Allow absolutely homomorphic encryption with Amazon SageMaker endpoints for safe, real-time inferencing

That is joint publish co-written by Leidos and AWS. Leidos is a FORTUNE 500 science and know-how options chief working to handle a few of the world’s hardest challenges within the protection, intelligence, homeland safety, civil, and healthcare markets.
Leidos has partnered with AWS to develop an strategy to privacy-preserving, confidential machine studying (ML) modeling the place you construct cloud-enabled, encrypted pipelines.
Homomorphic encryption is a brand new strategy to encryption that enables computations and analytical features to be run on encrypted information, with out first having to decrypt it, with a view to protect privateness in circumstances the place you have got a coverage that states information ought to by no means be decrypted. Totally homomorphic encryption (FHE) is the strongest notion of one of these strategy, and it means that you can unlock the worth of your information the place zero-trust is essential. The core requirement is that the information wants to have the ability to be represented with numbers by an encoding approach, which may be utilized to numerical, textual, and image-based datasets. Knowledge utilizing FHE is bigger in dimension, so testing have to be performed for functions that want the inference to be carried out in near-real time or with dimension limitations. It’s additionally necessary to phrase all computations as linear equations.
On this publish, we present learn how to activate privacy-preserving ML predictions for probably the most extremely regulated environments. The predictions (inference) use encrypted information and the outcomes are solely decrypted by the top shopper (consumer aspect).
To show this, we present an instance of customizing an Amazon SageMaker Scikit-learn, open sourced, deep learning container to allow a deployed endpoint to just accept client-side encrypted inference requests. Though this instance reveals learn how to carry out this for inference operations, you’ll be able to prolong the answer to coaching and different ML steps.
Endpoints are deployed with a pair clicks or strains of code utilizing SageMaker, which simplifies the method for builders and ML consultants to construct and prepare ML and deep studying fashions within the cloud. Fashions constructed utilizing SageMaker can then be deployed as real-time endpoints, which is vital for inference workloads the place you have got actual time, regular state, low latency necessities. Functions and companies can name the deployed endpoint instantly or by a deployed serverless Amazon API Gateway structure. To be taught extra about real-time endpoint architectural greatest practices, seek advice from Creating a machine learning-powered REST API with Amazon API Gateway mapping templates and Amazon SageMaker. The next determine reveals each variations of those patterns.
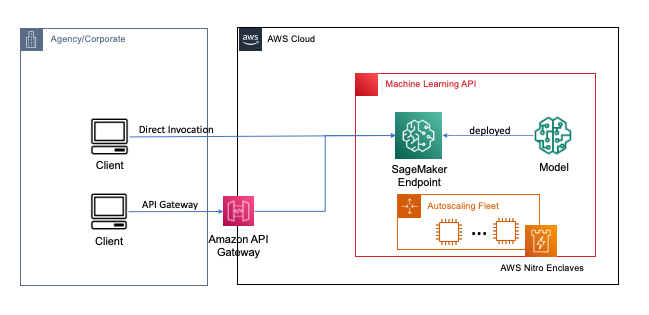
In each of those patterns, encryption in transit gives confidentiality as the information flows by the companies to carry out the inference operation. When obtained by the SageMaker endpoint, the information is mostly decrypted to carry out the inference operation at runtime, and is inaccessible to any exterior code and processes. To attain extra ranges of safety, FHE allows the inference operation to generate encrypted outcomes for which the outcomes may be decrypted by a trusted utility or consumer.
Extra on absolutely homomorphic encryption
FHE allows techniques to carry out computations on encrypted information. The ensuing computations, when decrypted, are controllably near these produced with out the encryption course of. FHE may end up in a small mathematical imprecision, much like a floating level error, as a consequence of noise injected into the computation. It’s managed by deciding on acceptable FHE encryption parameters, which is a problem-specific, tuned parameter. For extra data, try the video How would you explain homomorphic encryption?
The next diagram gives an instance implementation of an FHE system.
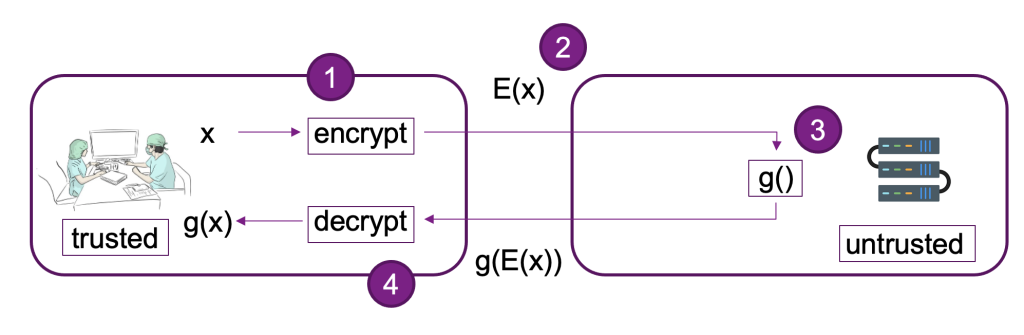
On this system, you or your trusted consumer can do the next:
- Encrypt the information utilizing a public key FHE scheme. There are a few totally different acceptable schemes; on this instance, we’re utilizing the CKKS scheme. To be taught extra concerning the FHE public key encryption course of we selected, seek advice from CKKS explained.
