How VMware constructed an MLOps pipeline from scratch utilizing GitLab, Amazon MWAA, and Amazon SageMaker

This publish is co-written with Mahima Agarwal, Machine Studying Engineer, and Deepak Mettem, Senior Engineering Supervisor, at VMware Carbon Black
VMware Carbon Black is a famend safety resolution providing safety towards the complete spectrum of contemporary cyberattacks. With terabytes of information generated by the product, the safety analytics staff focuses on constructing machine studying (ML) options to floor essential assaults and highlight rising threats from noise.
It’s essential for the VMware Carbon Black staff to design and construct a customized end-to-end MLOps pipeline that orchestrates and automates workflows within the ML lifecycle and permits mannequin coaching, evaluations, and deployments.
There are two essential functions for constructing this pipeline: help the info scientists for late-stage mannequin improvement, and floor mannequin predictions within the product by serving fashions in excessive quantity and in real-time manufacturing visitors. Subsequently, VMware Carbon Black and AWS selected to construct a customized MLOps pipeline utilizing Amazon SageMaker for its ease of use, versatility, and totally managed infrastructure. We orchestrate our ML coaching and deployment pipelines utilizing Amazon Managed Workflows for Apache Airflow (Amazon MWAA), which permits us to focus extra on programmatically authoring workflows and pipelines with out having to fret about auto scaling or infrastructure upkeep.
With this pipeline, what as soon as was Jupyter notebook-driven ML analysis is now an automatic course of deploying fashions to manufacturing with little handbook intervention from information scientists. Earlier, the method of coaching, evaluating, and deploying a mannequin might take over a day; with this implementation, every part is only a set off away and has decreased the general time to jiffy.
On this publish, VMware Carbon Black and AWS architects focus on how we constructed and managed customized ML workflows utilizing Gitlab, Amazon MWAA, and SageMaker. We focus on what we achieved up to now, additional enhancements to the pipeline, and classes realized alongside the best way.
Resolution overview
The next diagram illustrates the ML platform structure.
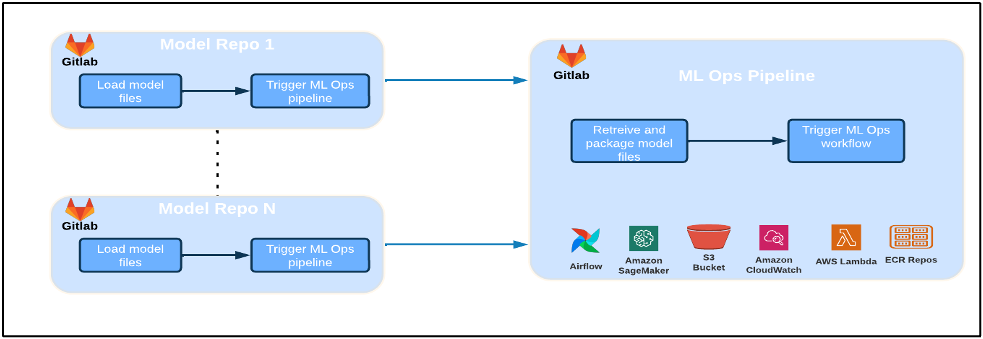
Excessive stage Resolution Design
This ML platform was envisioned and designed to be consumed by completely different fashions throughout numerous code repositories. Our staff makes use of GitLab as a supply code administration device to keep up all of the code repositories. Any modifications within the mannequin repository supply code are repeatedly built-in utilizing the Gitlab CI, which invokes the following workflows within the pipeline (mannequin coaching, analysis, and deployment).
The next structure diagram illustrates the end-to-end workflow and the elements concerned in our MLOps pipeline.
