














Studying the significance of coaching knowledge below idea drift – Google Analysis Weblog
Posted by Nishant Jain, Pre-doctoral Researcher, and Pradeep Shenoy, Analysis Scientist, Google Analysis The consistently altering nature of the world...
 Mitigating threat: AWS spine community visitors prediction utilizing GraphStorm
Mitigating threat: AWS spine community visitors prediction utilizing GraphStorm
 EON Actuality Launches Enhanced Profession Pathway Simulations – EON Actuality
EON Actuality Launches Enhanced Profession Pathway Simulations – EON Actuality
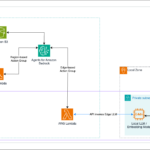
 HCLTech’s AWS powered AutoWise Companion: A seamless expertise for knowledgeable automotive purchaser choices with data-driven design
HCLTech’s AWS powered AutoWise Companion: A seamless expertise for knowledgeable automotive purchaser choices with data-driven design
 A Light Introduction to Rust for Python Programmers
A Light Introduction to Rust for Python Programmers
 Learnings from a Machine Studying Engineer — Half 1: The Knowledge | by David Martin | Jan, 2025
Learnings from a Machine Studying Engineer — Half 1: The Knowledge | by David Martin | Jan, 2025
Posted by Nishant Jain, Pre-doctoral Researcher, and Pradeep Shenoy, Analysis Scientist, Google Analysis The consistently altering nature of the world...

Neural operators, particularly the Fourier Neural Operators (FNO), have revolutionized how researchers strategy fixing partial differential equations (PDEs), a cornerstone...

AI is a transformational know-how. Even within the wake of twenty years of unprecedented innovation, AI stands aside as one...

Learn to guarantee the standard of your embeddings, which could be important to your machine-learning system.Creating high quality embeddings is...

Amazon SageMaker Feature Store is a totally managed, purpose-built repository to retailer, share, and handle options for machine studying (ML)...

Posted by Mónica Ribero Díaz, Analysis Scientist, Google Analysis Differential privacy (DP) is a property of randomized mechanisms that restrict...

February 14, 2024 – RealWear, a supplier of good glasses for frontline employees, has introduced that Provide Community, an employee-owned...

Promotional Content material Stable Diffusion models are revolutionizing digital artistry, reworking mere textual content into beautiful, lifelike pictures....

This put up is co-written with Santosh Waddi and Nanda Kishore Thatikonda from BigBasket. BigBasket is India’s largest on-line meals...

A heat wizard welcome! Have you ever, like many others, been questioning what all this metaverse enterprise is all about?...

For Enterprise and Crew customers, reminiscence might be helpful when utilizing ChatGPT for work. It could actually be taught your...

Reworking Studying and Employment via Immersive Applied sciences Irvine, CA – January XX– EON Actuality, the worldwide chief...

Since The New York Occasions sued OpenAI for infringing its copyrights by utilizing Occasions content material for coaching, everybody concerned...

Within the fascinating world of synthetic intelligence and music, a staff at Google DeepMind has made a groundbreaking stride. Their...
With its extremely profitable A100 and H100 processors for synthetic intelligence (AI) and high-performance computing (HPC) functions, NVIDIA dominates AI...

