The way to Construct a Scalable Knowledge Structure with Apache Kafka


Picture by Creator
Apache Kafka is a distributed message-passing system that works on a publisher-subscriber mannequin. It’s developed by Apache Software program Basis and written in Java and Scala. Kafka was created to beat the issue confronted by the distribution and scalability of conventional message-passing programs. It could possibly deal with and retailer giant volumes of knowledge with minimal latency and excessive throughput. As a consequence of these advantages, it may be appropriate for making real-time information processing purposes and streaming companies. It’s presently open-source and utilized by many organisations like Netflix, Walmart and Linkedin.
A Message Passing System makes a number of purposes ship or obtain information from one another with out worrying about information transmission and sharing. Level-to-Level and Writer-Subscriber are two widespread message-passing programs. In point-to-point, the sender pushes the information into the queue, and the receiver pops from it like a regular queue system following FIFO(first in, first out) precept. Additionally, the information will get deleted as soon as it will get learn, and solely a single receiver is allowed at a time. There is no such thing as a time dependency laid for the receiver to learn the message.

Fig.1 Level-to-Level Message System | Picture by Creator
Within the Writer-Subscriber mannequin, the sender is termed a writer, and the receiver is termed a subscriber. On this, a number of senders and receivers can learn or write information concurrently. However there’s a time dependency in it. The patron has to devour the message earlier than a sure period of time, because it will get deleted after that, even when it didn’t get learn. Relying on the consumer’s configuration, this time restrict is usually a day, every week, or a month.
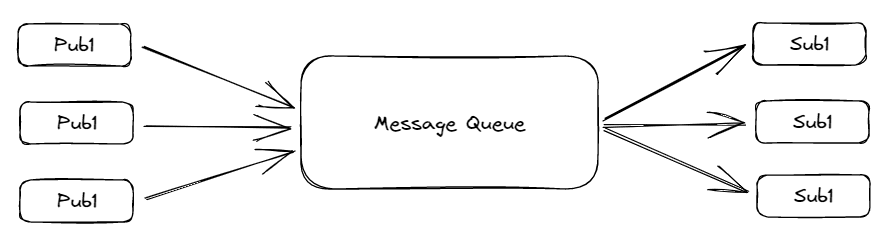
Fig.2 Writer-Subscriber Message System | Picture by Creator
Kafka structure consists of a number of key parts:
- Subject
- Partition
- Dealer
- Producer
- Shopper
- Kafka-Cluster
- Zookeeper
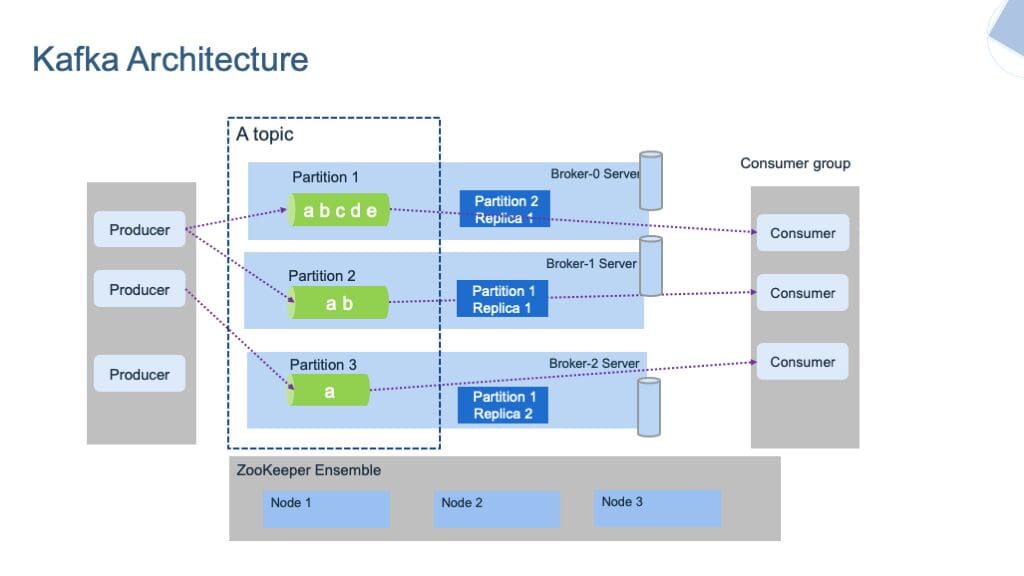
Fig.3 Kafka Structure | Picture by ibm-cloud-architecture
Let’s briefly perceive every element.
