Streamlining ETL information processing at Expertise.com with Amazon SageMaker
This submit is co-authored by Anatoly Khomenko, Machine Studying Engineer, and Abdenour Bezzouh, Chief Expertise Officer at Expertise.com.
Established in 2011, Talent.com aggregates paid job listings from their purchasers and public job listings, and has created a unified, simply searchable platform. Masking over 30 million job listings throughout greater than 75 nations and spanning numerous languages, industries, and distribution channels, Expertise.com caters to the varied wants of job seekers, successfully connecting tens of millions of job seekers with job alternatives.
Expertise.com’s mission is to facilitate international workforce connections. To realize this, Expertise.com aggregates job listings from numerous sources on the internet, providing job seekers entry to an intensive pool of over 30 million job alternatives tailor-made to their expertise and experiences. In keeping with this mission, Expertise.com collaborated with AWS to develop a cutting-edge job advice engine pushed by deep studying, aimed toward helping customers in advancing their careers.
To make sure the efficient operation of this job advice engine, it’s essential to implement a large-scale information processing pipeline liable for extracting and refining options from Expertise.com’s aggregated job listings. This pipeline is ready to course of 5 million day by day information in lower than 1 hour, and permits for processing a number of days of information in parallel. As well as, this answer permits for a fast deployment to manufacturing. The first supply of knowledge for this pipeline is the JSON Strains format, saved in Amazon Simple Storage Service (Amazon S3) and partitioned by date. Every day, this leads to the era of tens of 1000’s of JSON Strains recordsdata, with incremental updates occurring day by day.
The first goal of this information processing pipeline is to facilitate the creation of options mandatory for coaching and deploying the job advice engine on Expertise.com. It’s value noting that this pipeline should help incremental updates and cater to the intricate characteristic extraction necessities mandatory for the coaching and deployment modules important for the job advice system. Our pipeline belongs to the final ETL (extract, remodel, and cargo) course of household that mixes information from a number of sources into a big, central repository.
For additional insights into how Expertise.com and AWS collaboratively constructed cutting-edge pure language processing and deep studying mannequin coaching strategies, using Amazon SageMaker to craft a job advice system, seek advice from From text to dream job: Building an NLP-based job recommender at Talent.com with Amazon SageMaker. The system consists of characteristic engineering, deep studying mannequin structure design, hyperparameter optimization, and mannequin analysis, the place all modules are run utilizing Python.
This submit reveals how we used SageMaker to construct a large-scale information processing pipeline for getting ready options for the job advice engine at Expertise.com. The ensuing answer permits a Information Scientist to ideate characteristic extraction in a SageMaker pocket book utilizing Python libraries, reminiscent of Scikit-Learn or PyTorch, after which to rapidly deploy the identical code into the info processing pipeline performing characteristic extraction at scale. The answer doesn’t require porting the characteristic extraction code to make use of PySpark, as required when utilizing AWS Glue because the ETL answer. Our answer might be developed and deployed solely by a Information Scientist end-to-end utilizing solely a SageMaker, and doesn’t require information of different ETL options, reminiscent of AWS Batch. This will considerably shorten the time wanted to deploy the Machine Studying (ML) pipeline to manufacturing. The pipeline is operated by means of Python and seamlessly integrates with characteristic extraction workflows, rendering it adaptable to a variety of knowledge analytics purposes.
Answer overview

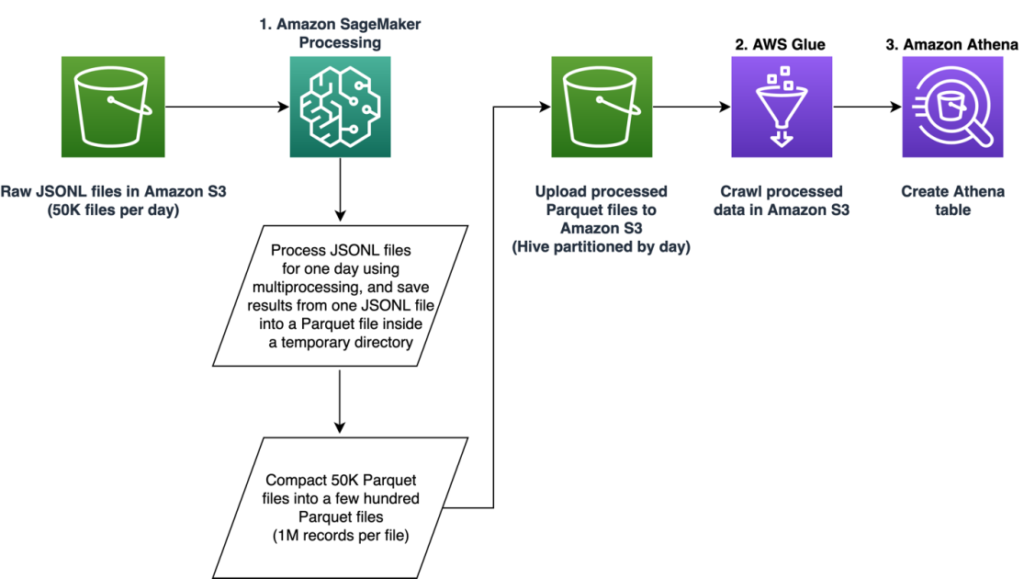
The pipeline is comprised of three main phases:
- Make the most of an Amazon SageMaker Processing job to deal with uncooked JSONL recordsdata related to a specified day. A number of days of knowledge might be processed by separate Processing jobs concurrently.
