Construct an image-to-text generative AI utility utilizing multimodality fashions on Amazon SageMaker
As we delve deeper into the digital period, the event of multimodality fashions has been important in enhancing machine understanding. These fashions course of and generate content material throughout numerous knowledge varieties, like textual content and pictures. A key function of those fashions is their image-to-text capabilities, which have proven outstanding proficiency in duties equivalent to picture captioning and visible query answering.
By translating photographs into textual content, we unlock and harness the wealth of knowledge contained in visible knowledge. As an illustration, in ecommerce, image-to-text can automate product categorization based mostly on photographs, enhancing search effectivity and accuracy. Equally, it could help in producing computerized picture descriptions, offering info that may not be included in product titles or descriptions, thereby bettering person expertise.
On this submit, we offer an summary of standard multimodality fashions. We additionally display methods to deploy these pre-trained fashions on Amazon SageMaker. Moreover, we talk about the varied purposes of those fashions, focusing notably on a number of real-world situations, equivalent to zero-shot tag and attribution era for ecommerce and computerized immediate era from photographs.
Background of multimodality fashions
Machine studying (ML) fashions have achieved important developments in fields like pure language processing (NLP) and pc imaginative and prescient, the place fashions can exhibit human-like efficiency in analyzing and producing content material from a single supply of information. Extra lately, there was growing consideration within the improvement of multimodality fashions, that are able to processing and producing content material throughout totally different modalities. These fashions, such because the fusion of imaginative and prescient and language networks, have gained prominence attributable to their potential to combine info from various sources and modalities, thereby enhancing their comprehension and expression capabilities.
On this part, we offer an summary of two standard multimodality fashions: CLIP (Contrastive Language-Image Pre-training) and BLIP (Bootstrapping Language-Image Pre-training).
CLIP mannequin
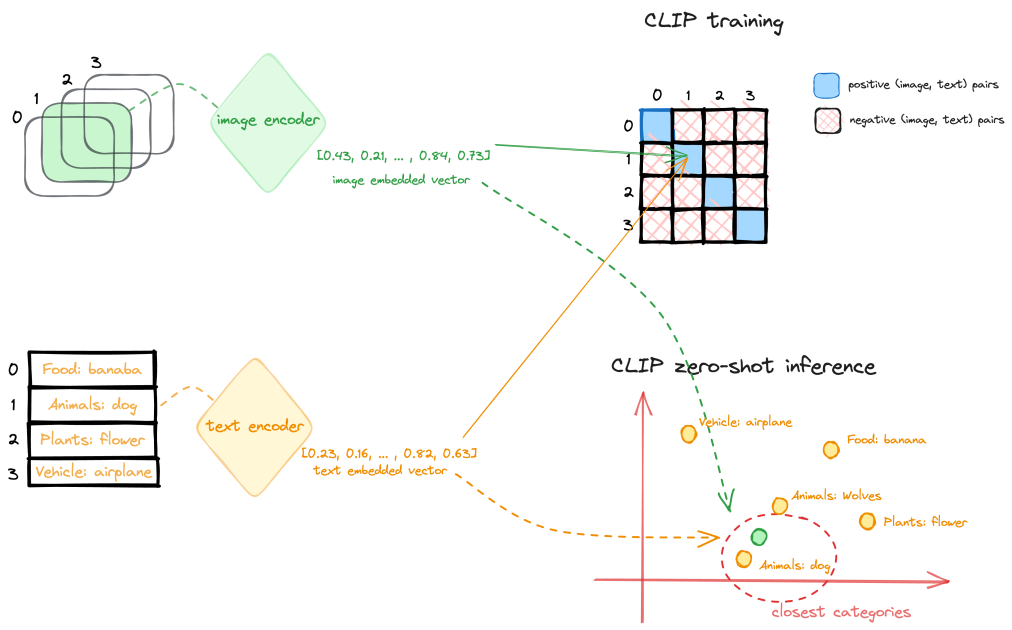
CLIP is a multi-modal imaginative and prescient and language mannequin, which can be utilized for image-text similarity and for zero-shot picture classification. CLIP is educated on a dataset of 400 million image-text pairs collected from a wide range of publicly obtainable sources on the web. The mannequin structure consists of a picture encoder and a textual content encoder, as proven within the following diagram.

