Implement unified textual content and picture search with a CLIP mannequin utilizing Amazon SageMaker and Amazon OpenSearch Service
The rise of textual content and semantic search engines has made ecommerce and retail companies search simpler for its customers. Search engines like google and yahoo powered by unified textual content and picture can present further flexibility in search options. You should utilize each textual content and pictures as queries. For instance, you could have a folder of a whole bunch of household footage in your laptop computer. You wish to shortly discover a image that was taken once you and your greatest good friend have been in entrance of your outdated home’s swimming pool. You should utilize conversational language like “two individuals stand in entrance of a swimming pool” as a question to go looking in a unified textual content and picture search engine. You don’t have to have the suitable key phrases in picture titles to carry out the question.
Amazon OpenSearch Service now helps the cosine similarity metric for k-NN indexes. Cosine similarity measures the cosine of the angle between two vectors, the place a smaller cosine angle denotes the next similarity between the vectors. With cosine similarity, you’ll be able to measure the orientation between two vectors, which makes it a good selection for some particular semantic search functions.
Contrastive Language-Image Pre-Training (CLIP) is a neural community skilled on a wide range of picture and textual content pairs. The CLIP neural community is ready to mission each photos and textual content into the identical latent space, which signifies that they are often in contrast utilizing a similarity measure, reminiscent of cosine similarity. You should utilize CLIP to encode your merchandise’ photos or description into embeddings, after which retailer them into an OpenSearch Service k-NN index. Then your prospects can question the index to retrieve merchandise that they’re fascinated by.
You should utilize CLIP with Amazon SageMaker to carry out encoding. Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it simple to deploy and scale machine studying (ML) fashions. With SageMaker, you’ll be able to deploy serverless for dev and check, after which transfer to real-time inference once you go to manufacturing. SageMaker serverless helps you save value by cutting down infrastructure to 0 throughout idle instances. That is good for constructing a POC, the place you should have lengthy idle instances between growth cycles. You too can use Amazon SageMaker batch transform to get inferences from massive datasets.
On this put up, we reveal easy methods to construct a search software utilizing CLIP with SageMaker and OpenSearch Service. The code is open supply, and it’s hosted on GitHub.
Answer overview
OpenSearch Service offers text-matching and embedding k-NN search. We use embedding k-NN search on this resolution. You should utilize each picture and textual content as a question to go looking objects from the stock. Implementing this unified picture and textual content search software consists of two phases:
- k-NN reference index – On this section, you move a set of corpus paperwork or product photos by means of a CLIP mannequin to encode them into embeddings. Textual content and picture embeddings are numerical representations of the corpus or photos, respectively. You save these embeddings right into a k-NN index in OpenSearch Service. The idea underpinning k-NN is that related knowledge factors exist in shut proximity within the embedding area. For instance, the textual content “a pink flower,” the textual content “rose,” and a picture of pink rose are related, so these textual content and picture embeddings are shut to one another within the embedding area.
- k-NN index question – That is the inference section of the applying. On this section, you submit a textual content search question or picture search question by means of the deep studying mannequin (CLIP) to encode as embeddings. Then, you utilize these embeddings to question the reference k-NN index saved in OpenSearch Service. The k-NN index returns related embeddings from the embedding area. For instance, in the event you move the textual content of “a pink flower,” it will return the embeddings of a pink rose picture as an identical merchandise.
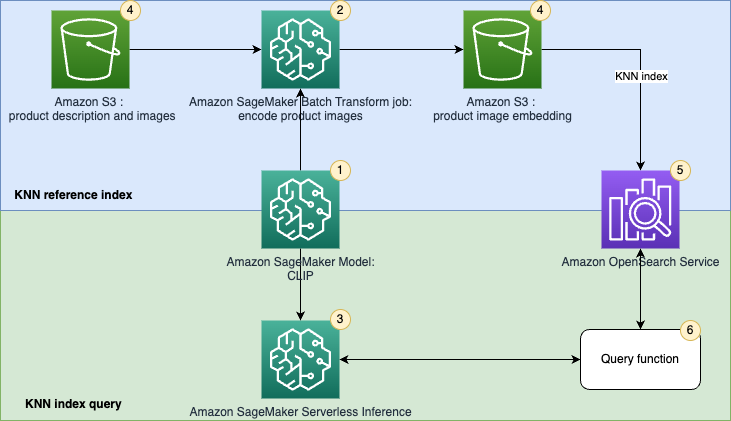
The next determine illustrates the answer structure.

