Average audio and textual content chats utilizing AWS AI providers and LLMs
On-line gaming and social communities provide voice and textual content chat performance for his or her customers to speak. Though voice and textual content chat typically help pleasant banter, it will possibly additionally result in issues similar to hate speech, cyberbullying, harassment, and scams. At this time, many corporations rely solely on human moderators to overview poisonous content material. Nevertheless, verifying violations in chat is time-consuming, error-prone, and difficult to scale.
On this put up, we introduce options that allow audio and textual content chat moderation utilizing numerous AWS providers, together with Amazon Transcribe, Amazon Comprehend, Amazon Bedrock, and Amazon OpenSearch Service.
Social platforms search an off-the-shelf moderation resolution that’s easy to provoke, however additionally they require customization for managing various insurance policies. Latency and value are additionally vital components that should be taken into consideration. By orchestrating toxicity classification with massive language fashions (LLMs) utilizing generative AI, we provide an answer that balances simplicity, latency, value, and suppleness to fulfill numerous necessities.
The pattern code for this put up is on the market within the GitHub repository.
Audio chat moderation workflow
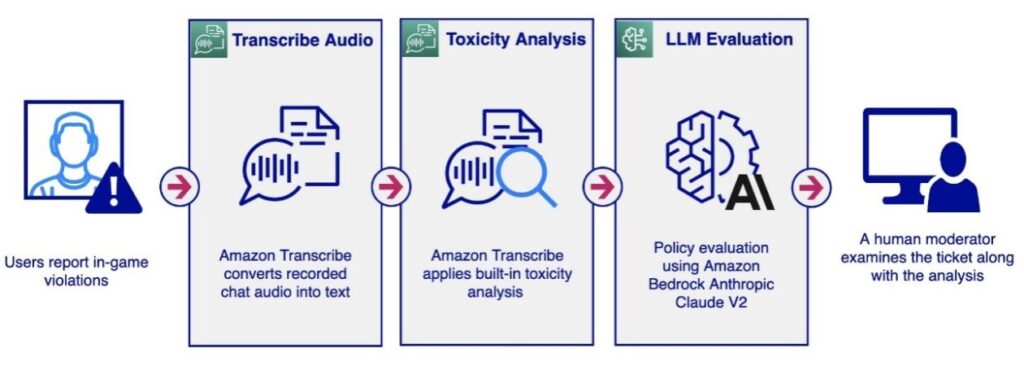
An audio chat moderation workflow could possibly be initiated by a person reporting different customers on a gaming platform for coverage violations similar to profanity, hate speech, or harassment. This represents a passive strategy to audio moderation. The system data all audio conversations with out rapid evaluation. When a report is acquired, the workflow retrieves the associated audio recordsdata and initiates the evaluation course of. A human moderator then opinions the reported dialog, investigating its content material to find out if it violates platform coverage.

Alternatively, the workflow could possibly be triggered proactively. As an example, in a social audio chat room, the system might document all conversations and apply evaluation.

Each passive and proactive approaches can set off the next pipeline for audio evaluation.
The audio moderation workflow includes the next steps:
- The workflow begins with receiving the audio file and storing it on a Amazon Simple Storage Service (Amazon S3) bucket for Amazon Transcribe to entry.
- The Amazon Transcribe
StartTranscriptionJobAPI is invoked with Toxicity Detection enabled. Amazon Transcribe converts the audio into textual content, offering further details about toxicity evaluation. For extra details about toxicity evaluation, check with Flag harmful language in spoken conversations with Amazon Transcribe Toxicity Detection. - If the toxicity evaluation returns a toxicity rating exceeding a sure threshold (for instance, 50%), we are able to use Knowledge Bases for Amazon Bedrock to guage the message towards personalized insurance policies utilizing LLMs.
- The human moderator receives an in depth audio moderation report highlighting the dialog segments thought-about poisonous and in violation of coverage, permitting them to make an knowledgeable determination.
The next screenshot exhibits a pattern software displaying toxicity evaluation for an audio section. It consists of the unique transcription, the outcomes from the Amazon Transcribe toxicity evaluation, and the evaluation carried out utilizing an Amazon Bedrock data base by way of the Amazon Bedrock Anthropic Claude V2 mannequin.
The LLM evaluation offers a violation end result (Y or N) and explains the rationale behind the mannequin’s determination relating to coverage violation. Moreover, the data base consists of the referenced coverage paperwork utilized by the analysis, offering moderators with further context.