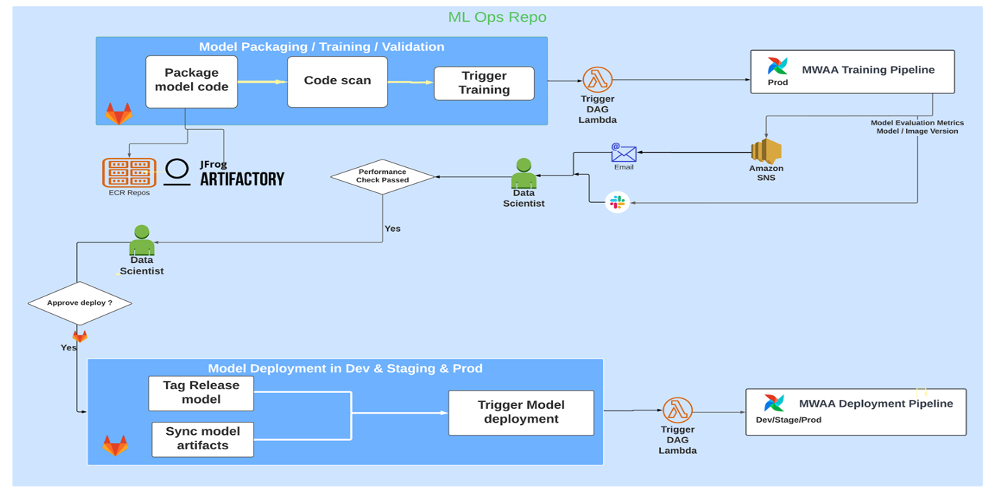
Finish-To-Finish Workflow
The ML mannequin coaching, analysis, and deployment pipelines are orchestrated utilizing Amazon MWAA, known as a Directed Acyclic Graph (DAG). A DAG is a group of duties collectively, organized with dependencies and relationships to say how they need to run.
At a excessive stage, the answer structure consists of three essential elements:
- ML pipeline code repository
- ML mannequin coaching and analysis pipeline
- ML mannequin deployment pipeline
Let’s focus on how these completely different elements are managed and the way they work together with one another.
ML pipeline code repository
After the mannequin repo integrates the MLOps repo as their downstream pipeline, and an information scientist commits code of their mannequin repo, a GitLab runner does normal code validation and testing outlined in that repo and triggers the MLOps pipeline primarily based on the code modifications. We use Gitlab’s multi-project pipeline to allow this set off throughout completely different repos.
The MLOps GitLab pipeline runs a sure set of phases. It conducts primary code validation utilizing pylint, packages the mannequin’s coaching and inference code inside the Docker picture, and publishes the container picture to Amazon Elastic Container Registry (Amazon ECR). Amazon ECR is a totally managed container registry providing high-performance internet hosting, so you’ll be able to reliably deploy utility photographs and artifacts wherever.
ML mannequin coaching and analysis pipeline
After the picture is printed, it triggers the coaching and analysis Apache Airflow pipeline by way of the AWS Lambda operate. Lambda is a serverless, event-driven compute service that permits you to run code for nearly any kind of utility or backend service with out provisioning or managing servers.
After the pipeline is efficiently triggered, it runs the Coaching and Analysis DAG, which in flip begins the mannequin coaching in SageMaker. On the finish of this coaching pipeline, the recognized consumer group will get a notification with the coaching and mannequin analysis outcomes over electronic mail by way of Amazon Simple Notification Service (Amazon SNS) and Slack. Amazon SNS is totally managed pub/sub service for A2A and A2P messaging.
After meticulous evaluation of the analysis outcomes, the info scientist or ML engineer can deploy the brand new mannequin if the efficiency of the newly skilled mannequin is best in comparison with the earlier model. The efficiency of the fashions is evaluated primarily based on the model-specific metrics (reminiscent of F1 rating, MSE, or confusion matrix).
ML mannequin deployment pipeline
To begin deployment, the consumer begins the GitLab job that triggers the Deployment DAG by way of the identical Lambda operate. After the pipeline runs efficiently, it creates or updates the SageMaker endpoint with the brand new mannequin. This additionally sends a notification with the endpoint particulars over electronic mail utilizing Amazon SNS and Slack.
