A Comparability of 8 Scaling Strategies and When to Use Them [White Paper]
Like many different sorts of survey analysis, one of many essential targets of shopper analysis (and extra usually, market analysis) is to map the human decision-making course of. Extra particularly, it goals to grasp what a very powerful issues are when making a purchase order in order that services could be tailor-made to draw the most important variety of potential customers1. Over the previous century a mess of strategies have been developed to do exactly that. A few of these strategies are extra highly effective than others, and a few of them are greatest suited just for particular conditions. On this article, we look at eight of these strategies and impute 4 standardized efficiency metrics for them—size of time to finish, between-item discrimination, between-group discrimination, and predictive validity— to find out the optimum conditions below which to make use of every.
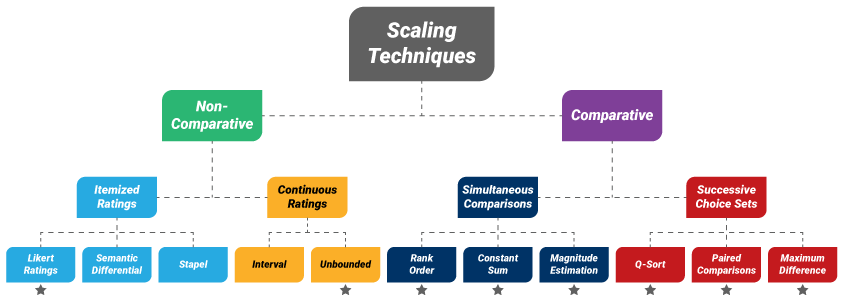
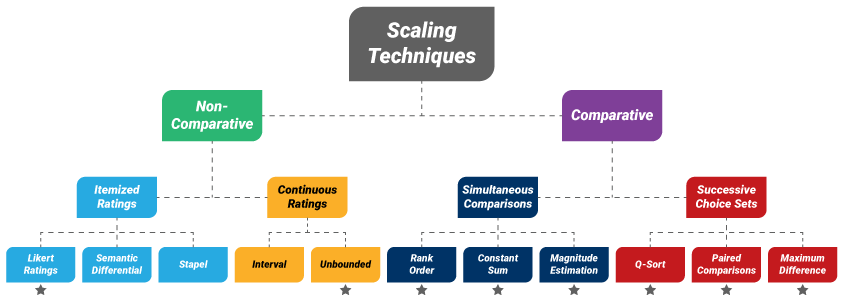
Determine 1. Varieties of scaling strategies
*Signifies approach is examined on this evaluation
On the whole, there are two sorts of scaling strategies out there to survey researchers: non-comparative (for which the respondents make no direct comparisons) and comparative (which require the respondents to check two or extra objects at a time)2. On this article, we examine two non-comparative and 6 comparative strategies (see Determine 1).
- Likert Rankings
- Unbounded Rankings
- Rank Order
- Fixed Sum
- Magnitude Estimation
- Paired Comparisons
- Q-Kind
- Most Distinction (MaxDiff)
Please observe, the opposite strategies in Determine 1: semantic differential, Stapel, and interval rankings—should not examined right here resulting from their missing of numerical efficiency metrics in present literature.
Non-Comparative Scaling Strategies
The non-comparative strategies are rankings scales, requiring respondents to assign every merchandise an significance score with out immediately evaluating any of them.