Amazon Transcribe Toxicity Detection
Amazon Transcribe is an computerized speech recognition (ASR) service that makes it easy for builders so as to add speech-to-text functionality to their functions. The audio moderation workflow makes use of Amazon Transcribe Toxicity Detection, which is a machine studying (ML)-powered functionality that makes use of audio and text-based cues to determine and classify voice-based poisonous content material throughout seven classes, together with sexual harassment, hate speech, threats, abuse, profanity, insults, and graphic language. Along with analyzing textual content, Toxicity Detection makes use of speech cues similar to tones and pitch to determine poisonous intent in speech.
The audio moderation workflow prompts the LLM’s coverage analysis solely when the toxicity evaluation exceeds a set threshold. This strategy reduces latency and optimizes prices by selectively making use of LLMs, filtering out a good portion of the visitors.
Use LLM immediate engineering to accommodate personalized insurance policies
The pre-trained Toxicity Detection fashions from Amazon Transcribe and Amazon Comprehend present a broad toxicity taxonomy, generally utilized by social platforms for moderating user-generated content material in audio and textual content codecs. Though these pre-trained fashions effectively detect points with low latency, it’s possible you’ll want an answer to detect violations towards your particular firm or enterprise area insurance policies, which the pre-trained fashions alone can’t obtain.
Moreover, detecting violations in contextual conversations, similar to figuring out child sexual grooming conversations, requires a customizable resolution that includes contemplating the chat messages and context outdoors of it, similar to person’s age, gender, and dialog historical past. That is the place LLMs can provide the pliability wanted to increase these necessities.
Amazon Bedrock is a totally managed service that gives a selection of high-performing basis fashions (FMs) from main AI corporations. These options use Anthropic Claude v2 from Amazon Bedrock to average audio transcriptions and textual content chat messages utilizing a versatile immediate template, as outlined within the following code:
The template incorporates placeholders for the coverage description, the chat message, and extra guidelines that requires moderation. The Anthropic Claude V2 mannequin delivers responses within the instructed format (Y or N), together with an evaluation explaining why it thinks the message violates the coverage. This strategy means that you can outline versatile moderation classes and articulate your insurance policies in human language.
The standard methodology of coaching an in-house classification mannequin includes cumbersome processes similar to knowledge annotation, coaching, testing, and mannequin deployment, requiring the experience of knowledge scientists and ML engineers. LLMs, in distinction, provide a excessive diploma of flexibility. Enterprise customers can modify prompts in human language, resulting in enhanced effectivity and lowered iteration cycles in ML mannequin coaching.
Amazon Bedrock data bases
Though immediate engineering is environment friendly for customizing insurance policies, injecting prolonged insurance policies and guidelines instantly into LLM prompts for every message might introduce latency and enhance value. To handle this, we use Amazon Bedrock data bases as a managed Retrieval Augmented Era (RAG) system. This allows you to handle the coverage doc flexibly, permitting the workflow to retrieve solely the related coverage segments for every enter message. This minimizes the variety of tokens despatched to the LLMs for evaluation.
You should use the AWS Management Console to add the coverage paperwork to an S3 bucket after which index the paperwork to a vector database for environment friendly retrieval. The next is a conceptual workflow managed by an Amazon Bedrock data base that retrieves paperwork from Amazon S3, splits the textual content into chunks, and invokes the Amazon Bedrock Titan text embeddings model to transform the textual content chunks into vectors, that are then saved within the vector database.

