English learners can now follow talking on Search – Google Analysis Weblog


Studying a language can open up new alternatives in an individual’s life. It may well assist folks join with these from completely different cultures, journey the world, and advance their profession. English alone is estimated to have 1.5 billion learners worldwide. But proficiency in a brand new language is troublesome to realize, and lots of learners cite an absence of alternative to follow talking actively and receiving actionable suggestions as a barrier to studying.
We’re excited to announce a brand new characteristic of Google Search that helps folks follow talking and enhance their language expertise. Inside the subsequent few days, Android customers in Argentina, Colombia, India (Hindi), Indonesia, Mexico, and Venezuela can get much more language assist from Google via interactive talking follow in English — increasing to extra nations and languages sooner or later. Google Search is already a useful device for language learners, offering translations, definitions, and different assets to enhance vocabulary. Now, learners translating to or from English on their Android telephones will discover a new English talking follow expertise with customized suggestions.
 |
| A brand new characteristic of Google Search permits learners to follow talking phrases in context. |
Learners are offered with real-life prompts after which type their very own spoken solutions utilizing a offered vocabulary phrase. They have interaction in follow classes of 3-5 minutes, getting customized suggestions and the choice to enroll in day by day reminders to maintain training. With solely a smartphone and a few high quality time, learners can follow at their very own tempo, anytime, wherever.
Actions with customized suggestions, to complement current studying instruments
Designed for use alongside different studying providers and assets, like private tutoring, cellular apps, and lessons, the brand new talking follow characteristic on Google Search is one other device to help learners on their journey.
We have now partnered with linguists, lecturers, and ESL/EFL pedagogical consultants to create a talking follow expertise that’s efficient and motivating. Learners follow vocabulary in genuine contexts, and materials is repeated over dynamic intervals to extend retention — approaches which are identified to be efficient in serving to learners turn into assured audio system. As one associate of ours shared:
“Talking in a given context is a talent that language learners usually lack the chance to follow. Subsequently this device may be very helpful to enhance lessons and different assets.” – Judit Kormos, Professor, Lancaster College
We’re additionally excited to be working with a number of language studying companions to floor content material they’re serving to create and to attach them with learners world wide. We look ahead to increasing this program additional and dealing with any associate.
Customized real-time suggestions
Each learner is completely different, so delivering customized suggestions in actual time is a key a part of efficient follow. Responses are analyzed to offer useful, real-time solutions and corrections.
The system provides semantic suggestions, indicating whether or not their response was related to the query and could also be understood by a dialog associate. Grammar suggestions gives insights into potential grammatical enhancements, and a set of instance solutions at various ranges of language complexity give concrete solutions for other ways to reply on this context.
 |
| The suggestions consists of three components: Semantic evaluation, grammar correction, and instance solutions. |
Contextual translation
Among the many a number of new applied sciences we developed, contextual translation gives the power to translate particular person phrases and phrases in context. Throughout follow classes, learners can faucet on any phrase they don’t perceive to see the interpretation of that phrase contemplating its context.
 |
| Instance of contextual translation characteristic. |
It is a troublesome technical process, since particular person phrases in isolation usually have a number of various meanings, and a number of phrases can type clusters of that means that must be translated in unison. Our novel method interprets the complete sentence, then estimates how the phrases within the authentic and the translated textual content relate to one another. That is generally often known as the word alignment problem.
