A Sensible Information to Switch Studying utilizing PyTorch
Co-authored with Naresh and Gaurav.
This text will cowl the what, why, and the way of switch studying.
- What is switch studying
- Why must you use switch studying
- How can you utilize switch studying on an actual classification activity
Particularly, we’ll be protecting the next features of switch studying.
- The motivation behind the thought of switch studying and its advantages.
- Develop an instinct for base mannequin choice. (notebook)
- Talk about totally different selections and the trade-offs made alongside the best way.
- Implementation of a picture classification activity with PyTorch. (notebook)
- Efficiency comparability of assorted base fashions.
- Sources to be taught extra about switch studying and the present state-of-the-art
Switch studying is a big and rising discipline and this text covers just some of its features. Nevertheless, there are numerous deep studying on-line communities which debate switch studying. For instance, here is a good article on how we are able to leverage switch studying to achieve increased benchmarks than coaching fashions from scratch.
Supposed Viewers and Stipulations
- You’re aware of fundamental machine studying (ML) ideas resembling defining and coaching classification fashions
- You’re aware of PyTorch and torchvision
Within the subsequent part, we’ll formally introduce switch studying and clarify it with examples.
What’s switch studying?
From this page,
“Switch studying is a machine studying methodology the place a mannequin developed for a activity is reused as the place to begin for a mannequin on a second activity.”
A deep studying mannequin is a community of weights whose values are optimized utilizing a loss operate throughout the coaching progress. The weights of the community are usually initialized randomly earlier than the beginning of the coaching course of. In switch studying, we use a pre-trained model that has been skilled on a associated activity. This provides us a set of preliminary weights which are more likely to carry out higher than the randomly initialized weights. We optimize the pre-trained weights additional for our particular activity.
Jeremy Howard (from quick.ai) says.
“Wherever potential, you need to intention to start out your neural community coaching with a pre-trained mannequin and fine-tune it. You actually don’t need to be beginning with random weights, as a result of that implies that you’re beginning with a mannequin that doesn’t know the way to do something in any respect! With pretraining, you should use 1000x much less knowledge than ranging from scratch.”
Beneath, we’ll see how one can consider the idea of switch studying because it pertains to people.
Human Analogy for Switch Studying
- Mannequin coaching: After a toddler is born, it takes them some time to be taught to face, steadiness, and stroll. Throughout this time, they undergo the part of constructing bodily muscle tissues, and their mind learns to know and internalize the talents to face, steadiness and stroll. They undergo a number of makes an attempt, some profitable and a few failures, to achieve a stage the place they’ll stand, steadiness and stroll with some consistency. That is just like coaching a deep studying mannequin which takes a number of time (coaching epochs) to be taught a generic activity (resembling classifying a picture as belonging to one of many 1000 ImageNet lessons) when it’s skilled on that activity.
- Switch studying: A toddler who has discovered to stroll finds it far simpler to be taught associated superior abilities resembling leaping and operating. Switch Studying is akin to this side of human studying the place a pre-trained mannequin that has already discovered generic abilities is leveraged to effectively practice for different associated duties.
Now that now we have constructed an intuitive understanding of switch studying and an analogy with human studying, let’s check out why one would use switch studying for ML fashions.
Why ought to I exploit switch studying?
Many imaginative and prescient AI duties resembling picture classification, picture segmentation, object localization, or detection differ solely within the particular objects they’re classifying, segmenting, or detecting. The fashions skilled on these duties have discovered the options of the objects of their coaching dataset. Therefore, they are often simply tailored to associated duties. For instance, a mannequin skilled to determine the presence of a automotive in a picture may very well be fine-tuned for figuring out a cat or a canine.
The principle benefit of switch studying is the power to empower you to attain higher accuracy in your duties. We will break down its benefits as follows:
- Coaching effectivity: Whenever you begin with a pre-trained mannequin that has already discovered the overall options of the information, you then solely must fine-tune the mannequin to your particular activity, which could be completed rather more shortly (i.e. utilizing fewer coaching epochs).
- Mannequin accuracy: Utilizing switch studying may give you a significant performance boost in comparison with coaching a mannequin from scratch utilizing the identical quantity of assets. Selecting the best pre-trained mannequin for transfer-learning in your particular activity is vital although.
- Coaching knowledge dimension: Since a pre-trained mannequin would have already discovered to determine lots of the options that overlap along with your task-specific options, you possibly can practice the pre-trained mannequin with much less domain-specific knowledge. That is helpful if you happen to don’t have as a lot labeled knowledge in your particular activity.
So, how will we go about doing switch studying in observe? The following part implements switch studying in PyTorch for a flower classification activity.
To carry out switch studying with PyTorch, we first want to pick a dataset and a pre-trained imaginative and prescient mannequin for picture classification. This text focuses on utilizing torch-vision (a site library used with PyTorch). Let’s perceive the place to seek out such pre-trained fashions and datasets.
The place to seek out pre-trained imaginative and prescient fashions for picture classification?
There are many web sites offering high-quality pre-trained picture classification fashions. For instance:
For the needs of this text, we’ll use pre-trained models from torchvision. It is value studying a bit about how these fashions have been skilled. Let’s discover that query subsequent!
Which datasets are torchvision fashions pre-trained on?
For vision-related duties involving pictures, torchvision fashions are often pre-trained on the ImageNet dataset. The most well-liked ImageNet subset utilized by researchers and for mannequin pre-training imaginative and prescient fashions comprises about 1.2M pictures throughout 1000 lessons. ImageNet classification is used as a pre-training activity as a result of:
- Its prepared availability to the analysis neighborhood
- The breadth and number of pictures it comprises
- Its use by numerous researchers – making it engaging to match outcomes utilizing a frequent denominator of Imagenet 1k classification
You may learn extra in regards to the historical past of the ImageNet problem, historic background, and details about the whole dataset on this wikipedia page.