- Ship client-side encrypted information to a supplier or server for processing.
- Carry out mannequin inference on encrypted information; with FHE, no decryption is required.
- Encrypted outcomes are returned to the caller after which decrypted to disclose your consequence utilizing a personal key that’s solely out there to you or your trusted customers inside the consumer.
We’ve used the previous structure to arrange an instance utilizing SageMaker endpoints, Pyfhel as an FHE API wrapper simplifying the mixing with ML functions, and SEAL as our underlying FHE encryption toolkit.
Answer overview
We’ve constructed out an instance of a scalable FHE pipeline in AWS utilizing an SKLearn logistic regression deep studying container with the Iris dataset. We carry out information exploration and have engineering utilizing a SageMaker pocket book, after which carry out mannequin coaching utilizing a SageMaker training job. The ensuing mannequin is deployed to a SageMaker real-time endpoint to be used by consumer companies, as proven within the following diagram.
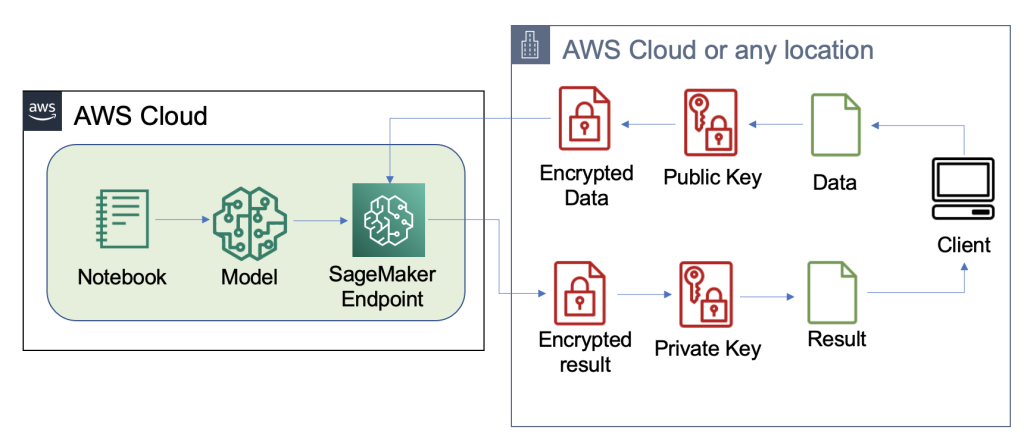
On this structure, solely the consumer utility sees unencrypted information. The info processed by the mannequin for inferencing stays encrypted all through its lifecycle, even at runtime inside the processor within the remoted AWS Nitro Enclave. Within the following sections, we stroll by the code to construct this pipeline.
Stipulations
To observe alongside, we assume you have got launched a SageMaker notebook with an AWS Identity and Access Management (IAM) function with the AmazonSageMakerFullAccess managed coverage.
Practice the mannequin
The next diagram illustrates the mannequin coaching workflow.
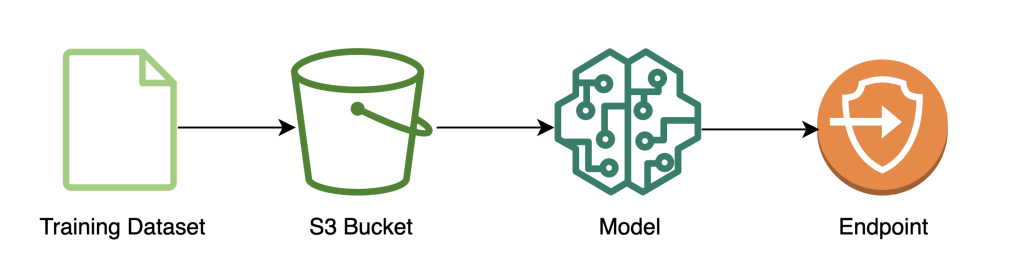
The next code reveals how we first put together the information for coaching utilizing SageMaker notebooks by pulling in our coaching dataset, performing the required cleansing operations, after which importing the information to an Amazon Simple Storage Service (Amazon S3) bucket. At this stage, you may additionally must do extra function engineering of your dataset or combine with totally different offline function shops.
