Few-click segmentation masks labeling in Amazon SageMaker Floor Fact Plus

Amazon SageMaker Ground Truth Plus is a managed information labeling service that makes it simple to label information for machine studying (ML) purposes. One widespread use case is semantic segmentation, which is a pc imaginative and prescient ML approach that includes assigning class labels to particular person pixels in a picture. For instance, in video frames captured by a transferring car, class labels can embody automobiles, pedestrians, roads, visitors indicators, buildings, or backgrounds. It offers a high-precision understanding of the places of various objects within the picture and is usually used to construct notion programs for autonomous automobiles or robotics. To construct an ML mannequin for semantic segmentation, it’s first essential to label a big quantity of information on the pixel stage. This labeling course of is complicated. It requires expert labelers and important time—some photos can take as much as 2 hours or extra to label precisely!
In 2019, we released an ML-powered interactive labeling tool called Auto-segment for Ground Truth that lets you shortly and simply create high-quality segmentation masks. For extra data, see Auto-Segmentation Tool. This function works by permitting you to click on the top-, left-, bottom-, and right-most “excessive factors” on an object. An ML mannequin working within the background will ingest this person enter and return a high-quality segmentation masks that instantly renders within the Floor Fact labeling device. Nonetheless, this function solely lets you place 4 clicks. In sure instances, the ML-generated masks might inadvertently miss sure parts of a picture, similar to across the object boundary the place edges are vague or the place colour, saturation, or shadows mix into the environment.
Excessive level clicking with a versatile variety of corrective clicks
We now have enhanced the device to permit additional clicks of boundary factors, which offers real-time suggestions to the ML mannequin. This lets you create a extra correct segmentation masks. Within the following instance, the preliminary segmentation end result isn’t correct due to the weak boundaries close to the shadow. Importantly, this device operates in a mode that permits for real-time suggestions—it doesn’t require you to specify all factors directly. As a substitute, you possibly can first make 4 mouse clicks, which can set off the ML mannequin to provide a segmentation masks. Then you possibly can examine this masks, find any potential inaccuracies, and subsequently place extra clicks as applicable to “nudge” the mannequin into the right end result.

Our earlier labeling device allowed you to position precisely 4 mouse clicks (purple dots). The preliminary segmentation end result (shaded purple space) isn’t correct due to the weak boundaries close to the shadow (bottom-left of purple masks).
With our enhanced labeling device, the person once more first makes 4 mouse clicks (purple dots in high determine). Then you might have the chance to examine the ensuing segmentation masks (shaded purple space in high determine). You may make extra mouse clicks (inexperienced dots in backside determine) to trigger the mannequin to refine the masks (shaded purple space in backside determine).

In contrast with the unique model of the device, the improved model offers an improved end result when objects are deformable, non-convex, and fluctuate in form and look.
We simulated the efficiency of this improved device on pattern information by first working the baseline device (with solely 4 excessive clicks) to generate a segmentation masks and evaluated its imply Intersection over Union (mIoU), a typical measure of accuracy for segmentation masks. Then we utilized simulated corrective clicks and evaluated the advance in mIoU after every simulated click on. The next desk summarizes these outcomes. The primary row reveals the mIoU, and the second row reveals the error (which is given by 100% minus the mIoU). With solely 5 extra mouse clicks, we will scale back the error by 9% for this activity!
| . | . | Variety of Corrective Clicks | . | |||
| . | Baseline | 1 | 2 | 3 | 4 | 5 |
| mIoU | 72.72 | 76.56 | 77.62 | 78.89 | 80.57 | 81.73 |
| Error | 27% | 23% | 22% | 21% | 19% | 18% |
Integration with Floor Fact and efficiency profiling
To combine this mannequin with Floor Fact, we observe a normal structure sample as proven within the following diagram. First, we construct the ML mannequin right into a Docker picture and deploy it to Amazon Elastic Container Registry (Amazon ECR), a totally managed Docker container registry that makes it simple to retailer, share, and deploy container photos. Utilizing the SageMaker Inference Toolkit in constructing the Docker picture permits us to simply use finest practices for mannequin serving and obtain low-latency inference. We then create an Amazon SageMaker real-time endpoint to host the mannequin. We introduce an AWS Lambda operate as a proxy in entrance of the SageMaker endpoint to supply varied varieties of information transformation. Lastly, we use Amazon API Gateway as a manner of integrating with our entrance finish, the Floor Fact labeling software, to supply safe authentication to our backend.
