Consideration-based Picture Captioning with Keras
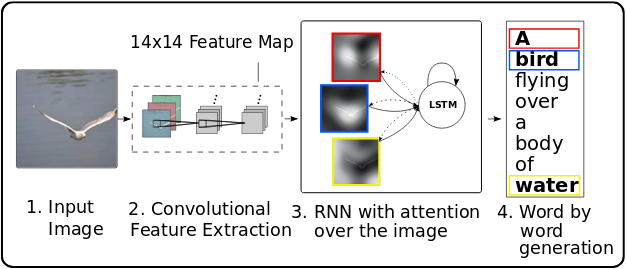
In picture captioning, an algorithm is given a picture and tasked with producing a smart caption. It’s a difficult process for a number of causes, not the least being that it includes a notion of saliency or relevance. For this reason current deep studying approaches largely embrace some “consideration” mechanism (typically even a couple of) to assist specializing in related picture options.
On this publish, we reveal a formulation of picture captioning as an encoder-decoder drawback, enhanced by spatial consideration over picture grid cells. The concept comes from a current paper on Neural Picture Caption Era with Visible Consideration (Xu et al. 2015), and employs the identical type of consideration algorithm as detailed in our publish on machine translation.
We’re porting Python code from a current Google Colaboratory notebook, utilizing Keras with TensorFlow keen execution to simplify our lives.
Conditions
The code proven right here will work with the present CRAN variations of tensorflow, keras, and tfdatasets.
Test that you simply’re utilizing a minimum of model 1.9 of TensorFlow. If that isn’t the case, as of this writing, this
will get you model 1.10.
When loading libraries, please ensure you’re executing the primary 4 traces on this actual order.
We’d like to verify we’re utilizing the TensorFlow implementation of Keras (tf.keras in Python land), and now we have to allow keen execution earlier than utilizing TensorFlow in any method.
No must copy-paste any code snippets – you’ll discover the whole code (so as vital for execution) right here: eager-image-captioning.R.
The dataset
MS-COCO (“Frequent Objects in Context”) is considered one of, maybe the, reference dataset in picture captioning (object detection and segmentation, too).
We’ll be utilizing the training images and annotations from 2014 – be warned, relying in your location, the obtain can take a lengthy time.
After unpacking, let’s outline the place the pictures and captions are.
annotation_file <- "train2014/annotations/captions_train2014.json"
image_path <- "train2014/train2014"The annotations are in JSON format, and there are 414113 of them! Fortunately for us we didn’t must obtain that many photographs – each picture comes with 5 totally different captions, for higher generalizability.
annotations <- fromJSON(file = annotation_file)
annot_captions <- annotations[[4]]
num_captions <- length(annot_captions)We retailer each annotations and picture paths in lists, for later loading.
all_captions <- vector(mode = "checklist", size = num_captions)
all_img_names <- vector(mode = "checklist", size = num_captions)
for (i in seq_len(num_captions)) {
caption <- paste0("<begin> ",
annot_captions[[i]][["caption"]],
" <finish>"
)
image_id <- annot_captions[[i]][["image_id"]]
full_coco_image_path <- sprintf(
"%s/COCO_train2014_percent012d.jpg",
image_path,
image_id
)
all_img_names[[i]] <- full_coco_image_path
all_captions[[i]] <- caption
}Relying in your computing setting, you’ll for positive wish to limit the variety of examples used.
This publish will use 30000 captioned photographs, chosen randomly, and put aside 20% for validation.
Under, we take random samples, break up into coaching and validation elements. The companion code may even retailer the indices on disk, so you possibly can decide up on verification and evaluation later.
num_examples <- 30000
random_sample <- sample(1:num_captions, dimension = num_examples)
train_indices <- sample(random_sample, dimension = length(random_sample) * 0.8)
validation_indices <- setdiff(random_sample, train_indices)
sample_captions <- all_captions[random_sample]
sample_images <- all_img_names[random_sample]
train_captions <- all_captions[train_indices]
train_images <- all_img_names[train_indices]
validation_captions <- all_captions[validation_indices]
validation_images <- all_img_names[validation_indices]Interlude
Earlier than actually diving into the technical stuff, let’s take a second to mirror on this process.