- Make use of AWS Glue for information crawling after processing a number of days of knowledge.
- Load processed options for a specified date vary utilizing SQL from an Amazon Athena desk, then prepare and deploy the job recommender mannequin.
Course of uncooked JSONL recordsdata
We course of uncooked JSONL recordsdata for a specified day utilizing a SageMaker Processing job. The job implements characteristic extraction and information compaction, and saves processed options into Parquet recordsdata with 1 million information per file. We make the most of CPU parallelization to carry out characteristic extraction for every uncooked JSONL file in parallel. Processing outcomes of every JSONL file is saved right into a separate Parquet file inside a short lived listing. After the entire JSONL recordsdata have been processed, we carry out compaction of 1000’s of small Parquet recordsdata into a number of recordsdata with 1 million information per file. The compacted Parquet recordsdata are then uploaded into Amazon S3 because the output of the processing job. The info compaction ensures environment friendly crawling and SQL queries within the subsequent phases of the pipeline.
The next is the pattern code to schedule a SageMaker Processing job for a specified day, for instance 2020-01-01, utilizing the SageMaker SDK. The job reads uncooked JSONL recordsdata from Amazon S3 (for instance from s3://bucket/raw-data/2020/01/01) and saves the compacted Parquet recordsdata into Amazon S3 (for instance to s3://bucket/processed/table-name/day_partition=2020-01-01/).
### set up dependencies
%pip set up sagemaker pyarrow s3fs awswrangler
import sagemaker
import boto3
from sagemaker.processing import FrameworkProcessor
from sagemaker.sklearn.estimator import SKLearn
from sagemaker import get_execution_role
from sagemaker.processing import ProcessingInput, ProcessingOutput
area = boto3.session.Session().region_name
function = get_execution_role()
bucket = sagemaker.Session().default_bucket()
### we use occasion with 16 CPUs and 128 GiB reminiscence
### word that the script will NOT load the complete information into reminiscence throughout compaction
### relying on the scale of particular person jsonl recordsdata, bigger occasion could also be wanted
occasion = "ml.r5.4xlarge"
n_jobs = 8 ### we use 8 course of employees
date = "2020-01-01" ### course of information for someday
est_cls = SKLearn
framework_version_str = "0.20.0"
### schedule processing job
script_processor = FrameworkProcessor(
function=function,
instance_count=1,
instance_type=occasion,
estimator_cls=est_cls,
framework_version=framework_version_str,
volume_size_in_gb=500,
)
script_processor.run(
code="processing_script.py", ### identify of the primary processing script
source_dir="../src/etl/", ### location of supply code listing
### our processing script hundreds uncooked jsonl recordsdata immediately from S3
### this avoids lengthy start-up instances of the processing jobs,
### since uncooked information doesn't must be copied into occasion
inputs=[], ### processing job enter is empty
outputs=[
ProcessingOutput(destination="s3://bucket/processed/table-name/",
source="/opt/ml/processing/output"),
],
arguments=[
### directory with job's output
"--output", "/opt/ml/processing/output",
### temporary directory inside instance
"--tmp_output", "/opt/ml/tmp_output",
"--n_jobs", str(n_jobs), ### number of process workers
"--date", date, ### date to process
### location with raw jsonl files in S3
"--path", "s3://bucket/raw-data/",
],
wait=False
)
The next code define for the primary script (processing_script.py) that runs the SageMaker Processing job is as follows:
import concurrent
import pyarrow.dataset as ds
import os
import s3fs
from pathlib import Path
### perform to course of uncooked jsonl file and save extracted options into parquet file
from process_data import process_jsonl
### parse command line arguments
args = parse_args()
### we use s3fs to crawl S3 enter path for uncooked jsonl recordsdata
fs = s3fs.S3FileSystem()
### we assume uncooked jsonl recordsdata are saved in S3 directories partitioned by date
### for instance: s3://bucket/raw-data/2020/01/01/
jsons = fs.discover(os.path.be a part of(args.path, *args.date.break up('-')))
### momentary listing location contained in the Processing job occasion
tmp_out = os.path.be a part of(args.tmp_output, f"day_partition={args.date}")