Throughout coaching, a picture and corresponding textual content snippet are fed by way of the encoders to get a picture function vector and textual content function vector. The objective is to make the picture and textual content options for a matched pair have a excessive cosine similarity, whereas options for mismatched pairs have low similarity. That is accomplished by way of a contrastive loss. This contrastive pre-training leads to encoders that map photographs and textual content to a typical embedding house the place semantics are aligned.
The encoders can then be used for zero-shot switch studying for downstream duties. At inference time, the picture and textual content pre-trained encoder processes its respective enter and transforms it right into a high-dimensional vector illustration, or an embedding. The embeddings of the picture and textual content are then in comparison with decide their similarity, equivalent to cosine similarity. The textual content immediate (picture courses, classes, or tags) whose embedding is most related (for instance, has the smallest distance) to the picture embedding is taken into account essentially the most related, and the picture is assessed accordingly.
BLIP mannequin
One other standard multimodality mannequin is BLIP. It introduces a novel mannequin structure able to adapting to various vision-language duties and employs a singular dataset bootstrapping method to study from noisy net knowledge. BLIP structure consists of a picture encoder and textual content encoder: the image-grounded textual content encoder injects visible info into the transformer block of the textual content encoder, and the image-grounded textual content decoder incorporates visible info into the transformer decoder block. With this structure, BLIP demonstrates excellent efficiency throughout a spectrum of vision-language duties that contain the fusion of visible and linguistic info, from image-based search and content material era to interactive visible dialog methods. In a earlier submit, we proposed a content moderation solution based on the BLIP model that addressed a number of challenges utilizing pc imaginative and prescient unimodal ML approaches.
Use case 1: Zero-shot tag or attribute era for an ecommerce platform
Ecommerce platforms function dynamic marketplaces teeming with concepts, merchandise, and providers. With tens of millions of merchandise listed, efficient sorting and categorization poses a big problem. That is the place the ability of auto-tagging and attribute era comes into its personal. By harnessing superior applied sciences like ML and NLP, these automated processes can revolutionize the operations of ecommerce platforms.
One of many key advantages of auto-tagging or attribute era lies in its potential to boost searchability. Merchandise tagged precisely might be discovered by clients swiftly and effectively. As an illustration, if a buyer is looking for a “cotton crew neck t-shirt with a emblem in entrance,” auto-tagging and attribute era allow the search engine to pinpoint merchandise that match not merely the broader “t-shirt” class, but in addition the precise attributes of “cotton” and “crew neck.” This exact matching can facilitate a extra customized buying expertise and increase buyer satisfaction. Furthermore, auto-generated tags or attributes can considerably enhance product advice algorithms. With a deep understanding of product attributes, the system can recommend extra related merchandise to clients, thereby growing the chance of purchases and enhancing buyer satisfaction.
CLIP provides a promising resolution for automating the method of tag or attribute era. It takes a product picture and a listing of descriptions or tags as enter, producing a vector illustration, or embedding, for every tag. These embeddings exist in a high-dimensional house, with their relative distances and instructions reflecting the semantic relationships between the inputs. CLIP is pre-trained on a big scale of image-text pairs to encapsulate these significant embeddings. If a tag or attribute precisely describes a picture, their embeddings must be comparatively shut on this house. To generate corresponding tags or attributes, a listing of potential tags might be inputted into the textual content a part of the CLIP mannequin, and the ensuing embeddings saved. Ideally, this checklist must be exhaustive, overlaying all potential classes and attributes related to the merchandise on the ecommerce platform. The next determine reveals some examples.

To deploy the CLIP mannequin on SageMaker, you possibly can observe the pocket book within the following GitHub repo. We use the SageMaker pre-built large model inference (LMI) containers to deploy the mannequin. The LMI containers use DJL Serving to serve your mannequin for inference. To study extra about internet hosting massive fashions on SageMaker, confer with Deploy large models on Amazon SageMaker using DJLServing and DeepSpeed model parallel inference and Deploy large models at high performance using FasterTransformer on Amazon SageMaker.
