Authoring customized transformations in Amazon SageMaker Knowledge Wrangler utilizing NLTK and SciPy
“As a substitute of specializing in the code, corporations ought to concentrate on creating systematic engineering practices for bettering knowledge in methods which are dependable, environment friendly, and systematic. In different phrases, corporations want to maneuver from a model-centric method to a data-centric method.” – Andrew Ng
An information-centric AI method entails constructing AI methods with high quality knowledge involving knowledge preparation and have engineering. This generally is a tedious process involving knowledge assortment, discovery, profiling, cleaning, structuring, remodeling, enriching, validating, and securely storing the information.
Amazon SageMaker Data Wrangler is a service in Amazon SageMaker Studio that gives an end-to-end resolution to import, put together, rework, featurize, and analyze knowledge utilizing little to no coding. You possibly can combine a Knowledge Wrangler knowledge preparation stream into your machine studying (ML) workflows to simplify knowledge preprocessing and have engineering, taking knowledge preparation to manufacturing quicker with out the necessity to writer PySpark code, set up Apache Spark, or spin up clusters.
For situations the place you should add your individual customized scripts for knowledge transformations, you possibly can write your transformation logic in Pandas, PySpark, PySpark SQL. Knowledge Wrangler now helps NLTK and SciPy libraries for authoring customized transformations to arrange textual content knowledge for ML and carry out constraint optimization.
You may run into situations the place you must add your individual customized scripts for knowledge transformation. With the Knowledge Wrangler customized rework functionality, you possibly can write your transformation logic in Pandas, PySpark, PySpark SQL.
On this submit, we focus on how one can write your customized transformation in NLTK to arrange textual content knowledge for ML. We can even share some instance customized code rework utilizing different frequent frameworks equivalent to NLTK, NumPy, SciPy, and scikit-learn in addition to AWS AI Companies. For the aim of this train, we use the Titanic dataset, a preferred dataset within the ML neighborhood, which has now been added as a sample dataset inside Knowledge Wrangler.
Resolution overview
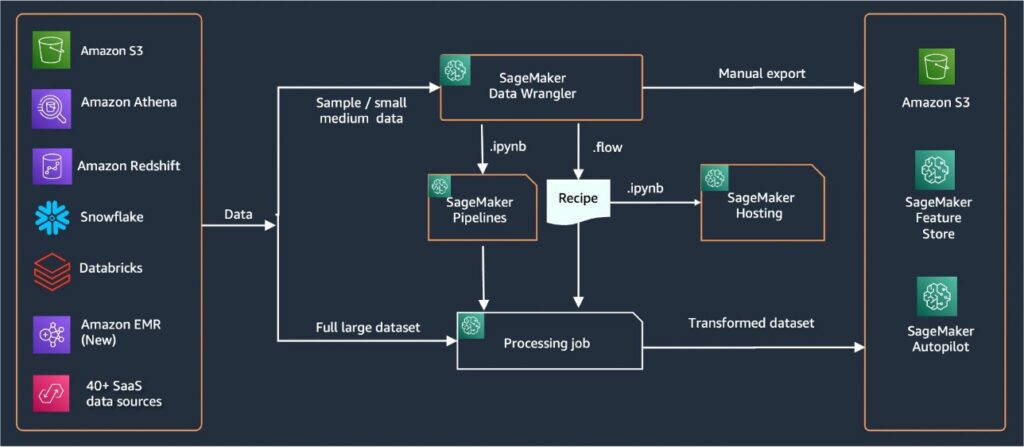
Knowledge Wrangler offers over 40 built-in connectors for importing knowledge. After knowledge is imported, you possibly can construct your knowledge evaluation and transformations utilizing over 300 built-in transformations. You possibly can then generate industrialized pipelines to push the options to Amazon Simple Storage Service (Amazon S3) or Amazon SageMaker Feature Store. The next diagram exhibits the end-to-end high-level structure.

Conditions
Knowledge Wrangler is a SageMaker characteristic obtainable inside Amazon SageMaker Studio. You possibly can comply with the Studio onboarding process to spin up the Studio surroundings and notebooks. Though you possibly can select from a number of authentication strategies, the best option to create a Studio area is to comply with the Quick start instructions. The Fast begin makes use of the identical default settings as the usual Studio setup. You can even select to onboard utilizing AWS IAM Identity Center (successor to AWS Single Signal-On) for authentication (see Onboard to Amazon SageMaker Domain Using IAM Identity Center).
Import the Titanic dataset
Begin your Studio surroundings and create a brand new Data Wrangler flow. You possibly can both import your individual dataset or use a pattern dataset (Titanic) as proven within the following screenshot. Knowledge Wrangler permits you to import datasets from totally different knowledge sources. For our use case, we import the pattern dataset from an S3 bucket.