### listing location with job's output
out_dir = os.path.be a part of(args.output, f"day_partition={args.date}")
### course of particular person jsonl recordsdata in parallel utilizing n_jobs course of employees
futures=[]
with concurrent.futures.ProcessPoolExecutor(max_workers=args.n_jobs) as executor:
for file in jsons:
inp_file = Path(file)
out_file = os.path.be a part of(tmp_out, inp_file.stem + ".snappy.parquet")
### process_jsonl perform reads uncooked jsonl file from S3 location (inp_file)
### and saves end result into parquet file (out_file) inside momentary listing
futures.append(executor.submit(process_jsonl, file, out_file))
### wait till all jsonl recordsdata are processed
for future in concurrent.futures.as_completed(futures):
end result = future.end result()
### compact parquet recordsdata
dataset = ds.dataset(tmp_out)
if len(dataset.schema) > 0:
### save compacted parquet recordsdata with 1MM information per file
ds.write_dataset(dataset, out_dir, format="parquet",
max_rows_per_file=1024 * 1024)
Scalability is a key characteristic of our pipeline. First, a number of SageMaker Processing jobs can be utilized to course of information for a number of days concurrently. Second, we keep away from loading the complete processed or uncooked information into reminiscence without delay, whereas processing every specified day of knowledge. This permits the processing of knowledge utilizing occasion sorts that may’t accommodate a full day’s value of knowledge in main reminiscence. The one requirement is that the occasion sort must be able to loading N uncooked JSONL or processed Parquet recordsdata into reminiscence concurrently, with N being the variety of course of employees in use.
Crawl processed information utilizing AWS Glue
After all of the uncooked information for a number of days has been processed, we are able to create an Athena desk from the complete dataset by utilizing an AWS Glue crawler. We use the AWS SDK for pandas (awswrangler) library to create the desk utilizing the next snippet:
import awswrangler as wr
### crawl processed information in S3
res = wr.s3.store_parquet_metadata(
path="s3://bucket/processed/table-name/",
database="database_name",
desk="table_name",
dataset=True,
mode="overwrite",
sampling=1.0,
path_suffix='.parquet',
)
### print desk schema
print(res[0])
Load processed options for coaching
Processed options for a specified date vary can now be loaded from the Athena desk utilizing SQL, and these options can then be used for coaching the job recommender mannequin. For instance, the next snippet hundreds one month of processed options right into a DataFrame utilizing the awswrangler library:
import awswrangler as wr
question = """
SELECT *
FROM table_name
WHERE day_partition BETWEN '2020-01-01' AND '2020-02-01'
"""
### load 1 month of knowledge from database_name.table_name right into a DataFrame
df = wr.athena.read_sql_query(question, database="database_name")
Moreover, using SQL for loading processed options for coaching might be prolonged to accommodate numerous different use circumstances. As an example, we are able to apply the same pipeline to keep up two separate Athena tables: one for storing person impressions and one other for storing person clicks on these impressions. Utilizing SQL be a part of statements, we are able to retrieve impressions that customers both clicked on or didn’t click on on after which go these impressions to a mannequin coaching job.
Answer advantages
Implementing the proposed answer brings a number of benefits to our present workflow, together with:
- Simplified implementation – The answer permits characteristic extraction to be applied in Python utilizing standard ML libraries. And, it doesn’t require the code to be ported into PySpark. This streamlines characteristic extraction as the identical code developed by a Information Scientist in a pocket book will likely be executed by this pipeline.
- Fast path-to-production – The answer might be developed and deployed by a Information Scientist to carry out characteristic extraction at scale, enabling them to develop an ML recommender mannequin towards this information. On the similar time, the identical answer might be deployed to manufacturing by an ML Engineer with little modifications wanted.
- Reusability – The answer gives a reusable sample for characteristic extraction at scale, and might be simply tailored for different use circumstances past constructing recommender fashions.