On this instance, we offer the recordsdata serving.properties, mannequin.py, and necessities.txt to arrange the mannequin artifacts and retailer them in a tarball file.
serving.propertiesis the configuration file that can be utilized to point to DJL Serving which mannequin parallelization and inference optimization libraries you want to use. Relying in your want, you possibly can set the suitable configuration. For extra particulars on the configuration choices and an exhaustive checklist, confer with Configurations and settings.mannequin.pyis the script that handles any requests for serving.necessities.txtis the textual content file containing any further pip wheels to put in.
If you wish to obtain the mannequin from Hugging Face instantly, you possibly can set the choice.model_id parameter within the serving.properties file because the mannequin id of a pre-trained mannequin hosted inside a mannequin repository on huggingface.co. The container makes use of this mannequin id to obtain the corresponding mannequin throughout deployment time. For those who set the model_id to an Amazon Simple Storage Service (Amazon S3) URL, the DJL will obtain the mannequin artifacts from Amazon S3 and swap the model_id to the precise location of the mannequin artifacts. In your script, you possibly can level to this worth to load the pre-trained mannequin. In our instance, we use the latter choice, as a result of the LMI container makes use of s5cmd to obtain knowledge from Amazon S3, which considerably reduces the velocity when loading fashions throughout deployment. See the next code:
Within the model.py script, we load the mannequin path utilizing the mannequin ID supplied within the property file:
After the mannequin artifacts are ready and uploaded to Amazon S3, you possibly can deploy the CLIP mannequin to SageMaker internet hosting with a number of strains of code:
When the endpoint is in service, you possibly can invoke the endpoint with an enter picture and a listing of labels because the enter immediate to generate the label possibilities:
Use case 2: Automated immediate era from photographs
One revolutionary utility utilizing the multimodality fashions is to generate informative prompts from a picture. In generative AI, a immediate refers back to the enter supplied to a language mannequin or different generative mannequin to instruct it on what sort of content material or response is desired. The immediate is basically a place to begin or a set of directions that guides the mannequin’s era course of. It may possibly take the type of a sentence, query, partial textual content, or any enter that conveys the context or desired output to the mannequin. The selection of a well-crafted immediate is pivotal in producing high-quality photographs with precision and relevance. Prompt engineering is the method of optimizing or crafting a textual enter to realize desired responses from a language mannequin, typically involving wording, format, or context changes.
Immediate engineering for picture era poses a number of challenges, together with the next:
- Defining visible ideas precisely – Describing visible ideas in phrases can generally be imprecise or ambiguous, making it troublesome to convey the precise picture desired. Capturing intricate particulars or complicated scenes by way of textual prompts may not be simple.
- Specifying desired kinds successfully – Speaking particular stylistic preferences, equivalent to temper, coloration palette, or creative model, might be difficult by way of textual content alone. Translating summary aesthetic ideas into concrete directions for the mannequin might be tough.
- Balancing complexity to stop overloading the mannequin – Elaborate prompts might confuse the mannequin or result in overloading it with info, affecting the generated output. Hanging the correct stability between offering adequate steerage and avoiding overwhelming complexity is important.
Due to this fact, crafting efficient prompts for picture era is time consuming, which requires iterative experimentation and refining to strike the correct stability between precision and creativity, making it a resource-intensive activity that closely depends on human experience.
The CLIP Interrogator is an computerized immediate engineering device for photographs that mixes CLIP and BLIP to optimize textual content prompts to match a given picture. You need to use the ensuing prompts with text-to-image fashions like Stable Diffusion to create cool artwork. The prompts created by CLIP Interrogator supply a complete description of the picture, overlaying not solely its basic components but in addition the creative model, the potential inspiration behind the picture, the medium the place the picture might have been or may be used, and past. You possibly can simply deploy the CLIP Interrogator resolution on SageMaker to streamline the deployment course of, and benefit from the scalability, cost-efficiency, and sturdy safety supplied by the absolutely managed service. The next diagram reveals the movement logic of this resolution.

