Value-effective doc classification utilizing the Amazon Titan Multimodal Embeddings Mannequin
Organizations throughout industries need to categorize and extract insights from excessive volumes of paperwork of various codecs. Manually processing these paperwork to categorise and extract info stays costly, error inclined, and tough to scale. Advances in generative artificial intelligence (AI) have given rise to clever doc processing (IDP) options that may automate the doc classification, and create a cheap classification layer able to dealing with various, unstructured enterprise paperwork.
Categorizing paperwork is a crucial first step in IDP techniques. It helps you establish the subsequent set of actions to take relying on the kind of doc. For instance, throughout the claims adjudication course of, the accounts payable workforce receives the bill, whereas the claims division manages the contract or coverage paperwork. Conventional rule engines or ML-based classification can classify the paperwork, however usually attain a restrict on kinds of doc codecs and assist for the dynamic addition of a brand new courses of doc. For extra info, see Amazon Comprehend document classifier adds layout support for higher accuracy.
On this publish, we talk about doc classification utilizing the Amazon Titan Multimodal Embeddings model to categorise any doc varieties with out the necessity for coaching.
Amazon Titan Multimodal Embeddings
Amazon not too long ago launched Titan Multimodal Embeddings in Amazon Bedrock. This mannequin can create embeddings for pictures and textual content, enabling the creation of doc embeddings for use in new doc classification workflows.
It generates optimized vector representations of paperwork scanned as pictures. By encoding each visible and textual parts into unified numerical vectors that encapsulate semantic which means, it allows speedy indexing, highly effective contextual search, and correct classification of paperwork.
As new doc templates and kinds emerge in enterprise workflows, you possibly can merely invoke the Amazon Bedrock API to dynamically vectorize them and append to their IDP techniques to quickly improve doc classification capabilities.
Answer overview
Let’s look at the next doc classification resolution with the Amazon Titan Multimodal Embeddings mannequin. For optimum efficiency, it’s best to customise the answer to your particular use case and present IDP pipeline setup.
This resolution classifies paperwork utilizing vector embedding semantic search by matching an enter doc to an already listed gallery of paperwork. We use the next key parts:
- Embeddings – Embeddings are numerical representations of real-world objects that machine studying (ML) and AI techniques use to know complicated data domains like people do.
- Vector databases – Vector databases are used to retailer embeddings. Vector databases effectively index and set up the embeddings, enabling quick retrieval of comparable vectors primarily based on distance metrics like Euclidean distance or cosine similarity.
- Semantic search – Semantic search works by contemplating the context and which means of the enter question and its relevance to the content material being searched. Vector embeddings are an efficient method to seize and retain the contextual which means of textual content and pictures. In our resolution, when an utility desires to carry out a semantic search, the search doc is first transformed into an embedding. The vector database with related content material is then queried to seek out essentially the most comparable embeddings.
Within the labeling course of, a pattern set of enterprise paperwork like invoices, financial institution statements, or prescriptions are transformed into embeddings utilizing the Amazon Titan Multimodal Embeddings mannequin and saved in a vector database towards predefined labels. The Amazon Titan Multimodal Embedding mannequin was skilled utilizing the Euclidean L2 algorithm and subsequently for greatest outcomes the vector database used ought to assist this algorithm.
The next structure diagram illustrates how you should use the Amazon Titan Multimodal Embeddings mannequin with paperwork in an Amazon Simple Storage Service (Amazon S3) bucket for picture gallery creation.
The workflow consists of the next steps:
- A consumer or utility uploads a pattern doc picture with classification metadata to a doc picture gallery. An S3 prefix or S3 object metadata can be utilized to categorise gallery pictures.
- An Amazon S3 object notification occasion invokes the embedding AWS Lambda perform.
- The Lambda perform reads the doc picture and interprets the picture into embeddings by calling Amazon Bedrock and utilizing the Amazon Titan Multimodal Embeddings mannequin.
- Picture embeddings, together with doc classification, are saved within the vector database.

When a brand new doc wants classification, the identical embedding mannequin is used to transform the question doc into an embedding. Then, a semantic similarity search is carried out on the vector database utilizing the question embedding. The label retrieved towards the highest embedding match would be the classification label for the question doc.
