This AI Paper from China Introduces BGE-M3: A New Member to BGE Mannequin Collection with Multi-Linguality (100+ languages)
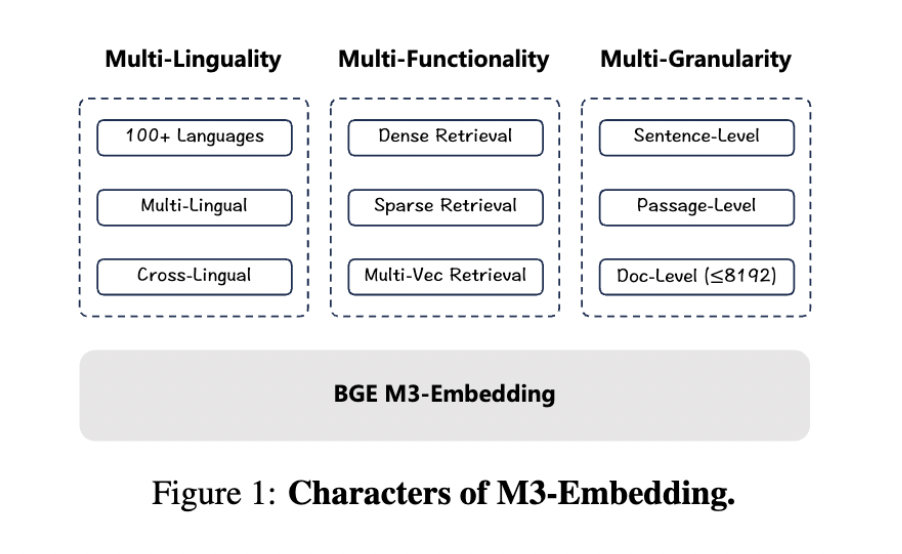
BAAI introduces BGE M3-Embedding with the assistance of researchers from the College of Science and Know-how of China. The M3 refers to 3 novel properties of textual content embedding- Multi-Lingual, Multi-Performance, and Multi-Granularity. It identifies the first challenges within the current embedding fashions, like being unable to assist a number of languages, restrictions in retrieval functionalities, and problem dealing with diversified enter granularities.
Present embedding fashions, resembling Contriever, GTR, E5, and others, have been confirmed to deliver notable progress within the area, however they lack language assist, a number of retrieval performance, or lengthy enter texts. These fashions are primarily skilled just for English and assist just one retrieval performance. The proposed resolution, BGE M3-Embedding, helps over 100 languages, accommodates numerous retrieval functionalities (dense, sparse, and multi-vector retrieval), and processes enter information starting from quick sentences to prolonged doc dealing with as much as 8192 tokens.
M3-Embedding includes a novel self-knowledge distillation strategy, optimizing batching methods for big enter lengths, for which researchers used large-scale, numerous multi-lingual datasets from varied sources like Wikipedia and S2ORC. It facilitates three frequent retrieval functionalities: dense retrieval, lexical retrieval, and multi-vector retrieval. The distillation course of includes combining relevance scores from varied retrieval functionalities to create a instructor sign that permits the mannequin to carry out a number of retrieval duties effectively.
The mannequin is evaluated for its efficiency with multilingual textual content(MLDR), diversified sequence size, and narrative QA responses. The analysis metric was nDCG@10(normalized discounted cumulative acquire). The experiments demonstrated that the M3 embedding mannequin outperformed current fashions in additional than 10 languages, giving at-par leads to English. The mannequin efficiency was just like the opposite fashions with smaller enter lengths however showcased improved outcomes with longer texts.
In conclusion, M3 embedding is a major development in textual content embedding fashions. It’s a versatile resolution that helps a number of languages, diversified retrieval functionalities, and completely different enter granularities. The proposed mannequin addresses essential limitations in current strategies, marking a considerable step ahead in info retrieval. It outperforms baseline strategies like BM25, mDPR, and E5, showcasing its effectiveness in addressing the recognized challenges.
Try the Paper and Github. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and Google News. Be a part of our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
In the event you like our work, you’ll love our newsletter..
Don’t Overlook to affix our Telegram Channel
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is at the moment pursuing her B.Tech from the Indian Institute of Know-how(IIT), Kharagpur. She is a tech fanatic and has a eager curiosity within the scope of software program and information science purposes. She is at all times studying concerning the developments in several area of AI and ML.