You need to use the next notebook to deploy the CLIP Interrogator resolution on SageMaker. Equally, for CLIP mannequin internet hosting, we use the SageMaker LMI container to host the answer on SageMaker utilizing DJL Serving. On this instance, we supplied a further enter file with the mannequin artifacts that specifies the fashions deployed to the SageMaker endpoint. You possibly can select totally different CLIP or BLIP fashions by passing the caption mannequin identify and the clip mannequin identify by way of the model_name.json file created with the next code:
The inference script mannequin.py comprises a deal with perform that DJL Serving will run your request by invoking this perform. To organize this entry level script, we adopted the code from the unique clip_interrogator.py file and modified it to work with DJL Serving on SageMaker internet hosting. One replace is the loading of the BLIP mannequin. The BLIP and CLIP fashions are loaded by way of the load_caption_model() and load_clip_model() perform throughout the initialization of the Interrogator object. To load the BLIP mannequin, we first downloaded the mannequin artifacts from Hugging Face and uploaded them to Amazon S3 because the goal worth of the model_id within the properties file. It is because the BLIP mannequin generally is a massive file, such because the blip2-opt-2.7b mannequin, which is greater than 15 GB in measurement. Downloading the mannequin from Hugging Face throughout mannequin deployment would require extra time for endpoint creation. Due to this fact, we level the model_id to the Amazon S3 location of the BLIP2 mannequin and cargo the mannequin from the mannequin path specified within the properties file. Word that, throughout deployment, the mannequin path shall be swapped to the native container path the place the mannequin artifacts have been downloaded to by DJL Serving from the Amazon S3 location. See the next code:
As a result of the CLIP mannequin isn’t very massive in measurement, we use open_clip to load the mannequin instantly from Hugging Face, which is similar as the unique clip_interrogator implementation:
We use related code to deploy the CLIP Interrogator resolution to a SageMaker endpoint and invoke the endpoint with an enter picture to get the prompts that can be utilized to generate related photographs.
Let’s take the next picture for instance. Utilizing the deployed CLIP Interrogator endpoint on SageMaker, it generates the next textual content description: croissant on a plate, pexels contest winner, facet ratio 16:9, cgsocietywlop, 8 h, golden cracks, the artist has used shiny, image of a loft in morning, object options, stylized border, pastry, french emperor.

We will additional mix the CLIP Interrogator resolution with Steady Diffusion and immediate engineering strategies—a complete new dimension of artistic prospects emerges. This integration permits us to not solely describe photographs with textual content, but in addition manipulate and generate various variations of the unique photographs. Steady Diffusion ensures managed picture synthesis by iteratively refining the generated output, and strategic immediate engineering guides the era course of in direction of desired outcomes.
Within the second part of the notebook, we element the steps to make use of immediate engineering to restyle photographs with the Steady Diffusion mannequin (Stable Diffusion XL 1.0). We use the Stability AI SDK to deploy this mannequin from SageMaker JumpStart after subscribing to this mannequin on the AWS marketplace. As a result of it is a newer and higher model for picture era supplied by Stability AI, we will get high-quality photographs based mostly on the unique enter picture. Moreover, if we prefix the previous description and add a further immediate mentioning a identified artist and considered one of his works, we get superb outcomes with restyling. The next picture makes use of the immediate: This scene is a Van Gogh portray with The Starry Evening model, croissant on a plate, pexels contest winner, facet ratio 16:9, cgsocietywlop, 8 h, golden cracks, the artist has used shiny, image of a loft in morning, object options, stylized border, pastry, french emperor.

The next picture makes use of the immediate: This scene is a Hokusai portray with The Nice Wave off Kanagawa model, croissant on a plate, pexels contest winner, facet ratio 16:9, cgsocietywlop, 8 h, golden cracks, the artist has used shiny, image of a loft in morning, object options, stylized border, pastry, french emperor.

Conclusion
The emergence of multimodality fashions, like CLIP and BLIP, and their purposes are quickly reworking the panorama of image-to-text conversion. Bridging the hole between visible and semantic info, they’re offering us with the instruments to unlock the huge potential of visible knowledge and harness it in ways in which have been beforehand unimaginable.
On this submit, we illustrated totally different purposes of the multimodality fashions. These vary from enhancing the effectivity and accuracy of search in ecommerce platforms by way of computerized tagging and categorization to the era of prompts for text-to-image fashions like Steady Diffusion. These purposes open new horizons for creating distinctive and interesting content material. We encourage you to study extra by exploring the varied multimodality fashions on SageMaker and construct an answer that’s revolutionary to your online business.
