Suggest and dynamically filter gadgets based mostly on consumer context in Amazon Personalize

Organizations are repeatedly investing effort and time in growing clever advice options to serve custom-made and related content material to their customers. The objectives might be many: rework the consumer expertise, generate significant interplay, and drive content material consumption. A few of these options use widespread machine studying (ML) fashions constructed on historic interplay patterns, consumer demographic attributes, product similarities, and group conduct. Apart from these attributes, context (similar to climate, location, and so forth) on the time of interplay can affect customers’ choices whereas navigating content material.
On this submit, we present the right way to use the consumer’s present gadget sort as context to boost the effectiveness of your Amazon Personalize-based suggestions. As well as, we present the right way to use such context to dynamically filter suggestions. Though this submit exhibits how Amazon Personalize can be utilized for a video on demand (VOD) use case, it’s value noting that Amazon Personalize can be utilized throughout a number of industries.
What’s Amazon Personalize?
Amazon Personalize permits builders to construct functions powered by the identical sort of ML know-how utilized by Amazon.com for real-time personalised suggestions. Amazon Personalize is able to delivering a wide selection of personalization experiences, together with particular product suggestions, personalised product reranking, and customised direct advertising. Moreover, as a totally managed AI service, Amazon Personalize accelerates buyer digital transformations with ML, making it simpler to combine personalised suggestions into current web sites, functions, e mail advertising techniques, and extra.
Why is context essential?
Utilizing a consumer’s contextual metadata similar to location, time of day, gadget sort, and climate supplies personalised experiences for current customers and helps enhance the cold-start section for brand spanking new or unidentified customers. The cold-start section refers back to the interval when your advice engine supplies non-personalized suggestions because of the lack of historic info relating to that consumer. In conditions the place there are different necessities to filter and promote gadgets (say in information and climate), including a consumer’s present context (season or time of day) helps enhance accuracy by together with and excluding suggestions.