On this instance, we’re utilizing script-mode on a natively supported framework inside SageMaker (scikit-learn), the place we instantiate our default SageMaker SKLearn estimator with a customized coaching script to deal with the encrypted information throughout inference. To see extra details about natively supported frameworks and script mode, seek advice from Use Machine Learning Frameworks, Python, and R with Amazon SageMaker.
Lastly, we prepare our mannequin on the dataset and deploy our skilled mannequin to the occasion sort of our alternative.
At this level, we’ve skilled a customized SKLearn FHE mannequin and deployed it to a SageMaker real-time inference endpoint that’s prepared settle for encrypted information.
Encrypt and ship consumer information
The next diagram illustrates the workflow of encrypting and sending consumer information to the mannequin.
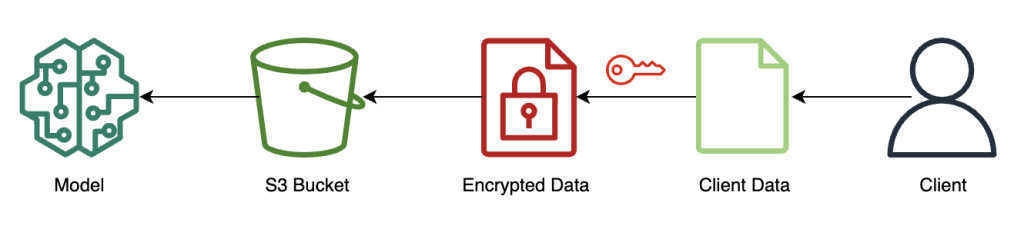
Normally, the payload of the decision to the inference endpoint accommodates the encrypted information moderately than storing it in Amazon S3 first. We do that on this instance as a result of we’ve batched numerous information to the inference name collectively. In apply, this batch dimension might be smaller or batch remodel might be used as an alternative. Utilizing Amazon S3 as an middleman isn’t required for FHE.
Now that the inference endpoint has been arrange, we are able to begin sending information over. We usually use totally different take a look at and coaching datasets, however for this instance we use the identical coaching dataset.
First, we load the Iris dataset on the consumer aspect. Subsequent, we arrange the FHE context utilizing Pyfhel. We chosen Pyfhel for this course of as a result of it’s easy to put in and work with, consists of fashionable FHE schemas, and depends upon trusted underlying open-sourced encryption implementation SEAL. On this instance, we ship the encrypted information, together with public keys data for this FHE scheme, to the server, which allows the endpoint to encrypt the consequence to ship on its aspect with the required FHE parameters, however doesn’t give it the power to decrypt the incoming information. The personal key stays solely with the consumer, which has the power to decrypt the outcomes.
After we encrypt our information, we put collectively an entire information dictionary—together with the related keys and encrypted information—to be saved on Amazon S3. Aferwards, the mannequin makes its predictions over the encrypted information from the consumer, as proven within the following code. Discover we don’t transmit the personal key, so the mannequin host isn’t capable of decrypt the information. On this instance, we’re passing the information by as an S3 object; alternatively, that information could also be despatched on to the Sagemaker endpoint. As a real-time endpoint, the payload accommodates the information parameter within the physique of the request, which is talked about within the SageMaker documentation.
The next screenshot reveals the central prediction inside fhe_train.py (the appendix reveals your complete coaching script).
We’re computing the outcomes of our encrypted logistic regression. This code computes an encrypted scalar product for every potential class and returns the outcomes to the consumer. The outcomes are the anticipated logits for every class throughout all examples.
Consumer returns decrypted outcomes
The next diagram illustrates the workflow of the consumer retrieving their encrypted consequence and decrypting it (with the personal key that solely they’ve entry to) to disclose the inference consequence.
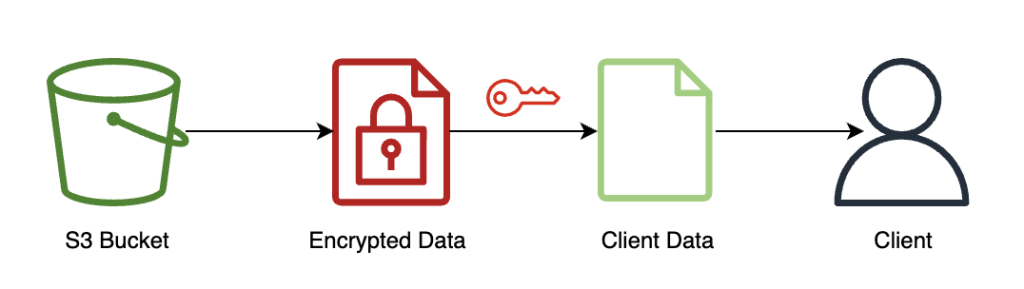
On this instance, outcomes are saved on Amazon S3, however usually this could be returned by the payload of the real-time endpoint. Utilizing Amazon S3 as an middleman isn’t required for FHE.