In typical image-related deep studying walk-throughs, we’re used to seeing well-defined issues – even when in some circumstances, the answer could also be exhausting. Take, for instance, the stereotypical canine vs. cat drawback. Some canines could seem like cats and a few cats could seem like canines, however that’s about it: All in all, within the standard world we reside in, it ought to be a kind of binary query.
If, however, we ask folks to explain what they see in a scene, it’s to be anticipated from the outset that we’ll get totally different solutions. Nonetheless, how a lot consensus there’s will very a lot depend upon the concrete dataset we’re utilizing.
Let’s check out some picks from the very first 20 coaching objects sampled randomly above.

Now this picture doesn’t depart a lot room for choice what to deal with, and obtained a really factual caption certainly: “There’s a plate with one slice of bacon a half of orange and bread.” If the dataset have been all like this, we’d suppose a machine studying algorithm ought to do fairly properly right here.
Choosing one other one from the primary 20:

What can be salient info to you right here? The caption offered goes “A smiling little boy has a checkered shirt.”
Is the look of the shirt as vital as that? You may as properly deal with the surroundings, – and even one thing on a totally totally different degree: The age of the picture, or it being an analog one.
Let’s take a closing instance.

What would you say about this scene? The official label we sampled right here is “A bunch of individuals posing in a humorous method for the digital camera.” Nicely …
Please don’t overlook that for every picture, the dataset consists of 5 totally different captions (though our n = 30000 samples most likely gained’t).
So this isn’t saying the dataset is biased – in no way. As an alternative, we wish to level out the ambiguities and difficulties inherent within the process. Really, given these difficulties, it’s all of the extra superb that the duty we’re tackling right here – having a community robotically generate picture captions – ought to be doable in any respect!
Now let’s see how we will do that.
For the encoding a part of our encoder-decoder community, we’ll make use of InceptionV3 to extract picture options. In precept, which options to extract is as much as experimentation, – right here we simply use the final layer earlier than the absolutely linked prime:
image_model <- application_inception_v3(
include_top = FALSE,
weights = "imagenet"
)For a picture dimension of 299×299, the output will likely be of dimension (batch_size, 8, 8, 2048), that’s, we’re making use of 2048 characteristic maps.
InceptionV3 being a “large mannequin,” the place each move by means of the mannequin takes time, we wish to precompute options prematurely and retailer them on disk.
We’ll use tfdatasets to stream photographs to the mannequin. This implies all our preprocessing has to make use of tensorflow features: That’s why we’re not utilizing the extra acquainted image_load from keras under.
Our customized load_image will learn in, resize and preprocess the pictures as required to be used with InceptionV3:
Now we’re prepared to save lots of the extracted options to disk. The (batch_size, 8, 8, 2048)-sized options will likely be flattened to (batch_size, 64, 2048). The latter form is what our encoder, quickly to be mentioned, will obtain as enter.
preencode <- unique(sample_images) %>% unlist() %>% sort()
num_unique <- length(preencode)
# adapt this in accordance with your system's capacities
batch_size_4save <- 1
image_dataset <-
tensor_slices_dataset(preencode) %>%
dataset_map(load_image) %>%
dataset_batch(batch_size_4save)
save_iter <- make_iterator_one_shot(image_dataset)
until_out_of_range({
save_count <- save_count + batch_size_4save
batch_4save <- save_iter$get_next()
img <- batch_4save[[1]]
path <- batch_4save[[2]]
batch_features <- image_model(img)
batch_features <- tf$reshape(
batch_features,
list(dim(batch_features)[1], -1L, dim(batch_features)[4]
)
)
for (i in 1:dim(batch_features)[1]) {
np$save(path[i]$numpy()$decode("utf-8"),
batch_features[i, , ]$numpy())
}
})Earlier than we get to the encoder and decoder fashions although, we have to handle the captions.
Processing the captions
We’re utilizing keras text_tokenizer and the textual content processing features texts_to_sequences and pad_sequences to rework ascii textual content right into a matrix.