Within the occasion of failure in both of the pipelines, customers are notified over the identical communication channels.
SageMaker affords real-time inference that’s ultimate for inference workloads with low latency and excessive throughput necessities. These endpoints are totally managed, load balanced, and auto scaled, and may be deployed throughout a number of Availability Zones for top availability. Our pipeline creates such an endpoint for a mannequin after it runs efficiently.
Within the following sections, we develop on the completely different elements and dive into the main points.
GitLab: Package deal fashions and set off pipelines
We use GitLab as our code repository and for the pipeline to bundle the mannequin code and set off downstream Airflow DAGs.
Multi-project pipeline
The multi-project GitLab pipeline function is used the place the mother or father pipeline (upstream) is a mannequin repo and the kid pipeline (downstream) is the MLOps repo. Every repo maintains a .gitlab-ci.yml, and the next code block enabled within the upstream pipeline triggers the downstream MLOps pipeline.
The upstream pipeline sends over the mannequin code to the downstream pipeline the place the packaging and publishing CI jobs get triggered. Code to containerize the mannequin code and publish it to Amazon ECR is maintained and managed by the MLOps pipeline. It sends the variables like ACCESS_TOKEN (may be created beneath Settings, Entry), JOB_ID (to entry upstream artifacts), and $CI_PROJECT_ID (the mission ID of mannequin repo) variables, in order that the MLOps pipeline can entry the mannequin code information. With the job artifacts function from Gitlab, the downstream repo acceses the distant artifacts utilizing the next command:
The mannequin repo can eat downstream pipelines for a number of fashions from the identical repo by extending the stage that triggers it utilizing the extends key phrase from GitLab, which permits you reuse the identical configuration throughout completely different phases.
After publishing the mannequin picture to Amazon ECR, the MLOps pipeline triggers the Amazon MWAA coaching pipeline utilizing Lambda. After consumer approval, it triggers the mannequin deployment Amazon MWAA pipeline as properly utilizing the identical Lambda operate.
Semantic versioning and passing variations downstream
We developed customized code to model ECR photographs and SageMaker fashions. The MLOps pipeline manages the semantic versioning logic for photographs and fashions as a part of the stage the place mannequin code will get containerized, and passes on the variations to later phases as artifacts.
Retraining
As a result of retraining is an important side of an ML lifecycle, we’ve applied retraining capabilities as a part of our pipeline. We use the SageMaker list-models API to establish if it’s retraining primarily based on the mannequin retraining model quantity and timestamp.
We handle the each day schedule of the retraining pipeline utilizing GitLab’s schedule pipelines.
Terraform: Infrastructure setup
Along with an Amazon MWAA cluster, ECR repositories, Lambda capabilities, and SNS subject, this resolution additionally makes use of AWS Identity and Access Management (IAM) roles, customers, and insurance policies; Amazon Simple Storage Service (Amazon S3) buckets, and an Amazon CloudWatch log forwarder.
To streamline the infrastructure setup and upkeep for the providers concerned all through our pipeline, we use Terraform to implement the infrastructure as code. Every time infra updates are required, the code modifications set off a GitLab CI pipeline that we arrange, which validates and deploys the modifications into numerous environments (for instance, including a permission to an IAM coverage in dev, stage and prod accounts).
Amazon ECR, Amazon S3, and Lambda: Pipeline facilitation
We use the next key providers to facilitate our pipeline:
- Amazon ECR – To take care of and permit handy retrievals of the mannequin container photographs, we tag them with semantic variations and add them to ECR repositories arrange per
${project_name}/${model_name}by way of Terraform. This permits a superb layer of isolation between completely different fashions, and permits us to make use of customized algorithms and to format inference requests and responses to incorporate desired mannequin manifest data (mannequin title, model, coaching information path, and so forth). - Amazon S3 – We use S3 buckets to persist mannequin coaching information, skilled mannequin artifacts per mannequin, Airflow DAGs, and different extra data required by the pipelines.