The workflow steps are as follows:
- Create a SageMaker model from a pretrained CLIP mannequin for batch and real-time inference.
- Generate embeddings of product photos utilizing a SageMaker batch remodel job.
- Use SageMaker Serverless Inference to encode question picture and textual content into embeddings in actual time.
- Use Amazon Simple Storage Service (Amazon S3) to retailer the uncooked textual content (product description) and pictures (product photos) and picture embedding generated by the SageMaker batch remodel jobs.
- Use OpenSearch Service because the search engine to retailer embeddings and discover related embeddings.
- Use a question perform to orchestrate encoding the question and carry out a k-NN search.
We use Amazon SageMaker Studio notebooks (not proven within the diagram) because the built-in growth surroundings (IDE) to develop the answer.
Arrange resolution assets
To arrange the answer, full the next steps:
- Create a SageMaker area and a person profile. For directions, check with Step 5 of Onboard to Amazon SageMaker Domain Using Quick setup.
- Create an OpenSearch Service area. For directions, see Creating and managing Amazon OpenSearch Service domains.
You too can use an AWS CloudFormation template by following the GitHub instructions to create a site.
You’ll be able to join Studio to Amazon S3 from Amazon Virtual Private Cloud (Amazon VPC) utilizing an interface endpoint in your VPC, as a substitute of connecting over the web. By utilizing an interface VPC endpoint (interface endpoint), the communication between your VPC and Studio is performed solely and securely throughout the AWS community. Your Studio pocket book can hook up with OpenSearch Service over a non-public VPC to make sure safe communication.
OpenSearch Service domains supply encryption of information at relaxation, which is a safety function that helps stop unauthorized entry to your knowledge. Node-to-node encryption offers an extra layer of safety on prime of the default options of OpenSearch Service. Amazon S3 robotically applies server-side encryption (SSE-S3) for every new object until you specify a unique encryption possibility.
Within the OpenSearch Service area, you’ll be able to connect identity-based insurance policies outline who can entry a service, which actions they’ll carry out, and if relevant, the assets on which they’ll carry out these actions.
Encode photos and textual content pairs into embeddings
This part discusses easy methods to encode photos and textual content into embeddings. This contains getting ready knowledge, making a SageMaker mannequin, and performing batch remodel utilizing the mannequin.
Information overview and preparation
You should utilize a SageMaker Studio pocket book with a Python 3 (Information Science) kernel to run the pattern code.
For this put up, we use the Amazon Berkeley Objects Dataset. The dataset is a group of 147,702 product listings with multilingual metadata and 398,212 distinctive catalogue photos. We solely use the merchandise photos and merchandise names in US English. For demo functions, we use roughly 1,600 merchandise. For extra particulars about this dataset, check with the README. The dataset is hosted in a public S3 bucket. There are 16 recordsdata that embrace product description and metadata of Amazon merchandise within the format of listings/metadata/listings_<i>.json.gz. We use the primary metadata file on this demo.
You utilize pandas to load the metadata, then choose merchandise which have US English titles from the information body. Pandas is an open-source knowledge evaluation and manipulation device constructed on prime of the Python programming language. You utilize an attribute known as main_image_id to determine a picture. See the next code:
There are 1,639 merchandise within the knowledge body. Subsequent, hyperlink the merchandise names with the corresponding merchandise photos. photos/metadata/photos.csv.gz comprises picture metadata. This file is a gzip-compressed CSV file with the next columns: image_id, peak, width, and path. You’ll be able to learn the metadata file after which merge it with merchandise metadata. See the next code:

You should utilize the SageMaker Studio pocket book Python 3 kernel built-in PIL library to view a pattern picture from the dataset:

Mannequin preparation
Subsequent, create a SageMaker model from a pretrained CLIP mannequin. Step one is to obtain the pre-trained mannequin weighting file, put it right into a mannequin.tar.gz file, and add it to an S3 bucket. The trail of the pretrained mannequin may be discovered within the CLIP repo. We use a pretrained ResNet-50 (RN50) mannequin on this demo. See the next code:
You then want to offer an inference entry level script for the CLIP mannequin. CLIP is applied utilizing PyTorch, so you utilize the SageMaker PyTorch framework. PyTorch is an open-source ML framework that accelerates the trail from analysis prototyping to manufacturing deployment. For details about deploying a PyTorch mannequin with SageMaker, check with Deploy PyTorch Models. The inference code accepts two surroundings variables: MODEL_NAME and ENCODE_TYPE. This helps us swap between completely different CLIP mannequin simply. We use ENCODE_TYPE to specify if we wish to encode a picture or a bit of textual content. Right here, you implement the model_fn, input_fn, predict_fn, and output_fn capabilities to override the default PyTorch inference handler. See the next code:
The answer requires extra Python packages throughout mannequin inference, so you’ll be able to present a necessities.txt file to permit SageMaker to put in extra packages when internet hosting fashions:
You utilize the PyTorchModel class to create an object to include the knowledge of the mannequin artifacts’ Amazon S3 location and the inference entry level particulars. You should utilize the thing to create batch remodel jobs or deploy the mannequin to an endpoint for on-line inference. See the next code:
Batch remodel to encode merchandise photos into embeddings
Subsequent, we use the CLIP mannequin to encode merchandise photos into embeddings, and use SageMaker batch remodel to run batch inference.
Earlier than creating the job, use the next code snippet to repeat merchandise photos from the Amazon Berkeley Objects Dataset public S3 bucket to your personal bucket. The operation takes lower than 10 minutes.
Subsequent, you carry out inference on the merchandise photos in a batch method. The SageMaker batch remodel job makes use of the CLIP mannequin to encode all the pictures saved within the enter Amazon S3 location and uploads output embeddings to an output S3 folder. The job takes round 10 minutes.
Load embeddings from Amazon S3 to a variable, so you’ll be able to ingest the information into OpenSearch Service later:
Create an ML-powered unified search engine
This part discusses easy methods to create a search engine that that makes use of k-NN search with embeddings. This contains configuring an OpenSearch Service cluster, ingesting merchandise embedding, and performing free textual content and picture search queries.
Arrange the OpenSearch Service area utilizing k-NN settings
Earlier, you created an OpenSearch cluster. Now you’re going to create an index to retailer the catalog knowledge and embeddings. You’ll be able to configure the index settings to allow the k-NN performance utilizing the next configuration:
This instance makes use of the Python Elasticsearch client to speak with the OpenSearch cluster and create an index to host your knowledge. You’ll be able to run %pip set up elasticsearch within the pocket book to put in the library. See the next code:
Ingest picture embedding knowledge into OpenSearch Service
You now loop by means of your dataset and ingest objects knowledge into the cluster. The info ingestion for this observe ought to end inside 60 seconds. It additionally runs a easy question to confirm if the information has been ingested into the index efficiently. See the next code:
Carry out a real-time question
Now that you’ve got a working OpenSearch Service index that comprises embeddings of merchandise photos as our stock, let’s have a look at how one can generate embedding for queries. It’s essential to create two SageMaker endpoints to deal with textual content and picture embeddings, respectively.
You additionally create two capabilities to make use of the endpoints to encode photos and texts. For the encode_text perform, you add that is earlier than an merchandise identify to translate an merchandise identify to a sentence for merchandise description. memory_size_in_mb is ready as 6 GB to serve the underline Transformer and ResNet fashions. See the next code:
You’ll be able to firstly plot the image that will probably be used.

