Unsupervised speech-to-speech translation from monolingual information – Google Analysis Weblog

Speech-to-speech translation (S2ST) is a sort of machine translation that converts spoken language from one language to a different. This expertise has the potential to interrupt down language obstacles and facilitate communication between folks from completely different cultures and backgrounds.
Beforehand, we launched Translatotron 1 and Translatotron 2, the primary ever fashions that have been capable of instantly translate speech between two languages. Nevertheless they have been skilled in supervised settings with parallel speech information. The shortage of parallel speech information is a serious problem on this area, a lot that almost all public datasets are semi- or fully-synthesized from textual content. This provides further hurdles to studying translation and reconstruction of speech attributes that aren’t represented within the textual content and are thus not mirrored within the synthesized coaching information.
Right here we current Translatotron 3, a novel unsupervised speech-to-speech translation structure. In Translatotron 3, we present that it’s attainable to be taught a speech-to-speech translation activity from monolingual information alone. This methodology opens the door not solely to translation between extra language pairs but additionally in direction of translation of the non-textual speech attributes akin to pauses, talking charges, and speaker identification. Our methodology doesn’t embody any direct supervision to focus on languages and subsequently we imagine it’s the proper course for paralinguistic traits (e.g., akin to tone, emotion) of the supply speech to be preserved throughout translation. To allow speech-to-speech translation, we use back-translation, which is a method from unsupervised machine translation (UMT) the place an artificial translation of the supply language is used to translate texts without bilingual text datasets. Experimental leads to speech-to-speech translation duties between Spanish and English present that Translatotron 3 outperforms a baseline cascade system.
Translatotron 3
Translatotron 3 addresses the issue of unsupervised S2ST, which might remove the requirement for bilingual speech datasets. To do that, Translatotron 3’s design incorporates three key features:
- Pre-training the whole mannequin as a masked autoencoder with SpecAugment, a easy information augmentation methodology for speech recognition that operates on the logarithmic mel spectogram of the enter audio (as an alternative of the uncooked audio itself) and is proven to successfully enhance the generalization capabilities of the encoder.
- Unsupervised embedding mapping based mostly on multilingual unsupervised embeddings (MUSE), which is skilled on unpaired languages however permits the mannequin to be taught an embedding house that’s shared between the supply and goal languages.
- A reconstruction loss based mostly on back-translation, to coach an encoder-decoder direct S2ST mannequin in a completely unsupervised method.
The mannequin is skilled utilizing a mixture of the unsupervised MUSE embedding loss, reconstruction loss, and S2S back-translation loss. Throughout inference, the shared encoder is utilized to encode the enter right into a multilingual embedding house, which is subsequently decoded by the goal language decoder.
Structure
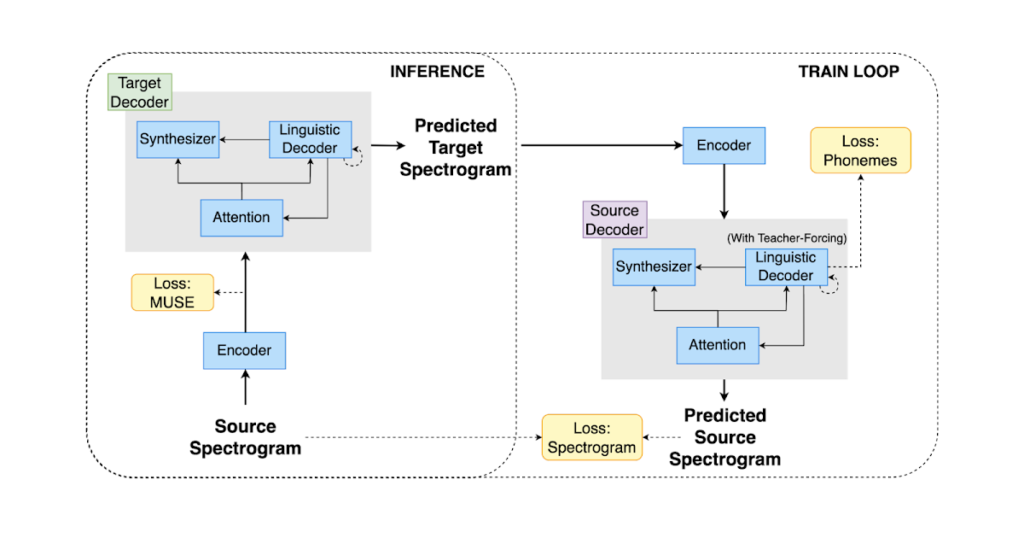
Translatotron 3 employs a shared encoder to encode each the supply and goal languages. The decoder consists of a linguistic decoder, an acoustic synthesizer (answerable for acoustic era of the interpretation speech), and a singular consideration module, like Translatotron 2. Nevertheless, for Translatotron 3 there are two decoders, one for the supply language and one other for the goal language. Throughout coaching, we use monolingual speech-text datasets (i.e., these information are made up of speech-text pairs; they’re not translations).