- Effectivity – The answer provides good efficiency: processing a single day of the Talent.com’s information took lower than 1 hour.
- Incremental updates – The answer additionally helps incremental updates. New day by day information might be processed with a SageMaker Processing job, and the S3 location containing the processed information might be recrawled to replace the Athena desk. We are able to additionally use a cron job to replace in the present day’s information a number of instances per day (for instance, each 3 hours).
We used this ETL pipeline to assist Expertise.com course of 50,000 recordsdata per day containing 5 million information, and created coaching information utilizing options extracted from 90 days of uncooked information from Expertise.com—a complete of 450 million information throughout 900,000 recordsdata. Our pipeline helped Expertise.com construct and deploy the advice system into manufacturing inside solely 2 weeks. The answer carried out all ML processes together with ETL on Amazon SageMaker with out using different AWS service. The job advice system drove an 8.6% improve in clickthrough charge in on-line A/B testing towards a earlier XGBoost-based answer, serving to join tens of millions of Expertise.com’s customers to raised jobs.
Conclusion
This submit outlines the ETL pipeline we developed for characteristic processing for coaching and deploying a job recommender mannequin at Expertise.com. Our pipeline makes use of SageMaker Processing jobs for environment friendly information processing and have extraction at a big scale. Function extraction code is applied in Python enabling using standard ML libraries to carry out characteristic extraction at scale, with out the necessity to port the code to make use of PySpark.
We encourage the readers to discover the potential of utilizing the pipeline offered on this weblog as a template for his or her use-cases the place characteristic extraction at scale is required. The pipeline might be leveraged by a Information Scientist to construct an ML mannequin, and the identical pipeline can then be adopted by an ML Engineer to run in manufacturing. This will considerably scale back the time wanted to productize the ML answer end-to-end, as was the case with Expertise.com. The readers can seek advice from the tutorial for setting up and running SageMaker Processing jobs. We additionally refer the readers to view the submit From text to dream job: Building an NLP-based job recommender at Talent.com with Amazon SageMaker, the place we talk about deep studying mannequin coaching strategies using Amazon SageMaker to construct Expertise.com’s job advice system.
In regards to the authors
 Dmitriy Bespalov is a Senior Utilized Scientist on the Amazon Machine Studying Options Lab, the place he helps AWS prospects throughout completely different industries speed up their AI and cloud adoption.
Dmitriy Bespalov is a Senior Utilized Scientist on the Amazon Machine Studying Options Lab, the place he helps AWS prospects throughout completely different industries speed up their AI and cloud adoption.
 Yi Xiang is a Utilized Scientist II on the Amazon Machine Studying Options Lab, the place she helps AWS prospects throughout completely different industries speed up their AI and cloud adoption.
Yi Xiang is a Utilized Scientist II on the Amazon Machine Studying Options Lab, the place she helps AWS prospects throughout completely different industries speed up their AI and cloud adoption.
 Tong Wang is a Senior Utilized Scientist on the Amazon Machine Studying Options Lab, the place he helps AWS prospects throughout completely different industries speed up their AI and cloud adoption.
Tong Wang is a Senior Utilized Scientist on the Amazon Machine Studying Options Lab, the place he helps AWS prospects throughout completely different industries speed up their AI and cloud adoption.
 Anatoly Khomenko is a Senior Machine Studying Engineer at Talent.com with a ardour for pure language processing matching good folks to good jobs.
Anatoly Khomenko is a Senior Machine Studying Engineer at Talent.com with a ardour for pure language processing matching good folks to good jobs.
 Abdenour Bezzouh is an govt with greater than 25 years expertise constructing and delivering know-how options that scale to tens of millions of consumers. Abdenour held the place of Chief Expertise Officer (CTO) at Talent.com when the AWS staff designed and executed this specific answer for Talent.com.
Abdenour Bezzouh is an govt with greater than 25 years expertise constructing and delivering know-how options that scale to tens of millions of consumers. Abdenour held the place of Chief Expertise Officer (CTO) at Talent.com when the AWS staff designed and executed this specific answer for Talent.com.
 Yanjun Qi is a Senior Utilized Science Supervisor on the Amazon Machine Studying Answer Lab. She innovates and applies machine studying to assist AWS prospects pace up their AI and cloud adoption.
Yanjun Qi is a Senior Utilized Science Supervisor on the Amazon Machine Studying Answer Lab. She innovates and applies machine studying to assist AWS prospects pace up their AI and cloud adoption.