Let’s take the instance of a VOD platform recommending exhibits, documentaries, and films to the consumer. Primarily based on conduct evaluation, we all know VOD customers are inclined to devour shorter-length content material like sitcoms on cell gadgets and longer-form content material like motion pictures on their TV or desktop.
Resolution overview
Increasing on the instance of contemplating a consumer’s gadget sort, we present the right way to present this info as context in order that Amazon Personalize can routinely be taught the affect of a consumer’s gadget on their most popular forms of content material.
We observe the structure sample proven within the following diagram as an example how context can routinely be handed to Amazon Personalize. Routinely deriving context is achieved by way of Amazon CloudFront headers which might be included in requests similar to a REST API in Amazon API Gateway that calls an AWS Lambda operate to retrieve suggestions. Consult with the total code instance out there at our GitHub repository. We offer a AWS CloudFormation template to create the required sources.
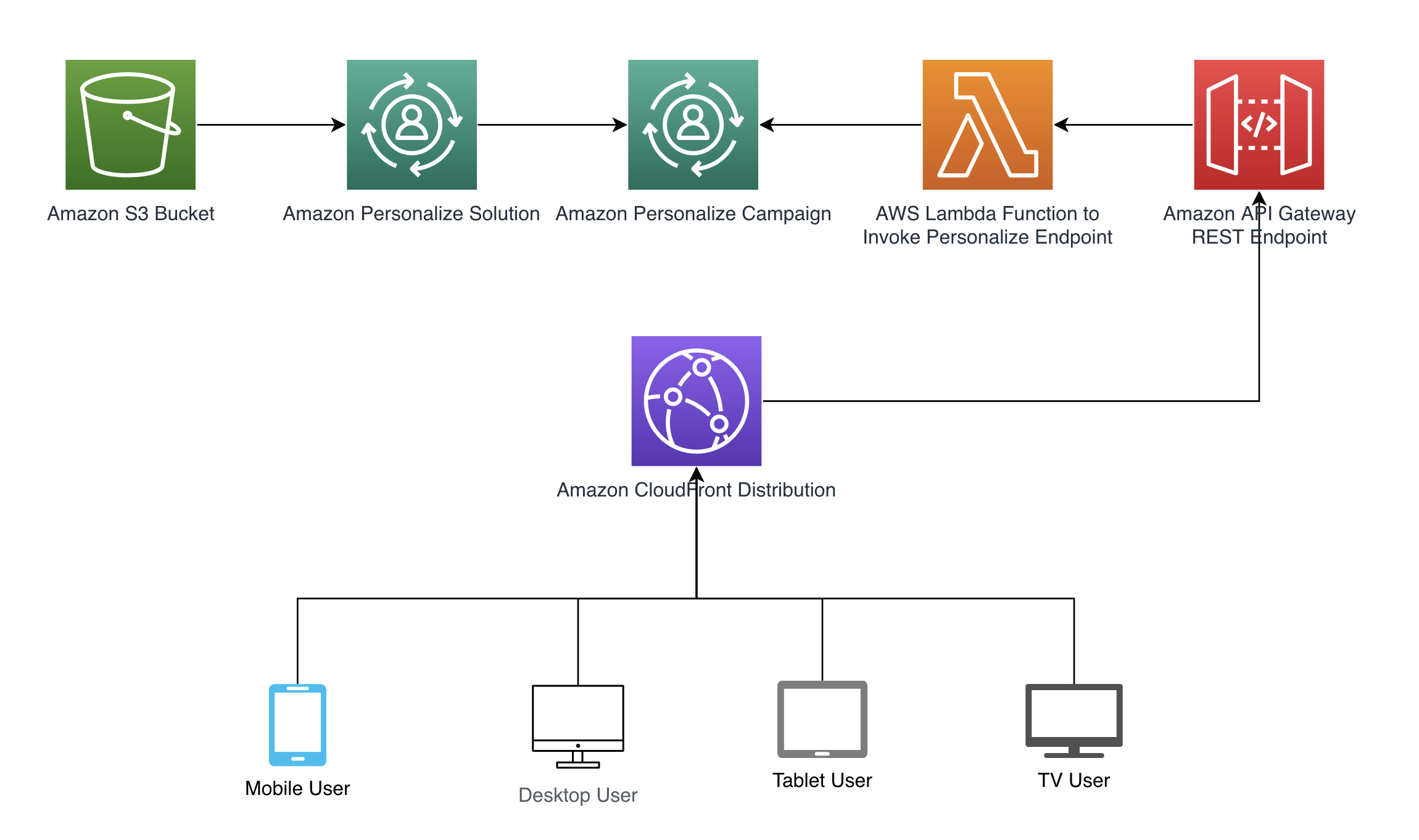
In following sections, we stroll by way of the right way to arrange every step of the pattern structure sample.
Select a recipe
Recipes are Amazon Personalize algorithms which might be ready for particular use instances. Amazon Personalize supplies recipes based mostly on widespread use instances for coaching fashions. For our use case, we construct a easy Amazon Personalize customized recommender utilizing the Consumer-Personalization recipe. It predicts the gadgets {that a} consumer will work together with based mostly on the interactions dataset. Moreover, this recipe additionally makes use of gadgets and customers datasets to affect suggestions, if supplied. To be taught extra about how this recipe works, consult with User-Personalization recipe.
Create and import a dataset
Profiting from context requires specifying context values with interactions so recommenders can use context as options when coaching fashions. We even have to supply the consumer’s present context at inference time. The interactions schema (see the next code) defines the construction of historic and real-time users-to-items interplay information. The USER_ID, ITEM_ID, and TIMESTAMP fields are required by Amazon Personalize for this dataset. DEVICE_TYPE is a customized categorical discipline that we’re including for this instance to seize the consumer’s present context and embrace it in mannequin coaching. Amazon Personalize makes use of this interactions dataset to coach fashions and create advice campaigns.