Encoder
The encoder has the identical structure because the speech encoder within the Translatotron 2. The output of the encoder is cut up into two elements: the primary half incorporates semantic info whereas the second half incorporates acoustic info. By utilizing the MUSE loss, the primary half of the output is skilled to be the MUSE embeddings of the textual content of the enter speech spectrogram. The latter half is up to date with out the MUSE loss. It is very important word that the identical encoder is shared between supply and goal languages. Moreover, the MUSE embedding is multilingual in nature. Because of this, the encoder is ready to be taught a multilingual embedding house throughout supply and goal languages. This enables a extra environment friendly and efficient encoding of the enter, because the encoder is ready to encode speech from each languages into a standard embedding house, somewhat than sustaining a separate embedding house for every language.
Decoder
Like Translatotron 2, the decoder consists of three distinct parts, particularly the linguistic decoder, the acoustic synthesizer, and the eye module. To successfully deal with the completely different properties of the supply and goal languages, nonetheless, Translatotron 3 has two separate decoders, for the supply and goal languages.
Two half coaching
The coaching methodology consists of two elements: (1) auto-encoding with reconstruction and (2) a back-translation time period. Within the first half, the community is skilled to auto-encode the enter to a multilingual embedding house utilizing the MUSE loss and the reconstruction loss. This section goals to make sure that the community generates significant multilingual representations. Within the second half, the community is additional skilled to translate the enter spectrogram by using the back-translation loss. To mitigate the difficulty of catastrophic forgetting and implementing the latent house to be multilingual, the MUSE loss and the reconstruction loss are additionally utilized on this second a part of coaching. To make sure that the encoder learns significant properties of the enter, somewhat than merely reconstructing the enter, we apply SpecAugment to encoder enter at each phases. It has been proven to successfully enhance the generalization capabilities of the encoder by augmenting the enter information.
Coaching goal
In the course of the back-translation coaching section (illustrated within the part under), the community is skilled to translate the enter spectrogram to the goal language after which again to the supply language. The purpose of back-translation is to implement the latent house to be multilingual. To attain this, the next losses are utilized:
- MUSE loss: The MUSE loss measures the similarity between the multilingual embedding of the enter spectrogram and the multilingual embedding of the back-translated spectrogram.
- Reconstruction loss: The reconstruction loss measures the similarity between the enter spectrogram and the back-translated spectrogram.
Along with these losses, SpecAugment is utilized to the encoder enter at each phases. Earlier than the back-translation coaching section, the community is skilled to auto-encode the enter to a multilingual embedding house utilizing the MUSE loss and reconstruction loss.
MUSE loss
To make sure that the encoder generates multilingual representations which are significant for each decoders, we make use of a MUSE loss throughout coaching. The MUSE loss forces the encoder to generate such a illustration through the use of pre-trained MUSE embeddings. In the course of the coaching course of, given an enter textual content transcript, we extract the corresponding MUSE embeddings from the embeddings of the enter language. The error between MUSE embeddings and the output vectors of the encoder is then minimized. Notice that the encoder is detached to the language of the enter throughout inference as a result of multilingual nature of the embeddings.
 |
| The coaching and inference in Translatotron 3. Coaching consists of the reconstruction loss by way of the auto-encoding path and employs the reconstruction loss by way of back-translation. |
Audio samples
Following are examples of direct speech-to-speech translation from Translatotron 3:
Spanish-to-English (on Conversational dataset)
| Enter (Spanish) | |
| TTS-synthesized reference (English) | |
| Translatotron 3 (English) |
Spanish-to-English (on CommonVoice11 Synthesized dataset)
| Enter (Spanish) | |
| TTS-synthesized reference (English) | |
| Translatotron 3 (English) |
Spanish-to-English (on CommonVoice11 dataset)
| Enter (Spanish) | |
| TTS reference (English) | |
| Translatotron 3 (English) |
Efficiency
To empirically consider the efficiency of the proposed strategy, we carried out experiments on English and Spanish utilizing numerous datasets, together with the Common Voice 11 dataset, in addition to two synthesized datasets derived from the Conversational and Widespread Voice 11 datasets.
The interpretation high quality was measured by BLEU (greater is best) on ASR (automated speech recognition) transcriptions from the translated speech, in comparison with the corresponding reference translation textual content. Whereas, the speech high quality is measured by the MOS rating (greater is best). Moreover, the speaker similarity is measured by the average cosine similarity (greater is best).