Legality issues when utilizing pre-trained fashions
ImageNet is launched for non-commercial analysis functions solely (https://image-net.org/download). Therefore, it’s not clear if one can legally use the weights from a mannequin that was pre-trained on ImageNet for business functions. For those who plan to take action, please search authorized recommendation.
Now that we all know the place we are able to discover the pre-trained fashions we’ll be utilizing for switch studying, let’s check out the place we are able to procure the dataset we want to use for our customized classification activity.
Dataset: Oxford Flowers 102
We can be utilizing the Flowers 102 dataset as an example switch studying utilizing PyTorch. We are going to practice a mannequin to categorise pictures within the Flowers 102 dataset into one of many 102 classes. It is a multi-class (single-label) categorization downside wherein predicted lessons are mutually unique. We’ll be leveraging Torchvision for this activity because it already provides this dataset for us to make use of.
The Flowers 102 dataset was obtained from the Visual Geometry Group at Oxford. Please see the web page for licensing phrases for the usage of the dataset.
Subsequent, let’s check out the high-level steps concerned on this course of.
How does switch studying work?
Switch studying for picture classification duties could be seen as a sequence of three steps as proven in Determine 1. These steps are as follows:
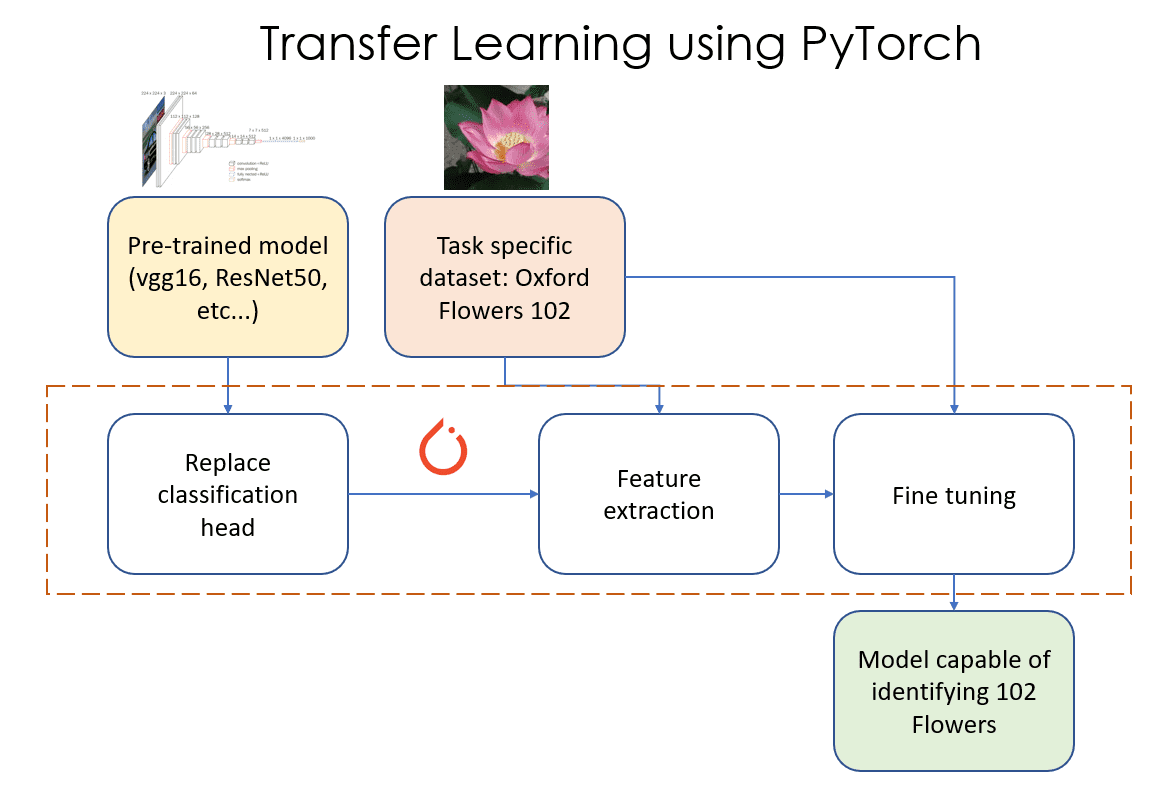
Determine 1: Switch Studying utilizing PyTorch. Supply: Creator(s)
- Substitute classifier layer: On this part, we determine and change the final “classification head” of our pre-trained mannequin with our personal “classification head” that has the correct variety of output options (102 on this instance).
- Function extraction: On this part, we freeze (make these layers non-trainable) all of the layers of the mannequin besides the newly added classification layer, and practice simply this newly added layer.
- Wonderful tuning: On this part, we unfreeze some subset of the layers within the mannequin (unfreezing a layer means making it trainable). On this article, we’ll unfreeze all of the layers of the mannequin and practice them as we might practice any Machine Studying (ML) PyTorch mannequin.
Every of those phases has a number of further element and nuance that we have to know and fear about. We’ll get into these particulars quickly. For now, let’s deep dive into 2 of the important thing phases, specifically characteristic extraction, and fine-tuning under.
Function extraction and fine-tuning
You’ll find extra details about characteristic extraction and fine-tuning right here.
