon Mechanical Turk, third-party distributors, or your personal non-public workforce. For extra particulars about your workforce choices, see Create and Manage Workforces. - Broaden Current-labels show choices and choose I need to show current labels from the dataset for this job.
- For Label attribute identify, select the identify out of your manifest that corresponds to the labels that you simply need to show for adjustment.
You’ll solely see label attribute names for labels that match the duty sort you chose within the earlier steps. - Manually enter the labels for Bounding field labeling software.
 The labels should include the identical labels used within the public dataset. You may add new labels. The next screenshot exhibits how one can select the employees and configure the software in your labeling job.
The labels should include the identical labels used within the public dataset. You may add new labels. The next screenshot exhibits how one can select the employees and configure the software in your labeling job.
- Select Preview to preview the picture and authentic annotations.
We’ve got now created a labeling job in Floor Reality. After our job is full, we are able to load the newly generated labeled knowledge into FiftyOne. Floor Reality produces output knowledge in a Floor Reality output manifest. For extra particulars on the output manifest file, see Bounding Box Job Output. The next code exhibits an instance of this output manifest format:
Assessment labeled outcomes from Floor Reality in FiftyOne
After the job is full, obtain the output manifest of the labeling job from Amazon S3.
Learn the output manifest file:
Create a FiftyOne dataset and convert the manifest traces to samples within the dataset:
Now you can see high-quality labeled knowledge from Floor Reality in FiftyOne.
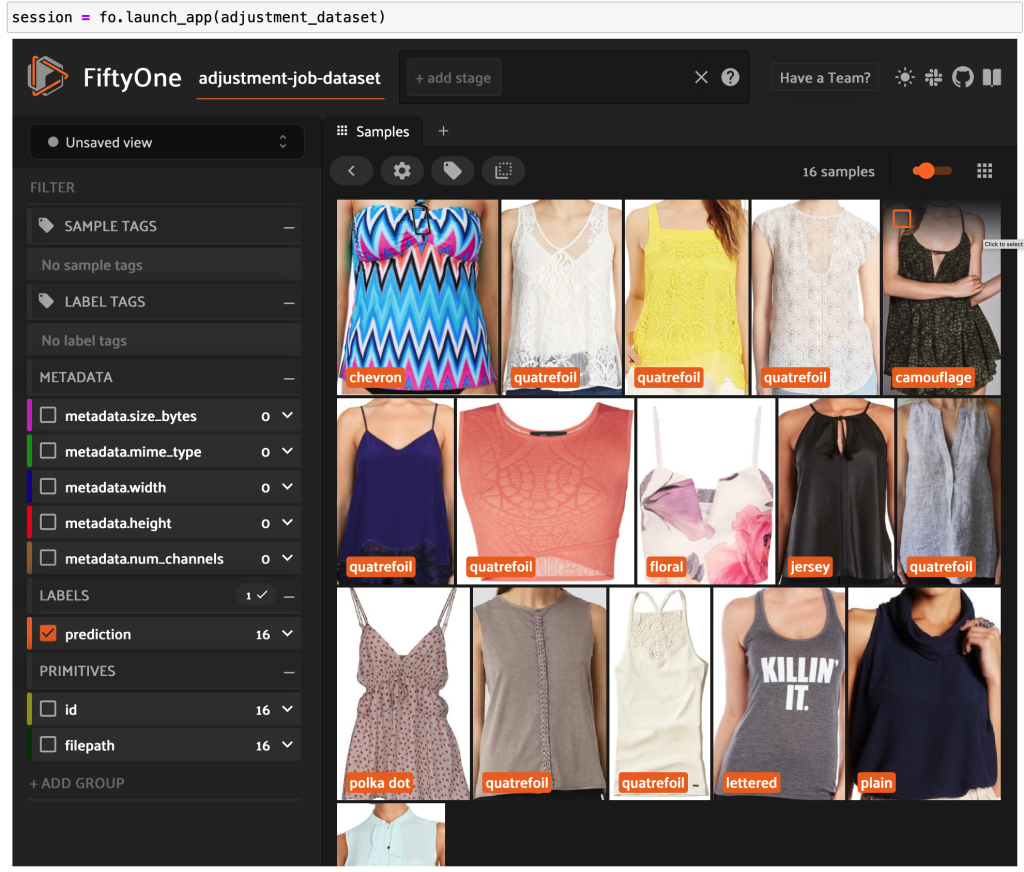
Conclusion
On this put up, we confirmed learn how to construct high-quality datasets by combining the ability of FiftyOne by Voxel51, an open-source toolkit that permits you to handle, observe, visualize, and curate your dataset, and Floor Reality, a knowledge labeling service that permits you to effectively and precisely label the datasets required for coaching ML programs by offering entry to a number of built-in activity templates and entry to a various workforce via Mechanical Turk, third-party distributors, or your personal non-public workforce.
We encourage you to check out this new performance by putting in a FiftyOne occasion and utilizing the Floor Reality console to get began. To study extra about Floor Reality, seek advice from Label Data, Amazon SageMaker Data Labeling FAQs, and the AWS Machine Learning Blog.
Join with the Machine Learning & AI community if in case you have any questions or suggestions!
Be a part of the FiftyOne group!
Be a part of the 1000’s of engineers and knowledge scientists already utilizing FiftyOne to resolve among the most difficult issues in laptop imaginative and prescient immediately!
In regards to the Authors
Shalendra Chhabra is at present Head of Product Administration for Amazon SageMaker Human-in-the-Loop (HIL) Companies. Beforehand, Shalendra incubated and led Language and Conversational Intelligence for Microsoft Groups Conferences, was EIR at Amazon Alexa Techstars Startup Accelerator, VP of Product and Advertising and marketing at Discuss.io, Head of Product and Advertising and marketing at Clipboard (acquired by Salesforce), and Lead Product Supervisor at Swype (acquired by Nuance). In complete, Shalendra has helped construct, ship, and market merchandise which have touched greater than a billion lives.
Jacob Marks is a Machine Studying Engineer and Developer Evangelist at Voxel51, the place he helps carry transparency and readability to the world’s knowledge. Previous to becoming a member of Voxel51, Jacob based a startup to assist rising musicians join and share artistic content material with followers. Earlier than that, he labored at Google X, Samsung Analysis, and Wolfram Analysis. In a previous life, Jacob was a theoretical physicist, finishing his PhD at Stanford, the place he investigated quantum phases of matter. In his free time, Jacob enjoys climbing, working, and studying science fiction novels.
Jason Corso is co-founder and CEO of Voxel51, the place he steers technique to assist carry transparency and readability to the world’s knowledge via state-of-the-art versatile software program. He’s additionally a Professor of Robotics, Electrical Engineering, and Pc Science on the College of Michigan, the place he focuses on cutting-edge issues on the intersection of laptop imaginative and prescient, pure language, and bodily platforms. In his free time, Jason enjoys spending time together with his household, studying, being in nature, enjoying board video games, and all kinds of artistic actions.
Brian Moore is co-founder and CTO of Voxel51, the place he leads technical technique and imaginative and prescient. He holds a PhD in Electrical Engineering from the College of Michigan, the place his analysis was targeted on environment friendly algorithms for large-scale machine studying issues, with a specific emphasis on laptop imaginative and prescient purposes. In his free time, he enjoys badminton, golf, mountaineering, and enjoying together with his twin Yorkshire Terriers.
Zhuling Bai is a Software program Improvement Engineer at Amazon Net Companies. She works on creating large-scale distributed programs to resolve machine studying issues.



