Can Machine Studying Fashions Be High quality-Tuned Extra Effectively? This AI Paper from Cohere for AI Reveals How REINFORCE Beats PPO in Reinforcement Studying from Human Suggestions
The alignment of Giant Language Fashions (LLMs) with human preferences has turn into a vital space of analysis. As these fashions acquire complexity and functionality, guaranteeing their actions and outputs align with human values and intentions is paramount. The traditional path to this alignment has concerned refined reinforcement studying methods, with Proximal Coverage Optimization (PPO) main the cost. Whereas efficient, this methodology comes with its personal challenges, together with excessive computational calls for and the necessity for delicate hyperparameter changes. These challenges elevate the query: Is there a extra environment friendly but equally efficient method to obtain the identical purpose?
A analysis staff from Cohere For AI and Cohere carried out an exploration to handle this query, turning their focus to a much less computationally intensive strategy that doesn’t compromise efficiency. They revisited the foundations of reinforcement studying within the context of human suggestions, particularly evaluating the effectivity of REINFORCE-style optimization variants in opposition to the standard PPO and up to date “RL-free” strategies like DPO and RAFT. Their investigation revealed that easier strategies might match and even surpass the efficiency of their extra complicated counterparts in aligning LLMs with human preferences.
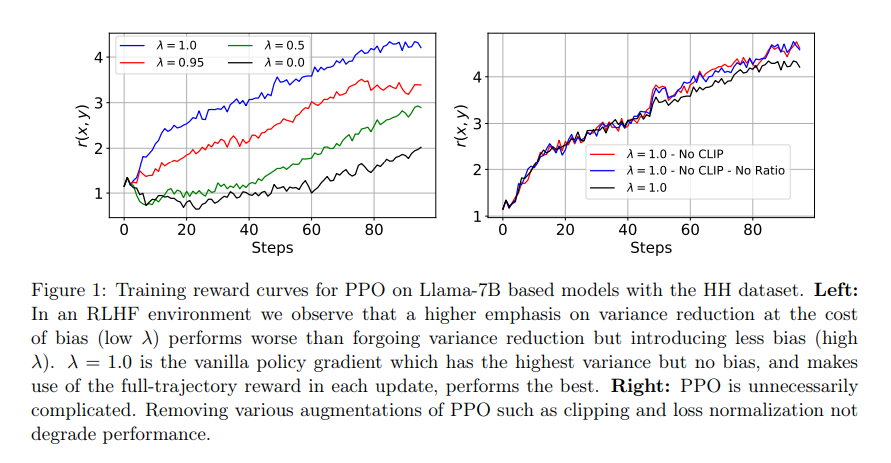
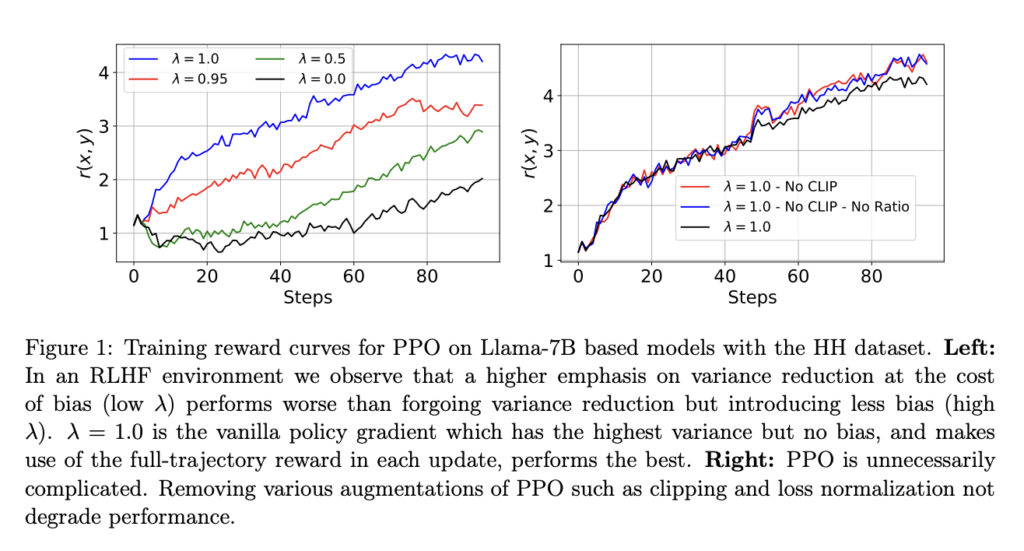
The methodology employed dissected the RL part of RLHF, stripping away the complexities related to PPO to spotlight the efficacy of easier, extra easy approaches. Via their evaluation, they recognized that the core rules driving the event of PPO, principally its deal with minimizing variance and maximizing stability in updates, is probably not as crucial within the context of RLHF as beforehand thought.
