How Veritone makes use of Amazon Bedrock, Amazon Rekognition, Amazon Transcribe, and knowledge retrieval to replace their video search pipeline
This publish is co-written with Tim Camara, Senior Product Supervisor at Veritone.
Veritone is a synthetic intelligence (AI) firm primarily based in Irvine, California. Based in 2014, Veritone empowers folks with AI-powered software program and options for varied functions, together with media processing, analytics, promoting, and extra. It provides options for media transcription, facial recognition, content material summarization, object detection, and different AI capabilities to unravel the distinctive challenges professionals face throughout industries.
Veritone started its journey with its foundational AI working system, aiWARETM, fixing business and brand-specific challenges by constructing functions on prime of this highly effective know-how. Rising within the media and leisure house, Veritone solves media administration, broadcast content material, and advert monitoring points. Alongside these functions, Veritone provides media companies together with AI-powered audio promoting and influencer advertising, content material licensing and media monetization companies, {and professional} companies to construct bespoke AI options.
With a decade of enterprise AI expertise, Veritone helps the general public sector, working with US federal authorities businesses, state and native authorities, regulation enforcement businesses, and authorized organizations to automate and simplify proof administration, redaction, person-of-interest monitoring, and eDiscovery. Veritone has additionally expanded into the expertise acquisition house, serving HR groups worldwide with its highly effective programmatic job promoting platform and distribution community.
Utilizing generative AI and new multimodal basis fashions (FMs) might be very strategic for Veritone and the companies they serve, as a result of it might considerably enhance media indexing and retrieval primarily based on contextual which means—a important first step to finally producing new content material. Constructing enhanced semantic search capabilities that analyze media contextually would lay the groundwork for creating AI-generated content material, permitting prospects to provide custom-made media extra effectively.
Veritone’s present media search and retrieval system depends on key phrase matching of metadata generated from ML companies, together with data associated to faces, sentiment, and objects. With current advances in massive language fashions (LLMs), Veritone has up to date its platform with these highly effective new AI capabilities. Wanting forward, Veritone desires to benefit from new superior FM methods to enhance the standard of media search outcomes of “Digital Media Hub”( DMH ) and develop the variety of customers by attaining a greater person expertise.
On this publish, we exhibit tips on how to use enhanced video search capabilities by enabling semantic retrieval of movies primarily based on textual content queries. We match probably the most related movies to text-based search queries by incorporating new multimodal embedding fashions like Amazon Titan Multimodal Embeddings to encode all visible, visual-meta, and transcription information. The first focus is constructing a strong textual content search that goes past conventional word-matching algorithms in addition to an interface for evaluating search algorithms. Moreover, we discover narrowing retrieval to particular photographs inside movies (a shot is a sequence of interrelated consecutive footage taken contiguously by a single digital camera representing a steady motion in time and house). General, we intention to enhance video search by way of cutting-edge semantic matching, offering an environment friendly strategy to discover movies related to your wealthy textual queries.
Answer overview
We use the next AWS companies to implement the answer:
Amazon Bedrock is a completely managed service that gives a selection of high-performing FMs from main AI corporations like AI21 Labs, Anthropic, Cohere, Meta, Mistral, Stability AI, and Amazon inside a single API, together with a broad set of capabilities you want to construct generative AI functions with safety, privateness, and accountable AI.
The present structure consists of three elements:
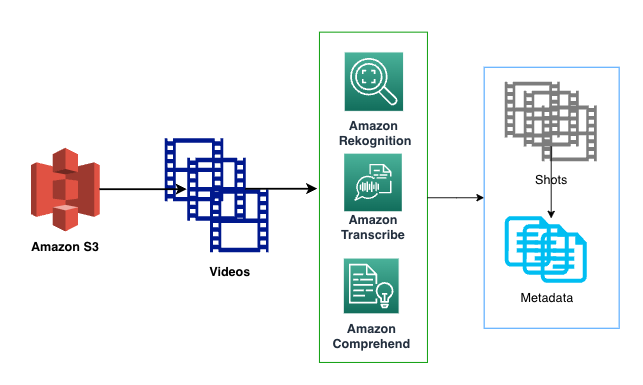
- Metadata technology – This element generates metadata from a video archive, processes it, and creates embeddings for search indexing. The movies from Amazon S3 are retrieved and transformed to H264 vcodec format utilizing the FFmpeg library. The processed movies are despatched to AWS companies like Amazon Rekognition, Amazon Transcribe, and Amazon Comprehend to generate metadata at shot stage and video stage. We use the Amazon Titan Textual content and Multimodal Embeddings fashions to embed the metadata and the video frames and index them in OpenSearch Service. We use AWS Step Functions to orchestrate your complete pipeline.
- Search – A UI-based video search pipeline takes within the person question as enter and retrieves related movies. The person question invokes a Lambda operate. Based mostly on the search technique chosen, you both carry out a text- or keyword-based search or an embedding-based search. The search physique is distributed to OpenSearch Service to retrieve video outcomes on the shot stage, which is exhibited to the person.
- Analysis – The UI allows you to carry out qualitative analysis towards completely different search settings. You enter a question and, primarily based on the search settings, video outcomes are retrieved from OpenSearch. You may view the outcomes and supply suggestions by voting for the successful setting.
The next diagram illustrates the answer structure.