- What is the difference between feature extraction and fine-tuning in transfer learning?
- Learning without forgetting
The diagrams under illustrate characteristic extraction and wonderful tuning visually.
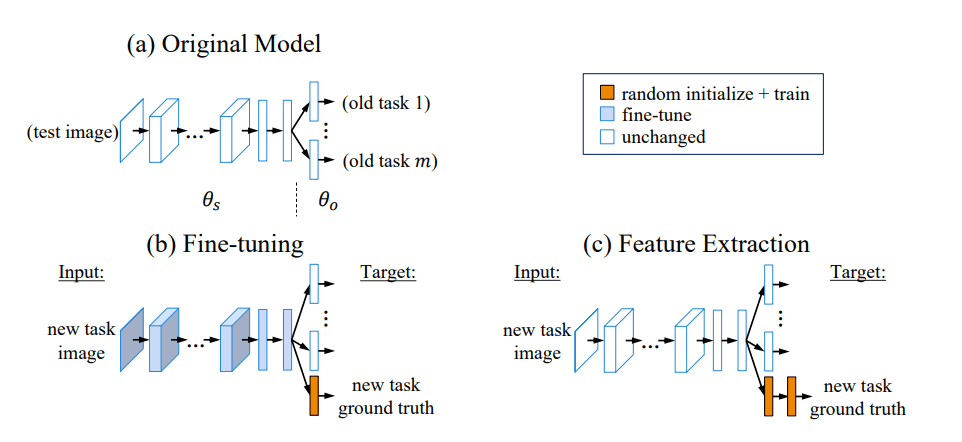
Determine 2: Visible clarification of wonderful tuning (b) and have extraction (c). Supply: Learning without forgetting
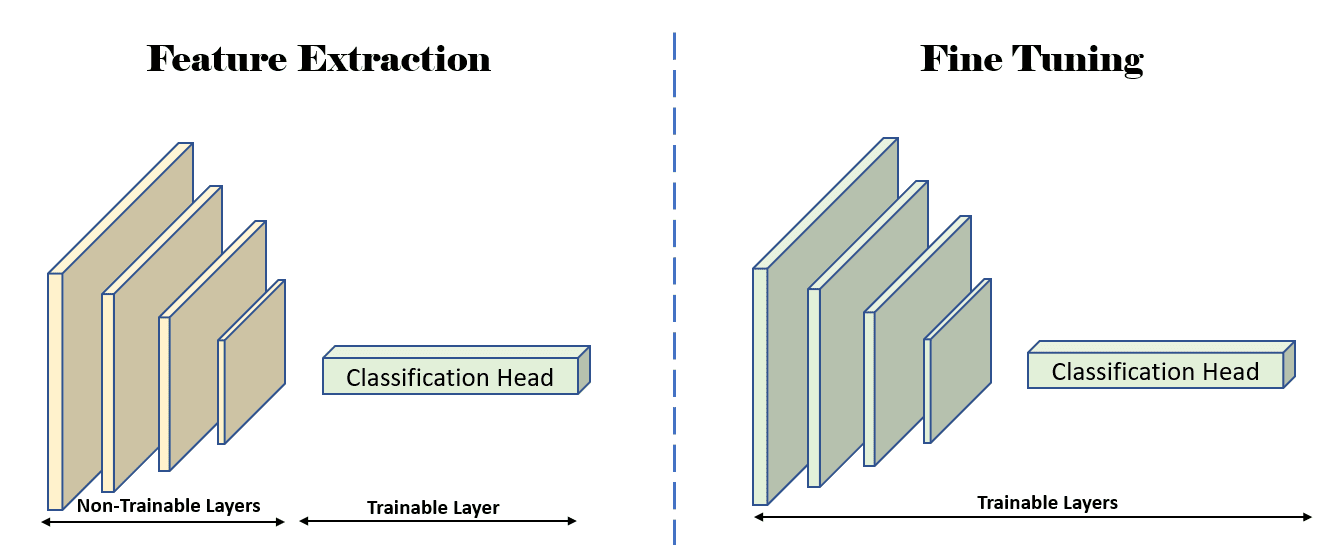
Determine 3: Illustration displaying which layers are trainable (unfrozen) throughout the feature-extraction, and fine-tuning levels. Supply: Creator(s)
Now that we’ve developed a superb understanding of the customized classification activity, the pre-trained mannequin we’ll be utilizing for this activity, and the way switch studying works, let’s take a look at some concrete code that performs switch studying.
On this part you’ll be taught ideas like exploratory mannequin evaluation, preliminary mannequin choice, the way to outline a mannequin, implement switch studying steps (mentioned above), and the way to forestall overfitting. We’ll talk about the practice/val/check break up for this dataset and interpret the outcomes.
The entire code for this experiment could be discovered here (Flowers102 classification using pre-trained models). The part on exploratory mannequin evaluation is in a separate notebook.
Exploratory mannequin evaluation
Just like exploratory knowledge evaluation in knowledge science, step one in transfer-learning is exploratory mannequin evaluation. On this step, we discover all of the pre-trained fashions obtainable for picture classification duties, and decide how each is structured.