# we'll use the 5000 most frequent phrases solely
top_k <- 5000
tokenizer <- text_tokenizer(
num_words = top_k,
oov_token = "<unk>",
filters = '!"#$%&()*+.,-/:;=?@[]^_`~ ')
tokenizer$fit_on_texts(sample_captions)
train_captions_tokenized <-
tokenizer %>% texts_to_sequences(train_captions)
validation_captions_tokenized <-
tokenizer %>% texts_to_sequences(validation_captions)
# pad_sequences will use 0 to pad all captions to the identical size
tokenizer$word_index["<pad>"] <- 0
# create a lookup dataframe that enables us to go in each instructions
word_index_df <- data.frame(
phrase = tokenizer$word_index %>% names(),
index = tokenizer$word_index %>% unlist(use.names = FALSE),
stringsAsFactors = FALSE
)
word_index_df <- word_index_df %>% arrange(index)
decode_caption <- perform(textual content) {
paste(map(textual content, perform(quantity)
word_index_df %>%
filter(index == quantity) %>%
select(phrase) %>%
pull()),
collapse = " ")
}
# pad all sequences to the identical size (the utmost size, in our case)
# might experiment with shorter padding (truncating the very longest captions)
caption_lengths <- map(
all_captions[1:num_examples],
perform(c) str_split(c," ")[[1]] %>% length()
) %>% unlist()
max_length <- fivenum(caption_lengths)[5]
train_captions_padded <- pad_sequences(
train_captions_tokenized,
maxlen = max_length,
padding = "publish",
truncating = "publish"
)
validation_captions_padded <- pad_sequences(
validation_captions_tokenized,
maxlen = max_length,
padding = "publish",
truncating = "publish"
)Loading the info for coaching
Now that we’ve taken care of pre-extracting the options and preprocessing the captions, we’d like a technique to stream them to our captioning mannequin. For that, we’re utilizing tensor_slices_dataset from tfdatasets, passing within the checklist of paths to the pictures and the preprocessed captions. Loading the pictures is then carried out as a TensorFlow graph operation (utilizing tf$pyfunc).
The unique Colab code additionally shuffles the info on each iteration. Relying in your {hardware}, this may increasingly take a very long time, and given the dimensions of the dataset it isn’t strictly essential to get affordable outcomes. (The outcomes reported under have been obtained with out shuffling.)
batch_size <- 10
buffer_size <- num_examples
map_func <- perform(img_name, cap) {
p <- paste0(img_name$decode("utf-8"), ".npy")
img_tensor <- np$load(p)
img_tensor <- tf$forged(img_tensor, tf$float32)
list(img_tensor, cap)
}
train_dataset <-
tensor_slices_dataset(list(train_images, train_captions_padded)) %>%
dataset_map(
perform(item1, item2) tf$py_func(map_func, list(item1, item2), list(tf$float32, tf$int32))
) %>%
# optionally shuffle the dataset
# dataset_shuffle(buffer_size) %>%
dataset_batch(batch_size)Captioning mannequin
The mannequin is mainly the identical as that mentioned within the machine translation post. Please consult with that article for a proof of the ideas, in addition to an in depth walk-through of the tensor shapes concerned at each step. Right here, we offer the tensor shapes as feedback within the code snippets, for fast overview/comparability.
Nevertheless, in the event you develop your individual fashions, with keen execution you possibly can merely insert debugging/logging statements at arbitrary locations within the code – even in mannequin definitions. So you possibly can have a perform
And in the event you now set
you possibly can hint – not solely tensor shapes, however precise tensor values by means of your fashions, as proven under for the encoder. (We don’t show any debugging statements after that, however the sample code has many extra.)
Encoder
Now it’s time to outline some some sizing-related hyperparameters and housekeeping variables:
# for encoder output
embedding_dim <- 256
# decoder (LSTM) capability
gru_units <- 512
# for decoder output
vocab_size <- top_k
# variety of characteristic maps gotten from Inception V3
features_shape <- 2048
# form of consideration options (flattened from 8x8)
attention_features_shape <- 64The encoder on this case is only a absolutely linked layer, taking within the options extracted from Inception V3 (in flattened kind, as they have been written to disk), and embedding them in 256-dimensional area.
cnn_encoder <- perform(embedding_dim, title = NULL) {
keras_model_custom(title = title, perform(self) {
self$fc <- layer_dense(models = embedding_dim, activation = "relu")
perform(x, masks = NULL) {
# enter form: (batch_size, 64, features_shape)
maybecat("encoder enter", x)
# form after fc: (batch_size, 64, embedding_dim)
x <- self$fc(x)
maybecat("encoder output", x)
x
}
})
}Consideration module
In contrast to within the machine translation publish, right here the eye module is separated out into its personal customized mannequin.