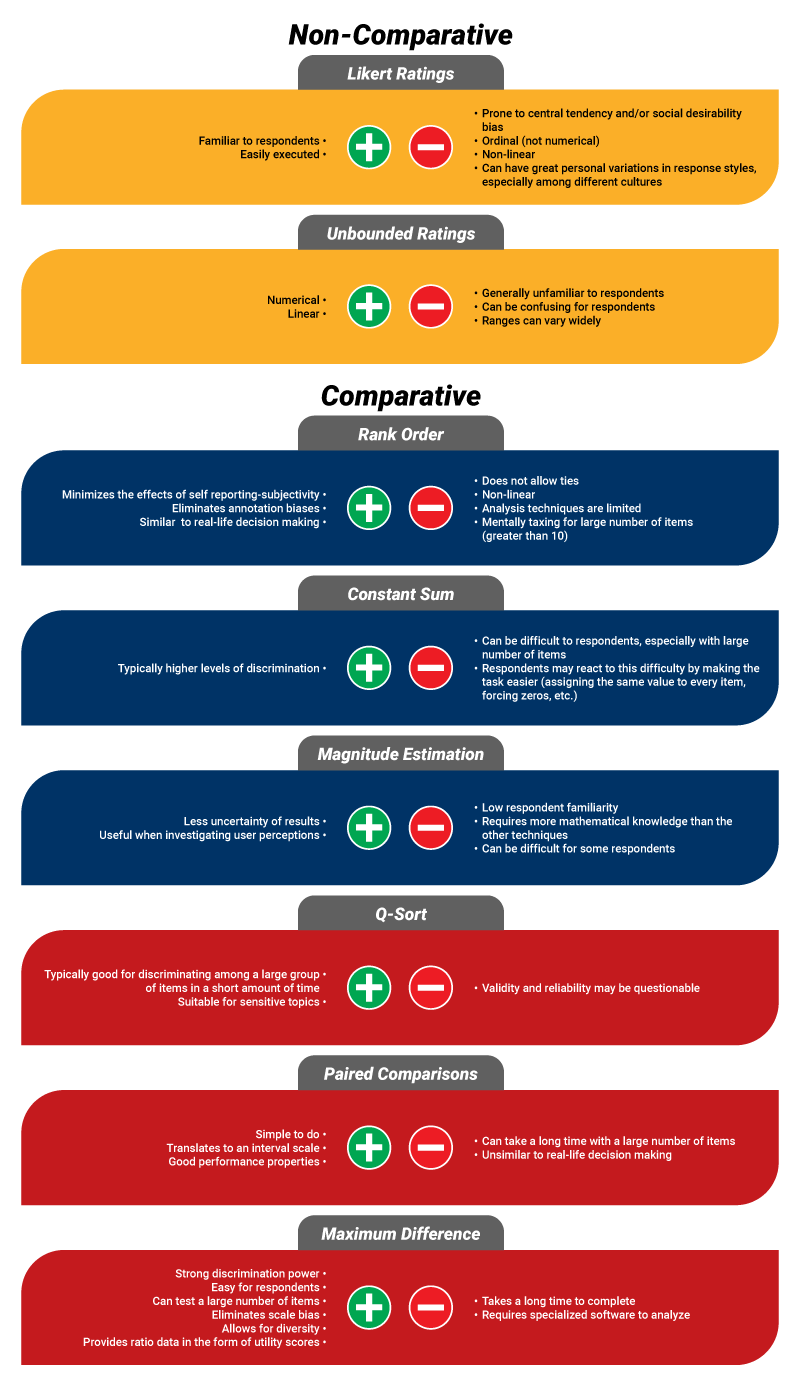
Itemized Rankings: The most typical kind of itemized score approach consists of a set of things, normally within the type of a grid, on which the respondent is requested to price how vital every merchandise is when making a purchase order choice on a particular scale. This scale is normally a Likert scale with 5, 7, or 10 values for which the bottom worth signifies the bottom stage of significance, and the very best worth signifies the very best stage of significance.
Steady Rankings: In distinction, a steady score scale has no mounted values, as is the case for an unbounded rankings scale. For this system, respondents are instructed to insert as many I’s (for ‘vital’) or as many U’s (for ‘unimportant’) as they really feel essential for every merchandise, or 0 if completely detached towards an merchandise. To right for the possibly huge distribution of ranges, every of the assigned values is split by the most important worth given by the respondent, in absolute worth phrases (See Determine 2 for an instance of the sort of query in a survey).