The high-level takeaways from this work are the next:
- Utilizing an Amazon Rekognition API to detect photographs and index them achieved higher retrieving recall (at the very least 50% enchancment) than performing the identical on the video stage
- Incorporating the Amazon Titan Textual content Embeddings mannequin to semantically retrieve the video outcomes as a substitute of utilizing uncooked textual content generated by Amazon Rekognition and Amazon Transcribe boosted the recall efficiency by 52%
- The Amazon Titan Multimodal Embeddings mannequin confirmed excessive functionality to encode visible data of video picture frames and achieved the most effective efficiency when mixed with textual content embeddings of Amazon Rekognition and Amazon Transcribe textual content metadata, enhancing on baseline metrics by as much as 3 times
- The A/B analysis UI that we developed to check new search strategies and options proved to be efficient
Detailed quantitative evaluation of those conclusions is mentioned later on this publish.
Metadata technology pipeline
The video metadata technology pipeline consists of processing video information utilizing AWS companies resembling Amazon Transcribe, Amazon Rekognition, and Amazon Comprehend, as proven within the following diagram. The metadata is generated on the shot stage for a video.

On this part, we focus on the small print of every service and the workflow in additional element.
Amazon Transcribe
The transcription for your complete video is generated utilizing the StartTranscriptionJob API. When the job is full, you’ll be able to receive the uncooked transcript information utilizing GetTranscriptionJob. The GetTranscriptionJob returns a TranscriptFileUri, which could be processed to get the audio system and transcripts primarily based on a timestamp. The file codecs supported by Amazon Transcribe are AMR, FLAC (beneficial), M4A, MP3, MP4, Ogg, WebM, and WAV (beneficial).
The uncooked transcripts are additional processed to be saved utilizing timestamps, as proven within the following instance.

Amazon Rekognition
Amazon Rekognition requires the video to be encoded utilizing the H.264 codec and formatted to both MPEG-4 or MOV. We used FFmpeg to format the movies in Amazon S3 to the required vcodec. FFmpeg is a free and open-source software program undertaking within the type of a command line device designed for processing video, audio, and different multimedia information and streams. Python offers a wrapper library across the device known as ffmpeg-python.
The answer runs Amazon Rekognition APIs for label detection, text detection, celebrity detection, and face detection on movies. The metadata generated for every video by the APIs is processed and saved with timestamps. The movies are then segmented into particular person photographs. With Amazon Rekognition, you’ll be able to detect the beginning, finish, and length of every shot in addition to the overall shot rely for a content material piece. The video shot detection job begins with the StartSegmentDetection API, which returns a jobId that can be utilized to observe standing with the GetSegmentDetection API. When the video segmentation standing modifications to Succeeded, for every shot, you parse the beforehand generated Amazon Rekognition API metadata utilizing the shot’s timestamp. You then append this parsed metadata to the shot report. Equally, the complete transcript from Amazon Transcribe is segmented utilizing the shot begin and finish timestamps to create shot-level transcripts.
Amazon Comprehend
The temporal transcripts are then processed by Amazon Comprehend to detect entities and sentiments utilizing the DetectEntities, DetectSentiment, and DetectTargetedSentiment APIs. The next code offers extra particulars on the API requests and responses used to generate metadata by utilizing pattern shot-level metadata generated for a video:

Metadata processing
The shot-level metadata generated by the pipeline is processed to stage it for embedding technology. The purpose of this processing is to combination helpful data and take away null or much less important data that wouldn’t add worth for embedding technology.
The processing algorithm is as follows:
rekognition_metadata - shot_metadata: extract StartFrameNumber and EndFrameNumber - celeb_metadata: extract celeb_metadata - label_metadata: extract distinctive labels - text_metadata: extract distinctive textual content labels if there are greater than 3 phrases (comes noisy with "-", "null" and different values) - face_analysis_metadata: extract distinctive listing of AgeRange, Feelings, GenderWe mix all rekognition textual content information into `rek_text_metadata` stringtranscribe_metadata - transcribe_metadata: test the wordcount of the dialog throughout all audio system.whether it is greater than 50 phrases, mark it for summarization process with Amazon Bedrockcomprehend_metadata - comprehend_metadata: extract sentiment - comprehend_metadata: extract goal sentiment scores for phrases with rating > 0.9
Giant transcript summarization
Giant transcripts from the processed metadata are summarized by way of the Anthropic Claude 2 mannequin. After summarizing the transcript, we extract the names of the important thing characters talked about within the abstract as effectively the vital key phrases.
Embeddings technology
On this part, we focus on the small print for producing shot-level and video-level embeddings.
Shot-level embeddings
We generate two sorts of embeddings: textual content and multimodal. To grasp which metadata and repair contributes to the search efficiency and by how a lot, we create a various set of embeddings for experimental evaluation.
We implement the next with Amazon Titan Multimodal Embeddings:
- Embed picture:
- TMM_shot_img_embs – We pattern the center body from each shot and embed them. We assume the center body within the shot captures the semantic nuance in your complete shot. You too can experiment with embedding all of the frames and averaging them.
- TMM_rek_text_shot_emb – We pattern the center body from each shot and embed it together with Amazon Rekognition textual content information.
- TMM_transcribe_shot_emb – We pattern the center body from each shot and embed it together with Amazon Transcribe textual content information.
- Embed textual content (to match if the textual content information is represented effectively with the LLM or multimodal mannequin, we additionally embed them with Amazon Titan Multimodal):
- TMM_rek_text_emb – We embed the Amazon Rekognition textual content as multimodal embeddings with out the pictures.
- TMM_transcribe_emb – We embed the Amazon Transcribe textual content as multimodal embeddings with out the pictures.
We implement the next with the Amazon Titan Textual content Embeddings mannequin:
- Embed textual content:
- TT_rek_text_emb – We embed the Amazon Rekognition textual content as textual content embeddings
- TT_transcribe_emb – We embed the Amazon Transcribe textual content as textual content embeddings
Video-level embeddings
If a video has just one shot (a small video capturing a single motion), the embeddings would be the similar as shot-level embeddings.
For movies which have multiple shot, we implement the next utilizing the Amazon Titan Multimodal Embeddings Mannequin:
- Embed picture:
- TMM_shot_img_embs – We pattern Ok photographs with substitute throughout all of the shot-level metadata, generate embeddings, and common them
- TMM_rek_text_shot_emb – We pattern Ok photographs with substitute throughout all of the shot-level metadata, embed it together with Amazon Rekognition textual content information, and common them.
- TMM_transcribe_shot_emb – We pattern Ok photographs with substitute throughout all of the shot-level metadata, embed it together with Amazon Transcribe textual content information, and common them
- Embed textual content:
- TMM_rek_text_emb – We mix all of the Amazon Rekognition textual content information and embed it as multimodal embeddings with out the pictures
- TMM_transcribe_emb – We mix all of the Amazon Transcribe textual content information and embed it as multimodal embeddings with out the pictures
We implement the next utilizing the Amazon Titan Textual content Embeddings mannequin:
- Embed textual content:
- TT_rek_text_emb – We mix all of the Amazon Rekognition textual content information and embed it as textual content embeddings
- TT_transcribe_emb – We mix all of the Amazon Transcribe textual content information and embed it as textual content embeddings
Search pipeline
On this part, we focus on the elements of the search pipeline.
Search index creation
We use an OpenSearch cluster (OpenSearch Service area) with t3.medium.search to retailer and retrieve indexes for our experimentation with textual content, knn_vector, and Boolean fields listed. We advocate exploring Amazon OpenSearch Serverless for manufacturing deployment for indexing and retrieval. OpenSearch Serverless can index billions of data and has expanded its auto scaling capabilities to effectively deal with tens of hundreds of question transactions per minute.
The next screenshots are examples of the textual content, Boolean, and embedding fields that we created.