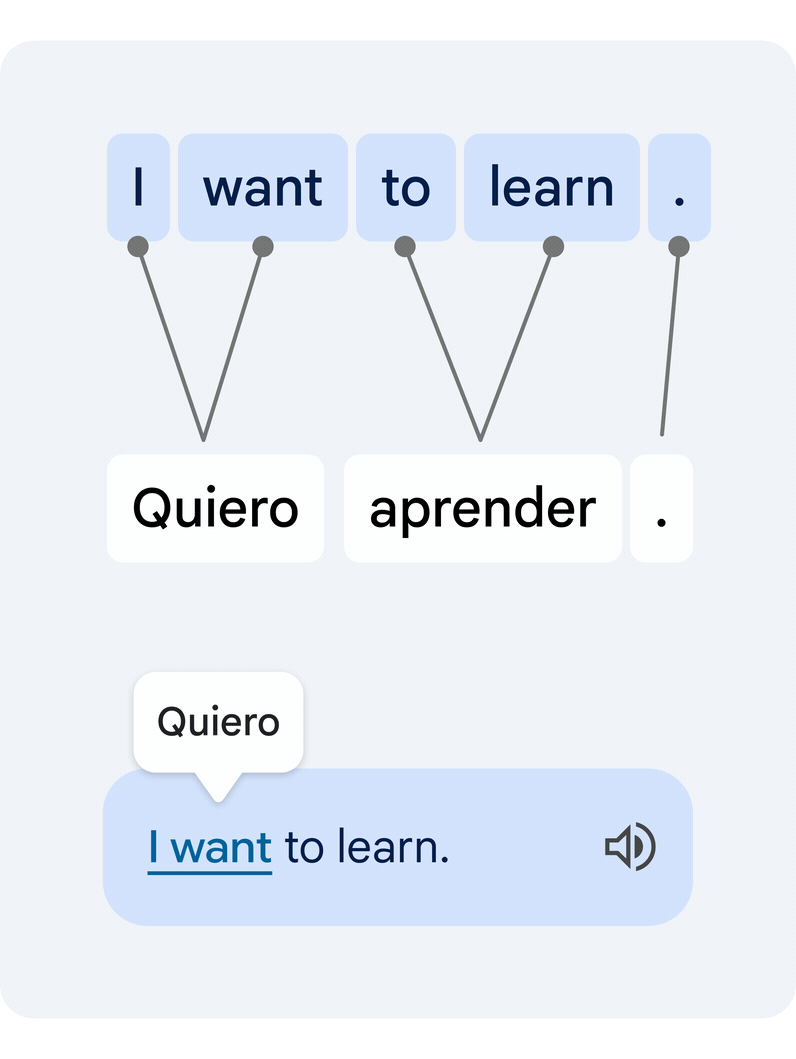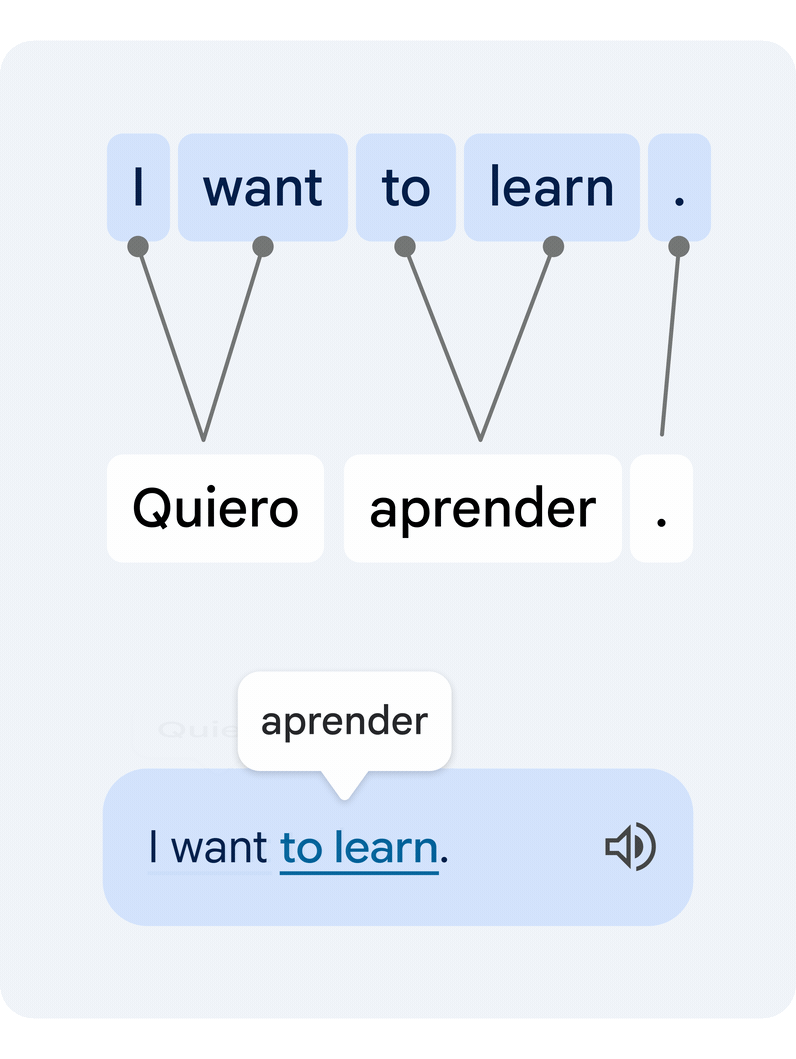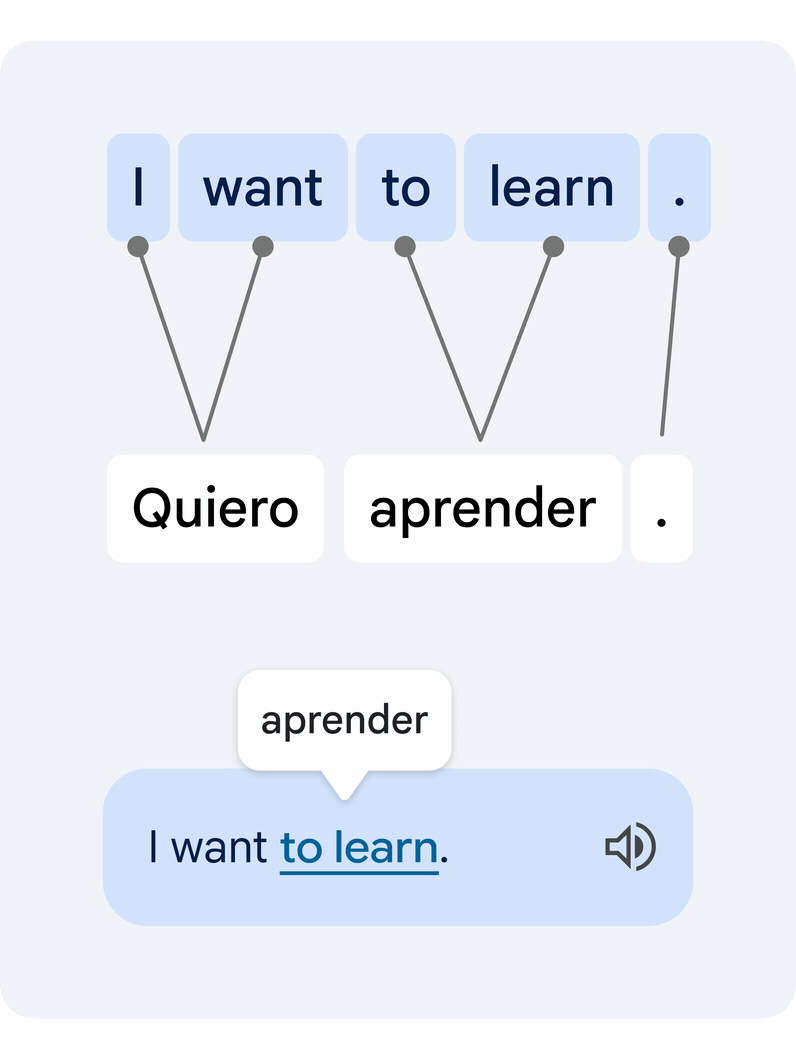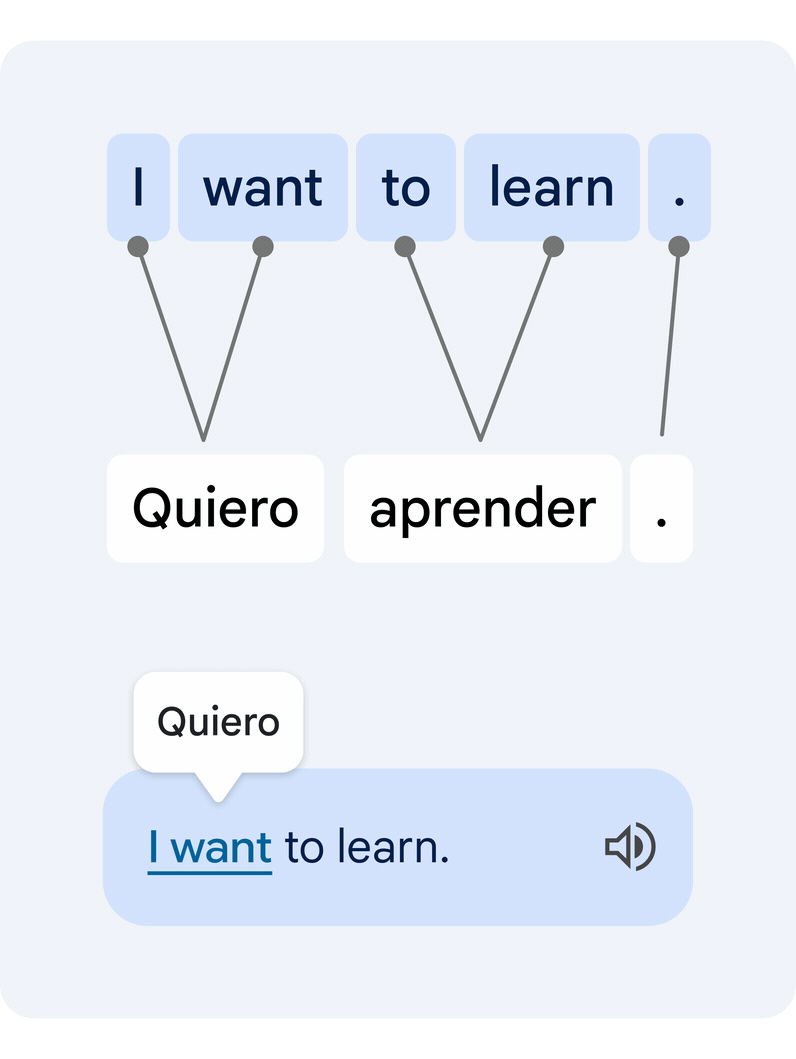 |
| Instance of a translated sentence pair and its phrase alignment. A deep studying alignment mannequin connects the completely different phrases that create the that means to recommend a translation. |
The important thing expertise piece that allows this performance is a novel deep learning mannequin developed in collaboration with the Google Translate staff, referred to as Deep Aligner. The essential concept is to take a multilingual language mannequin skilled on lots of of languages, then fine-tune a novel alignment mannequin on a set of phrase alignment examples (see the determine above for an instance) offered by human consultants, for a number of language pairs. From this, the only mannequin can then precisely align any language pair, reaching state-of-the-art alignment error fee (AER, a metric to measure the standard of phrase alignments, the place decrease is best). This single new mannequin has led to dramatic enhancements in alignment high quality throughout all examined language pairs, decreasing common AER from 25% to five% in comparison with alignment approaches primarily based on Hidden Markov models (HMMs).
 |
| Alignment error charges (decrease is best) between English (EN) and different languages. |
This mannequin can also be integrated into Google’s translation APIs, tremendously bettering, for instance, the formatting of translated PDFs and web sites in Chrome, the interpretation of YouTube captions, and enhancing Google Cloud’s translation API.
Grammar suggestions
To allow grammar suggestions for accented spoken language, our analysis groups tailored grammar correction fashions for written textual content (see the blog and paper) to work on automated speech recognition (ASR) transcriptions, particularly for the case of accented speech. The important thing step was fine-tuning the written