- Lambda – As a result of our Airflow cluster is deployed in a separate VPC for safety concerns, the DAGs can’t be accessed immediately. Subsequently, we use a Lambda operate, additionally maintained with Terraform, to set off any DAGs specified by the DAG title. With correct IAM setup, the GitLab CI job triggers the Lambda operate, which passes by way of the configurations right down to the requested coaching or deployment DAGs.
Amazon MWAA: Coaching and deployment pipelines
As talked about earlier, we use Amazon MWAA to orchestrate the coaching and deployment pipelines. We use SageMaker operators obtainable within the Amazon provider package for Airflow to combine with SageMaker (to keep away from jinja templating).
We use the next operators on this coaching pipeline (proven within the following workflow diagram):
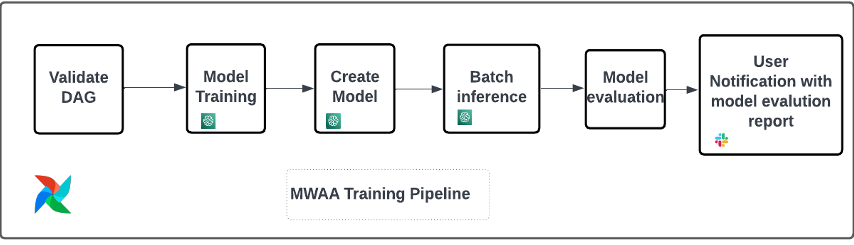
MWAA Coaching Pipeline
We use the next operators within the deployment pipeline (proven within the following workflow diagram):
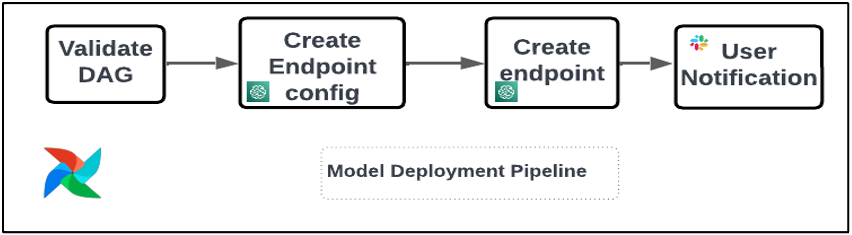
Mannequin Deployment Pipeline
We use Slack and Amazon SNS to publish the error/success messages and analysis ends in each pipelines. Slack offers a variety of choices to customise messages, together with the next:
- SnsPublishOperator – We use SnsPublishOperator to ship success/failure notifications to consumer emails
- Slack API – We created the incoming webhook URL to get the pipeline notifications to the specified channel
CloudWatch and VMware Wavefront: Monitoring and logging
We use a CloudWatch dashboard to configure endpoint monitoring and logging. It helps visualize and preserve observe of assorted operational and mannequin efficiency metrics particular to every mission. On high of the auto scaling insurance policies set as much as observe a few of them, we repeatedly monitor the modifications in CPU and reminiscence utilization, requests per second, response latencies, and mannequin metrics.
CloudWatch is even built-in with a VMware Tanzu Wavefront dashboard in order that it might probably visualize the metrics for mannequin endpoints in addition to different providers on the mission stage.
Enterprise advantages and what’s subsequent
ML pipelines are very essential to ML providers and options. On this publish, we mentioned an end-to-end ML use case utilizing capabilities from AWS. We constructed a customized pipeline utilizing SageMaker and Amazon MWAA, which we are able to reuse throughout initiatives and fashions, and automatic the ML lifecycle, which decreased the time from mannequin coaching to manufacturing deployment to as little as 10 minutes.
With the shifting of the ML lifecycle burden to SageMaker, it offered optimized and scalable infrastructure for the mannequin coaching and deployment. Mannequin serving with SageMaker helped us make real-time predictions with millisecond latencies and monitoring capabilities. We used Terraform for the benefit of setup and to handle infrastructure.