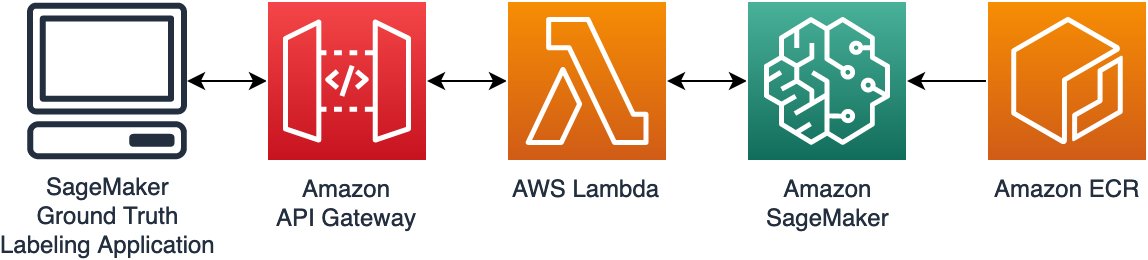
You’ll be able to observe this generic sample in your personal use instances for purpose-built ML instruments and to combine them with customized Floor Fact activity UIs. For extra data, consult with Build a custom data labeling workflow with Amazon SageMaker Ground Truth.
After provisioning this structure and deploying our mannequin utilizing the AWS Cloud Development Kit (AWS CDK), we evaluated the latency traits of our mannequin with totally different SageMaker occasion sorts. That is very simple to do as a result of we use SageMaker real-time inference endpoints to serve our mannequin. SageMaker real-time inference endpoints combine seamlessly with Amazon CloudWatch and emit such metrics as reminiscence utilization and mannequin latency with no required setup (see SageMaker Endpoint Invocation Metrics for extra particulars).
Within the following determine, we present the ModelLatency metric natively emitted by SageMaker real-time inference endpoints. We are able to simply use varied metric math features in CloudWatch to point out latency percentiles, similar to p50 or p90 latency.
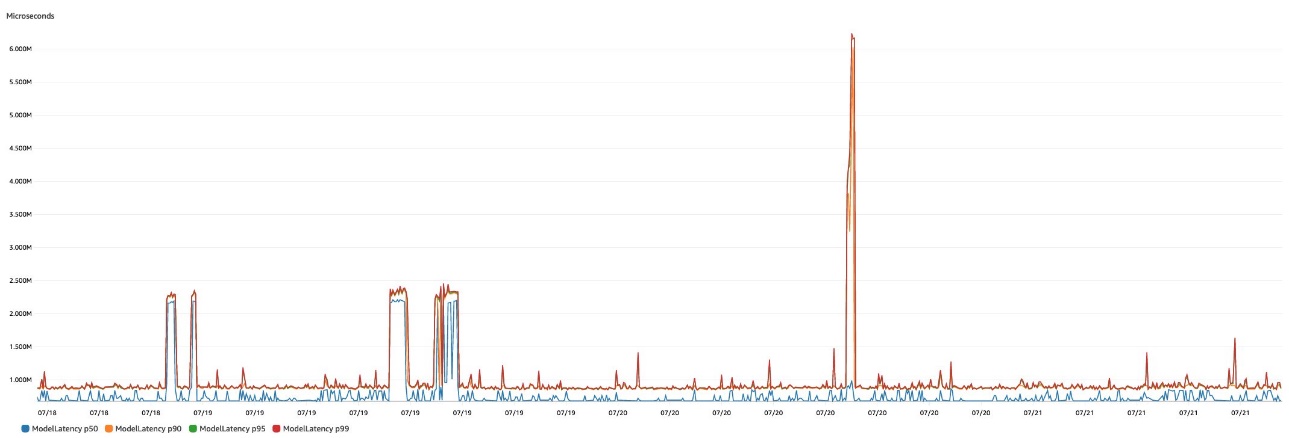
The next desk summarizes these outcomes for our enhanced excessive clicking device for semantic segmentation for 3 occasion sorts: p2.xlarge, p3.2xlarge, and g4dn.xlarge. Though the p3.2xlarge occasion offers the bottom latency, the g4dn.xlarge occasion offers one of the best cost-to-performance ratio. The g4dn.xlarge occasion is simply 8% slower (35 milliseconds) than the p3.2xlarge occasion, however it’s 81% cheaper on an hourly foundation than the p3.2xlarge (see Amazon SageMaker Pricing for extra particulars on SageMaker occasion sorts and pricing).