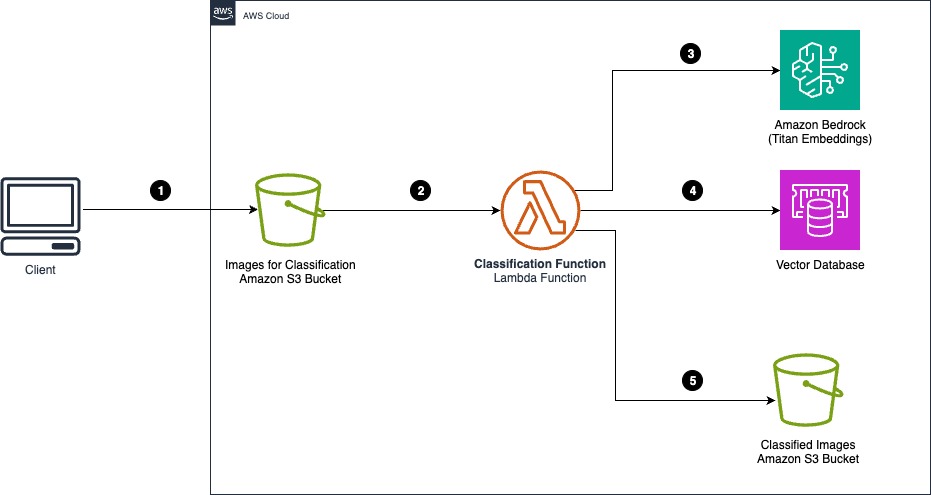
The next structure diagram illustrates find out how to use the Amazon Titan Multimodal Embeddings mannequin with paperwork in an S3 bucket for picture classification.
The workflow consists of the next steps:
- Paperwork that require classification are uploaded to an enter S3 bucket.
- The classification Lambda perform receives the Amazon S3 object notification.
- The Lambda perform interprets the picture to an embedding by calling the Amazon Bedrock API.
- The vector database is looked for an identical doc utilizing semantic search. Classification of the matching doc is used to categorise the enter doc.
- The enter doc is moved to the goal S3 listing or prefix utilizing the classification retrieved from the vector database search.

That can assist you check the answer with your individual paperwork, now we have created an instance Python Jupyter pocket book, which is obtainable on GitHub.
Conditions
To run the pocket book, you want an AWS account with acceptable AWS Identity and Access Management (IAM) permissions to name Amazon Bedrock. Moreover, on the Mannequin entry web page of the Amazon Bedrock console, make it possible for entry is granted for the Amazon Titan Multimodal Embeddings mannequin.
Implementation
Within the following steps, change every consumer enter placeholder with your individual info:
- Create the vector database. On this resolution, we use an in-memory FAISS database, however you possibly can use another vector database. Amazon Titan’s default dimension dimension is 1024.
- After the vector database is created, enumerate over the pattern paperwork, creating embeddings of every and retailer these into the vector database
- Take a look at along with your paperwork. Change the folders within the following code with your individual folders that include identified doc varieties:
- Utilizing the Boto3 library, name Amazon Bedrock. The variable
inputImageB64is a base64 encoded byte array representing your doc. The response from Amazon Bedrock comprises the embeddings.
- Add the embeddings to the vector database, with a category ID that represents a identified doc sort:
- With the vector database populated with pictures (representing our gallery), you possibly can uncover similarities with new paperwork. For instance, the next is the syntax used for search. The okay=1 tells FAISS to return the highest 1 match.
As well as, the Euclidean L2 distance between the picture available and the discovered picture can be returned. If the picture is an actual match, this worth can be 0. The bigger this worth is, the additional aside the photographs are in similarity.
Further concerns
On this part, we talk about further concerns for utilizing the answer successfully. This consists of information privateness, safety, integration with present techniques, and value estimates.
Information privateness and safety
The AWS shared responsibility model applies to data protection in Amazon Bedrock. As described on this mannequin, AWS is chargeable for defending the worldwide infrastructure that runs all the AWS Cloud. Prospects are chargeable for sustaining management over their content material that’s hosted on this infrastructure. As a buyer, you’re chargeable for the safety configuration and administration duties for the AWS providers that you just use.