Let’s have a look at the outcomes of a easy question. After retrieving outcomes from OpenSearch Service, you get the checklist of merchandise names and pictures from dataset:

The primary merchandise has a rating of 1.0, as a result of the 2 photos are the identical. Different objects are several types of glasses within the OpenSearch Service index.
You should utilize textual content to question the index as nicely:

You’re now capable of get three footage of water glasses from the index. You could find the pictures and textual content throughout the identical latent area with the CLIP encoder. One other instance of that is to seek for the phrase “pizza” within the index:

Clear up
With a pay-per-use mannequin, Serverless Inference is an economical possibility for an rare or unpredictable site visitors sample. You probably have a strict service-level agreement (SLA), or can’t tolerate chilly begins, real-time endpoints are a more sensible choice. Utilizing multi-model or multi-container endpoints present scalable and cost-effective options for deploying massive numbers of fashions. For extra data, check with Amazon SageMaker Pricing.
We advise deleting the serverless endpoints when they’re now not wanted. After ending this train, you’ll be able to take away the assets with the next steps (you’ll be able to delete these assets from the AWS Management Console, or utilizing the AWS SDK or SageMaker SDK):
- Delete the endpoint you created.
- Optionally, delete the registered fashions.
- Optionally, delete the SageMaker execution function.
- Optionally, empty and delete the S3 bucket.
Abstract
On this put up, we demonstrated easy methods to create a k-NN search software utilizing SageMaker and OpenSearch Service k-NN index options. We used a pre-trained CLIP mannequin from its OpenAI implementation.
The OpenSearch Service ingestion implementation of the put up is just used for prototyping. If you wish to ingest knowledge from Amazon S3 into OpenSearch Service at scale, you’ll be able to launch an Amazon SageMaker Processing job with the suitable occasion kind and occasion rely. For an additional scalable embedding ingestion resolution, check with Novartis AG uses Amazon OpenSearch Service K-Nearest Neighbor (KNN) and Amazon SageMaker to power search and recommendation (Part 3/4).
CLIP offers zero-shot capabilities, which makes it doable to undertake a pre-trained mannequin straight with out utilizing transfer learning to fine-tune a mannequin. This simplifies the applying of the CLIP mannequin. You probably have pairs of product photos and descriptive textual content, you’ll be able to fine-tune the mannequin with your personal knowledge utilizing switch studying to additional enhance the mannequin efficiency. For extra data, see Learning Transferable Visual Models From Natural Language Supervision and the CLIP GitHub repository.
Concerning the Authors
 Kevin Du is a Senior Information Lab Architect at AWS, devoted to helping prospects in expediting the event of their Machine Studying (ML) merchandise and MLOps platforms. With greater than a decade of expertise constructing ML-enabled merchandise for each startups and enterprises, his focus is on serving to prospects streamline the productionalization of their ML options. In his free time, Kevin enjoys cooking and watching basketball.
Kevin Du is a Senior Information Lab Architect at AWS, devoted to helping prospects in expediting the event of their Machine Studying (ML) merchandise and MLOps platforms. With greater than a decade of expertise constructing ML-enabled merchandise for each startups and enterprises, his focus is on serving to prospects streamline the productionalization of their ML options. In his free time, Kevin enjoys cooking and watching basketball.
 Ananya Roy is a Senior Information Lab architect specialised in AI and machine studying primarily based out of Sydney Australia . She has been working with various vary of shoppers to offer architectural steerage and assist them to ship efficient AI/ML resolution by way of knowledge lab engagement. Previous to AWS , she was working as senior knowledge scientist and handled large-scale ML fashions throughout completely different industries like Telco, banks and fintech’s. Her expertise in AI/ML has allowed her to ship efficient options for complicated enterprise issues, and she or he is keen about leveraging cutting-edge applied sciences to assist groups obtain their targets.
Ananya Roy is a Senior Information Lab architect specialised in AI and machine studying primarily based out of Sydney Australia . She has been working with various vary of shoppers to offer architectural steerage and assist them to ship efficient AI/ML resolution by way of knowledge lab engagement. Previous to AWS , she was working as senior knowledge scientist and handled large-scale ML fashions throughout completely different industries like Telco, banks and fintech’s. Her expertise in AI/ML has allowed her to ship efficient options for complicated enterprise issues, and she or he is keen about leveraging cutting-edge applied sciences to assist groups obtain their targets.