As soon as imported, you will note two nodes (the supply node and the information kind node) within the knowledge stream. Knowledge Wrangler mechanically identifies the information kind for all of the columns within the dataset.

Customized transformations with NLTK
For knowledge preparation and have engineering with Knowledge Wrangler, you should utilize over 300 built-in transformations or construct your individual customized transformations. Custom transforms will be written as separate steps inside Knowledge Wrangler. They turn out to be a part of the .stream file inside Knowledge Wrangler. The customized rework characteristic helps Python, PySpark, and SQL as totally different steps in code snippets. After pocket book recordsdata (.ipynb) are generated from the .stream file or the .stream file is used as recipes, the customized rework code snippets persist with out requiring any modifications. This design of Knowledge Wrangler permits customized transforms to turn out to be a part of a SageMaker Processing job for processing large datasets with customized transformations.
Titanic dataset has couple of options (title and residential.dest) that comprise textual content info. We use NLTK to separate the title column and extract the final title, and print the frequency of final names. NLTK is a number one platform for constructing Python applications to work with human language knowledge. It offers easy-to-use interfaces to over 50 corpora and lexical resources equivalent to WordNet, together with a collection of textual content processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, and wrappers for industrial-strength pure language processing (NLP) libraries.
So as to add a brand new rework, full the next steps:
- Select the plus signal and select Add Rework.
- Select Add Step and select Customized Rework.
You possibly can create a customized rework utilizing Pandas, PySpark, Python user-defined features, and SQL PySpark.

- Select Python (Pandas) and add the next code to extract the final title from the title column:
- Select Preview to assessment the outcomes.
The next screenshot exhibits the last_name column extracted.

- Add one other customized rework step to establish the frequency distribution of the final names, utilizing the next code:
- Select Preview to assessment the outcomes of the frequency.

Customized transformations with AWS AI providers
AWS pre-trained AI providers present ready-made intelligence to your functions and workflows. AWS AI providers simply combine along with your functions to deal with many frequent use circumstances. Now you can use the capabilities for AWS AI providers as a customized rework step in Knowledge Wrangler.
Amazon Comprehend makes use of NLP to extract insights concerning the content material of paperwork. It develops insights by recognizing the entities, key phrases, language, sentiments, and different frequent components in a doc.
We use Amazon Comprehend to extract the entities from the title column. Full the next steps:
- Add a customized rework step.
- Select Python (Pandas).
- Enter the next code to extract the entities:
- Select Preview and visualize the outcomes.

Now we have now added three customized transforms in Knowledge Wrangler.
- Select Knowledge Move to visualise the end-to-end knowledge stream.

Customized transformations with NumPy and SciPy
NumPy is an open-source library for Python providing complete mathematical features, random quantity mills, linear algebra routines, Fourier transforms, and extra. SciPy is an open-source Python library used for scientific computing and technical computing, containing modules for optimization, linear algebra, integration, interpolation, particular features, quick Fourier rework (FFT), sign and picture processing, solvers, and extra.
Knowledge Wrangler customized transforms assist you to mix Python, PySpark, and SQL as totally different steps. Within the following Knowledge Wrangler stream, totally different features from Python packages, NumPy, and SciPy are utilized on the Titanic dataset as a number of steps.

NumPy transformations
The fare column of the Titanic dataset has boarding fares of various passengers. The histogram of the fare column exhibits uniform distribution, apart from the final bin. By making use of NumPy transformations like log or sq. root, we are able to change the distribution (as proven by the sq. root transformation).
 |
 |
See the next code:
SciPy transformations
SciPy features like z-score are utilized as a part of the customized rework to standardize fare distribution with imply and commonplace deviation.

See the next code:
Constraint optimization with NumPy and SciPy
Knowledge Wrangler customized transforms can deal with superior transformations like constraint optimization making use of SciPy optimize features and mixing SciPy with NumPy. Within the following instance, fare as a perform of age doesn’t present any observable development. Nevertheless, constraint optimization can rework fare as a perform of age. The constraint situation on this case is that the brand new complete fare stays the identical because the outdated complete fare. Knowledge Wrangler customized transforms assist you to run the SciPy optimize perform to find out the optimum coefficient that may rework fare as a perform of age below constraint circumstances.
 |
 |
Optimization definition, goal definition, and a number of constraints will be talked about as totally different features whereas formulating constraint optimization in a Knowledge Wrangler customized rework utilizing SciPy and NumPy. Customized transforms also can deliver totally different solver strategies which are obtainable as a part of the SciPy optimize package deal. A brand new reworked variable will be generated by multiplying the optimum coefficient with the unique column and added to current columns of Knowledge Wrangler. See the next code:
The Knowledge Wrangler customized rework characteristic has the UI functionality to point out the outcomes of SciPy optimize features like worth of optimum coefficient (or a number of coefficients).