Equally, the gadgets schema (see the next code) defines the construction of product and video catalog information. The ITEM_ID is required by Amazon Personalize for this dataset. CREATION_TIMESTAMP is a reserved column title however it’s not required. GENRE and ALLOWED_COUNTRIES are customized fields that we’re including for this instance to seize the video’s style and international locations the place the movies are allowed to be performed. Amazon Personalize makes use of this gadgets dataset to coach fashions and create advice campaigns.
In our context, historic information refers to end-user interplay historical past with movies and gadgets on the VOD platform. This information is normally gathered and saved in software’s database.
For demo functions, we use Python’s Faker library to generate some take a look at information mocking the interactions dataset with totally different gadgets, customers, and gadget varieties over a 3-month interval. After the schema and enter interactions file location are outlined, the following steps are to create a dataset group, embrace the interactions dataset throughout the dataset group, and eventually import the coaching information into the dataset, as illustrated within the following code snippets:
Collect historic information and prepare the mannequin
On this step, we outline the chosen recipe and create an answer and resolution model referring to the beforehand outlined dataset group. While you create a customized resolution, you specify a recipe and configure coaching parameters. While you create an answer model for the answer, Amazon Personalize trains the mannequin backing the answer model based mostly on the recipe and coaching configuration. See the next code:
Create a marketing campaign endpoint
After you prepare your mannequin, you deploy it right into a campaign. A marketing campaign creates and manages an auto-scaling endpoint in your skilled mannequin that you should utilize to get personalised suggestions utilizing the GetRecommendations API. In a later step, we use this marketing campaign endpoint to routinely move the gadget sort as a context as a parameter and obtain personalised suggestions. See the next code:
Create a dynamic filter
When getting suggestions from the created marketing campaign, you may filter outcomes based mostly on customized standards. For our instance, we create a filter to fulfill the requirement of recommending movies which might be solely allowed to be performed from consumer’s present nation. The nation info is handed dynamically from the CloudFront HTTP header.
Create a Lambda operate
The following step in our structure is to create a Lambda operate to course of API requests coming from the CloudFront distribution and reply by invoking the Amazon Personalize marketing campaign endpoint. On this Lambda operate, we outline logic to research the next CloudFront request’s HTTP headers and question string parameters to find out the consumer’s gadget sort and consumer ID, respectively:
CloudFront-Is-Desktop-ViewerCloudFront-Is-Cell-ViewerCloudFront-Is-SmartTV-ViewerCloudFront-Is-Pill-ViewerCloudFront-Viewer-Nation
The code to create this operate is deployed by way of the CloudFormation template.
Create a REST API
To make the Lambda operate and Amazon Personalize marketing campaign endpoint accessible to the CloudFront distribution, we create a REST API endpoint arrange as a Lambda proxy. API Gateway supplies instruments for creating and documenting APIs that route HTTP requests to Lambda capabilities. The Lambda proxy integration characteristic permits CloudFront to name a single Lambda operate abstracting requests to the Amazon Personalize marketing campaign endpoint. The code to create this operate is deployed by way of the CloudFormation template.
Create a CloudFront distribution
When making a CloudFront distribution, as a result of this can be a demo setup, we disable caching utilizing a customized caching coverage, guaranteeing the request goes to the origin each time. Moreover, we use an origin request coverage specifying the required HTTP headers and question string parameters which might be included in an origin request. The code to create this operate is deployed by way of the CloudFormation template.
Check suggestions
When the CloudFront distribution’s URL is accessed from totally different gadgets (desktop, pill, telephone, and so forth), we are able to see personalised video suggestions which might be most related to their gadget. Additionally, if a chilly consumer is offered, the suggestions tailor-made for consumer’s gadget are offered. Within the following pattern outputs, names of movies are solely used for illustration of their style and runtime to make it relatable.
