













Methods to Create Useful Information Assessments | by Xiaoxu Gao | Jul, 2023
What issues isn't the amount, however the high quality.Picture by Shubham Dhage on UnsplashData high quality has been extensively mentioned...
 EON Actuality Launches Strategic Partnership with Qlick Africa Group Ltd to Set up EON Actuality Kenya: Pioneering Academic and Industrial Improvements – EON Actuality
EON Actuality Launches Strategic Partnership with Qlick Africa Group Ltd to Set up EON Actuality Kenya: Pioneering Academic and Industrial Improvements – EON Actuality
 How I Would Study Information Science in 2025 (If I Might Begin Over)
How I Would Study Information Science in 2025 (If I Might Begin Over)
 The Greatest Solution to Put together for Knowledge Science and Machine Studying Interviews | by Marina Wyss – Gratitude Pushed
The Greatest Solution to Put together for Knowledge Science and Machine Studying Interviews | by Marina Wyss – Gratitude Pushed
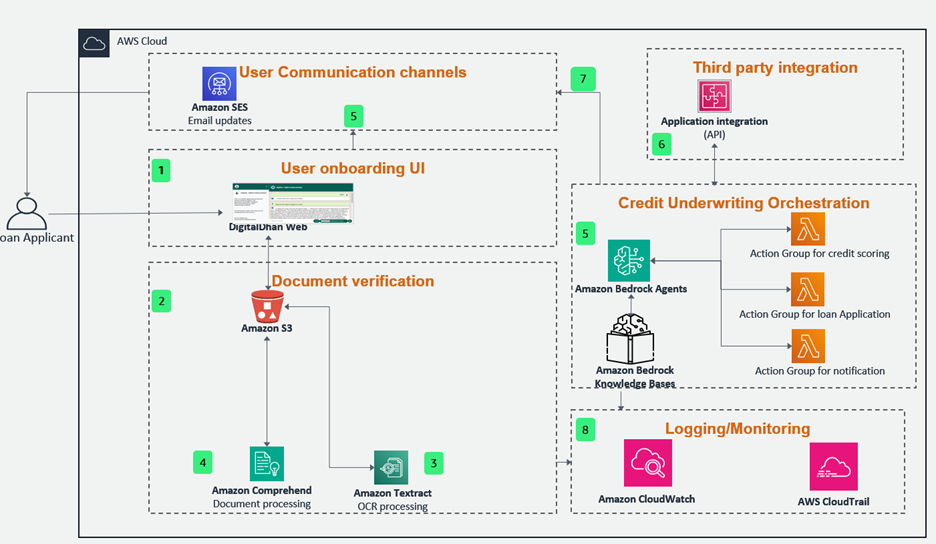
 Construct an Amazon Bedrock based mostly digital lending resolution on AWS
Construct an Amazon Bedrock based mostly digital lending resolution on AWS
 OPTIX unveils AR & VR improvements at CES 2025
OPTIX unveils AR & VR improvements at CES 2025
What issues isn't the amount, however the high quality.Picture by Shubham Dhage on UnsplashData high quality has been extensively mentioned...

Firms throughout varied industries create, scan, and retailer giant volumes of PDF paperwork. In lots of instances, the content material...

About six months in the past, we confirmed how to create a custom wrapper to acquire uncertainty estimates from a...

Leonardo da Vinci, the grasp of many disciplines, remodeled humanity's horizons by his artwork, science, and ingenuity. As we speak,...

This text was initially printed by Arprio. Trying to study extra about immersive know-how? Arprio helps firms navigate the XR...

Synthetic Intelligence (AI) and Predictive Analytics are reshaping the best way all companies function. On this article, we are going...

(Observe: the hyperlinks on this publish take you to explainers by the identical writer.)Duplicated knowledgePerhaps you measured 10,000 actual human...

Picture by Creator If you're working within the knowledge trade or aspire to take action, you may be questioning...

PNY Applied sciences is well-known within the computing business for its NVIDIA-based graphics playing cards, however the firm additionally participates...

Welcome to the world of state area fashions. On this world, there's a latent course of, hidden from our eyes;...

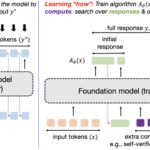
By combining a number of actions into one instruction, instruction tuning enhances generalization to new duties. Such capability to answer...

June 28, 2023 – BANC3, Inc., a know-how product improvement agency supporting the U.S. Division of Protection, has not too...

All the things has modified in a brief time frame. AI instruments, like ChatGPT and GPT-4, are taking on and...

This weblog submit is co-written with Marat Adayev and Dmitrii Evstiukhin from Provectus. When machine studying (ML) fashions are deployed...

Effective-tuning massive language fashions (LLMs) permits you to modify open-source foundational fashions to realize improved efficiency in your domain-specific duties....