Question movement
The next diagram illustrates the question workflow.

You should use a person question to match the video data utilizing textual content or semantic (embedding) seek for retrieval.
For text-based retrieval, we use the search question as enter to retrieve outcomes from OpenSearch Service utilizing the search fields transcribe_metadata, transcribe_summary, transcribe_keyword, transcribe_speakers, and rek_text_metadata:
OpenSearch Enter
search_fields=[
"transcribe_metadata",
"transcribe_summary",
"transcribe_keyword",
"transcribe_speakers",
"rek_text_metadata"
]search_body = {
"question": {
"multi_match": {
"question": search_query,
"fields": search_fields
}
}
}For semantic retrieval, the question is embedded utilizing the amazon.Titan-embed-text-v1 or amazon.titan-embed-image-v1 mannequin, which is then used as an enter to retrieve outcomes from OpenSearch Service utilizing the search discipline title, which might match with the metadata embedding of selection:
OpenSearch Enter
search_body = {
"measurement": <variety of prime outcomes>,
"fields": ["name"],
"question": {
"knn": {
vector_field: {"vector": <embedding>, "okay": <size of embedding>}
}
},
}
Search outcomes mixture
Precise match and semantic search have their very own advantages relying on the appliance. Customers who seek for a particular superstar or film title would profit from an actual match search, whereas customers searching for thematic queries like “summer season seashore vibes” and “candlelit dinner” would discover semantic search outcomes extra relevant. To allow the most effective of each, we mix the outcomes from each sorts of searches. Moreover, completely different embeddings might seize completely different semantics (for instance, Amazon Transcribe textual content embedding vs. picture embedding with a multimodal mannequin). Subsequently, we additionally discover combining completely different semantic search outcomes.
To mix search outcomes from completely different search strategies and completely different rating ranges, we used the next logic:
- Normalize the scores from every outcomes listing independently to a standard 0–1 vary utilizing
rank_norm. - Sum the weighted normalized scores for every outcome video from all of the search outcomes.
- Type the outcomes primarily based on the rating.
- Return the highest Ok outcomes.
We use the rank_norm technique, the place the rating is calculated primarily based on the rank of every video within the listing. The next is the Python implementation of this technique:
def rank_norm(outcomes):
n_results = len(outcomes)
normalized_results = {}
for i, doc_id in enumerate(outcomes.keys()):
normalized_results[doc_id] = 1 - (i / n_results)
ranked_normalized_results = sorted(
normalized_results.objects(), key=lambda x: x[1], reverse=True
)
return dict(ranked_normalized_results)
Analysis pipeline
On this part, we focus on the elements of the analysis pipeline.
Search and analysis UI
The next diagram illustrates the structure of the search and analysis UI.