Within the following code, a identified consumer who loves comedy based mostly on previous interactions and is accessing from a telephone gadget is offered with shorter sitcoms:
The next identified consumer is offered with characteristic movies when accessing from a sensible TV gadget based mostly on previous interactions:
A chilly (unknown) consumer accessing from a telephone is offered with shorter however standard exhibits:
Suggestions for consumer: 666 ITEM_ID GENRE ALLOWED_COUNTRIES 940 Satire US|FI|CN|ES|HK|AE 760 Satire US|FI|CN|ES|HK|AE 160 Sitcom US|FI|CN|ES|HK|AE 880 Comedy US|FI|CN|ES|HK|AE 360 Satire US|PK|NI|JM|IN|DK 840 Satire US|PK|NI|JM|IN|DK 420 Satire US|PK|NI|JM|IN|DK
A chilly (unknown) consumer accessing from a desktop is offered with high science fiction movies and documentaries:
The next identified consumer accessing from a telephone is returning filtered suggestions based mostly on location (US):
Conclusion
On this submit, we described the right way to use consumer gadget sort as contextual information to make your suggestions extra related. Utilizing contextual metadata to coach Amazon Personalize fashions will show you how to advocate merchandise which might be related to each new and current customers, not simply from the profile information but in addition from a shopping gadget platform. Not solely that, context like location (nation, metropolis, area, postal code) and time (day of the week, weekend, weekday, season) opens up the chance to make suggestions relatable to the consumer. You’ll be able to run the total code instance by utilizing the CloudFormation template supplied in our GitHub repository and cloning the notebooks into Amazon SageMaker Studio.
Concerning the Authors
 Gilles-Kuessan Satchivi is an AWS Enterprise Options Architect with a background in networking, infrastructure, safety, and IT operations. He’s obsessed with serving to clients construct Properly-Architected techniques on AWS. Earlier than becoming a member of AWS, he labored in ecommerce for 17 years. Exterior of labor, he likes to spend time together with his household and cheer on his youngsters’s soccer workforce.
Gilles-Kuessan Satchivi is an AWS Enterprise Options Architect with a background in networking, infrastructure, safety, and IT operations. He’s obsessed with serving to clients construct Properly-Architected techniques on AWS. Earlier than becoming a member of AWS, he labored in ecommerce for 17 years. Exterior of labor, he likes to spend time together with his household and cheer on his youngsters’s soccer workforce.
 Aditya Pendyala is a Senior Options Architect at AWS based mostly out of NYC. He has intensive expertise in architecting cloud-based functions. He’s presently working with giant enterprises to assist them craft extremely scalable, versatile, and resilient cloud architectures, and guides them on all issues cloud. He has a Grasp of Science diploma in Laptop Science from Shippensburg College and believes within the quote “While you stop to be taught, you stop to develop.”
Aditya Pendyala is a Senior Options Architect at AWS based mostly out of NYC. He has intensive expertise in architecting cloud-based functions. He’s presently working with giant enterprises to assist them craft extremely scalable, versatile, and resilient cloud architectures, and guides them on all issues cloud. He has a Grasp of Science diploma in Laptop Science from Shippensburg College and believes within the quote “While you stop to be taught, you stop to develop.”
 Prabhakar Chandrasekaran is a Senior Technical Account Supervisor with AWS Enterprise Help. Prabhakar enjoys serving to clients construct cutting-edge AI/ML options on the cloud. He additionally works with enterprise clients offering proactive steerage and operational help, serving to them enhance the worth of their options when utilizing AWS. Prabhakar holds six AWS and 6 different skilled certifications. With over 20 years {of professional} expertise, Prabhakar was a knowledge engineer and a program chief within the monetary providers area previous to becoming a member of AWS.
Prabhakar Chandrasekaran is a Senior Technical Account Supervisor with AWS Enterprise Help. Prabhakar enjoys serving to clients construct cutting-edge AI/ML options on the cloud. He additionally works with enterprise clients offering proactive steerage and operational help, serving to them enhance the worth of their options when utilizing AWS. Prabhakar holds six AWS and 6 different skilled certifications. With over 20 years {of professional} expertise, Prabhakar was a knowledge engineer and a program chief within the monetary providers area previous to becoming a member of AWS.