On this resolution, we use Amazon OpenSearch Service because the vector retailer. OpenSearch is a scalable, versatile, and extensible open supply software program suite for search, analytics, safety monitoring, and observability functions, licensed beneath the Apache 2.0 license. OpenSearch Service is a totally managed service that makes it easy to deploy, scale, and function OpenSearch within the AWS Cloud.
After the doc is listed in OpenSearch Service, the audio and textual content moderation workflow sends chat messages, triggering the next question move for personalized coverage analysis.

The method is just like the initiation workflow. First, the textual content message is transformed to textual content embeddings utilizing the Amazon Bedrock Titan Textual content Embedding API. These embeddings are then used to carry out a vector search towards the OpenSearch Service database, which has already been populated with doc embeddings. The database returns coverage chunks with the best matching rating, related to the enter textual content message. We then compose prompts containing each the enter chat message and the coverage section, that are despatched to Anthropic Claude V2 for analysis. The LLM mannequin returns an evaluation end result based mostly on the immediate directions.
For detailed directions on tips on how to create a brand new occasion along with your coverage doc in an Amazon Bedrock data base, check with Knowledge Bases now delivers fully managed RAG experience in Amazon Bedrock.
Textual content chat moderation workflow
The textual content chat moderation workflow follows an analogous sample to audio moderation, but it surely makes use of Amazon Comprehend toxicity evaluation, which is tailor-made for textual content moderation. The pattern app helps an interface for importing bulk textual content recordsdata in CSV or TXT format and offers a single-message interface for fast testing. The next diagram illustrates the workflow.

The textual content moderation workflow includes the next steps:
- The person uploads a textual content file to an S3 bucket.
- Amazon Comprehend toxicity evaluation is utilized to the textual content message.
- If the toxicity evaluation returns a toxicity rating exceeding a sure threshold (for instance, 50%), we use an Amazon Bedrock data base to guage the message towards personalized insurance policies utilizing the Anthropic Claude V2 LLM.
- A coverage analysis report is shipped to the human moderator.
Amazon Comprehend toxicity evaluation
Within the textual content moderation workflow, we use Amazon Comprehend toxicity evaluation to evaluate the toxicity degree of the textual content messages. Amazon Comprehend is a pure language processing (NLP) service that makes use of ML to uncover priceless insights and connections in textual content. The Amazon Comprehend toxicity detection API assigns an total toxicity rating to textual content content material, starting from 0–1, indicating the chance of it being poisonous. It additionally categorizes textual content into the next classes and offers a confidence rating for every: hate_speech, graphic, harrassement_or_abuse, sexual, violence_or_threat, insult, and profanity.
On this textual content moderation workflow, Amazon Comprehend toxicity evaluation performs an important function in figuring out whether or not the incoming textual content message incorporates poisonous content material. Much like the audio moderation workflow, it features a situation to activate the downstream LLM coverage analysis solely when the toxicity evaluation returns a rating exceeding a predefined threshold. This optimization helps cut back total latency and value related to LLM evaluation.
Abstract
On this put up, we launched options for audio and textual content chat moderation utilizing AWS providers, together with Amazon Transcribe, Amazon Comprehend, Amazon Bedrock, and OpenSearch Service. These options use pre-trained fashions for toxicity evaluation and are orchestrated with generative AI LLMs to attain the optimum steadiness in accuracy, latency, and value. In addition they empower you to flexibly outline your personal insurance policies.
You may expertise the pattern app by following the directions within the GitHub repo.
In regards to the creator
 Lana Zhang is a Senior Options Architect at AWS WWSO AI Companies workforce, specializing in AI and ML for Content material Moderation, Laptop Imaginative and prescient, Pure Language Processing and Generative AI. Together with her experience, she is devoted to selling AWS AI/ML options and aiding prospects in remodeling their enterprise options throughout various industries, together with social media, gaming, e-commerce, media, promoting & advertising.
Lana Zhang is a Senior Options Architect at AWS WWSO AI Companies workforce, specializing in AI and ML for Content material Moderation, Laptop Imaginative and prescient, Pure Language Processing and Generative AI. Together with her experience, she is devoted to selling AWS AI/ML options and aiding prospects in remodeling their enterprise options throughout various industries, together with social media, gaming, e-commerce, media, promoting & advertising.