Determine 2. Instance of a survey query using unbounded rankings3

Comparative Scaling Strategies
Rank Order: Some of the primary comparative scales is rank order scaling. For this system, a set of N objects is introduced to respondents with directions to rank them from 1=’most vital’ to N=’least vital’ when making a particular choice. For ease of execution on the a part of respondents, it’s usually beneficial that N be no larger than ten4,5.
Fixed Sum: One other comparatively easy approach is fixed sum scaling. In contrast to rank order scaling, which has mounted values, fixed sum scaling requires respondents to allocate a quantity to every of the N objects (the bigger the quantity, the extra vital the merchandise) in order that the sum of the N numbers equals a prespecified worth, normally 1003,6.
Magnitude Estimation: Someplace in between the mounted worth rank order scaling and non-fixed worth fixed sum scaling is magnitude estimation: For this system, one merchandise is randomly chosen from an inventory of N and assigned a particular worth, serving as an anchor. The respondent is then requested to assign the remainder of the objects a worth relative to that anchored merchandise (i.e. if an merchandise is twice as vital, the respondent would assign twice the anchored worth, and if it was half as vital, the respondent would assign half of the anchored worth). To right for the possibly huge distribution of ranges, every worth is usually log-transformed7,8.
The three different comparative strategies are Q-sort, paired comparability scaling, and most distinction scaling (MaxDiff). These three strategies require the respondent to decide on objects in successive comparative units:
Q-Kind: For Q-sort, objects are categorized right into a quasi-normal distribution. For instance, a set of N=10 objects is proven to the respondent, and the respondent is requested 4 successive questions: “What’s a very powerful merchandise?”, “What are the subsequent (2) most vital objects?”, “What’s the least vital merchandise?” and “What are the subsequent (2) least vital objects?” and people chosen objects are assigned values of two, 1, -2 and -1, respectively. The remaining 4 objects are assigned a worth of 0, thus finishing the quasi-normal distribution. Q-sort is a blended technique, each qualitative and quantitative in nature9.
Paired Comparability: One other set-based approach is paired comparability scaling. This method can have a considerably larger variety of comparability units, however every set accommodates a quite simple alternative between 2 objects. Extra particularly, within the full mannequin, the respondent is introduced with N(N-1)/2 separate pairs (i.e. the entire attainable pairs of things) and is requested to pick out which merchandise from every pair is extra vital. For big N’s, nevertheless, a fractional mannequin (exhibiting a subset of all attainable comparisons) is usually ample10,11.
Most Distinction: And eventually, for max distinction (MaxDiff) scaling (also called best-worst scaling), the researcher chooses the variety of units the respondent will see. For N complete objects, the variety of objects in every set (y) can be chosen by the researcher, however is beneficial for greatest apply to be three, 4 or 5. And, if the researcher desires the respondent to see every merchandise z occasions total, the variety of units required is z x N/y; once more, for functions of greatest apply, z=3 is usually beneficial. For every set, the respondent is requested to decide on which merchandise is most vital to them and which merchandise is least vital. Lastly, the outcomes of the selection train are analyzed (usually a hierarchical Bayesian multinomial logistic regression) and every merchandise is assigned a steady ratio worth referred to as a utility rating3,12
Determine 3. Execs and cons of utilizing every of the 8 scaling strategies
Comparisons of Efficiency Metrics
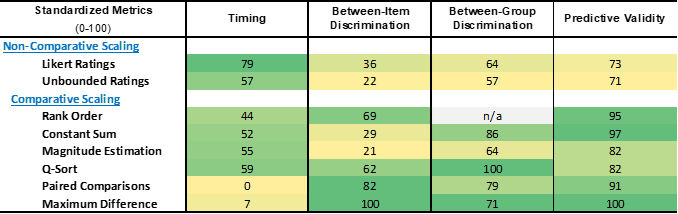
Utilizing knowledge from 5 completely different sources3,11,13,14,15, metrics on time to finish, between-item discrimination, between-group discrimination, and predictive validity for every approach are retrieved and standardized to a 0-100 scale for functions of comparability. For all 4 metrics, larger scores point out higher efficiency, together with time to finish (i.e. the next rating signifies a shorter time interval).