The inference consequence might be controllably near the outcomes as if that they had computed it themselves, with out utilizing FHE.
Clear up
We finish this course of by deleting the endpoint we created, to ensure there isn’t any unused compute after this course of.
Outcomes and concerns
One of many widespread drawbacks of utilizing FHE on high of fashions is that it provides computational overhead, which—in apply—makes the ensuing mannequin too gradual for interactive use circumstances. However, in circumstances the place the information is extremely delicate, it is perhaps worthwhile to just accept this latency trade-off. Nevertheless, for our easy logistic regression, we’re capable of course of 140 enter information samples inside 60 seconds and see linear efficiency. The next chart consists of the full end-to-end time, together with the time carried out by the consumer to encrypt the enter and decypt the outcomes. It additionally makes use of Amazon S3, which provides latency and isn’t required for these circumstances.
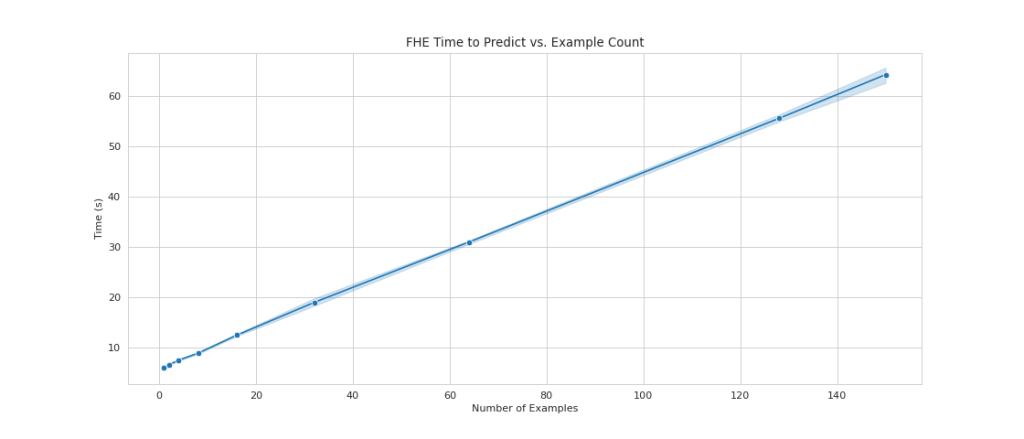
We see linear scaling as we improve the variety of examples from 1 to 150. That is anticipated as a result of every instance is encrypted independently from one another, so we count on a linear improve in computation, with a hard and fast setup value.
This additionally means you could scale your inference fleet horizontally for better request throughput behind your SageMaker endpoint. You should utilize Amazon SageMaker Inference Recommender to value optimize your fleet relying on what you are promoting wants.
Conclusion
And there you have got it: absolutely homomorphic encryption ML for a SKLearn logistic regression mannequin you could arrange with a couple of strains of code. With some customization, you’ll be able to implement this identical encryption course of for various mannequin sorts and frameworks, impartial of the coaching information.
For those who’d wish to be taught extra about constructing an ML answer that makes use of homomorphic encryption, attain out to your AWS account group or associate, Leidos, to be taught extra. You too can seek advice from the next sources for extra examples:
The content material and opinions on this publish accommodates these from third-party authors and AWS isn’t answerable for the content material or accuracy of this publish.
Appendix
The total coaching script is as follows:
In regards to the Authors
Liv d’Aliberti is a researcher inside the Leidos AI/ML Accelerator underneath the Workplace of Expertise. Their analysis focuses on privacy-preserving machine studying.
Manbir Gulati is a researcher inside the Leidos AI/ML Accelerator underneath the Workplace of Expertise. His analysis focuses on the intersection of cybersecurity and rising AI threats.
Joe Kovba is a Cloud Heart of Excellence Follow Lead inside the Leidos Digital Modernization Accelerator underneath the Workplace of Expertise. In his free time, he enjoys refereeing soccer video games and taking part in softball.
Ben Snively is a Public Sector Specialist Options Architect. He works with authorities, non-profit, and schooling clients on large information and analytical tasks, serving to them construct options utilizing AWS. In his spare time, he provides IoT sensors all through his home and runs analytics on them.
Sami Hoda is a Senior Options Architect within the Companions Consulting division protecting the Worldwide Public Sector. Sami is captivated with tasks the place equal elements design pondering, innovation, and emotional intelligence can be utilized to unravel issues for and impression individuals in want.





