Use Snowflake as an information supply to coach ML fashions with Amazon SageMaker

Amazon SageMaker is a completely managed machine studying (ML) service. With SageMaker, knowledge scientists and builders can rapidly and simply construct and prepare ML fashions, after which instantly deploy them right into a production-ready hosted setting. Sagemaker supplies an built-in Jupyter authoring pocket book occasion for straightforward entry to your knowledge sources for exploration and evaluation, so that you don’t must handle servers. It additionally supplies widespread ML algorithms which can be optimized to run effectively towards extraordinarily giant knowledge in a distributed setting.
SageMaker requires that the coaching knowledge for an ML mannequin be current both in Amazon Simple Storage Service (Amazon S3), Amazon Elastic File System (Amazon EFS) or Amazon FSx for Lustre (for more information, refer to Access Training Data). With a purpose to prepare a mannequin utilizing knowledge saved outdoors of the three supported storage companies, the info first must be ingested into one among these companies (usually Amazon S3). This requires constructing an information pipeline (utilizing instruments akin to Amazon SageMaker Data Wrangler) to maneuver knowledge into Amazon S3. Nevertheless, this strategy could create an information administration problem when it comes to managing the lifecycle of this knowledge storage medium, crafting entry controls, knowledge auditing, and so forth, all for the aim of staging coaching knowledge throughout the coaching job. In such conditions, it could be fascinating to have the info accessible to SageMaker within the ephemeral storage media hooked up to the ephemeral coaching cases with out the intermediate storage of information in Amazon S3.
This submit reveals a approach to do that utilizing Snowflake as the info supply and by downloading the info instantly from Snowflake right into a SageMaker Coaching job occasion.
Resolution overview
We use the California Housing Dataset as a coaching dataset for this submit and prepare an ML mannequin to foretell the median home worth for every district. We add this knowledge to Snowflake as a brand new desk. We create a customized coaching container that downloads knowledge instantly from the Snowflake desk into the coaching occasion reasonably than first downloading the info into an S3 bucket. After the info is downloaded into the coaching occasion, the customized coaching script performs knowledge preparation duties after which trains the ML mannequin utilizing the XGBoost Estimator. All code for this submit is obtainable within the GitHub repo.
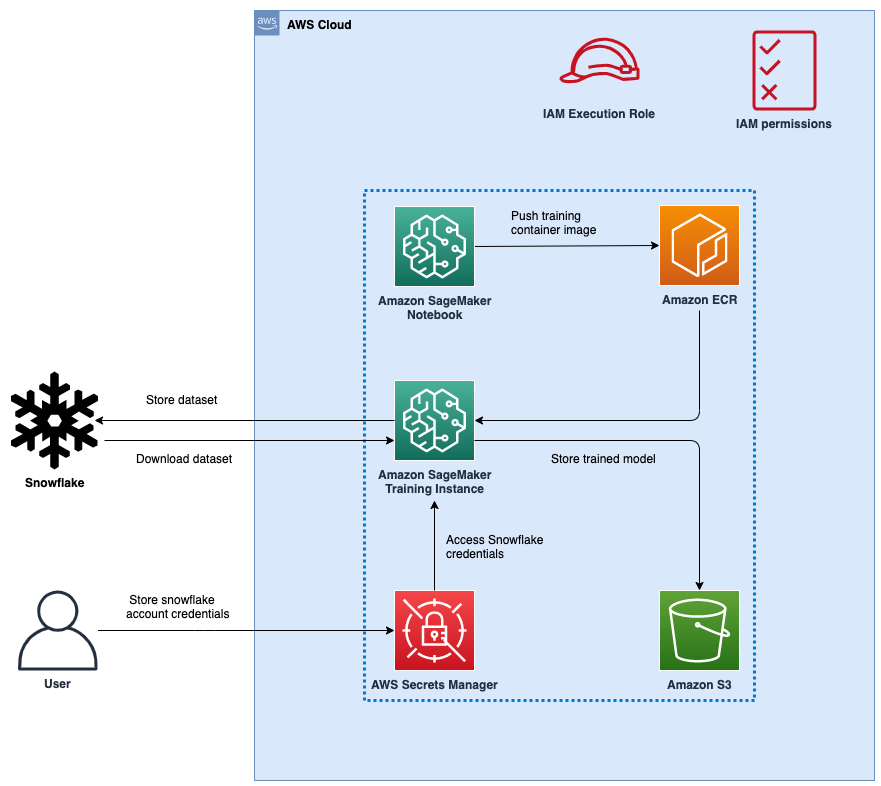
Determine 1: Structure
The next determine represents the high-level structure of the proposed resolution to make use of Snowflake as an information supply to coach ML fashions with SageMaker.