Kafka shops the messages in numerous Matters. A subject is a bunch that accommodates the messages of a selected class. It’s just like a desk in a database. A subject will be uniquely recognized by its identify. We can not create two subjects with the identical identify.
The subjects are additional categorized into Partitions. Every file of those partitions is related to a novel identifier termed Offset, which denotes the place of the file in that partition.
Apart from this, there are Producers and Shoppers within the system. Producers write or publish the information within the subjects utilizing the Producing APIs. These producers can write both on the subject or partition ranges.
Shoppers learn or devour the information from the subjects utilizing the Shopper APIs. They’ll additionally learn the information both on the subject or partition ranges. Shoppers who carry out related duties will type a bunch often called the Shopper Group.
There are different programs like Dealer and Zookeeper, which run within the background of Kafka Server. Brokers are the software program that maintains and retains the file of revealed messages. Additionally it is answerable for delivering the correct message to the correct client within the right order utilizing offsets. The set of brokers collectively speaking with one another will be referred to as Kafka clusters. Brokers will be dynamically added or faraway from the Kafka cluster with out going through any downtime within the system. And one of many brokers within the Kafka cluster is termed a Controller. It manages states and replicas contained in the cluster and performs administrative duties.
Alternatively, Zookeeper is answerable for sustaining the well being standing of the Kafka cluster and coordinating with every dealer of that cluster. It maintains the metadata of every cluster within the type of key-value pairs.
This tutorial is principally targeted on the sensible implementation of Apache Kafka. If you wish to learn extra about its structure, you may learn this article by Upsolver.
Contemplate the use case of a taxi reserving service like Uber. This software makes use of Apache Kafka to ship and obtain messages via varied companies like Transactions, Emails, Analytics, and so on.
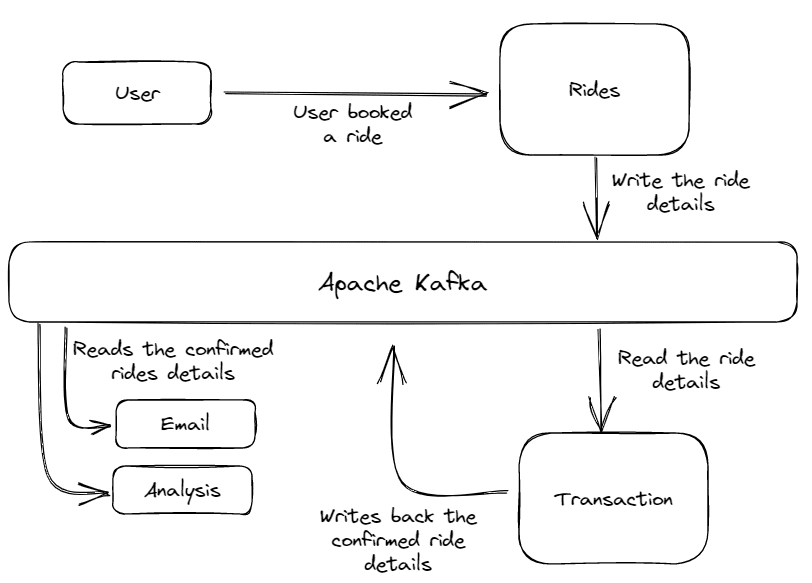
Fig.4 Structure of the Taxi App | Picture by Creator
The structure consists of a number of companies. The Rides service receives the journey request from the client and writes the journey particulars on the Kafka Message System.
Then these order particulars had been learn by the Transaction service, which confirms the order and fee standing. After confirming that journey, this Transaction service writes the confirmed journey once more within the message system with some further particulars. After which lastly, the confirmed journey particulars are learn by different companies like E mail or Knowledge Analytics to ship the affirmation mail to the client and to carry out some evaluation on it.