The logic is similar although:
attention_module <- perform(gru_units, title = NULL) {
keras_model_custom(title = title, perform(self) {
self$W1 = layer_dense(models = gru_units)
self$W2 = layer_dense(models = gru_units)
self$V = layer_dense(models = 1)
perform(inputs, masks = NULL) {
options <- inputs[[1]]
hidden <- inputs[[2]]
# options(CNN_encoder output) form == (batch_size, 64, embedding_dim)
# hidden form == (batch_size, gru_units)
# hidden_with_time_axis form == (batch_size, 1, gru_units)
hidden_with_time_axis <- k_expand_dims(hidden, axis = 2)
# rating form == (batch_size, 64, 1)
rating <- self$V(k_tanh(self$W1(options) + self$W2(hidden_with_time_axis)))
# attention_weights form == (batch_size, 64, 1)
attention_weights <- k_softmax(rating, axis = 2)
# context_vector form after sum == (batch_size, embedding_dim)
context_vector <- k_sum(attention_weights * options, axis = 2)
list(context_vector, attention_weights)
}
})
}Decoder
The decoder at every time step calls the eye module with the options it acquired from the encoder and its final hidden state, and receives again an consideration vector. The eye vector will get concatenated with the present enter and additional processed by a GRU and two absolutely linked layers, the final of which supplies us the (unnormalized) possibilities for the following phrase within the caption.
The present enter at every time step right here is the earlier phrase: the proper one throughout coaching (instructor forcing), the final generated one throughout inference.
rnn_decoder <- perform(embedding_dim, gru_units, vocab_size, title = NULL) {
keras_model_custom(title = title, perform(self) {
self$gru_units <- gru_units
self$embedding <- layer_embedding(input_dim = vocab_size,
output_dim = embedding_dim)
self$gru <- if (tf$take a look at$is_gpu_available()) {
layer_cudnn_gru(
models = gru_units,
return_sequences = TRUE,
return_state = TRUE,
recurrent_initializer = 'glorot_uniform'
)
} else {
layer_gru(
models = gru_units,
return_sequences = TRUE,
return_state = TRUE,
recurrent_initializer = 'glorot_uniform'
)
}
self$fc1 <- layer_dense(models = self$gru_units)
self$fc2 <- layer_dense(models = vocab_size)
self$consideration <- attention_module(self$gru_units)
perform(inputs, masks = NULL) {
x <- inputs[[1]]
options <- inputs[[2]]
hidden <- inputs[[3]]
c(context_vector, attention_weights) %<-%
self$consideration(list(options, hidden))
# x form after passing by means of embedding == (batch_size, 1, embedding_dim)
x <- self$embedding(x)
# x form after concatenation == (batch_size, 1, 2 * embedding_dim)
x <- k_concatenate(list(k_expand_dims(context_vector, 2), x))
# passing the concatenated vector to the GRU
c(output, state) %<-% self$gru(x)
# form == (batch_size, 1, gru_units)
x <- self$fc1(output)
# x form == (batch_size, gru_units)
x <- k_reshape(x, c(-1, dim(x)[[3]]))
# output form == (batch_size, vocab_size)
x <- self$fc2(x)
list(x, state, attention_weights)
}
})
}Loss perform, and instantiating all of it
Now that we’ve outlined our mannequin (constructed of three customized fashions), we nonetheless want to really instantiate it (being exact: the 2 lessons we’ll entry from exterior, that’s, the encoder and the decoder).
We additionally must instantiate an optimizer (Adam will do), and outline our loss perform (categorical crossentropy).
Notice that tf$nn$sparse_softmax_cross_entropy_with_logits expects uncooked logits as an alternative of softmax activations, and that we’re utilizing the sparse variant as a result of our labels are usually not one-hot-encoded.
encoder <- cnn_encoder(embedding_dim)
decoder <- rnn_decoder(embedding_dim, gru_units, vocab_size)
optimizer = tf$practice$AdamOptimizer()
cx_loss <- perform(y_true, y_pred) {
masks <- 1 - k_cast(y_true == 0L, dtype = "float32")
loss <- tf$nn$sparse_softmax_cross_entropy_with_logits(
labels = y_true,
logits = y_pred
) * masks
tf$reduce_mean(loss)
}Coaching
Coaching the captioning mannequin is a time-consuming course of, and you’ll for positive wish to save the mannequin’s weights!
