This AI Analysis Evaluates the Correctness and Faithfulness of Instruction-Following Fashions For Their Capability To Carry out Query-Answering
Not too long ago launched Massive Language Fashions (LLMs) have taken the Synthetic Intelligence (AI) group by storm. These fashions have been capable of efficiently imitate human beings by utilizing super-good Pure Language Processing (NLP), Pure Language Era (NLG) and Pure Language Understanding (NLU). LLMs have change into well-known for imitating people for having reasonable conversations and are able to answering easy and complicated questions, content material era, code completion, machine translation, and textual content summarization. The objective of NLP is to make it doable for pc techniques to understand and react to instructions given in pure language, enabling folks to interact with them in a extra pure and versatile method, the very best instance of which is the instruction following fashions.
These fashions are skilled utilizing LLMs, supervised examples, or different kinds of supervision, and publicity to hundreds of duties written as pure language directions. In current analysis, a group from Mila Quebec AI Institute, McGill College, and Fb CIFAR AI Chair has researched evaluating the efficiency of instruction-following fashions for his or her means to carry out question-answering (QA) on a given set of textual content passages. These fashions can reply questions when supplied with a immediate describing the duty, the query, and related textual content passages retrieved by a retriever, and the responses produced by these fashions are recognized to be pure and informative, which helps construct customers’ belief and engagement.
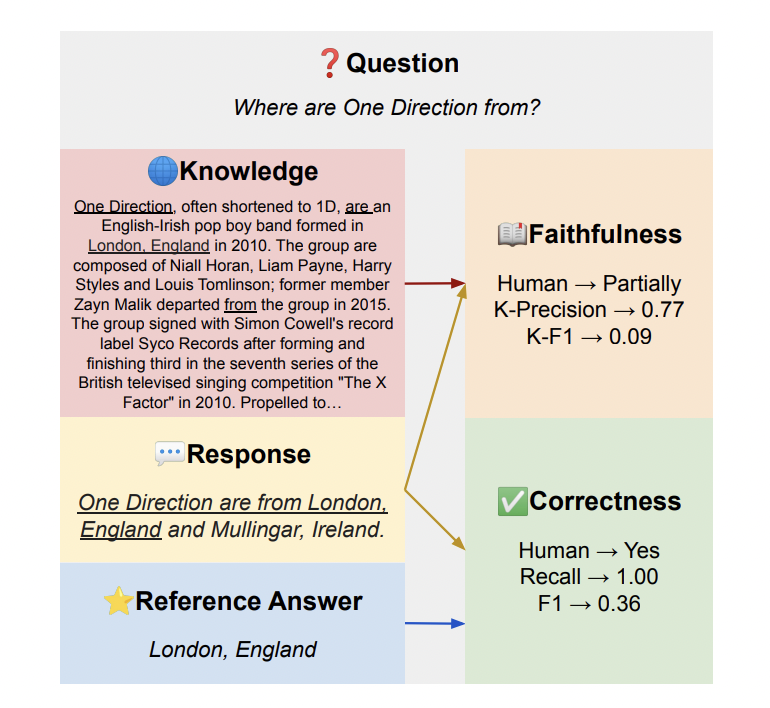
These fashions can reply to person queries naturally and fluently by solely including retrieved paperwork and directions to their enter. Nevertheless, this additional verbosity makes it tough for standard QA analysis metrics like actual match (EM) and F1 rating to successfully quantify mannequin efficiency. That is as a result of risk that the mannequin’s response might embrace extra particulars that the reference reply omits whereas nonetheless being correct. The group has offered two standards for measuring instruction-following fashions in retrieval-augmented high quality assurance (QA) with a purpose to overcome this drawback.
- Concerning info necessity, accuracy: This dimension evaluates how effectively the mannequin satisfies the informational necessities of a person. It’s involved with whether or not the generated response contains pertinent info, even when it goes past what’s talked about immediately within the reference reply.
- Constancy in relation to info offered: This dimension assesses how effectively the mannequin grounds solutions within the data introduced. A real mannequin ought to chorus from responding when irrelevant info is introduced, along with giving exact solutions when it’s accessible.
The authors have evaluated a number of current instruction-following fashions on three various QA datasets: Pure Questions for open-domain QA, HotpotQA for multi-hop QA, and TopiOCQA for conversational QA. They analyzed 900 mannequin responses manually and in contrast the outcomes with completely different computerized metrics for accuracy and faithfulness. Their analysis has instructed that recall, which measures the share of tokens from the reference reply which can be additionally current within the mannequin response, correlates extra strongly with correctness than lexical overlap metrics like EM or F1 rating. In comparison with different token-overlap metrics for faithfulness, Okay-Precision, which is the share of mannequin reply tokens that exist within the data snippet, has a stronger correlation with human judgments.
In conclusion, this examine seeks to advance a extra thorough evaluation of instruction-following fashions for QA duties, making an allowance for each their benefits and downsides. The group has promoted further development on this space by making their code and knowledge accessible on their GitHub repository
Try the Paper, GitHub, and Tweet. All Credit score For This Analysis Goes To the Researchers on This Challenge. Additionally, don’t overlook to affix our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, the place we share the most recent AI analysis information, cool AI initiatives, and extra.
Tanya Malhotra is a last 12 months undergrad from the College of Petroleum & Power Research, Dehradun, pursuing BTech in Laptop Science Engineering with a specialization in Synthetic Intelligence and Machine Studying.
She is a Information Science fanatic with good analytical and important pondering, together with an ardent curiosity in buying new expertise, main teams, and managing work in an organized method.





