Modernizing information science lifecycle administration with AWS and Wipro
This publish was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Apply.
Many organizations have been utilizing a mixture of on-premises and open supply information science options to create and handle machine studying (ML) fashions.
Information science and DevOps groups could face challenges managing these remoted instrument stacks and techniques. Integrating a number of instrument stacks to construct a compact answer may contain constructing customized connectors or workflows. Managing completely different dependencies primarily based on the present model of every stack and sustaining these dependencies with the discharge of recent updates of every stack complicates the answer. This will increase the price of infrastructure upkeep and hampers productiveness.
Synthetic intelligence (AI) and machine studying (ML) choices from Amazon Web Services (AWS), together with built-in monitoring and notification companies, assist organizations obtain the required stage of automation, scalability, and mannequin high quality at optimum price. AWS additionally helps information science and DevOps groups to collaborate and streamlines the general mannequin lifecycle course of.
The AWS portfolio of ML companies features a strong set of companies that you need to use to speed up the event, coaching, and deployment of machine studying functions. The suite of companies can be utilized to assist the entire mannequin lifecycle together with monitoring and retraining ML fashions.
On this publish, we focus on mannequin improvement and MLOps framework implementation for one in every of Wipro’s clients that makes use of Amazon SageMaker and different AWS companies.
Wipro is an AWS Premier Tier Services Partner and Managed Service Supplier (MSP). Its AI/ML solutions drive enhanced operational effectivity, productiveness, and buyer expertise for a lot of of their enterprise purchasers.
Present challenges
Let’s first perceive a couple of of the challenges the shopper’s information science and DevOps groups confronted with their present setup. We are able to then study how the built-in SageMaker AI/ML choices helped clear up these challenges.
- Collaboration – Information scientists every labored on their very own native Jupyter notebooks to create and practice ML fashions. They lacked an efficient methodology for sharing and collaborating with different information scientists.
- Scalability – Coaching and re-training ML fashions was taking increasingly more time as fashions turned extra advanced whereas the allotted infrastructure capability remained static.
- MLOps – Mannequin monitoring and ongoing governance wasn’t tightly built-in and automatic with the ML fashions. There are dependencies and complexities with integrating third-party instruments into the MLOps pipeline.
- Reusability – With out reusable MLOps frameworks, every mannequin should be developed and ruled individually, which provides to the general effort and delays mannequin operationalization.
This diagram summarizes the challenges and the way Wipro’s implementation on SageMaker addressed them with built-in SageMaker companies and choices.

Determine 1 – SageMaker choices for ML workload migration
Wipro outlined an structure that addresses the challenges in a cost-optimized and absolutely automated means.
The next is the use case and mannequin used to construct the answer:
- Use case: Value prediction primarily based on the used automotive dataset
- Drawback kind: Regression
- Fashions used: XGBoost and Linear Learner (SageMaker built-in algorithms)
Answer structure
Wipro consultants carried out a deep-dive discovery workshop with the shopper’s information science, DevOps, and information engineering groups to know the present setting in addition to their necessities and expectations for a contemporary answer on AWS. By the top of the consulting engagement, the staff had carried out the next structure that successfully addressed the core necessities of the shopper staff, together with:
Code Sharing – SageMaker notebooks allow information scientists to experiment and share code with different staff members. Wipro additional accelerated their ML mannequin journey by implementing Wipro’s code accelerators and snippets to expedite characteristic engineering, mannequin coaching, mannequin deployment, and pipeline creation.
Steady integration and steady supply (CI/CD) pipeline – Utilizing the shopper’s GitHub repository enabled code versioning and automatic scripts to launch pipeline deployment each time new variations of the code are dedicated.
MLOps – The structure implements a SageMaker mannequin monitoring pipeline for steady mannequin high quality governance by validating information and mannequin drift as required by the outlined schedule. At any time when drift is detected, an occasion is launched to inform the respective groups to take motion or provoke mannequin retraining.
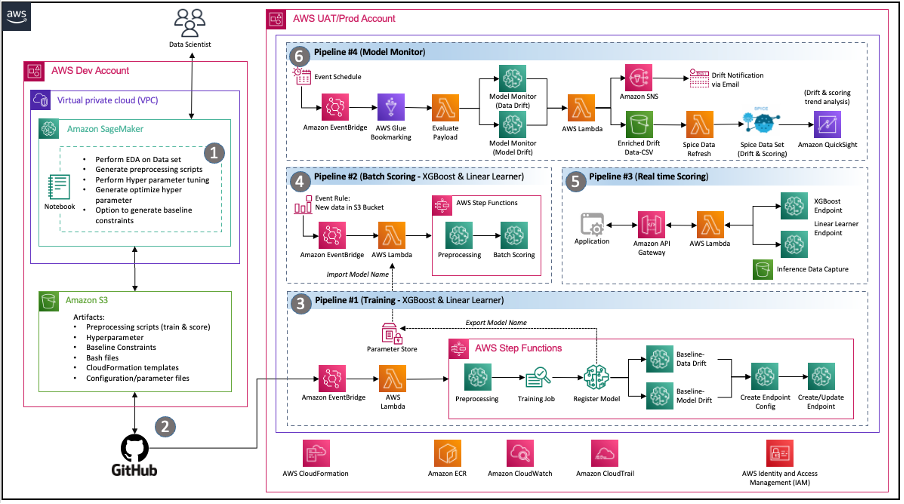
Occasion-driven structure – The pipelines for mannequin coaching, mannequin deployment, and mannequin monitoring are nicely built-in by use Amazon EventBridge, a serverless occasion bus. When outlined occasions happen, EventBridge can invoke a pipeline to run in response. This supplies a loosely-coupled set of pipelines that may run as wanted in response to the setting.