How does this work with keen execution?
We create a tf$practice$Checkpoint object, passing it the objects to be saved: In our case, the encoder, the decoder, and the optimizer. Later, on the finish of every epoch, we’ll ask it to put in writing the respective weights to disk.
restore_checkpoint <- FALSE
checkpoint_dir <- "./checkpoints_captions"
checkpoint_prefix <- file.path(checkpoint_dir, "ckpt")
checkpoint <- tf$practice$Checkpoint(
optimizer = optimizer,
encoder = encoder,
decoder = decoder
)As we’re simply beginning to practice the mannequin, restore_checkpoint is ready to false. Later, restoring the weights will likely be as simple as
if (restore_checkpoint) {
checkpoint$restore(tf$practice$latest_checkpoint(checkpoint_dir))
}The coaching loop is structured similar to within the machine translation case: We loop over epochs, batches, and the coaching targets, feeding within the right earlier phrase at each timestep.
Once more, tf$GradientTape takes care of recording the ahead move and calculating the gradients, and the optimizer applies the gradients to the mannequin’s weights.
As every epoch ends, we additionally save the weights.
num_epochs <- 20
if (!restore_checkpoint) {
for (epoch in seq_len(num_epochs)) {
total_loss <- 0
progress <- 0
train_iter <- make_iterator_one_shot(train_dataset)
until_out_of_range({
batch <- iterator_get_next(train_iter)
loss <- 0
img_tensor <- batch[[1]]
target_caption <- batch[[2]]
dec_hidden <- k_zeros(c(batch_size, gru_units))
dec_input <- k_expand_dims(
rep(list(word_index_df[word_index_df$word == "<start>", "index"]),
batch_size)
)
with(tf$GradientTape() %as% tape, {
options <- encoder(img_tensor)
for (t in seq_len(dim(target_caption)[2] - 1)) {
c(preds, dec_hidden, weights) %<-%
decoder(list(dec_input, options, dec_hidden))
loss <- loss + cx_loss(target_caption[, t], preds)
dec_input <- k_expand_dims(target_caption[, t])
}
})
total_loss <-
total_loss + loss / k_cast_to_floatx(dim(target_caption)[2])
variables <- c(encoder$variables, decoder$variables)
gradients <- tape$gradient(loss, variables)
optimizer$apply_gradients(purrr::transpose(list(gradients, variables)),
global_step = tf$practice$get_or_create_global_step()
)
})
cat(paste0(
"nnTotal loss (epoch): ",
epoch,
": ",
(total_loss / k_cast_to_floatx(buffer_size)) %>% as.double() %>% round(4),
"n"
))
checkpoint$save(file_prefix = checkpoint_prefix)
}
}Peeking at outcomes
Identical to within the translation case, it’s attention-grabbing to have a look at mannequin efficiency throughout coaching. The companion code has that performance built-in, so you possibly can watch mannequin progress for your self.
The fundamental perform right here is get_caption: It will get handed the trail to a picture, hundreds it, obtains its options from Inception V3, after which asks the encoder-decoder mannequin to generate a caption. If at any level the mannequin produces the finish image, we cease early. In any other case, we proceed till we hit the predefined most size.
get_caption <-
function(image) {
attention_matrix <-
matrix(0, nrow = max_length, ncol = attention_features_shape)
temp_input <- k_expand_dims(load_image(image)[[1]], 1)
img_tensor_val <- image_model(temp_input)
img_tensor_val <- k_reshape(
img_tensor_val,
list(dim(img_tensor_val)[1], -1, dim(img_tensor_val)[4])
)
features <- encoder(img_tensor_val)
dec_hidden <- k_zeros(c(1, gru_units))
dec_input <-
k_expand_dims(
list(word_index_df[word_index_df$word == "<start>", "index"])
)
result <- ""
for (t in seq_len(max_length - 1)) {
c(preds, dec_hidden, attention_weights) %<-%
decoder(list(dec_input, features, dec_hidden))
attention_weights <- k_reshape(attention_weights, c(-1))
attention_matrix[t,] <- attention_weights %>% as.double()
pred_idx <- tf$multinomial(exp(preds), num_samples = 1)[1, 1]
%>% as.double()
pred_word <-
word_index_df[word_index_df$index == pred_idx, "word"]
if (pred_word == "<end>") {
result <-
paste(result, pred_word)
attention_matrix <-
attention_matrix[1:length(str_split(result, " ")[[1]]), ,
drop = FALSE]
return (list(result, attention_matrix))
} else {
result <-
paste(result, pred_word)
dec_input <- k_expand_dims(list(pred_idx))
}
}
list(str_trim(result), attention_matrix)
}With that functionality, now let’s actually do that: peek at results while the network is learning!