The workflow steps are as follows:
- Arrange a SageMaker pocket book and an AWS Identity and Access Management (IAM) function with applicable permissions to permit SageMaker to entry Amazon Elastic Container Registry (Amazon ECR), Secrets and techniques Supervisor, and different companies inside your AWS account.
- Retailer your Snowflake account credentials in AWS Secrets and techniques Supervisor.
- Ingest the info in a desk in your Snowflake account.
- Create a customized container picture for ML mannequin coaching and push it to Amazon ECR.
- Launch a SageMaker Coaching job for coaching the ML mannequin. The coaching occasion retrieves Snowflake credentials from Secrets and techniques Supervisor after which makes use of these credentials to obtain the dataset from Snowflake instantly. That is the step that eliminates the necessity for knowledge to be first downloaded into an S3 bucket.
- The educated ML mannequin is saved in an S3 bucket.
Conditions
To implement the answer supplied on this submit, you need to have an AWS account, a Snowflake account and familiarity with SageMaker.
Arrange a SageMaker Pocket book and IAM function
We use AWS CloudFormation to create a SageMaker pocket book known as aws-aiml-blogpost-sagemaker-snowflake-example and an IAM function known as SageMakerSnowFlakeExample. Select Launch Stack for the Area you wish to deploy sources to.
Retailer Snowflake credentials in Secrets and techniques Supervisor
Retailer your Snowflake credentials as a secret in Secrets and techniques Supervisor. For directions on how you can create a secret, confer with Create an AWS Secrets Manager secret.
- Title the key
snowflake_credentials. That is required as a result of the code insnowflake-load-dataset.ipynbexpects the key to be known as that. - Create the key as a key-value pair with two keys:
- username – Your Snowflake person title.
- password – The password related along with your Snowflake person title.
Ingest the info in a desk in your Snowflake account
To ingest the info, full the next steps:
- On the SageMaker console, select Notebooks within the navigation pane.
- Choose the pocket book aws-aiml-blogpost-sagemaker-snowflake-example and select Open JupyterLab.

Determine 2: Open JupyterLab
- Select
snowflake-load-dataset.ipynbto open it in JupyterLab. This pocket book will ingest the California Housing Dataset to a Snowflake desk. - Within the pocket book, edit the contents of the next cell to interchange the placeholder values with the one matching your snowflake account:
- On the Run menu, select Run All Cells to run the code on this pocket book. This may obtain the dataset regionally into the pocket book after which ingest it into the Snowflake desk.

Determine 3: Pocket book Run All Cells
The next code snippet within the pocket book ingests the dataset into Snowflake. See the snowflake-load-dataset.ipynb pocket book for the complete code.
- Shut the pocket book in spite of everything cells run with none error. Your knowledge is now out there in Snowflake. The next screenshot reveals the
california_housingdesk created in Snowflake.
Determine 4: Snowflake Desk
Run the sagemaker-snowflake-example.ipynb pocket book
This pocket book creates a customized coaching container with a Snowflake connection, extracts knowledge from Snowflake into the coaching occasion’s ephemeral storage with out staging it in Amazon S3, and performs Distributed Knowledge Parallel (DDP) XGBoost mannequin coaching on the info. DDP coaching isn’t required for mannequin coaching on such a small dataset; it’s included right here for illustration of yet one more just lately launched SageMaker function.
Determine 5: Open SageMaker Snowflake Instance Pocket book
Create a customized container for coaching
We now create a customized container for the ML mannequin coaching job. Be aware that root entry is required for making a Docker container. This SageMaker pocket book was deployed with root entry enabled. In case your enterprise group insurance policies don’t permit root entry to cloud sources, it’s possible you’ll wish to use the next Docker file and shell scripts to construct a Docker container elsewhere (for instance, your laptop computer) after which push it to Amazon ECR. We use the container primarily based on the SageMaker XGBoost container picture 246618743249.dkr.ecr.us-west-2.amazonaws.com/sagemaker-xgboost:1.5-1 with the next additions:
- The Snowflake Connector for Python to obtain the info from the Snowflake desk to the coaching occasion.
- A Python script to connect with Secrets and techniques Supervisor to retrieve Snowflake credentials.
Utilizing the Snowflake connector and Python script ensures that customers who use this container picture for ML mannequin coaching don’t have to put in writing this code as a part of their coaching script and may use this performance that’s already out there to them.
The next is the Dockerfile for the coaching container:
The container picture is constructed and pushed to Amazon ECR. This picture is used for coaching the ML mannequin.