| SageMaker Occasion Sort | p90 Latency (ms) | |
| 1 | p2.xlarge | 751 |
| 2 | p3.2xlarge | 424 |
| 3 | g4dn.xlarge | 459 |
Conclusion
On this publish, we launched an extension to the Floor Fact auto section function for semantic segmentation annotation duties. Whereas the unique model of the device lets you make precisely 4 mouse clicks, which triggers a mannequin to supply a high-quality segmentation masks, the extension lets you make corrective clicks and thereby replace and information the ML mannequin to make higher predictions. We additionally offered a primary architectural sample that you should utilize to deploy and combine interactive instruments into Floor Fact labeling UIs. Lastly, we summarized the mannequin latency, and confirmed how the usage of SageMaker real-time inference endpoints makes it simple to observe mannequin efficiency.
To be taught extra about how this device can scale back labeling value and improve accuracy, go to Amazon SageMaker Data Labeling to start out a session right this moment.
Concerning the authors
 Jonathan Buck is a Software program Engineer at Amazon Internet Companies working on the intersection of machine studying and distributed programs. His work includes productionizing machine studying fashions and growing novel software program purposes powered by machine studying to place the newest capabilities within the palms of consumers.
Jonathan Buck is a Software program Engineer at Amazon Internet Companies working on the intersection of machine studying and distributed programs. His work includes productionizing machine studying fashions and growing novel software program purposes powered by machine studying to place the newest capabilities within the palms of consumers.
 Li Erran Li is the utilized science supervisor at humain-in-the-loop companies, AWS AI, Amazon. His analysis pursuits are 3D deep studying, and imaginative and prescient and language illustration studying. Beforehand he was a senior scientist at Alexa AI, the pinnacle of machine studying at Scale AI and the chief scientist at Pony.ai. Earlier than that, he was with the notion group at Uber ATG and the machine studying platform group at Uber engaged on machine studying for autonomous driving, machine studying programs and strategic initiatives of AI. He began his profession at Bell Labs and was adjunct professor at Columbia College. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized a number of workshops at NeurIPS, ICML, CVPR, ICCV on machine studying for autonomous driving, 3D imaginative and prescient and robotics, machine studying programs and adversarial machine studying. He has a PhD in pc science at Cornell College. He’s an ACM Fellow and IEEE Fellow.
Li Erran Li is the utilized science supervisor at humain-in-the-loop companies, AWS AI, Amazon. His analysis pursuits are 3D deep studying, and imaginative and prescient and language illustration studying. Beforehand he was a senior scientist at Alexa AI, the pinnacle of machine studying at Scale AI and the chief scientist at Pony.ai. Earlier than that, he was with the notion group at Uber ATG and the machine studying platform group at Uber engaged on machine studying for autonomous driving, machine studying programs and strategic initiatives of AI. He began his profession at Bell Labs and was adjunct professor at Columbia College. He co-taught tutorials at ICML’17 and ICCV’19, and co-organized a number of workshops at NeurIPS, ICML, CVPR, ICCV on machine studying for autonomous driving, 3D imaginative and prescient and robotics, machine studying programs and adversarial machine studying. He has a PhD in pc science at Cornell College. He’s an ACM Fellow and IEEE Fellow.