The following steps for this pipeline can be to boost the mannequin coaching pipeline with retraining capabilities whether or not it’s scheduled or primarily based on mannequin drift detection, help shadow deployment or A/B testing for sooner and certified mannequin deployment, and ML lineage monitoring. We additionally plan to judge Amazon SageMaker Pipelines as a result of GitLab integration is now supported.
Classes realized
As a part of constructing this resolution, we realized that it is best to generalize early, however don’t over-generalize. Once we first completed the structure design, we tried to create and implement code templating for the mannequin code as a greatest apply. Nevertheless, it was so early on within the improvement course of that the templates had been both too generalized or too detailed to be reusable for future fashions.
After delivering the primary mannequin by way of the pipeline, the templates got here out naturally primarily based on the insights from our earlier work. A pipeline can’t do every part from day one.
Mannequin experimentation and productionization usually have very completely different (or generally even conflicting) necessities. It’s essential to steadiness these necessities from the start as a staff and prioritize accordingly.
Moreover, you won’t want each function of a service. Utilizing important options from a service and having a modularized design are keys to extra environment friendly improvement and a versatile pipeline.
Conclusion
On this publish, we confirmed how we constructed an MLOps resolution utilizing SageMaker and Amazon MWAA that automated the method of deploying fashions to manufacturing, with little handbook intervention from information scientists. We encourage you to judge numerous AWS providers like SageMaker, Amazon MWAA, Amazon S3, and Amazon ECR to construct a whole MLOps resolution.
*Apache, Apache Airflow, and Airflow are both registered logos or logos of the Apache Software Foundation in america and/or different nations.
Concerning the Authors
 Deepak Mettem is a Senior Engineering Supervisor in VMware, Carbon Black Unit. He and his staff work on constructing the streaming primarily based functions and providers which are extremely obtainable, scalable and resilient to convey clients machine studying primarily based options in real-time. He and his staff are additionally liable for creating instruments mandatory for information scientists to construct, prepare, deploy and validate their ML fashions in manufacturing.
Deepak Mettem is a Senior Engineering Supervisor in VMware, Carbon Black Unit. He and his staff work on constructing the streaming primarily based functions and providers which are extremely obtainable, scalable and resilient to convey clients machine studying primarily based options in real-time. He and his staff are additionally liable for creating instruments mandatory for information scientists to construct, prepare, deploy and validate their ML fashions in manufacturing.
 Mahima Agarwal is a Machine Studying Engineer in VMware, Carbon Black Unit.
Mahima Agarwal is a Machine Studying Engineer in VMware, Carbon Black Unit.
She works on designing, constructing, and growing the core elements and structure of the machine studying platform for the VMware CB SBU.
 Vamshi Krishna Enabothala is a Sr. Utilized AI Specialist Architect at AWS. He works with clients from completely different sectors to speed up high-impact information, analytics, and machine studying initiatives. He’s obsessed with advice techniques, NLP, and pc imaginative and prescient areas in AI and ML. Exterior of labor, Vamshi is an RC fanatic, constructing RC gear (planes, vehicles, and drones), and in addition enjoys gardening.
Vamshi Krishna Enabothala is a Sr. Utilized AI Specialist Architect at AWS. He works with clients from completely different sectors to speed up high-impact information, analytics, and machine studying initiatives. He’s obsessed with advice techniques, NLP, and pc imaginative and prescient areas in AI and ML. Exterior of labor, Vamshi is an RC fanatic, constructing RC gear (planes, vehicles, and drones), and in addition enjoys gardening.
 Sahil Thapar is an Enterprise Options Architect. He works with clients to assist them construct extremely obtainable, scalable, and resilient functions on the AWS Cloud. He’s at the moment targeted on containers and machine studying options.
Sahil Thapar is an Enterprise Options Architect. He works with clients to assist them construct extremely obtainable, scalable, and resilient functions on the AWS Cloud. He’s at the moment targeted on containers and machine studying options.




