Changing JSONs to Pandas DataFrames: Parsing Them the Proper Approach
Picture by Writer
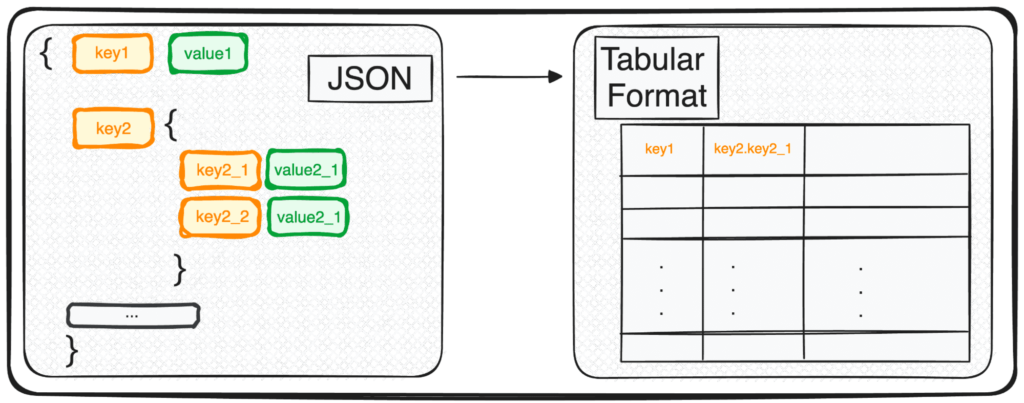
Diving into the world of knowledge science and machine studying, one of many basic expertise you may encounter is the artwork of studying information. In case you have already some expertise with it, you are most likely aware of JSON (JavaScript Object Notation) – a well-liked format for each storing and exchanging information.
Consider how NoSQL databases like MongoDB like to retailer information in JSON, or how REST APIs usually reply in the identical format.
Nonetheless, JSON, whereas excellent for storage and trade, is not fairly prepared for in-depth evaluation in its uncooked type. That is the place we remodel it into one thing extra analytically pleasant – a tabular format.
So, whether or not you are coping with a single JSON object or a pleasant array of them, in Python’s phrases, you are primarily dealing with a dict or an inventory of dicts.
Let’s discover collectively how this transformation unfolds, making our information ripe for evaluation ????
At present I’ll be explaining a magic command that enables us to simply parse any JSON right into a tabular format in seconds.
And it’s… pd.json_normalize()
So let’s see the way it works with various kinds of JSONs.
The primary sort of JSON that we will work with is single-leveled JSONs with a number of keys and values. We outline our first easy JSONs as follows:
Code by Writer
So let’s simulate the necessity to work with these JSON. Everyone knows there’s not a lot to do of their JSON format. We have to remodel these JSONs into some readable and modifiable format… which suggests Pandas DataFrames!
1.1 Coping with easy JSON buildings
First, we have to import the pandas library after which we will use the command pd.json_normalize(), as follows:
import pandas as pd
pd.json_normalize(json_string)
By making use of this command to a JSON with a single report, we acquire probably the most fundamental desk. Nonetheless, when our information is just a little bit extra complicated and presents an inventory of JSONs, we will nonetheless use the identical command with no additional problems and the output will correspond to a desk with a number of information.

Picture by Writer
Simple… proper?
The following pure query is what occurs when a few of the values are lacking.
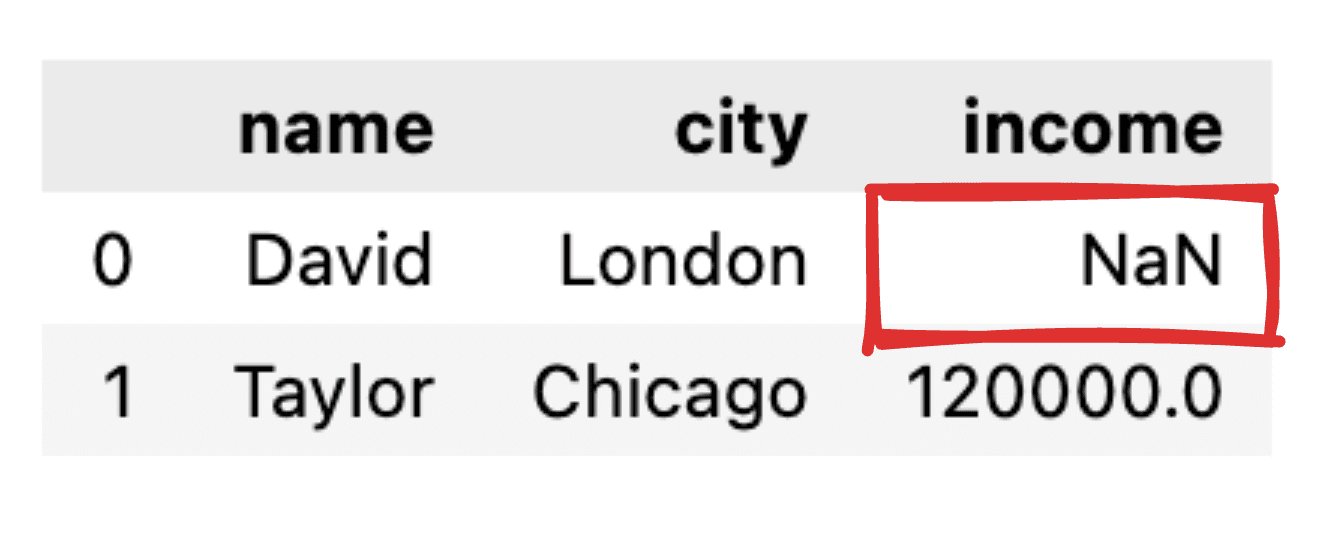
1.2 Coping with null values
Think about a few of the values are usually not knowledgeable, like for example, the Earnings report for David is lacking. When reworking our JSON right into a easy pandas dataframe, the corresponding worth will seem as NaN.