We’ve picked 3 examples each from the training and validation sets. Here they are.
First, our picks from the training set:

Let’s see the target captions:
- a herd of giraffe standing on top of a grass covered field
- a view of cards driving down a street
- the skateboarding flips his board off of the sidewalk
Interestingly, here we also have a demonstration of how labeled datasets (like anything human) may contain errors. (The samples were not picked for that; instead, they were chosen – without too much screening – for being rather unequivocal in their visual content.)
Now for the validation candidates.

and their official captions:
- a left handed pitcher throwing the base ball
- a woman taking a bite of a slice of pizza in a restaraunt
- a woman hitting swinging a tennis racket at a tennis ball on a tennis court
(Again, any spelling peculiarities have not been introduced by us.)
Epoch 1
Now, what does our network produce after the first epoch? Remember that this means, having seen each one of the 24000 training images once.
First then, here are the captions for the train images:
a group of sheep standing in the grass
a group of cars driving down a street
a man is standing on a street
Not only is the syntax correct in every case, the content isn’t that bad either!
How about the validation set?
a baseball player is playing baseball uniform is holding a baseball bat
a man is holding a table with a table with a table with a table with a table with a table with a table with a table with a table with a table with a table with a table with a table with a table
a tennis player is holding a tennis court
This certainly tells that the network has been able to generalize over – let’s not call them concepts, but mappings between visual and textual entities, say It’s true that it will have seen some of these images before, because images come with several captions. You could be more strict setting up your training and validation sets – but here, we don’t really care about objective performance scores and so, it does not really matter.
Let’ skip directly to epoch 20, our last training epoch, and check for further improvements.
Epoch 20
This is what we get for the training images:
a group of many tall giraffe standing next to a sheep
a view of cards and white gloves on a street
a skateboarding flips his board
And this, for the validation images.
a baseball catcher and umpire hit a baseball game
a man is eating a sandwich
a female tennis player is in the court
I think we might agree that this still leaves room for improvement – but then, we only trained for 20 epochs and on a very small portion of the dataset.
In the above code snippets, you may have noticed the decoder returning an attention_matrix – but we weren’t commenting on it.
Now finally, just as in the translation example, have a look what we can make of that.
Where does the network look?
We can visualize where the network is “looking” as it generates each word by overlaying the original image and the attention matrix. This example is taken from the 4th epoch.
Here white-ish squares indicate areas receiving stronger focus. Compared to text-to-text translation though, the mapping is inherently less straightforward – where does one “look” when producing words like “and,” “the,” or “in?”

Conclusion
It probably goes without saying that much better results are to be expected when training on (much!) more data and for much more time.
Apart from that, there are other options, though. The concept implemented here uses spatial attention over a uniform grid, that is, the attention mechanism guides the decoder where on the grid to look next when generating a caption.
However, this is not the only way, and this is not how it works with humans. A much more plausible approach is a mix of top-down and bottom-up attention. E.g., (Anderson et al. 2017) use object detection strategies to bottom-up isolate attention-grabbing objects, and an LSTM stack whereby the primary LSTM computes top-down consideration guided by the output phrase generated by the second.
One other attention-grabbing strategy involving consideration is utilizing a multimodal attentive translator (Liu et al. 2017), the place the picture options are encoded and offered in a sequence, such that we find yourself with sequence fashions each on the encoding and the decoding sides.
One other different is so as to add a realized matter to the data enter (Zhu, Xue, and Yuan 2018), which once more is a top-down characteristic present in human cognition.
When you discover considered one of these, or yet one more, strategy extra convincing, an keen execution implementation, within the model of the above, will seemingly be a sound method of implementing it.