Usually, it’s laborious to know which mannequin will carry out greatest for our activity, so it’s not unusual to check out a couple of fashions that appear promising or relevant for our state of affairs. On this hypothetical situation, let’s assume that mannequin dimension isn’t vital (we don’t need to deploy these fashions on cellular units or such edge units). We’ll first take a look at the checklist of accessible pre-trained classification fashions in torchvision.
classification_models = torchvision.fashions.list_models(module=torchvision.fashions)
print(len(classification_models), "classification fashions:", classification_models)
Will print
80 classification fashions: ['alexnet', 'convnext_base', 'convnext_large', 'convnext_small', 'convnext_tiny', 'densenet121', 'densenet161', 'densenet169', 'densenet201', 'efficientnet_b0', 'efficientnet_b1', 'efficientnet_b2', 'efficientnet_b3', 'efficientnet_b4', 'efficientnet_b5', 'efficientnet_b6', 'efficientnet_b7', 'efficientnet_v2_l', 'efficientnet_v2_m', 'efficientnet_v2_s', 'googlenet', 'inception_v3', 'maxvit_t', 'mnasnet0_5', 'mnasnet0_75', 'mnasnet1_0', 'mnasnet1_3', 'mobilenet_v2', 'mobilenet_v3_large', 'mobilenet_v3_small', 'regnet_x_16gf', 'regnet_x_1_6gf', 'regnet_x_32gf', 'regnet_x_3_2gf', 'regnet_x_400mf', 'regnet_x_800mf', 'regnet_x_8gf', 'regnet_y_128gf', 'regnet_y_16gf', 'regnet_y_1_6gf', 'regnet_y_32gf', 'regnet_y_3_2gf', 'regnet_y_400mf', 'regnet_y_800mf', 'regnet_y_8gf', 'resnet101', 'resnet152', 'resnet18', 'resnet34', 'resnet50', 'resnext101_32x8d', 'resnext101_64x4d', 'resnext50_32x4d', 'shufflenet_v2_x0_5', 'shufflenet_v2_x1_0', 'shufflenet_v2_x1_5', 'shufflenet_v2_x2_0', 'squeezenet1_0', 'squeezenet1_1', 'swin_b', 'swin_s', 'swin_t', 'swin_v2_b', 'swin_v2_s', 'swin_v2_t', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'vit_b_16', 'vit_b_32', 'vit_h_14', 'vit_l_16', 'vit_l_32', 'wide_resnet101_2', 'wide_resnet50_2']
Wow! That’s a pretty big checklist of fashions to select from! For those who’re feeling confused, don’t fear – within the subsequent part, we’ll take a look at the elements to contemplate when selecting the preliminary set of fashions for performing switch studying.
Preliminary mannequin choice
Now that now we have a listing of 80 candidate fashions to select from, we have to slender it all the way down to a handful of fashions that we are able to run experiments on. The selection of the pre-trained mannequin spine is a hyper-parameter, and we are able to (and will) discover a number of choices by operating experiments to see which one works greatest. Working experiments is dear and time consuming, and it’s unlikely that we’ll be capable to strive all of the fashions, which is why we attempt to slender down the checklist to 3-4 fashions to start with.
We determined to go along with the next pre-trained mannequin backbones to start with.
- Vgg16: 135M parameters
- ResNet50: 23M parameters
- ResNet152: 58M parameters
Right here’s how/why we selected these 3 to start with.
- We’re not constrained by mannequin dimension or inference latency, so we don’t want to seek out the fashions which are tremendous environment friendly. If you’d like a comparative examine of assorted imaginative and prescient fashions for cellular units, please learn the paper titled “Comparison and Benchmarking of AI Models and Frameworks on Mobile Devices”.
- The fashions we select are pretty standard within the imaginative and prescient ML neighborhood and are typically good go-to selections for classification duties. You would use the quotation depend for papers on these fashions as first rate proxies for a way efficient these fashions may very well be. Nevertheless, please pay attention to a possible bias the place papers on fashions resembling AlexNet which have been round lengthy could have extra citations although one wouldn’t use them for any severe classification activity as a default selection.
- Even inside mannequin architectures, there are typically many flavours or sizes of fashions. For instance, EfficientNet is available in trims named B0 via B7. Please seek advice from the papers on the precise fashions for particulars on what these trims imply.
Quotation counts of assorted papers on pre-trained classification fashions obtainable in torchvision.
- Resnet: 165k
- AlexNet: 132k
- Vgg16: 102k
- MobileNet: 19k
- Imaginative and prescient Transformers: 16k
- EfficientNet: 12k
- ShuffleNet: 6k
For those who’d prefer to learn extra on elements which will have an effect on your selection of pre-trained mannequin, please learn the next articles:
- 4 Pre-Trained CNN Models to Use for Computer Vision with Transfer Learning
- How to choose the best pre-trained model for your Convolutional Neural Network?
- Benchmark Analysis of Representative Deep Neural Network Architectures
Let’s try the classification heads for these fashions.
vgg16 = torchvision.fashions.vgg16_bn(weights=None)
resnet50 = torchvision.fashions.resnet50(weights=None)
resnet152 = torchvision.fashions.resnet152(weights=None)
print(“vgg16n“, vgg16.classifier)
print(“resnet50n“, resnet50.fc)
print(“resnet152n“, resnet152.fc)
vgg16
Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
resnet50
Linear(in_features=2048, out_features=1000, bias=True)
resnet152
Linear(in_features=2048, out_features=1000, bias=True)
You’ll find the whole pocket book for exploratory model analysis here.
Since we’re going to be operating experiments on 3 pre-trained fashions and performing switch studying on every considered one of them individually, let’s outline some abstractions and lessons that can assist us run and monitor these experiments.
Defining a PyTorch mannequin to wrap pre-trained fashions
To permit straightforward exploration, we’ll outline a PyTorch mannequin named Flowers102Classifier, and use that all through this train. We are going to progressively add performance to this class until we obtain our closing objective. The entire pocket book for transfer learning for Flowers 102 classification can be found here.