We are able to execute all these processes in real-time with very excessive throughput and minimal latency. Additionally, because of the functionality of horizontal scaling of Apache Kafka, we will scale this software to deal with hundreds of thousands of customers.
This part accommodates a fast tutorial to implement the kafka message system in our software. It contains the steps to obtain kafka, configure it, and create producer-consumer features.
Word: This tutorial relies on python programming language and makes use of a home windows machine.
Apache Kafka Downloading Steps
1.Obtain the newest model of Apache Kafka from that hyperlink. Kafka relies on JVM languages, so Java 7 or larger model have to be put in in your system.
- Extract the downloaded zip file out of your pc’s (C:) drive and rename the folder as
/apache-kafka.
- The father or mother listing comprise two sub-directories,
/binand/config, which accommodates the executable and configuration information for the zookeeper and the kafka server.
Configuration Steps
First, we have to create log directories for the Kafka and Zookeeper servers. These directories will retailer all of the metadata of those clusters and the messages of the subjects and partitions.
Word: By default, these log directories are created contained in the /tmp listing, a unstable listing that vanishes off all the information inside when the system shuts down or restarts. We have to set the everlasting path for the log directories to resolve this subject. Let’s see how.
Navigate to apache-kafka >> config and open the server.properties file. Right here you may configure many properties of kafka, like paths for log directories, log retention hours, variety of partitions, and so on.
Contained in the server.properties file, we now have to alter the trail of the log listing’s file from the momentary /tmp listing to a everlasting listing. The log listing accommodates the generated or written information within the Kafka Server. To alter the trail, replace the log.dirs variable from /tmp/kafka-logs to c:/apache-kafka/kafka-logs. This can make your logs saved completely.
log.dirs=c:/apache-kafka/kafka-logs
The Zookeeper server additionally accommodates some log information to retailer the metadata of the Kafka servers. To alter the trail, repeat the above step, i.e open zookeeper.properties file and change the trail as follows.
dataDir=c:/apache-kafka/zookeeper-logs
This zookeeper server will act as a useful resource supervisor for our kafka server.
Run the Kafka and Zookeeper Servers
To run the zookeeper server, open a brand new cmd immediate inside your father or mother listing and run the beneath command.
$ .binwindowszookeeper-server-start.bat .configzookeeper.properties
Picture by Creator
Maintain the zookeeper occasion operating.
To run the kafka server, open a separate cmd immediate and execute the beneath code.
$ .binwindowskafka-server-start.bat .configserver.properties
Maintain the kafka and zookeeper servers operating, and within the subsequent part, we’ll create producer and client features which is able to learn and write information to the kafka server.
Creating Producer & Shopper Capabilities
For creating the producer and client features, we’ll take the instance of our e-commerce app that we mentioned earlier. The `Orders` service will perform as a producer, which writes order particulars to the kafka server, and the E mail and Analytics service will perform as a client, which reads that information from the server. The Transaction service will work as a client in addition to a producer. It reads the order particulars and writes them again once more after transaction affirmation.
However first, we have to set up the Kafka python library, which accommodates inbuilt features for Producer and Shoppers.
$ pip set up kafka-python
Now, create a brand new listing named kafka-tutorial. We’ll create the python information inside that listing containing the required features.
$ mkdir kafka-tutorial
$ cd .kafka-tutorial
Producer Perform:
Now, create a python file named `rides.py` and paste the next code into it.
rides.py
import kafka
import json
import time
import random
topicName = "ride_details"
producer = kafka.KafkaProducer(bootstrap_servers="localhost:9092")
for i in vary(1, 10):
journey = {
"id": i,
"customer_id": f"user_{i}",
"location": f"Lat: {random.randint(-90, 90)}, Lengthy: {random.randint(-90, 90)}",
}
producer.ship(topicName, json.dumps(journey).encode("utf-8"))
print(f"Experience Particulars Ship Succesfully!")
time.sleep(5)
Rationalization:
Firstly, we now have imported all the required libraries, together with kafka. Then, the subject identify and an inventory of assorted gadgets are outlined. Do not forget that subject is a bunch that accommodates related kinds of messages. On this instance, this subject will comprise all of the orders.