The UI webpage is hosted in an S3 bucket and deployed utilizing Amazon CloudFront distributions. The present strategy makes use of an API key for authentication. This may be enhanced by utilizing Amazon Cognito and registering customers. The person can carry out two actions on the webpage:
- Search – Enter the question to retrieve video content material
- Suggestions – Based mostly on the outcomes displayed for a question, vote for the successful technique
We create two API endpoints utilizing Amazon API Gateway: GET /search and POST /suggestions. The next screenshot illustrates our UI with two retrieval strategies which were anonymized for the person for a bias-free analysis.

GET /search
We move two QueryStringParameters with this API name:
- question – The person enter question
- technique – The strategy the person is evaluating
This API is created with a proxy integration with a Lambda operate invoked. The Lambda operate processes the question and, primarily based on the tactic used, retrieves outcomes from OpenSearch Service. The outcomes are then processed to retrieve movies from the S3 bucket and displayed on the webpage. Within the search UI, we use a particular technique (search setting) to retrieve outcomes:
Request?question=<>&technique=<>
Response
{
"outcomes": [
{"name": <video-name>, "score": <score>},
{"name": <video-name>, "score": <score>},
...
]
}
The next is a pattern request:
?question=candlelit dinner&technique=MethodB
The next screenshot exhibits our outcomes.

POST /suggestions
Given a question, every technique can have video content material and the video title displayed on the webpage. Based mostly on the relevance of the outcomes, the person can vote if a specific technique has higher efficiency over the opposite (win or lose) or if the strategies are tied. The API has a proxy connection to Lambda. Lambda shops these outcomes into an S3 bucket. Within the analysis UI, you’ll be able to analyze the tactic search outcomes to seek out the most effective search configuration setting. The request physique contains the next syntax:
Request Physique
{
"outcome": <successful technique>,
"searchQuery":<question>,
"sessionId":<current-session-id>,
"Technique<>":{
"methodType": <Kind of technique used>,
"outcomes":"[{"name":<video-name>,"score":<score>}]"},
"Technique<>":{
"methodType": <Kind of technique used>,
"outcomes":"[{"name":"1QT426_s01","score":1.5053753}]"}
}The next screenshot exhibits a pattern request.

Experiments and outcomes
On this part, we focus on the datasets utilized in our experiments and the quantitative and qualitative evaluations primarily based on the outcomes.
Quick movies dataset
This dataset contains 500 movies with a median size of 20 seconds. Every video has manually written metadata resembling key phrases and descriptions. Normally, the movies on this dataset are associated to journey, holidays, and eating places subjects.
The vast majority of movies are lower than 20 seconds and the utmost is 400 seconds, as illustrated within the following determine.

Lengthy movies dataset
The second dataset has 300 high-definition movies with a video size starting from 20–160 minutes, as illustrated within the following determine.