Customized transformations with scikit-learn
scikit-learn is a Python module for machine studying constructed on high of SciPy. It’s an open-source ML library that helps supervised and unsupervised studying. It additionally offers numerous instruments for mannequin becoming, knowledge preprocessing, mannequin choice, mannequin analysis, and lots of different utilities.
Discretization
Discretization (in any other case often called quantization or binning) offers a option to partition steady options into discrete values. Sure datasets with steady options might profit from discretization, as a result of discretization can rework the dataset of steady attributes to 1 with solely nominal attributes. One-hot encoded discretized options could make a mannequin extra expressive, whereas sustaining interpretability. As an example, preprocessing with a discretizer can introduce nonlinearity to linear fashions.
Within the following code, we use KBinsDiscretizer to discretize the age column into 10 bins:
You possibly can see the bin edges printed within the following screenshot.

One-hot encoding
Values within the Embarked columns are categorical values. Subsequently, now we have to signify these strings as numerical values with a view to carry out our classification with our mannequin. We might additionally do that utilizing a one-hot encoding rework.
There are three values for Embarked: S, C, and Q. We signify these with numbers. See the next code:

Clear up
Whenever you’re not utilizing Knowledge Wrangler, it’s vital to close down the occasion on which it runs to keep away from incurring extra charges.
Knowledge Wrangler mechanically saves your knowledge stream each 60 seconds. To keep away from shedding work, save your knowledge stream earlier than shutting Knowledge Wrangler down.
- To save lots of your knowledge stream in Studio, select File, then select Save Knowledge Wrangler Move.
- To close down the Knowledge Wrangler occasion, in Studio, select Working Cases and Kernels.
- Underneath RUNNING APPS, select the shutdown icon subsequent to the sagemaker-data-wrangler-1.0 app.
- Select Shut down all to substantiate.
Knowledge Wrangler runs on an ml.m5.4xlarge occasion. This occasion disappears from RUNNING INSTANCES while you shut down the Knowledge Wrangler app.
After you shut down the Knowledge Wrangler app, it has to restart the subsequent time you open a Knowledge Wrangler stream file. This may take a couple of minutes.
Conclusion
On this submit, we demonstrated how you should utilize customized transformations in Knowledge Wrangler. We used the libraries and framework inside the Knowledge Wrangler container to increase the built-in knowledge transformation capabilities. The examples on this submit signify a subset of the frameworks used. The transformations within the Knowledge Wrangler stream can now be scaled in to a pipeline for DataOps.
To study extra about utilizing knowledge flows with Knowledge Wrangler, discuss with Create and Use a Data Wrangler Flow and Amazon SageMaker Pricing. To get began with Knowledge Wrangler, see Prepare ML Data with Amazon SageMaker Data Wrangler. To study extra about Autopilot and AutoML on SageMaker, go to Automate model development with Amazon SageMaker Autopilot.
Concerning the authors
 Meenakshisundaram Thandavarayan is a Senior AI/ML specialist with AWS. He helps hi-tech strategic accounts on their AI and ML journey. He’s very keen about data-driven AI.
Meenakshisundaram Thandavarayan is a Senior AI/ML specialist with AWS. He helps hi-tech strategic accounts on their AI and ML journey. He’s very keen about data-driven AI.
 Sovik Kumar Nath is an AI/ML resolution architect with AWS. He has intensive expertise in end-to-end designs and options for machine studying; enterprise analytics inside monetary, operational, and advertising and marketing analytics; healthcare; provide chain; and IoT. Exterior work, Sovik enjoys touring and watching films.
Sovik Kumar Nath is an AI/ML resolution architect with AWS. He has intensive expertise in end-to-end designs and options for machine studying; enterprise analytics inside monetary, operational, and advertising and marketing analytics; healthcare; provide chain; and IoT. Exterior work, Sovik enjoys touring and watching films.
 Abigail is a Software program Growth Engineer at Amazon SageMaker. She is keen about serving to prospects put together their knowledge in DataWrangler and constructing distributed machine studying methods. In her free time, Abigail enjoys touring, climbing, snowboarding, and baking.
Abigail is a Software program Growth Engineer at Amazon SageMaker. She is keen about serving to prospects put together their knowledge in DataWrangler and constructing distributed machine studying methods. In her free time, Abigail enjoys touring, climbing, snowboarding, and baking.