Then, we create an occasion of a KafkaProducer perform and join it to the kafka server operating on the localhost:9092. In case your kafka server is operating on a distinct handle and port, then you should point out the server’s IP and port quantity there.
After that, we’ll generate some orders in JSON format and write them to the kafka server on the outlined subject identify. Sleep perform is used to generate a niche between the following orders.
Shopper Capabilities:
transaction.py
import json
import kafka
import random
RIDE_DETAILS_KAFKA_TOPIC = "ride_details"
RIDES_CONFIRMED_KAFKA_TOPIC = "ride_confirmed"
client = kafka.KafkaConsumer(
RIDE_DETAILS_KAFKA_TOPIC, bootstrap_servers="localhost:9092"
)
producer = kafka.KafkaProducer(bootstrap_servers="localhost:9092")
print("Listening Experience Particulars")
whereas True:
for information in client:
print("Loading Transaction..")
message = json.hundreds(information.worth.decode())
customer_id = message["customer_id"]
location = message["location"]
confirmed_ride = {
"customer_id": customer_id,
"customer_email": f"{customer_id}@xyz.com",
"location": location,
"alloted_driver": f"driver_{customer_id}",
"pickup_time": f"{random.randint(1, 20)}minutes",
}
print(f"Transaction Accomplished..({customer_id})")
producer.ship(
RIDES_CONFIRMED_KAFKA_TOPIC, json.dumps(confirmed_ride).encode("utf-8")
)
Rationalization:
The transaction.py file is used to verify the transitions made by the customers and assign them a driver and estimated pickup time. It reads the journey particulars from the kafka server and writes it once more within the kafka server after confirming the journey.
Now, create two python information named electronic mail.py and analytics.py, that are used to ship emails to the client for his or her journey affirmation and to carry out some evaluation respectively. These information are solely created to show that even a number of shoppers can learn the information from the Kafka server concurrently.
electronic mail.py
import kafka
import json
RIDES_CONFIRMED_KAFKA_TOPIC = "ride_confirmed"
client = kafka.KafkaConsumer(
RIDES_CONFIRMED_KAFKA_TOPIC, bootstrap_servers="localhost:9092"
)
print("Listening Confirmed Rides!")
whereas True:
for information in client:
message = json.hundreds(information.worth.decode())
electronic mail = message["customer_email"]
print(f"E mail despatched to {electronic mail}!")
evaluation.py
import kafka
import json
RIDES_CONFIRMED_KAFKA_TOPIC = "ride_confirmed"
client = kafka.KafkaConsumer(
RIDES_CONFIRMED_KAFKA_TOPIC, bootstrap_servers="localhost:9092"
)
print("Listening Confirmed Rides!")
whereas True:
for information in client:
message = json.hundreds(information.worth.decode())
id = message["customer_id"]
driver_details = message["alloted_driver"]
pickup_time = message["pickup_time"]
print(f"Knowledge despatched to ML Mannequin for evaluation ({id})!")
Now, we now have finished with the appliance, within the subsequent part, we’ll run all of the companies concurrently and test the efficiency.
Check the Software
Run every file one after the other in 4 separate command prompts.