Quantitative analysis
We use the next metrics in our quantitative analysis:
- Imply reciprocal rank – Mean reciprocal rank (MRR) measures the inverse of the place variety of probably the most related merchandise in search outcomes.
- Recall@topK – We measure recall at topk as the proportion of accurately retrieved video out of the specified video search outcomes (floor reality). For instance:
A, B, C are associated (GT)A, D, N, M, G are the TopK retrieved moviesRecall @TOP5 = 1/3
We compute these metrics utilizing a floor reality dataset offered by Veritone that had mappings of search question examples to related video IDs.
The next desk summarizes the highest three retrieval strategies from the lengthy movies dataset (% enchancment over baseline).
| Strategies | Video Stage: MRR vs. Video-level Baseline MRR | Shot Stage: MRR vs. Video-level Baseline MRR | Video Stage: Recall@top10 vs. Video-level Baseline Recall@top10 | Shot Stage: Recall@top10 vs. Video-level Baseline Recall@top10 |
| Uncooked Textual content: Amazon Transcribe + Amazon Rekognition | Baseline comparability | N/A | . | . |
| Semantic: Amazon Transcribe + Amazon Rekognition | 0.84% | 52.41% | 19.67% | 94.00% |
| Semantic: Amazon Transcribe + Amazon Rekognition + Amazon Titan Multimodal | 37.31% | 81.19% | 71.00% | 93.33% |
| Semantic: Amazon Transcribe + Amazon Titan Multimodal | 15.56% | 58.54% | 61.33% | 121.33% |
The next are our observations on the MRR and recall outcomes:
- General shot-level retrieval outperforms the video-level retrieval baseline throughout each MRR and recall metrics.
- Uncooked textual content has decrease MRR and recall scores than embedding-based search on each video and shot stage. All three semantic strategies present enchancment in MRR and recall.
- Combining semantic (Amazon Transcribe + Amazon Rekognition + Amazon Titan Multimodal) yields the most effective enchancment throughout video MRR, shot MRR, and video recall metrics.
The next desk summarizes the highest three retrieval strategies from the brief movies dataset (% enchancment over baseline).
| Strategies | Video Stage: MRR vs. Video-level Baseline MRR | Shot Stage: MRR vs. Video-level Baseline MRR | Video Stage: Recall@top10 vs. Video-Stage Baseline Recall@top10 | Shot Stage: Recall@top10 vs. Video-level Baseline Recall@top10 |
| Uncooked Textual content: Amazon Transcribe + Amazon Rekognition | Baseline | N/A | Baseline | N/A |
| Semantic: Amazon Titan Multimodal | 226.67% | 226.67% | 373.57% | 382.61% |
| Semantic: Amazon Transcribe + Amazon Rekognition + Amazon Titan Multimodal | 100.00% | 60.00% | 299.28% | 314.29% |
| Semantic: Amazon Transcribe + Amazon Titan Multimodal | 53.33% | 53.33% | 307.21% | 312.77% |
We made the next observations on the MRR and recall outcomes:
- Encoding the movies utilizing the Amazon Titan Multimodal Embeddings mannequin alone yields the most effective outcome in comparison with including simply Amazon Transcribe, Amazon Transcribe + Rekognition, or Amazon Transcribe + Amazon Rekognition + Amazon Titan Multimodal Embeddings (as a consequence of lack of dialogue and scene modifications in these brief movies)
- All semantic retrieval strategies (2, 3, and 4) ought to at the very least have 53% enchancment over the baseline
- Though Amazon Titan Multimodal alone works effectively for this information, it ought to be famous that different metadata like Amazon Transcribe, Amazon Rekognition, and pre-existing human labels as semantic illustration retrieval could be augmented with Amazon Titan Multimodal Embeddings to enhance efficiency relying on the character of the information
Qualitative analysis
We evaluated the quantitative outcomes from our pipeline to seek out matches with the bottom reality shared by Veritone. Nonetheless, there might be different related movies within the retrieved outcomes from our pipeline that aren’t a part of the bottom reality, which might additional enhance a few of these metrics. Subsequently, to qualitatively consider our pipeline, we used an A/B testing framework, the place a person can view outcomes from two anonymized strategies (the metadata utilized by the tactic shouldn’t be uncovered to cut back any bias) and fee which ends had been extra aligned with the question entered.
The aggregated outcomes throughout the tactic comparability had been used to calculate the win fee to pick the ultimate embedding technique for search pipeline.
The next strategies had been shortlisted primarily based on Veritone’s curiosity to cut back a number of comparability strategies.
| Technique Title (Uncovered to Person) | Retrieval Kind (Not Uncovered to Person) |
| Technique E | Simply semantic Amazon Transcribe retrieval outcomes |
| Technique F | Fusion of semantic Amazon Transcribe + Amazon Titan Multimodal retrieval outcomes |
| Technique G | Fusion of semantic Amazon Transcribe + semantic Amazon Rekognition + Amazon Titan Multimodal retrieval outcomes |
The next desk summarizes the quantitative outcomes and successful fee.
| Experiment | Profitable Technique (Depend of Queries) | . | . |
| Technique E | Technique F | Tie | |
| Technique E vs. Technique F | 10% | 85% | 5% |
| Technique F | Technique G | Tie | |
| Technique F vs. Technique G | 30% | 60% | 10% |
Based mostly on the outcomes, we see that including Amazon Titan Multimodal Embeddings to the transcription technique (Technique F) is best than simply utilizing semantic transcription retrieval (Technique E). Including Amazon Rekognition primarily based retrieval outcomes (Technique G) improves over Technique F.
Takeaways
We had the next key takeaways:
- Enabling vector search indexing and retrieving as a substitute of relying solely on textual content matching with AI generated textual content metadata improves the search recall.
- Indexing and retrieving movies on the shot stage can enhance efficiency and enhance buyer expertise. Customers can effectively discover exact clips matching their question fairly than sifting by way of total movies.
- Multimodal illustration of queries and metadata by way of fashions educated on each photographs and textual content have higher efficiency over single modality illustration from fashions educated on simply textual information.
- The fusion of textual content and visible cues considerably improves search relevance by capturing semantic alignments between queries and clips extra precisely and semantically capturing the person search intent.
- Enabling direct human comparability between retrieval fashions by way of A/B testing permits for inspecting and deciding on the optimum strategy. This could enhance the boldness to ship new options or search strategies to manufacturing.
Safety greatest practices
We advocate the next safety pointers for constructing safe functions on AWS:
Conclusion
On this publish, we confirmed how Veritone upgraded their classical search pipelines with Amazon Titan Multimodal Embeddings in Amazon Bedrock by way of a couple of API calls. We confirmed how movies could be listed in several representations, textual content vs. textual content embeddings vs. multimodal embeddings, and the way they are often analyzed to provide a strong search primarily based on the information traits and use case.
If you’re involved in working with the AWS Generative AI Innovation Middle, please attain out to the GenAIIC.
In regards to the Authors
 Tim Camara is a Senior Product Supervisor on the Digital Media Hub workforce at Veritone. With over 15 years of expertise throughout a variety of applied sciences and industries, he’s centered on discovering methods to make use of rising applied sciences to enhance buyer experiences.
Tim Camara is a Senior Product Supervisor on the Digital Media Hub workforce at Veritone. With over 15 years of expertise throughout a variety of applied sciences and industries, he’s centered on discovering methods to make use of rising applied sciences to enhance buyer experiences.
 Mohamad Al Jazaery is an Utilized Scientist on the Generative AI Innovation Middle. As a scientist and tech lead, he helps AWS prospects envision and construct GenAI options to deal with their enterprise challenges in several domains resembling Media and Leisure, Finance, and Way of life.
Mohamad Al Jazaery is an Utilized Scientist on the Generative AI Innovation Middle. As a scientist and tech lead, he helps AWS prospects envision and construct GenAI options to deal with their enterprise challenges in several domains resembling Media and Leisure, Finance, and Way of life.