textual content mannequin on a corpus of human and ASR transcripts of accented speech, with expert-provided grammar corrections. Moreover, impressed by previous work, the groups developed a novel edit-based output illustration that leverages the excessive overlap between the inputs and outputs that’s significantly well-suited for brief enter sentences widespread in language studying settings.
The edit illustration might be defined utilizing an instance:
- Enter: I1 am2 so3 unhealthy4 cooking5
- Correction: I1 am2 so3 unhealthy4 at5 cooking6
- Edits: (‘at’, 4, PREPOSITION, 4)
Within the above, “at” is the phrase that’s inserted at place 4 and “PREPOSITION” denotes that is an error involving prepositions. We used the error tag to pick out tag-dependent acceptance thresholds that improved the mannequin additional. The mannequin elevated the recall of grammar issues from 4.6% to 35%.
Some instance output from our mannequin and a mannequin skilled on written corpora:
| Instance 1 | Instance 2 | |||
| Consumer enter (transcribed speech) | I dwell of my occupation. | I want a environment friendly card and dependable. | ||
| Textual content-based grammar mannequin | I dwell by my occupation. | I want an environment friendly card and a dependable. | ||
| New speech-optimized mannequin | I dwell off my occupation. | I want an environment friendly and dependable card. |
Semantic evaluation
A main purpose of dialog is to speak one’s intent clearly. Thus, we designed a characteristic that visually communicates to the learner whether or not their response was related to the context and could be understood by a associate. It is a troublesome technical downside, since early language learners’ spoken responses might be syntactically unconventional. We needed to fastidiously steadiness this expertise to concentrate on the readability of intent relatively than correctness of syntax.
Our system makes use of a mix of two approaches:
- Sensibility classification: Giant language fashions like LaMDA or PaLM are designed to offer pure responses in a dialog, so it’s no shock that they do effectively on the reverse: judging whether or not a given response is contextually smart.
- Similarity to good responses: We used an encoder architecture to check the learner’s enter to a set of identified good responses in a semantic embedding area. This comparability gives one other helpful sign on semantic relevance, additional bettering the standard of suggestions and solutions we offer.
 |
| The system gives suggestions about whether or not the response was related to the immediate, and could be understood by a communication associate. |
ML-assisted content material growth
Our obtainable follow actions current a mixture of human-expert created content material, and content material that was created with AI help and human evaluation. This consists of talking prompts, focus phrases, in addition to units of instance solutions that showcase significant and contextual responses.
 |
| A listing of instance solutions is offered when the learner receives suggestions and after they faucet the assistance button. |
Since learners have completely different ranges of skill, the language complexity of the content material needs to be adjusted appropriately. Prior work on language complexity estimation focuses on textual content of paragraph length or longer, which differs considerably from the kind of responses that our system processes. Thus, we developed novel fashions that may estimate the complexity of a single sentence, phrase, and even particular person phrases. That is difficult as a result of even a phrase composed of easy phrases might be exhausting for a language learner (e.g., “Let’s minimize to the chase”). Our greatest mannequin relies on BERT and achieves complexity predictions closest to human knowledgeable consensus. The mannequin was pre-trained utilizing a big set of LLM-labeled examples, after which fine-tuned utilizing a human knowledgeable–labeled dataset.