Picture by Writer
And what about if I solely need to get a few of the fields?
1.3 Choosing solely these columns of curiosity
In case we simply need to remodel some particular fields right into a tabular pandas DataFrame, the json_normalize() command doesn’t permit us to decide on what fields to remodel.
Due to this fact, a small preprocessing of the JSON must be carried out the place we filter simply these columns of curiosity.
# Fields to incorporate
fields = ['name', 'city']
# Filter the JSON information
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
So, let’s transfer to some extra superior JSON construction.
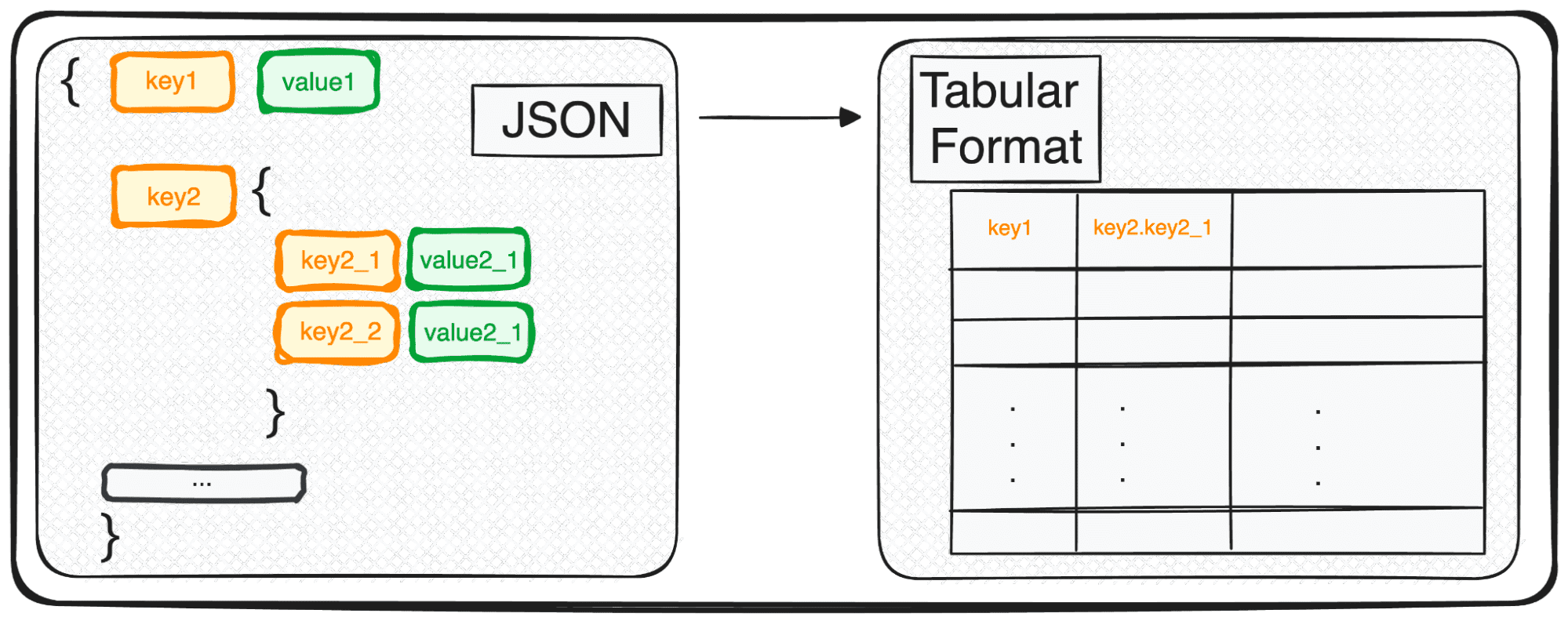
When coping with multiple-leveled JSONs we discover ourselves with nested JSONs inside completely different ranges. The process is identical as earlier than, however on this case, we will select what number of ranges we need to remodel. By default, the command will all the time increase all ranges and generate new columns containing the concatenated title of all of the nested ranges.