Determine 2 – Occasion Pushed MLOps structure with SageMaker
Answer elements
This part describes the varied answer elements of the structure.
Experiment notebooks
- Goal: The client’s information science staff wished to experiment with varied datasets and a number of fashions to provide you with the optimum options, utilizing these as additional inputs to the automated pipeline.
- Answer: Wipro created SageMaker experiment notebooks with code snippets for every reusable step, equivalent to studying and writing information, mannequin characteristic engineering, mannequin coaching, and hyperparameter tuning. Function engineering duties may also be ready in Information Wrangler, however the consumer particularly requested for SageMaker processing jobs and AWS Step Functions as a result of they have been extra snug utilizing these applied sciences. We used the AWS step operate information science SDK to create a step operate—for circulate testing—instantly from the pocket book occasion to allow well-defined inputs for the pipelines. This has helped the info scientist staff to create and check pipelines at a a lot sooner tempo.
Automated coaching pipeline
- Goal: To allow an automatic coaching and re-training pipeline with configurable parameters equivalent to occasion kind, hyperparameters, and an Amazon Simple Storage Service (Amazon S3) bucket location. The pipeline also needs to be launched by the info push occasion to S3.
- Answer: Wipro carried out a reusable coaching pipeline utilizing the Step Capabilities SDK, SageMaker processing, coaching jobs, a SageMaker mannequin monitor container for baseline era, AWS Lambda, and EventBridge companies.Utilizing AWS event-driven structure, the pipeline is configured to launch mechanically primarily based on a brand new information occasion being pushed to the mapped S3 bucket. Notifications are configured to be despatched to the outlined electronic mail addresses. At a excessive stage, the coaching circulate appears like the next diagram:

Determine 3 – Coaching pipeline step machine.
Stream description for the automated coaching pipeline
The above diagram is an automatic coaching pipeline constructed utilizing Step Capabilities, Lambda, and SageMaker. It’s a reusable pipeline for organising automated mannequin coaching, producing predictions, making a baseline for mannequin monitoring and information monitoring, and creating and updating an endpoint primarily based on earlier mannequin threshold worth.
- Pre-processing: This step takes information from an Amazon S3 location as enter and makes use of the SageMaker SKLearn container to carry out vital characteristic engineering and information pre-processing duties, such because the practice, check, and validate break up.
- Mannequin coaching: Utilizing the SageMaker SDK, this step runs coaching code with the respective mannequin picture and trains datasets from pre-processing scripts whereas producing the educated mannequin artifacts.
- Save mannequin: This step creates a mannequin from the educated mannequin artifacts. The mannequin title is saved for reference in one other pipeline utilizing the AWS Systems Manager Parameter Store.
- Question coaching outcomes: This step calls the Lambda operate to fetch the metrics of the finished coaching job from the sooner mannequin coaching step.
- RMSE threshold: This step verifies the educated mannequin metric (RMSE) in opposition to an outlined threshold to resolve whether or not to proceed in direction of endpoint deployment or reject this mannequin.
- Mannequin accuracy too low: At this step the mannequin accuracy is checked in opposition to the earlier finest mannequin. If the mannequin fails at metric validation, the notification is shipped by a Lambda operate to the goal subject registered in Amazon Simple Notification Service (Amazon SNS). If this examine fails, the circulate exits as a result of the brand new educated mannequin didn’t meet the outlined threshold.
- Baseline job information drift: If the educated mannequin passes the validation steps, baseline stats are generated for this educated mannequin model to allow monitoring and the parallel department steps are run to generate the baseline for the mannequin high quality examine.
- Create mannequin endpoint configuration: This step creates endpoint configuration for the evaluated mannequin within the earlier step with an allow information seize configuration.
- Verify endpoint: This step checks if the endpoint exists or must be created. Primarily based on the output, the subsequent step is to create or replace the endpoint.
- Export configuration: This step exports the parameter’s mannequin title, endpoint title, and endpoint configuration to the AWS Systems Manager Parameter Retailer.
Alerts and notifications are configured to be despatched to the configured SNS subject electronic mail on the failure or success of state machine standing change. The identical pipeline configuration is reused for the XGBoost mannequin.
Automated batch scoring pipeline
- Goal: Launch batch scoring as quickly as scoring enter batch information is obtainable within the respective Amazon S3 location. The batch scoring ought to use the newest registered mannequin to do the scoring.
- Answer: Wipro carried out a reusable scoring pipeline utilizing the Step Capabilities SDK, SageMaker batch transformation jobs, Lambda, and EventBridge. The pipeline is auto triggered primarily based on the brand new scoring batch information availability to the respective S3 location.

Determine 4 – Scoring pipeline step machine for linear learner and XGBoost mannequin
Stream description for the automated batch scoring pipeline:
- Pre-processing: The enter for this step is an information file from the respective S3 location, and does the required pre-processing earlier than calling SageMaker batch transformation job.
- Scoring: This step runs the batch transformation job to generate inferences, calling the newest model of the registered mannequin and storing the scoring output in an S3 bucket. Wipro has used the enter filter and be part of performance of SageMaker batch transformation API. It helped enrich the scoring information for higher determination making.

Determine 5 – Enter filter and be part of circulate for batch transformation
- On this step, the state machine pipeline is launched by a brand new information file within the S3 bucket.
The notification is configured to be despatched to the configured SNS subject electronic mail on the failure/success of the state machine standing change.
Actual-time inference pipeline
- Goal: To allow real-time inferences from each the fashions’ (Linear Learner and XGBoost) endpoints and get the utmost predicted worth (or through the use of some other customized logic that may be written as a Lambda operate) to be returned to the applying.
- Answer: The Wipro staff has carried out reusable structure utilizing Amazon API Gateway, Lambda, and SageMaker endpoint as proven in Determine 6:

Determine 6 – Actual-time inference pipeline
Stream description for the real-time inference pipeline proven in Determine 6:
- The payload is shipped from the applying to Amazon API Gateway, which routes it to the respective Lambda operate.
- A Lambda operate (with an built-in SageMaker customized layer) does the required pre-processing, JSON or CSV payload formatting, and invokes the respective endpoints.
- The response is returned to Lambda and despatched again to the applying by API Gateway.
The client used this pipeline for small and medium scale fashions, which included utilizing varied kinds of open-source algorithms. One of many key advantages of SageMaker is that varied kinds of algorithms will be introduced into SageMaker and deployed utilizing a convey your personal container (BYOC) approach. BYOC entails containerizing the algorithm and registering the picture in Amazon Elastic Container Registry (Amazon ECR), after which utilizing the identical picture to create a container to do coaching and inference.
Scaling is among the greatest points within the machine studying cycle. SageMaker comes with the mandatory instruments for scaling a mannequin throughout inference. Within the previous structure, customers have to allow auto-scaling of SageMaker, which ultimately handles the workload. To allow auto-scaling, customers should present an auto-scaling coverage that asks for the throughput per occasion and most and minimal situations. Throughout the coverage in place, SageMaker mechanically handles the workload for real-time endpoints and switches between situations when wanted.
Customized mannequin monitor pipeline
- Goal: The client staff wished to have automated mannequin monitoring to seize each information drift and mannequin drift. The Wipro staff used SageMaker mannequin monitoring to allow each information drift and mannequin drift with a reusable pipeline for real-time inferences and batch transformation.Observe that in the course of the improvement of this answer, the SageMaker mannequin monitoring didn’t present provision for detecting information or mannequin drift for batch transformation. We’ve carried out customizations to make use of the mannequin monitor container for the batch transformations payload.
- Answer: The Wipro staff carried out a reusable model-monitoring pipeline for real-time and batch inference payloads utilizing AWS Glue to seize the incremental payload and invoke the mannequin monitoring job in accordance with the outlined schedule.

Determine 7 – Mannequin monitor step machine
Stream description for the customized mannequin monitor pipeline:
The pipeline runs in accordance with the outlined schedule configured by EventBridge.
- CSV consolidation – It makes use of the AWS Glue bookmark characteristic to detect the presence of incremental payload within the outlined S3 bucket of real-time information seize and response and batch information response. It then aggregates that information for additional processing.
- Consider payload – If there’s incremental information or payload current for the present run, it invokes the monitoring department. In any other case, it bypasses with out processing and exits the job.
- Submit processing – The monitoring department is designed to have two parallel sub branches—one for information drift and one other for mannequin drift.
- Monitoring (information drift) – The info drift department runs each time there’s a payload current. It makes use of the newest educated mannequin baseline constraints and statistics recordsdata generated by the coaching pipeline for the info options and runs the mannequin monitoring job.
- Monitoring (mannequin drift) – The mannequin drift department runs solely when floor reality information is provided, together with the inference payload. It makes use of educated mannequin baseline constraints and statistics recordsdata generated by the coaching pipeline for the mannequin high quality options and runs the mannequin monitoring job.
- Consider drift – The end result of each information and mannequin drift is a constraint violation file that’s evaluated by the consider drift Lambda operate which sends notification to the respective Amazon SNS subjects with particulars of the drift. Drift information is enriched additional with the addition of attributes for reporting functions. The drift notification emails will look much like the examples in Determine 8.

Determine 8 – Information and mannequin drift notification message

Determine 9 – Information and mannequin drift notification message
Insights with Amazon QuickSight visualization:
- Goal: The client wished to have insights in regards to the information and mannequin drift, relate the drift information to the respective mannequin monitoring jobs, and discover out the inference information tendencies to know the character of the interference information tendencies.
- Answer: The Wipro staff enriched the drift information by connecting enter information with the drift consequence, which allows triage from drift to monitoring and respective scoring information. Visualizations and dashboards have been created utilizing Amazon QuickSight with Amazon Athena as the info supply (utilizing the Amazon S3 CSV scoring and drift information).

Determine 10 – Mannequin monitoring visualization structure
Design concerns:
- Use the QuickSight spice dataset for higher in-memory efficiency.
- Use QuickSight refresh dataset APIs to automate the spice information refresh.
- Implement group-based safety for dashboard and evaluation entry management.
- Throughout accounts, automate deployment utilizing export and import dataset, information supply, and evaluation API calls supplied by QuickSight.
Mannequin monitoring dashboard:
To allow an efficient final result and significant insights of the mannequin monitoring jobs, customized dashboards have been created for the mannequin monitoring information. The enter information factors are mixed in parallel with inference request information, jobs information, and monitoring output to create a visualization of tendencies revealed by the mannequin monitoring.
This has actually helped the shopper staff to visualise the features of assorted information options together with the anticipated final result of every batch of inference requests.