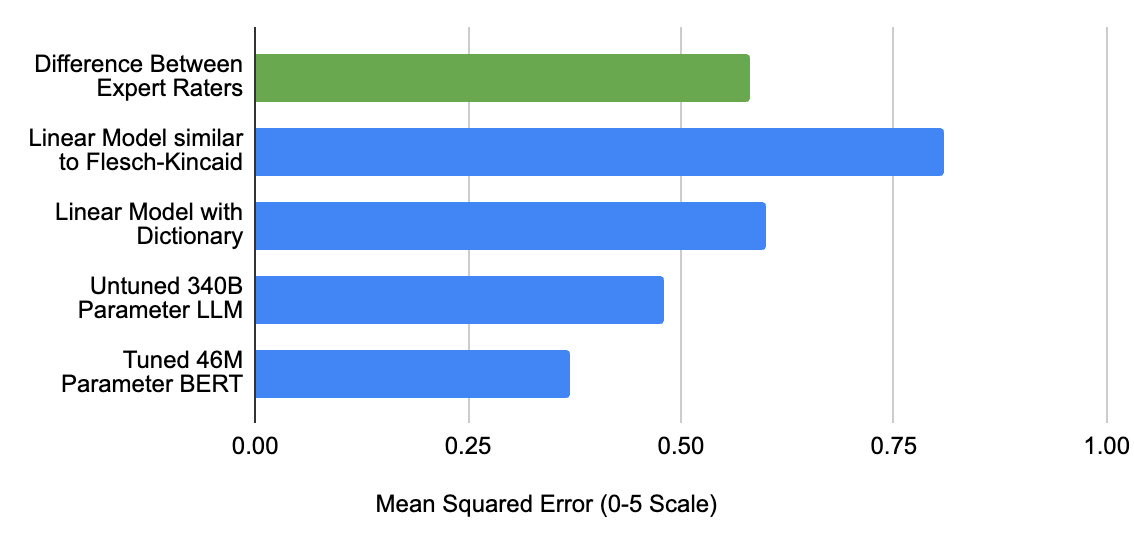 |
| Mean squared error of varied approaches’ efficiency estimating content material problem on a various corpus of ~450 conversational passages (textual content / transcriptions). High row: Human raters labeled the objects on a scale from 0.0 to five.0, roughly aligned to the CEFR scale (from A1 to C2). Backside 4 rows: Totally different fashions carried out the identical process, and we present the distinction to the human knowledgeable consensus. |
Utilizing this mannequin, we are able to consider the issue of textual content objects, supply a various vary of solutions, and most significantly problem learners appropriately for his or her skill ranges. For instance, utilizing our mannequin to label examples, we are able to fine-tune our system to generate talking prompts at numerous language complexity ranges.
| Vocabulary focus phrases, to be elicited by the questions | ||||||
| guitar | apple | lion | ||||
| Easy | What do you wish to play? | Do you want fruit? | Do you want huge cats? | |||
| Intermediate | Do you play any musical devices? | What’s your favourite fruit? | What’s your favourite animal? | |||
| Advanced | What stringed instrument do you get pleasure from taking part in? | Which sort of fruit do you get pleasure from consuming for its crunchy texture and candy taste? | Do you get pleasure from watching massive, highly effective predators? | |||
Moreover, content material problem estimation is used to regularly enhance the duty problem over time, adapting to the learner’s progress.
Conclusion
With these newest updates, which can roll out over the subsequent few days, Google Search has turn into much more useful. In case you are an Android consumer in India (Hindi), Indonesia, Argentina, Colombia, Mexico, or Venezuela, give it a attempt by translating to or from English with Google.
We look ahead to increasing to extra nations and languages sooner or later, and to begin providing associate follow content material quickly.
Acknowledgements
Many individuals have been concerned within the growth of this venture. Amongst many others, we thank our exterior advisers within the language studying subject: Jeffrey Davitz, Judit Kormos, Deborah Healey, Anita Bowles, Susan Gaer, Andrea Revesz, Bradley Opatz, and Anne Mcquade.




