Google AI Introduces AltUp (Alternating Updates): An Synthetic Intelligence Methodology that Takes Benefit of Rising Scale in Transformer Networks with out Rising the Computation Price
In deep studying, Transformer neural networks have garnered important consideration for his or her effectiveness in varied domains, particularly in pure language processing and rising purposes like laptop imaginative and prescient, robotics, and autonomous driving. Nonetheless, whereas enhancing efficiency, the ever-increasing scale of those fashions brings a couple of substantial rise in compute value and inference latency. The basic problem lies in leveraging some great benefits of bigger fashions with out incurring impractical computational burdens.
The present panorama of deep studying fashions, significantly Transformers, showcases outstanding progress throughout various domains. Nonetheless, the scalability of those fashions usually must be improved as a result of escalating computational necessities. Prior efforts, exemplified by sparse mixture-of-experts fashions like Change Transformer, Skilled Alternative, and V-MoE, have predominantly targeted on effectively scaling up community parameters, mitigating the elevated compute per enter. Nonetheless, a analysis hole exists in regards to the scaling up of the token illustration dimension itself. Enter AltUp is a novel technique launched to deal with this hole.
AltUp stands out by offering a way to reinforce token illustration with out amplifying the computational overhead. This technique ingeniously partitions a widened illustration vector into equal-sized blocks, processing just one block at every layer. The crux of AltUp’s efficacy lies in its prediction-correction mechanism, enabling the inference of outputs for the non-processed blocks. By sustaining the mannequin dimension and sidestepping the quadratic improve in computation related to simple enlargement, AltUp emerges as a promising answer to the computational challenges posed by bigger Transformer networks.

AltUp’s mechanics delve into the intricacies of token embeddings and the way they are often widened with out triggering a surge in computational complexity. The strategy includes:
- Invoking a 1x width transformer layer for one of many blocks.
- Termed the “activated” block.
- Concurrently using a light-weight predictor.
This predictor computes a weighted mixture of all enter blocks, and the expected values, together with the computed worth of the activated block, endure correction via a light-weight corrector. This correction mechanism facilitates the replace of inactivated blocks primarily based on the activated ones. Importantly, each prediction and correction steps contain minimal vector additions and multiplications, considerably quicker than a traditional transformer layer.
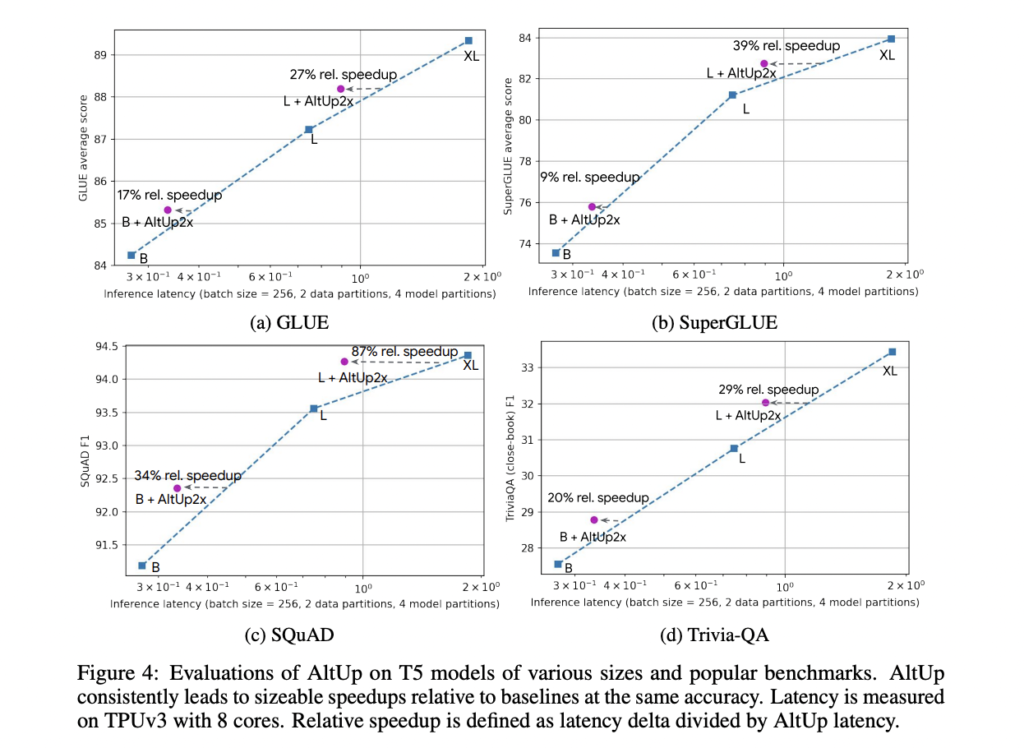
The analysis of AltUp on T5 fashions throughout benchmark language duties demonstrates its constant capacity to outperform dense fashions on the similar accuracy. Notably, a T5 Giant mannequin augmented with AltUp achieves notable speedups of 27%, 39%, 87%, and 29% on GLUE, SuperGLUE, SQuAD, and Trivia-QA benchmarks, respectively. AltUp’s relative efficiency enhancements develop into extra pronounced when utilized to bigger fashions, underscoring its scalability and enhanced efficacy as mannequin measurement will increase.

In conclusion, AltUp emerges as a noteworthy answer to the long-standing problem of effectively scaling up Transformer neural networks. Its capacity to reinforce token illustration with out a proportional improve in computational value holds important promise for varied purposes. The progressive method of AltUp, characterised by its partitioning and prediction-correction mechanism, provides a practical strategy to harness the advantages of bigger fashions with out succumbing to impractical computational calls for.
The researchers’ extension of AltUp, often known as Recycled-AltUp, additional showcases the adaptability of the proposed technique. Recycled-AltUp, by replicating embeddings as an alternative of widening the preliminary token embeddings, demonstrates strict enhancements in pre-training efficiency with out introducing perceptible slowdown. This dual-pronged method, coupled with AltUp’s seamless integration with different methods like MoE, exemplifies its versatility and opens avenues for future analysis in exploring the dynamics of coaching and mannequin efficiency.
AltUp signifies a breakthrough within the quest for environment friendly scaling of Transformer networks, presenting a compelling answer to the trade-off between mannequin measurement and computational effectivity. As outlined on this paper, the analysis crew’s contributions mark a big step in direction of making large-scale Transformer fashions extra accessible and sensible for a myriad of purposes.
Take a look at the Paper and Google Article. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to hitch our 32k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the newest AI analysis information, cool AI tasks, and extra.
If you like our work, you will love our newsletter..
We’re additionally on Telegram and WhatsApp.
Madhur Garg is a consulting intern at MarktechPost. He’s at present pursuing his B.Tech in Civil and Environmental Engineering from the Indian Institute of Know-how (IIT), Patna. He shares a powerful ardour for Machine Studying and enjoys exploring the newest developments in applied sciences and their sensible purposes. With a eager curiosity in synthetic intelligence and its various purposes, Madhur is decided to contribute to the sector of Knowledge Science and leverage its potential affect in varied industries.