Their empirical evaluation, using datasets from Google Vizier, demonstrated a notable efficiency enchancment when using REINFORCE and its multi-sample extension, REINFORCE Depart-One-Out (RLOO), over conventional strategies. Their findings confirmed an over 20% improve in efficiency, marking a major leap ahead within the effectivity and effectiveness of LLM alignment with human preferences.
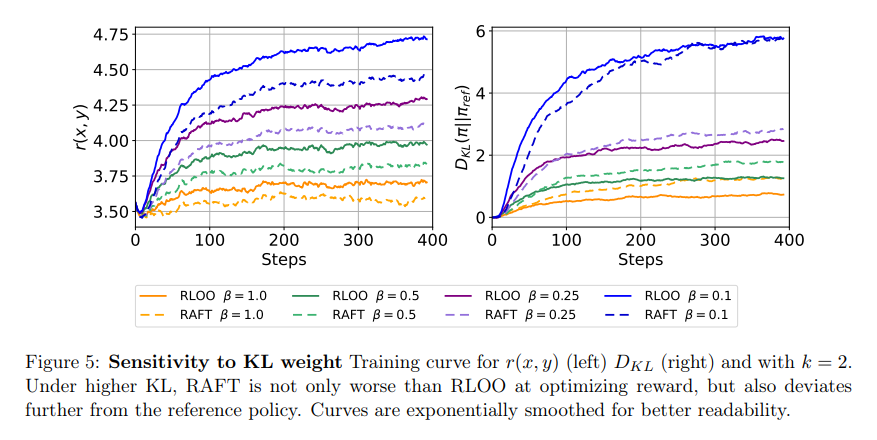
This analysis challenges the prevailing norms concerning the need of complicated reinforcement studying strategies for LLM alignment and opens the door to extra accessible and probably more practical alternate options. The important thing insights from this examine underscore the potential of easier reinforcement studying variants in reaching high-quality LLM alignment at a decrease computational value.
In conclusion, Cohere’s analysis suggests some key insights, together with:
- Simplifying the RL part of RLHF can result in improved alignment of LLMs with human preferences with out sacrificing computational effectivity.
- Conventional, complicated strategies reminiscent of PPO won’t be indispensable in RLHF settings, paving the best way for easier, extra environment friendly alternate options.
- REINFORCE and its multi-sample extension, RLOO, emerge as promising candidates, providing a mix of efficiency and computational effectivity that challenges the established order.
This work marks a pivotal shift within the strategy to LLM alignment, suggesting that simplicity, fairly than complexity, could be the important thing to more practical and environment friendly alignment of synthetic intelligence with human values and preferences.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and Google News. Be part of our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
Should you like our work, you’ll love our newsletter..
Don’t Overlook to hitch our Telegram Channel
Whats up, My identify is Adnan Hassan. I’m a consulting intern at Marktechpost and shortly to be a administration trainee at American Specific. I’m presently pursuing a twin diploma on the Indian Institute of Expertise, Kharagpur. I’m keen about know-how and wish to create new merchandise that make a distinction.