Time to Full: As seen in Desk 1, the quickest approach to finish is the Likert scale rankings, whereas paired comparisons takes practically 4 occasions as lengthy.
Between-Merchandise Discrimination: Most distinction has the perfect between-item discrimination, whereas magnitude estimation and unbounded rankings discriminate the least.
Between-Group Discrimination: Q-sort performs greatest at discriminating between teams of respondents whereas unbounded rankings scaling once more discriminates the least..
Predictive Validity: And eventually, most distinction scaling has the very best predictive validity whereas the 2 non-comparative strategies (Likert and unbounded rankings scaling) have the bottom.
Desk 1. Standardized efficiency metrics of the 8 scaling strategies
Optimum Circumstances for Utilizing Every Technique
Based mostly on the efficiency metrics, it’s clear that non-comparative scaling strategies don’t carry out in addition to their comparative counterparts.
Rankings scales are greatest used along with a comparative approach (for further validation) in addition to for market segmentation. Usually, Likert scale rankings ought to be thought of over unbounded rankings due to their familiarity to respondents (yielding a quicker time to finish), higher between-item discrimination, and barely higher between-group discrimination.
Magnitude estimation additionally performs comparatively poorly in comparison with different choices and is greatest suited if you find yourself searching for a deep investigation into person perceptions (primarily as a result of it’s one among solely two strategies with no restrictions on worth ranges larger than zero, the opposite being unbounded rankings).
Among the many larger performing choices…
Fixed sum scaling ought to be used while you want a comparatively fast approach to make predictions.
Q-sort ought to be carried out when that you must a fast approach to judge variations between teams.
Rank order scaling ought to be used while you want a fast approach and between-item discrimination is vital, like when figuring out what a very powerful attributes are when making a particular buy choice.
This leaves us with the 2 most time-consuming strategies, Paired Comparisons and MaxDiff. When the size of execution time just isn’t a problem…
Most Distinction scaling ought to be the strategy of alternative in case you have entry to the required evaluation software program (e.g., Sawtooth, R) or are working with a analysis companion, like Touchstone Analysis that may design and analyze MaxDiff outcomes.
Paired Comparisons is an effective possibility in the event you don’t have entry to the required software program (and should not working with a analysis companion like Touchstone Analysis).
Every of the strategies has its distinctive set of benefits and challenges and show to range in efficiency by completely different analysis need-states. To optimize the worth of shopper analysis, these variations ought to be fastidiously weighed when deciding the way to greatest mannequin buy decision-making processes.
Quantitative Analysis Experience
As any researcher is aware of, the standard of the survey instrument/questionnaire is among the most important items in direction of unlocking the very best high quality of perception for a analysis venture. With out a stable questionnaire at its basis, a analysis venture is probably going doomed to sub-par insights. Our in-house group of quantitative analysts and venture administrators are true consultants in designing, fielding, and analyzing quantitative analysis initiatives throughout a variety of methodologies. We all know what questions and scales to make use of, what stream to comply with, and what language/phrases to make use of for all audiences (together with preschoolers, children, and youths) to assist our purchasers get probably the most from their analysis initiatives. Our experience contains all the things from content material/pilot testing to tradition analysis to UX, and all the things in between. Need assistance designing, fielding, or analyzing your subsequent quantitative analysis venture? We might love to attach and talk about how we could possibly assist! Drop us a line at [email protected].