In regards to the Authors
 Yanwei Cui, PhD, is a Senior Machine Studying Specialist Options Architect at AWS. He began machine studying analysis at IRISA (Analysis Institute of Pc Science and Random Techniques), and has a number of years of expertise constructing AI-powered industrial purposes in pc imaginative and prescient, pure language processing, and on-line person conduct prediction. At AWS, he shares his area experience and helps clients unlock enterprise potentials and drive actionable outcomes with machine studying at scale. Exterior of labor, he enjoys studying and touring.
Yanwei Cui, PhD, is a Senior Machine Studying Specialist Options Architect at AWS. He began machine studying analysis at IRISA (Analysis Institute of Pc Science and Random Techniques), and has a number of years of expertise constructing AI-powered industrial purposes in pc imaginative and prescient, pure language processing, and on-line person conduct prediction. At AWS, he shares his area experience and helps clients unlock enterprise potentials and drive actionable outcomes with machine studying at scale. Exterior of labor, he enjoys studying and touring.
 Raghu Ramesha is a Senior ML Options Architect with the Amazon SageMaker Service staff. He focuses on serving to clients construct, deploy, and migrate ML manufacturing workloads to SageMaker at scale. He focuses on machine studying, AI, and pc imaginative and prescient domains, and holds a grasp’s diploma in Pc Science from UT Dallas. In his free time, he enjoys touring and pictures.
Raghu Ramesha is a Senior ML Options Architect with the Amazon SageMaker Service staff. He focuses on serving to clients construct, deploy, and migrate ML manufacturing workloads to SageMaker at scale. He focuses on machine studying, AI, and pc imaginative and prescient domains, and holds a grasp’s diploma in Pc Science from UT Dallas. In his free time, he enjoys touring and pictures.
 Sam Edwards, is a Cloud Engineer (AI/ML) at AWS Sydney specialised in machine studying and Amazon SageMaker. He’s enthusiastic about serving to clients remedy points associated to machine studying workflows and creating new options for them. Exterior of labor, he enjoys taking part in racquet sports activities and touring.
Sam Edwards, is a Cloud Engineer (AI/ML) at AWS Sydney specialised in machine studying and Amazon SageMaker. He’s enthusiastic about serving to clients remedy points associated to machine studying workflows and creating new options for them. Exterior of labor, he enjoys taking part in racquet sports activities and touring.
 Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based mostly in Sydney, Australia. She helps enterprise clients construct options utilizing state-of-the-art AI/ML instruments on AWS and offers steerage on architecting and implementing ML options with greatest practices. In her spare time, she likes to discover nature and spend time with household and associates.
Melanie Li, PhD, is a Senior AI/ML Specialist TAM at AWS based mostly in Sydney, Australia. She helps enterprise clients construct options utilizing state-of-the-art AI/ML instruments on AWS and offers steerage on architecting and implementing ML options with greatest practices. In her spare time, she likes to discover nature and spend time with household and associates.
 Gordon Wang is a Senior AI/ML Specialist TAM at AWS. He helps strategic clients with AI/ML greatest practices cross many industries. He’s enthusiastic about pc imaginative and prescient, NLP, generative AI, and MLOps. In his spare time, he loves working and mountaineering.
Gordon Wang is a Senior AI/ML Specialist TAM at AWS. He helps strategic clients with AI/ML greatest practices cross many industries. He’s enthusiastic about pc imaginative and prescient, NLP, generative AI, and MLOps. In his spare time, he loves working and mountaineering.
 Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from massive enterprises to mid-sized startups on issues associated to distributed computing, and Synthetic Intelligence. He focuses on Deep studying together with NLP and Pc Imaginative and prescient domains. He helps clients obtain excessive efficiency mannequin inference on SageMaker.
Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from massive enterprises to mid-sized startups on issues associated to distributed computing, and Synthetic Intelligence. He focuses on Deep studying together with NLP and Pc Imaginative and prescient domains. He helps clients obtain excessive efficiency mannequin inference on SageMaker.