Meghana Ashok is a Machine Studying Engineer on the Generative AI Innovation Middle. She collaborates intently with prospects, guiding them in creating safe, cost-efficient, and resilient options and infrastructure tailor-made to their generative AI wants.
 Divya Bhargavi is a Senior Utilized Scientist Lead on the Generative AI Innovation Middle, the place she solves high-value enterprise issues for AWS prospects utilizing generative AI strategies. She works on picture/video understanding and retrieval, data graph augmented massive language fashions, and personalised promoting use circumstances.
Divya Bhargavi is a Senior Utilized Scientist Lead on the Generative AI Innovation Middle, the place she solves high-value enterprise issues for AWS prospects utilizing generative AI strategies. She works on picture/video understanding and retrieval, data graph augmented massive language fashions, and personalised promoting use circumstances.
 Vidya Sagar Ravipati is a Science Supervisor on the Generative AI Innovation Middle, the place he makes use of his huge expertise in large-scale distributed techniques and his ardour for machine studying to assist AWS prospects throughout completely different business verticals speed up their AI and cloud adoption.
Vidya Sagar Ravipati is a Science Supervisor on the Generative AI Innovation Middle, the place he makes use of his huge expertise in large-scale distributed techniques and his ardour for machine studying to assist AWS prospects throughout completely different business verticals speed up their AI and cloud adoption.