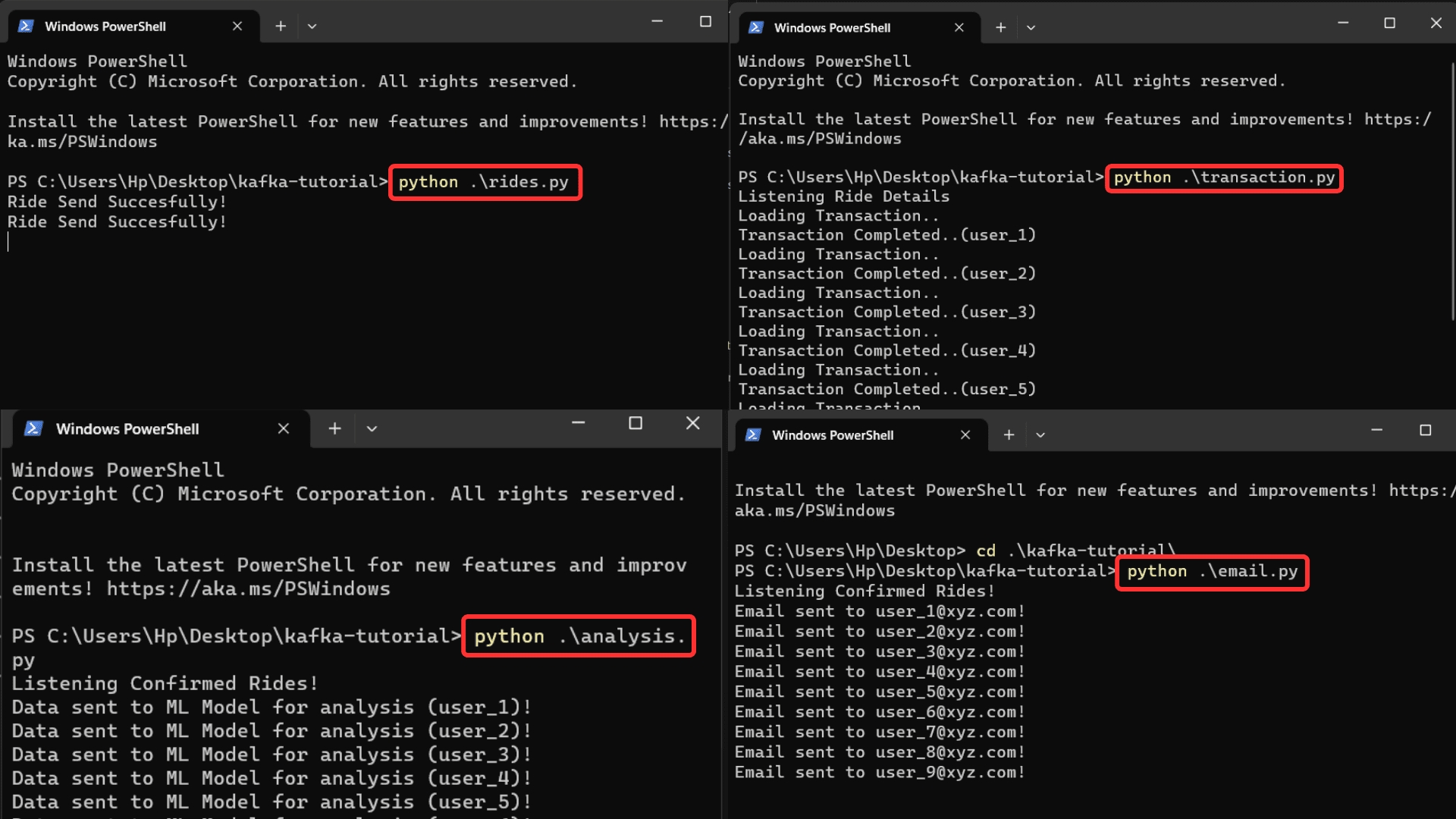
Picture by Creator
You’ll be able to obtain output from all of the information concurrently when the journey particulars are pushed into the server. You may also enhance processing velocity by eradicating the delay perform within the rides.py file. The `rides.py` file pushed the information into the kafka server, and the opposite three information concurrently learn that information from the kafka server and performance accordingly.
I hope you get a fundamental understanding of Apache Kafka and how one can implement it.
On this article, we now have learnt about Apache Kafka, its working and its sensible implementation utilizing a use case of a taxi reserving app. Designing a scalable pipeline with Kafka requires cautious planning and implementation. You’ll be able to enhance the variety of brokers and partitions to make these purposes extra scalable. Every partition is processed independently in order that the load will be distributed amongst them. Additionally, you may optimise the kafka configuration by setting the dimensions of the cache, the dimensions of the buffer or the variety of threads.
GitHub hyperlink for the whole code used within the article.
Thanks for studying this text. In case you have any feedback or options, please be happy to contact me on Linkedin.
Aryan Garg is a B.Tech. Electrical Engineering scholar, presently within the remaining 12 months of his undergrad. His curiosity lies within the discipline of Internet Improvement and Machine Studying. He have pursued this curiosity and am desirous to work extra in these instructions.