As a result of Translatotron 3 is an unsupervised methodology, as a baseline we used a cascaded S2ST system that’s mixed from ASR, unsupervised machine translation (UMT), and TTS (text-to-speech). Particularly, we make use of UMT that makes use of the closest neighbor within the embedding house in an effort to create the interpretation.
Translatotron 3 outperforms the baseline by massive margins in each side we measured: translation high quality, speaker similarity, and speech high quality. It significantly excelled on the conversational corpus. Furthermore, Translatotron 3 achieves speech naturalness much like that of the bottom reality audio samples (measured by MOS, greater is best).
 |
| Translation high quality (measured by BLEU, the place greater is best) evaluated on three Spanish-English corpora. |
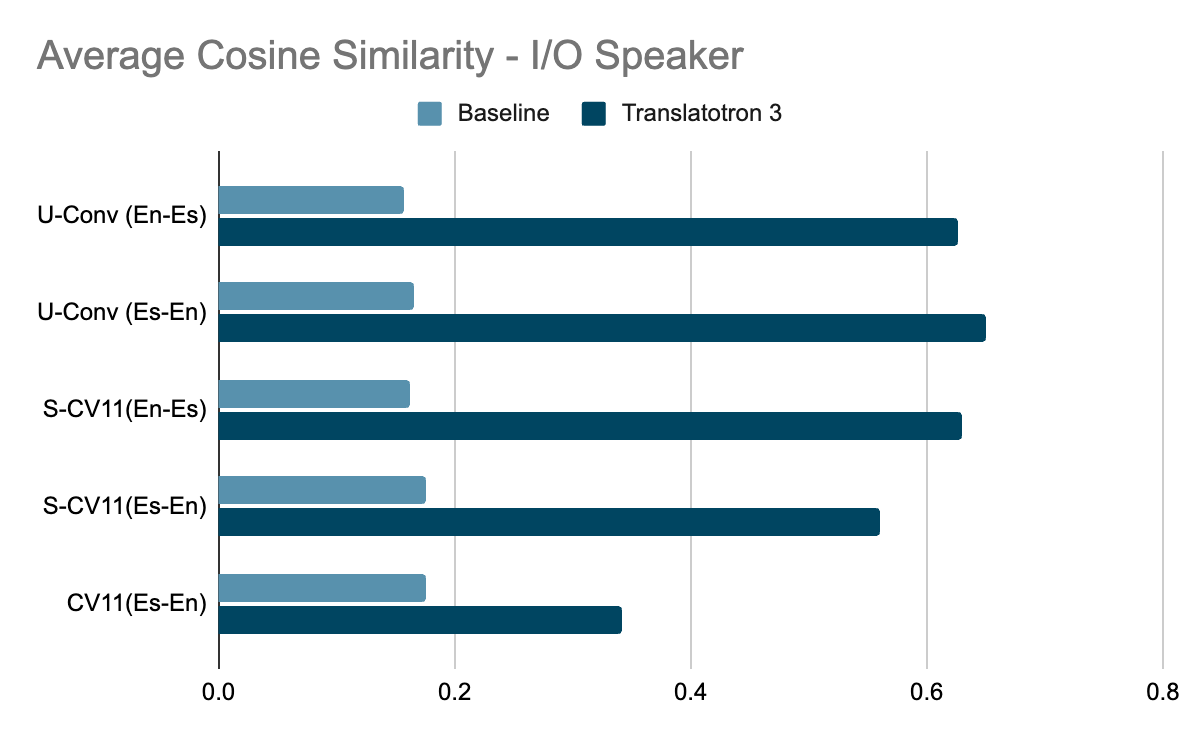 |
| Speech similarity (measured by common cosine similarity between enter speaker and output speaker, the place greater is best) evaluated on three Spanish-English corpora. |
 |
| Imply-opinion-score (measured by common MOS metric, the place greater is best) evaluated on three Spanish-English corpora. |
Future work
As future work, we wish to prolong the work to extra languages and examine whether or not zero-shot S2ST might be utilized with the back-translation approach. We’d additionally like to look at the usage of back-translation with various kinds of speech information, akin to noisy speech and low-resource languages.
Acknowledgments
The direct contributors to this work embody Eliya Nachmani, Alon Levkovitch, Yifan Ding, Chulayutsh Asawaroengchai, Heiga Zhen, and Michelle Tadmor Ramanovich. We additionally thank Yu Zhang, Yuma Koizumi, Soroosh Mariooryad, RJ Skerry-Ryan, Neil Zeghidour, Christian Frank, Marco Tagliasacchi, Nadav Bar, Benny Schlesinger and Yonghui Wu.