The sections under will dive deeper into every of the mechanical steps wanted to carry out switch studying.
Changing the previous classification head with a brand new one
The prevailing classification head for every of those fashions that’s pre-trained on the ImageNet classification activity has 1000 output options. Our customized activity for flower classification has 102 output options. Therefore, we have to change the ultimate classification head (layer) with a brand new one which has 102 output options.
The constructor for our class will embrace code that hundreds the pre-trained mannequin of curiosity from torchvision utilizing pre-trained weights, and can change the classification head with a customized classification head for 102 lessons.
def __init__(self, spine, load_pretrained):
tremendous().__init__()
assert spine in backbones
self.spine = spine
self.pretrained_model = None
self.classifier_layers = []
self.new_layers = []
if spine == "resnet50":
if load_pretrained:
self.pretrained_model = torchvision.fashions.resnet50(
weights=torchvision.fashions.ResNet50_Weights.IMAGENET1K_V2
)
else:
self.pretrained_model = torchvision.fashions.resnet50(weights=None)
# finish if
self.classifier_layers = [self.pretrained_model.fc]
# Substitute the ultimate layer with a classifier for 102 lessons for the Flowers 102 dataset.
self.pretrained_model.fc = nn.Linear(
in_features=2048, out_features=102, bias=True
)
self.new_layers = [self.pretrained_model.fc]
elif spine == "resnet152":
if load_pretrained:
self.pretrained_model = torchvision.fashions.resnet152(
weights=torchvision.fashions.ResNet152_Weights.IMAGENET1K_V2
)
else:
self.pretrained_model = torchvision.fashions.resnet152(weights=None)
# finish if
self.classifier_layers = [self.pretrained_model.fc]
# Substitute the ultimate layer with a classifier for 102 lessons for the Flowers 102 dataset.
self.pretrained_model.fc = nn.Linear(
in_features=2048, out_features=102, bias=True
)
self.new_layers = [self.pretrained_model.fc]
elif spine == "vgg16":
if load_pretrained:
self.pretrained_model = torchvision.fashions.vgg16_bn(
weights=torchvision.fashions.VGG16_BN_Weights.IMAGENET1K_V1
)
else:
self.pretrained_model = torchvision.fashions.vgg16_bn(weights=None)
# finish if
self.classifier_layers = [self.pretrained_model.classifier]
# Substitute the ultimate layer with a classifier for 102 lessons for the Flowers 102 dataset.
self.pretrained_model.classifier[6] = nn.Linear(
in_features=4096, out_features=102, bias=True
)
self.new_layers = [self.pretrained_model.classifier[6]]
Since we’ll be performing feature-extraction adopted by fine-tuning, we’ll save the newly added layers into the self.new_layers checklist. It will assist us set the weights of these layers as trainable or non-tainable relying on what we’re doing.
Now that now we have changed the older classification head with a brand new classification head that has randomly initialized weights, we might want to practice these weights in order that the mannequin can carry out correct predictions. This consists of characteristic extraction and wonderful tuning and we’ll check out that subsequent.
Switch Studying (trainable parameters and studying charges)
Switch studying includes operating characteristic extraction and wonderful tuning in that particular order. Let’s take a more in-depth take a look at why they should be run in that order and the way we are able to deal with trainable parameters for the varied switch studying phases.
Function Extraction: We set requires_grad to False for weights in all of the layers within the mannequin, and set requires_grad to True for under the newly added layers.
We practice the brand new layer(s) for 16 epochs with a studying price of 1e-3. This ensures that the brand new layer(s) are capable of alter and adapt their weights to the weights within the characteristic extractor a part of the community. It’s vital to freeze the remainder of the layers within the community and practice solely the brand new layer(s) in order that we don’t shock the community into forgetting what it has already discovered. If we don’t freeze the sooner layers, they’ll find yourself getting re-trained on junk weights that have been randomly initialized once we added the brand new classification head.
Wonderful Tuning: We set requires_grad to True for weights in all of the layers of the mannequin. We practice all the community for 8 epochs. Nevertheless, we undertake a differential studying price technique on this case. We decay the training price (LR) in order that the LR decreases as we transfer towards the enter layers (away from the output classification head). We decay the training price as we transfer up the mannequin in direction of the preliminary layers of the mannequin as a result of these preliminary layers have discovered fundamental options in regards to the picture, which might be frequent for many imaginative and prescient AI duties. Therefore, the preliminary layers are skilled with a really low LR to keep away from disturbing what they’ve discovered. As we transfer down the mannequin in direction of the classification head, the mannequin is studying one thing activity particular, so it is sensible to coach these later layers with the next LR. One can undertake totally different methods right here, and in our case, we use 2 totally different methods as an example the effectiveness of each of them.
- VGG16: For the vgg16 community, we decay the LR linearly from LR=1e-4 to LR=1e-7 (1000x decrease than the LR of the classification layer). Since there are 44 layers within the characteristic extraction part, every layer is assigned a LR that’s (1e-7 – 1e-4)/44 = 2.3e-6 decrease than the earlier layer.
- ResNet: For the ResNet (50/152) community, we decay the LR exponentially ranging from LR=1e-4. We scale back the LR by 3x for each layer we transfer up.