Information safety in Amazon Bedrock
Amazon Bedrock avoids utilizing buyer prompts and continuations to coach AWS fashions or share them with third events. Amazon Bedrock doesn’t retailer or log buyer information in its service logs. Mannequin suppliers don’t have entry to Amazon Bedrock logs or entry to buyer prompts and continuations. Consequently, the photographs used for producing embeddings by the Amazon Titan Multimodal Embeddings mannequin are usually not saved or employed in coaching AWS fashions or exterior distribution. Moreover, different utilization information, equivalent to timestamps and logged account IDs, is excluded from mannequin coaching.
Integration with present techniques
The Amazon Titan Multimodal Embeddings mannequin underwent coaching with the Euclidean L2 algorithm, so the vector database getting used ought to be appropriate with this algorithm.
Value estimate
On the time of penning this publish, as per Amazon Bedrock Pricing for the Amazon Titan Multimodal Embeddings mannequin, the next are the estimated prices utilizing on-demand pricing for this resolution:
- One-time indexing value – $0.06 for a single run of indexing, assuming a 1,000 pictures gallery
- Classification value – $6 for 100,000 enter pictures per thirty days
Clear up
To keep away from incurring future fees, delete the assets you created, such because the Amazon SageMaker notebook instance, when not in use.
Conclusion
On this publish, we explored how you should use the Amazon Titan Multimodal Embeddings mannequin to construct a reasonable resolution for doc classification within the IDP workflow. We demonstrated find out how to create a picture gallery of identified paperwork and carry out similarity searches with new paperwork to categorise them. We additionally mentioned the advantages of utilizing multimodal picture embeddings for doc classification, together with their potential to deal with various doc varieties, scalability, and low latency.
As new doc templates and kinds emerge in enterprise workflows, builders can invoke the Amazon Bedrock API to vectorize them dynamically and append to their IDP techniques to quickly improve doc classification capabilities. This creates a reasonable, infinitely scalable classification layer that may deal with even essentially the most various, unstructured enterprise paperwork.
General, this publish offers a roadmap for constructing a reasonable resolution for doc classification within the IDP workflow utilizing Amazon Titan Multimodal Embeddings.
As subsequent steps, try What is Amazon Bedrock to begin utilizing the service. And comply with Amazon Bedrock on the AWS Machine Learning Blog to maintain updated with new capabilities and use instances for Amazon Bedrock.
In regards to the Authors
 Sumit Bhati is a Senior Buyer Options Supervisor at AWS, focuses on expediting the cloud journey for enterprise prospects. Sumit is devoted to helping prospects by each section of their cloud adoption, from accelerating migrations to modernizing workloads and facilitating the mixing of progressive practices.
Sumit Bhati is a Senior Buyer Options Supervisor at AWS, focuses on expediting the cloud journey for enterprise prospects. Sumit is devoted to helping prospects by each section of their cloud adoption, from accelerating migrations to modernizing workloads and facilitating the mixing of progressive practices.
 David Girling is a Senior AI/ML Options Architect with over 20 years of expertise in designing, main, and growing enterprise techniques. David is a part of a specialist workforce that focuses on serving to prospects study, innovate, and make the most of these extremely succesful providers with their information for his or her use instances.
David Girling is a Senior AI/ML Options Architect with over 20 years of expertise in designing, main, and growing enterprise techniques. David is a part of a specialist workforce that focuses on serving to prospects study, innovate, and make the most of these extremely succesful providers with their information for his or her use instances.
 Ravi Avula is a Senior Options Architect in AWS specializing in Enterprise Structure. Ravi has 20 years of expertise in software program engineering and has held a number of management roles in software program engineering and software program structure working within the funds trade.
Ravi Avula is a Senior Options Architect in AWS specializing in Enterprise Structure. Ravi has 20 years of expertise in software program engineering and has held a number of management roles in software program engineering and software program structure working within the funds trade.
 George Belsian is a Senior Cloud Utility Architect at AWS. He’s captivated with serving to prospects speed up their modernization and cloud adoption journey. In his present position, George works alongside buyer groups to strategize, architect, and develop progressive, scalable options.
George Belsian is a Senior Cloud Utility Architect at AWS. He’s captivated with serving to prospects speed up their modernization and cloud adoption journey. In his present position, George works alongside buyer groups to strategize, architect, and develop progressive, scalable options.