Determine 11 – Mannequin monitor dashboard with choice prompts

Determine 12 – Mannequin monitor drift evaluation
Conclusion
The implementation defined on this publish enabled Wipro to successfully migrate their on-premises fashions to AWS and construct a scalable, automated mannequin improvement framework.
The usage of reusable framework elements empowers the info science staff to successfully package deal their work as deployable AWS Step Capabilities JSON elements. Concurrently, the DevOps groups used and enhanced the automated CI/CD pipeline to facilitate the seamless promotion and retraining of fashions in greater environments.
Mannequin monitoring element has enabled steady monitoring of the mannequin efficiency, and customers obtain alerts and notifications each time information or mannequin drift is detected.
The client’s staff is utilizing this MLOps framework emigrate or develop extra fashions and improve their SageMaker adoption.
By harnessing the excellent suite of SageMaker companies along with our meticulously designed structure, clients can seamlessly onboard a number of fashions, considerably lowering deployment time and mitigating complexities related to code sharing. Furthermore, our structure simplifies code versioning upkeep, guaranteeing a streamlined improvement course of.
This structure handles the complete machine studying cycle, encompassing automated mannequin coaching, real-time and batch inference, proactive mannequin monitoring, and drift evaluation. This end-to-end answer empowers clients to attain optimum mannequin efficiency whereas sustaining rigorous monitoring and evaluation capabilities to make sure ongoing accuracy and reliability.
To create this structure, start by creating important sources like Amazon Virtual Private Cloud (Amazon VPC), SageMaker notebooks, and Lambda features. Be certain that to arrange acceptable AWS Identity and Access Management (IAM) insurance policies for these sources.
Subsequent, give attention to constructing the elements of the structure—equivalent to coaching and preprocessing scripts—inside SageMaker Studio or Jupyter Pocket book. This step entails creating the mandatory code and configurations to allow the specified functionalities.
After the structure’s elements are outlined, you may proceed with constructing the Lambda features for producing inferences or performing post-processing steps on the info.
On the finish, use Step Capabilities to attach the elements and set up a easy workflow that coordinates the working of every step.
In regards to the Authors
 Stephen Randolph is a Senior Companion Options Architect at Amazon Net Providers (AWS). He allows and helps World Methods Integrator (GSI) companions on the newest AWS expertise as they develop business options to resolve enterprise challenges. Stephen is particularly enthusiastic about Safety and Generative AI, and serving to clients and companions architect safe, environment friendly, and progressive options on AWS.
Stephen Randolph is a Senior Companion Options Architect at Amazon Net Providers (AWS). He allows and helps World Methods Integrator (GSI) companions on the newest AWS expertise as they develop business options to resolve enterprise challenges. Stephen is particularly enthusiastic about Safety and Generative AI, and serving to clients and companions architect safe, environment friendly, and progressive options on AWS.
 Bhajandeep Singh has served because the AWS AI/ML Heart of Excellence Head at Wipro Applied sciences, main buyer engagements to ship information analytics and AI options. He holds the AWS AI/ML Specialty certification and authors technical blogs on AI/ML companies and options. With expertise of main AWS AI/ML options throughout industries, Bhajandeep has enabled purchasers to maximise the worth of AWS AI/ML companies by his experience and management.
Bhajandeep Singh has served because the AWS AI/ML Heart of Excellence Head at Wipro Applied sciences, main buyer engagements to ship information analytics and AI options. He holds the AWS AI/ML Specialty certification and authors technical blogs on AI/ML companies and options. With expertise of main AWS AI/ML options throughout industries, Bhajandeep has enabled purchasers to maximise the worth of AWS AI/ML companies by his experience and management.
 Ajay Vishwakarma is an ML engineer for the AWS wing of Wipro’s AI answer follow. He has good expertise in constructing BYOM answer for customized algorithm in SageMaker, finish to finish ETL pipeline deployment, constructing chatbots utilizing Lex, Cross account QuickSight useful resource sharing and constructing CloudFormation templates for deployments. He likes exploring AWS taking each clients downside as a problem to discover extra and supply options to them.
Ajay Vishwakarma is an ML engineer for the AWS wing of Wipro’s AI answer follow. He has good expertise in constructing BYOM answer for customized algorithm in SageMaker, finish to finish ETL pipeline deployment, constructing chatbots utilizing Lex, Cross account QuickSight useful resource sharing and constructing CloudFormation templates for deployments. He likes exploring AWS taking each clients downside as a problem to discover extra and supply options to them.