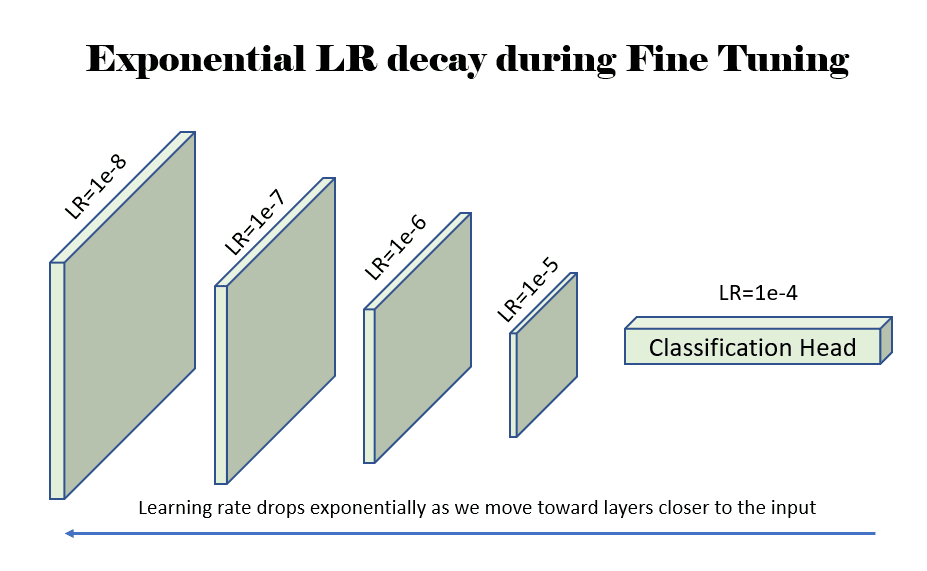
Determine 4: An instance displaying the training price (LR) decaying exponentially by an element of 10 as we transfer up towards the layers nearer to the enter to the community. Supply: Creator(s).
The code for freezing layers for each characteristic extraction in addition to wonderful tuning is proven within the operate named fine_tune() under.
def fine_tune(self, what: FineTuneType):
# The requires_grad parameter controls whether or not this parameter is
# trainable throughout mannequin coaching.
m = self.pretrained_model
for p in m.parameters():
p.requires_grad = False
if what's FineTuneType.NEW_LAYERS:
for l in self.new_layers:
for p in l.parameters():
p.requires_grad = True
elif what's FineTuneType.CLASSIFIER:
for l in self.classifier_layers:
for p in l.parameters():
p.requires_grad = True
else:
for p in m.parameters():
p.requires_grad = True
In PyTorch, the best way to set differential LRs for every layer is to specify the weights that want that LR to the optimizer that can be used throughout switch studying. In our pocket book, we use the Adam optimizer. The get_optimizer_params() methodology under will get the optimizer parameters to cross into the Adam (or different) optimizer we can be utilizing.
def get_optimizer_params(self):
"""This methodology is used solely throughout mannequin fine-tuning when we have to
set a linearly or exponentially decaying studying price (LR) for the
layers within the mannequin. We exponentially decay the training price as we
transfer away from the final output layer.
"""
choices = []
if self.spine == "vgg16":
# For vgg16, we begin with a studying price of 1e-3 for the final layer, and
# decay it to 1e-7 on the first conv layer. The intermediate charges are
# decayed linearly.
lr = 0.0001
choices.append(
{
"params": self.pretrained_model.classifier.parameters(),
"lr": lr,
}
)
final_lr = lr / 1000.0
diff_lr = final_lr - lr
lr_step = diff_lr / 44.0
for i in vary(43, -1, -1):
choices.append(
{
"params": self.pretrained_model.options[i].parameters(),
"lr": lr + lr_step * (44 - i),
}
)
# finish for
elif self.spine in ["resnet50", "resnet152"]:
# For the resnet class of fashions, we decay the LR exponentially and scale back
# it to a 3rd of the earlier worth at every step.
layers = ["conv1", "bn1", "layer1", "layer2", "layer3", "layer4", "fc"]
lr = 0.0001
for layer_name in reversed(layers):
choices.append(
{
"params": getattr(self.pretrained_model, layer_name).parameters(),
"lr": lr,
}
)
lr = lr / 3.0
# finish for
# finish if
return choices
# finish def
As soon as now we have the mannequin parameters with their very own LRs, we are able to cross them into the optimizer with a single line of code. A default LR of 1e-8 is used for parameters whose weights should not specified within the dictionary returned by get_optimizer_params().
optimizer = torch.optim.Adam(fc.get_optimizer_params(), lr=1e-8)Now that we all know the way to carry out switch studying, let’s check out what different issues we’d like to remember earlier than we wonderful tune our mannequin. This consists of steps that we have to take to stop overfitting, and selecting the best practice/val/check break up.
Stopping overfitting
In our notebook, we use the next knowledge augmentation methods on the coaching knowledge to stop overfitting and permit the mannequin to be taught the options in order that it might carry out predictions on unseen knowledge.
- Coloration Jitter
- Horizontal Flip
- Rotation
- Shear
There isn’t any knowledge augmentation utilized to the validation break up.
One must also discover weight decaying, which is a regularization method to stop overfitting by lowering the complexity of the mannequin.
Prepare/Val/Take a look at break up
The authors of the Flowers 102 dataset advocate a practice/val/check break up that’s of dimension 1020/ 1020/6149. Many authors do issues in a different way. For instance,
- Within the ResNet strikes back paper, the authors use the practice+val (2040 pictures) break up because the practice set, and the check set because the check set. It isn’t clear if there’s a validation break up.
- On this article on classification on Flowers 102, the authors use the check break up of dimension 6149 because the practice break up.
- On this notebook, the writer makes use of a practice/val/check break up of dimension 6552, 818, and 819 respectively.
The one method to know which writer is doing what’s to learn the papers or the code.