Practice the ML mannequin utilizing a SageMaker Coaching job
After we efficiently create the container picture and push it to Amazon ECR, we will begin utilizing it for mannequin coaching.
- We create a set of Python scripts to obtain the info from Snowflake utilizing the Snowflake Connector for Python, put together the info after which use the
XGBoost Regressorto coach the ML mannequin. It’s the step of downloading the info on to the coaching occasion that avoids having to make use of Amazon S3 because the intermediate storage for coaching knowledge. - We facilitate Distributed Knowledge Parallel coaching by having the coaching code obtain a random subset of the info such that every coaching occasion downloads an equal quantity of information from Snowflake. For instance, if there are two coaching nodes, then every node downloads a random pattern of fifty% of the rows within the Snowflake desk.See the next code:
- We then present the coaching script to the SageMaker SDK
Estimatortogether with the supply listing so that each one the scripts we create might be supplied to the coaching container when the coaching job is run utilizing theEstimator.fittechnique:For extra info, confer with Prepare a Scikit-Learn Training Script.
- After the mannequin coaching is full, the educated mannequin is obtainable as a
mannequin.tar.gzfile within the default SageMaker bucket for the Area:
Now you can deploy the educated mannequin for getting inference on new knowledge! For directions, confer with Create your endpoint and deploy your model.
Clear up
To keep away from incurring future prices, delete the sources. You are able to do this by deleting the CloudFormation template used to create the IAM function and SageMaker pocket book.

Determine 6: Cleansing Up
You’ll have to delete the Snowflake sources manually from the Snowflake console.
Conclusion
On this submit, we confirmed how you can obtain knowledge saved in a Snowflake desk to a SageMaker Coaching job occasion and prepare an XGBoost mannequin utilizing a customized coaching container. This strategy permits us to instantly combine Snowflake as an information supply with a SageMaker pocket book with out having the info staged in Amazon S3.
We encourage you to study extra by exploring the Amazon SageMaker Python SDK and constructing an answer utilizing the pattern implementation supplied on this submit and a dataset related to your online business. In case you have questions or ideas, go away a remark.
In regards to the authors
 Amit Arora is an AI and ML specialist architect at Amazon Internet Providers, serving to enterprise prospects use cloud-based machine studying companies to quickly scale their improvements. He’s additionally an adjunct lecturer within the MS knowledge science and analytics program at Georgetown College in Washington D.C.
Amit Arora is an AI and ML specialist architect at Amazon Internet Providers, serving to enterprise prospects use cloud-based machine studying companies to quickly scale their improvements. He’s additionally an adjunct lecturer within the MS knowledge science and analytics program at Georgetown College in Washington D.C.
 Divya Muralidharan is a Options Architect at Amazon Internet Providers. She is captivated with serving to enterprise prospects clear up enterprise issues with expertise. She has a Masters in Laptop Science from Rochester Institute of Expertise. Exterior of workplace, she spends time cooking, singing, and rising vegetation.
Divya Muralidharan is a Options Architect at Amazon Internet Providers. She is captivated with serving to enterprise prospects clear up enterprise issues with expertise. She has a Masters in Laptop Science from Rochester Institute of Expertise. Exterior of workplace, she spends time cooking, singing, and rising vegetation.
 Sergey Ermolin is a Principal AIML Options Architect at AWS. Beforehand, he was a software program options architect for deep studying, analytics, and massive knowledge applied sciences at Intel. A Silicon Valley veteran with a ardour for machine studying and synthetic intelligence, Sergey has been taken with neural networks since pre-GPU days, when he used them to foretell growing older conduct of quartz crystals and cesium atomic clocks at Hewlett-Packard. Sergey holds an MSEE and a CS certificates from Stanford and a BS diploma in physics and mechanical engineering from California State College, Sacramento. Exterior of labor, Sergey enjoys wine-making, snowboarding, biking, crusing, and scuba-diving. Sergey can be a volunteer pilot for Angel Flight.
Sergey Ermolin is a Principal AIML Options Architect at AWS. Beforehand, he was a software program options architect for deep studying, analytics, and massive knowledge applied sciences at Intel. A Silicon Valley veteran with a ardour for machine studying and synthetic intelligence, Sergey has been taken with neural networks since pre-GPU days, when he used them to foretell growing older conduct of quartz crystals and cesium atomic clocks at Hewlett-Packard. Sergey holds an MSEE and a CS certificates from Stanford and a BS diploma in physics and mechanical engineering from California State College, Sacramento. Exterior of labor, Sergey enjoys wine-making, snowboarding, biking, crusing, and scuba-diving. Sergey can be a volunteer pilot for Angel Flight.