White Paper Ready by: Michael Kozloski – Senior Analysis Analyst
Michael is a Senior Analysis Analyst with over 15 years {of professional} expertise conducting quantitative market and social science analysis. Whereas he’s extremely skilled with all phases of the quantitative analysis course of and has led quite a few research throughout a variety of methodologies, his space of specific experience is in knowledge preparation and evaluation, with a key part being knowledge merging and meta-analyses.
Sources
- Jaeger, S., Jørgensen, A., Aaslyng, M. & Bredie, W. (2008). Finest–worst scaling: An introduction and preliminary comparability with monadic score for choice elicitation with meals merchandise. Meals High quality and Desire, 19(6), 579-588. doi:10.1016/j.foodqual.2008.03.002.
- Malhotra, N. & Birks, D.F. (2007). Measurement and scaling: fundamentals, comparative and non-comparative scaling. Advertising Analysis: An Utilized Method. 334-368.
- Chrzan, Okay., & Golovashkina, N. (2006). An empirical take a look at of six said significance measures. Worldwide Journal of Market Analysis, 48(6), 717-740. doi:10.1177/1470785306048006
- Yannakakis, G.N. & Martínez, H.P. (2015). Rankings are overrated! ICT, 2, 2:13. doi:10.3389/fict.2015.00013
- Rating questions vs. score questions. Verint. (2022, November 2). Retrieved January 10, 2023, from https://www.verint.com/weblog/ranking-questions-vs-rating-questions/
- Comparative scales. Questionstar. (2021, August 9). Retrieved January 14, 2023, from https://www.questionstar.com/textbook-principles-of-survey-research/survey-measurement-and-scaling/comparative-scales/
- Fukuda, S., Goodall, G., Michel, M. & Beecher, H. (2012). Is magnitude estimation definitely worth the bother? Proceedings of the twenty ninth West Coast Convention on Formal Linguistics, ed. Jaehoon Choi et al., Somerville, MA, pp. 328-336.
- Turpin, A., Scholer, F., Mizzaro, S. & Maddalena, E. (2015). The advantages of magnitude estimation relevance assessments for Data retrieval analysis. In Proceedings of the thirty eighth Worldwide ACM SIGIR Convention on Analysis and Growth in Data Retrieval (SIGIR ’15). Affiliation for Computing Equipment, New York, NY, pp. 565–574. doi:10.1145/2766462.2767760
- Bashatahl, L.S. (2016). Q-methodology: What and the way? IOSR Journal of Analysis & Technique in Schooling (IOSR-JRME), 6(5), 37-43. doi:10.9790/7388-0605053743
- Madansky, A. (2022, September 16). Knowledge use: Evaluating paired comparisons, most distinction and conventional rating: Article. Quirk’s Media. Retrieved January 10, 2023, from https://www.quirks.com/articles/data-use-evaluating-paired-comparisons-maximum-difference-and-traditional-ranking
- Cohen, S., & Orme, B. (2004). What’s your choice? Asking survey respondents about their preferences creates new scaling choices. Advertising Analysis, 16(2), 32-37.
- Mora, M. (2021, November 9). Making the case for Maxdiff. Related Insights. Retrieved January 10, 2023, from https://www.relevantinsights.com/articles/making-the-case-for-maxdiff/
- Cohen, S. (2003). Most distinction scaling: Improved measures of significance and choice for segmentation. Sawtooth Software program Convention Proceedings. San Diego, CA, 61-74.
- Crits-Christoph, P., Gallop, R., Diehl, C.Okay. & Yin, S. (2017). Strategies for incorporating affected person preferences for therapies of melancholy in neighborhood psychological well being settings. Adm Coverage Ment Well being, 44, 735–746. doi:10.1007/s10488-016-0746-1
- Lee, A., & Lind, M. (n.d.). A sensible take a look at options to conventional significance measures. YouGov DefinitiveInsights. Retrieved January 11, 2023, from http://cdn.yougov.com/cumulus_uploads/doc/w48tgcwndp/A_Practical_Look_at_Alternatives.pdf