In our pocket book (on this article), we use the break up of dimension 6149 because the practice break up and the break up of dimension 2040 because the validation break up. We don’t use a check break up, since we aren’t actually making an attempt to compete right here.
At this cut-off date, you need to really feel empowered to go to this notebook that performs the entire steps above and has their outcomes offered so that you can view. Please be happy to clone the pocket book on Kaggle or Google Colab and run it your self on a GPU. For those who’re utilizing Google Colab, you’ll want to repair up a few of the paths the place the datasets and pre-trained fashions are downloaded and the place the very best weights for the fine-tuned fashions are saved.
Beneath, we’ll take a look at the outcomes of our switch studying experiments!
Outcomes
The outcomes have some frequent themes that we’ll discover under.
- After the characteristic extraction step alone, virtually all of the networks have an accuracy between 91% and 94%
- Virtually all networks do rather well, attaining an accuracy of 96+% after the fine-tuning step. This reveals that the wonderful tuning step actually helps throughout switch studying.
There’s a major distinction within the variety of parameters in our community, with vgg16 at 135M parameters, ResNet50 at 23M parameters, and ResNet152 at 58M parameters. This implies that we are able to most likely discover a smaller community with comparable accuracy and efficiency.
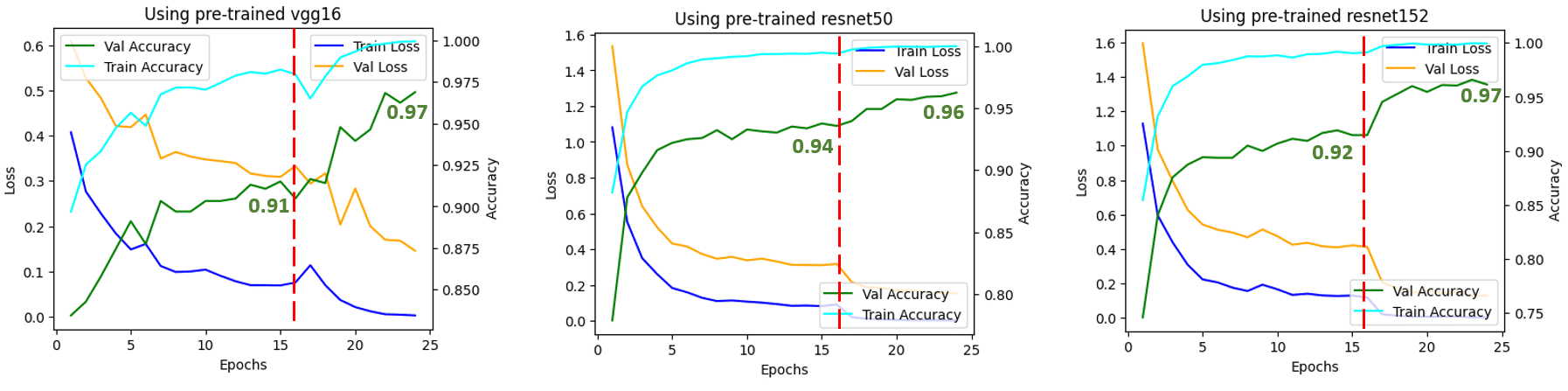
Determine 5: Prepare/Val Loss and Accuracy over the switch studying course of. Supply: Creator(s).
The vertical crimson line signifies the epoch once we switched from characteristic extraction (16 epochs) to fine-tuning (8 epochs). You may see that once we switched to fine-tuning, all of the networks confirmed a rise in accuracy. This reveals that fine-tuning after characteristic extraction could be very efficient.
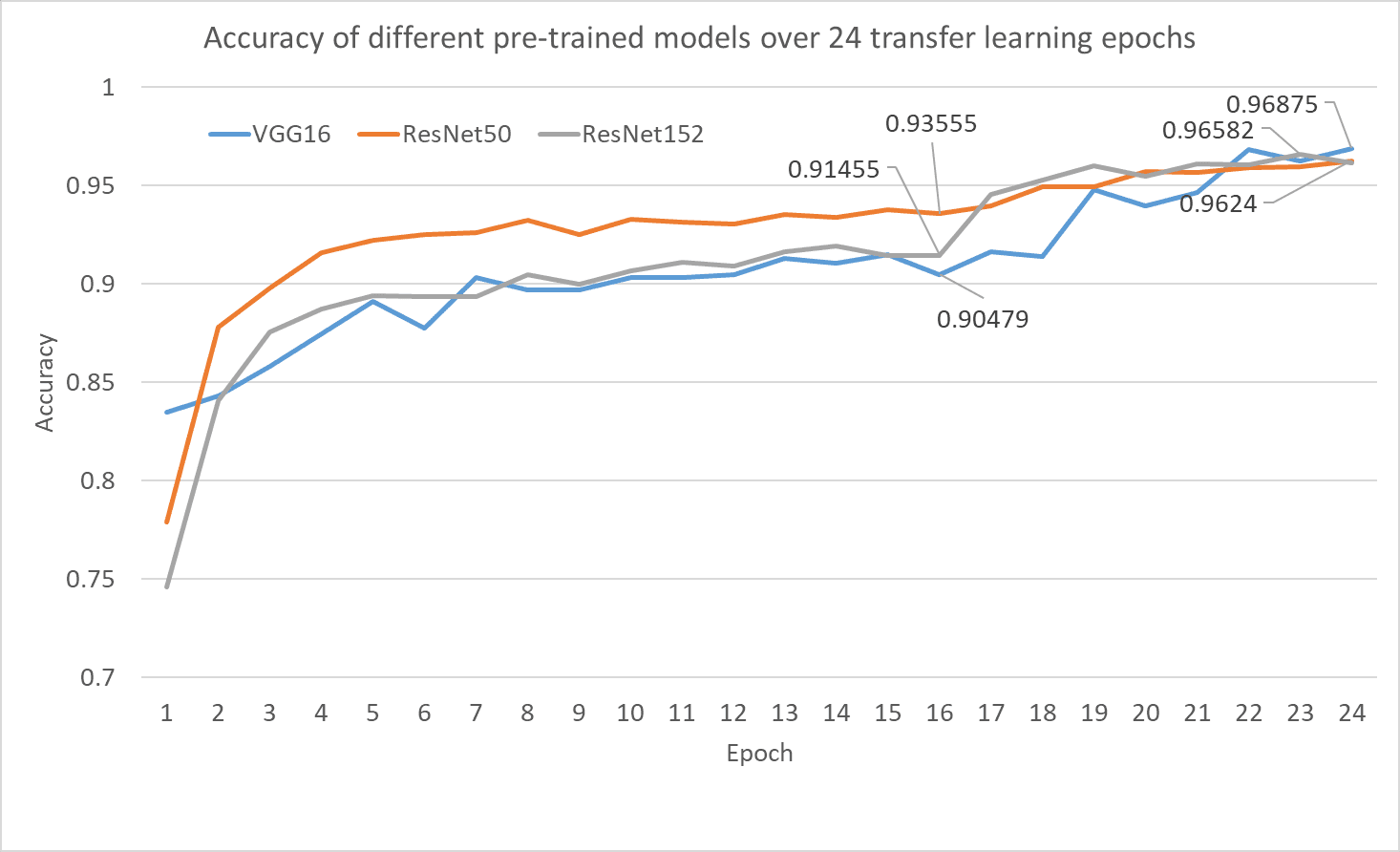
Determine 6: Validation accuracy of all the three pre-trained fashions after switch studying on the flowers classification activity. The validation accuracy after characteristic extraction at epoch 16 is proven together with the very best validation accuracy for every mannequin throughout the wonderful tuning part. Supply: writer(s).
- Switch studying is a thrifty and efficient method to practice your community by ranging from a pre-trained community on the same however unrelated activity
- Torchvision gives many fashions pre-trained on ImageNet for researchers to make use of throughout switch studying
- Watch out when utilizing pre-trained fashions in manufacturing to make sure that you don’t violate any licenses or phrases of use for datasets on which fashions have been pre-trained
- Switch studying consists of characteristic extraction and fine-tune, which have to be carried out in that particular order
Now that we all know the way to carry out switch studying for a customized activity ranging from a mannequin that’s pre-trained on a special dataset, wouldn’t it’s nice if we may keep away from utilizing a separate dataset for the pre-training (pretext activity) and use our personal dataset for this objective? Seems, that is turning into possible!