So if we normalize the next JSONs.
Code by Writer
We’d get the next desk with 3 columns below the sector expertise:
- expertise.python
- expertise.SQL
- expertise.GCP
and 4 columns below the sector roles
- roles.undertaking supervisor
- roles.information engineer
- roles.information scientist
- roles.information analyst

Picture by Writer
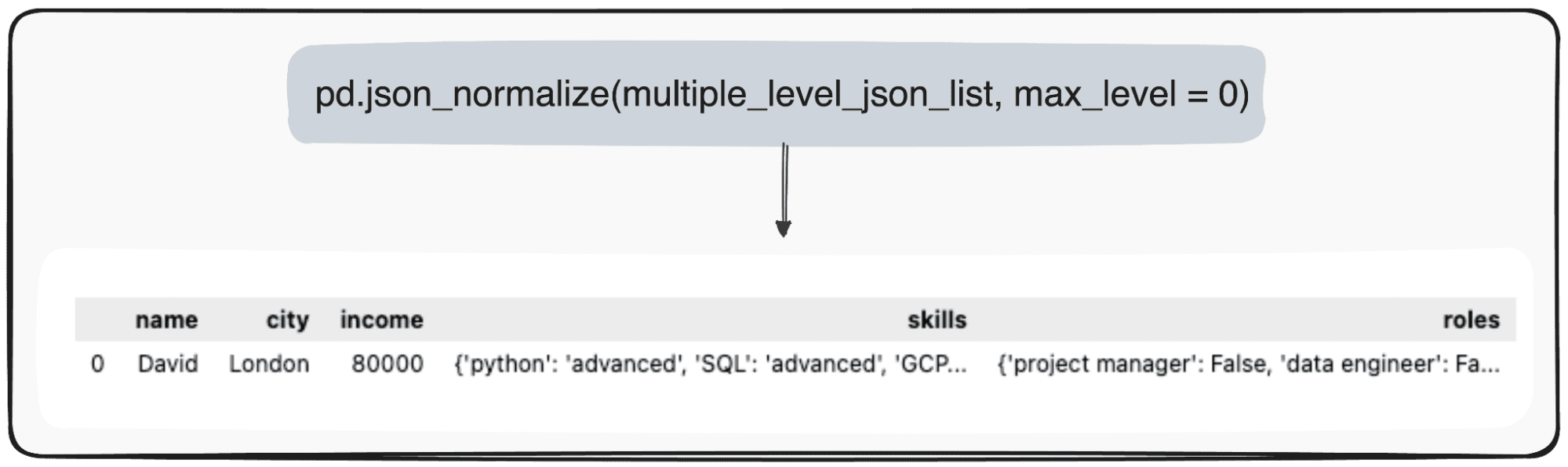
Nonetheless, think about we simply need to remodel our high stage. We are able to accomplish that by particularly defining the parameter max_level to 0 (the max_level we need to increase).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
The pending values will likely be maintained inside JSONs inside our pandas DataFrame.
Picture by Writer
The final case we will discover is having a nested Record inside a JSON area. So we first outline our JSONs to make use of.
Code by Writer
We are able to successfully handle this information utilizing Pandas in Python. The pd.json_normalize() operate is especially helpful on this context. It could flatten the JSON information, together with the nested listing, right into a structured format appropriate for evaluation. When this operate is utilized to our JSON information, it produces a normalized desk that comes with the nested listing as a part of its fields.
Furthermore, Pandas affords the potential to additional refine this course of. By using the record_path parameter in pd.json_normalize(), we will direct the operate to particularly normalize the nested listing.
This motion leads to a devoted desk completely for the listing’s contents. By default, this course of will solely unfold the weather inside the listing. Nonetheless, to complement this desk with extra context, corresponding to retaining an related ID for every report, we will use the meta parameter.

Picture by Writer
In abstract, the transformation of JSON information into CSV information utilizing Python’s Pandas library is straightforward and efficient.
JSON remains to be the commonest format in fashionable information storage and trade, notably in NoSQL databases and REST APIs. Nonetheless, it presents some necessary analytic challenges when coping with information in its uncooked format.
The pivotal function of Pandas’ pd.json_normalize() emerges as a good way to deal with such codecs and convert our information into pandas DataFrame.
I hope this information was helpful, and subsequent time you’re coping with JSON, you are able to do it in a more practical means.
You’ll be able to go examine the corresponding Jupyter Pocket book within the following GitHub repo.
Josep Ferrer is an analytics engineer from Barcelona. He graduated in physics engineering and is presently working within the Information Science area utilized to human mobility. He’s a part-time content material creator targeted on information science and expertise. You’ll be able to contact him on LinkedIn, Twitter or Medium.