Lately, researchers and practitioners have been utilizing self-supervised learning as a method to carry out mannequin pre-training (studying the pretext activity) which has a profit of coaching the mannequin on a dataset with the identical distribution because the goal dataset that the mannequin is meant to be consuming in manufacturing. If you’re all in favour of studying extra about self-supervised pre-training and hierarchical pretraining, please see this paper from 2021 titled self-supervised pretraining improves self-supervised pretraining.
For those who personal the information in your particular activity, you should use self-supervised studying for pre-training your mannequin and never fear about utilizing the ImageNet dataset for the pre-training step, thus staying within the clear so far as use of the ImageNet dataset is worried.
- Classification head: In PyTorch, that is an nn.Linear layer that maps quite a few enter options to a set of output options
- Freeze weights: Make the weights non-trainable. In PyTorch, that is completed by setting requires_grad=False
- Unfreeze (or thaw) weights: Make the weights trainable. In PyTorch, that is completed by setting requires_grad=True
- Self-supervised studying: A method to practice an ML mannequin in order that it may be skilled on knowledge with none human generated labels. The labels may very well be robotically or machine generated although
Dhruv Matani is a Machine Studying fanatic specializing in PyTorch, CNNs, Imaginative and prescient, Speech, and Textual content AI. He’s an professional on on-device AI, mannequin optimization and quantization, ML and Knowledge Infrastructure. Authoring a chapter on Environment friendly PyTorch within the Environment friendly Deep Studying E-book at https://efficientdlbook.com/. His views are his personal, not these of any of his employer(s); previous, current, or future.
Naresh is deeply within the “studying” side of the Neural Community. His work is focussed on neural community architectures and the way easy topological adjustments improve their studying capabilities. He has held engineering roles at Microsoft, Amazon, and Citrix in his decade-long skilled profession. He has been concerned within the deep studying discipline for the final 6-7 years. You’ll find him on medium at https://medium.com/u/1e659a80cffd.
Gaurav is a Workers Software program Engineer at Google Analysis the place he leads analysis tasks geared in direction of optimizing giant machine studying fashions for environment friendly coaching and inference on units starting from tiny microcontrollers to Tensor Processing Unit (TPU)-based servers. His work has positively impacted over 1 Billion of lively customers throughout YouTube, Cloud, Advertisements, Chrome, and so forth. He’s additionally an writer of an upcoming e-book with Manning Publication on Environment friendly Machine Studying. Earlier than Google, Gaurav labored at Fb for 4.5 years and has contributed considerably to Fb’s Search system and large-scale distributed databases. He has an M.S. in Pc Science from Stony Brook College.





