Saying enhanced desk extractions with Amazon Textract

Amazon Textract is a machine studying (ML) service that robotically extracts textual content, handwriting, and knowledge from any doc or picture. Amazon Textract has a Tables characteristic inside the AnalyzeDocument API that gives the power to robotically extract tabular constructions from any doc. On this publish, we focus on the enhancements made to the Tables characteristic and the way it makes it simpler to extract data in tabular constructions from all kinds of paperwork.
Tabular constructions in paperwork corresponding to monetary studies, paystubs, and certificates of study recordsdata are sometimes formatted in a manner that permits straightforward interpretation of knowledge. They usually additionally embody data corresponding to desk title, desk footer, part title, and abstract rows inside the tabular construction for higher readability and group. For the same doc previous to this enhancement, the Tables characteristic inside AnalyzeDocument would have recognized these parts as cells, and it didn’t extract titles and footers which are current outdoors the bounds of the desk. In such circumstances, customized postprocessing logic to determine such data or extract it individually from the API’s JSON output was obligatory. With this announcement of enhancements to the Desk characteristic, the extraction of assorted features of tabular knowledge turns into a lot easier.
In April 2023, Amazon Textract launched the power to robotically detect titles, footers, part titles, and abstract rows current in paperwork by way of the Tables characteristic. On this publish, we focus on these enhancements and provides examples that will help you perceive and use them in your doc processing workflows. We stroll via find out how to use these enhancements via code examples to make use of the API and course of the response with the Amazon Textract Textractor library.
Overview of resolution
The next picture reveals that the up to date mannequin not solely identifies the desk within the doc however all corresponding desk headers and footers. This pattern monetary report doc comprises desk title, footer, part title, and abstract rows.
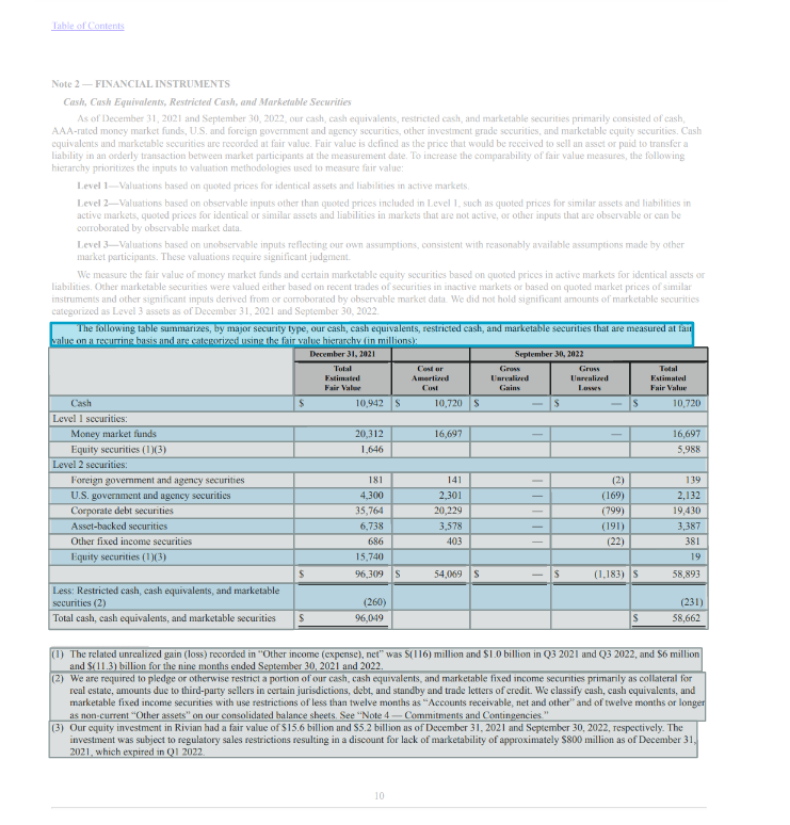
The Tables characteristic enhancement provides assist for 4 new parts within the API response that lets you extract every of those desk parts with ease, and provides the power to tell apart the kind of desk.
Desk parts
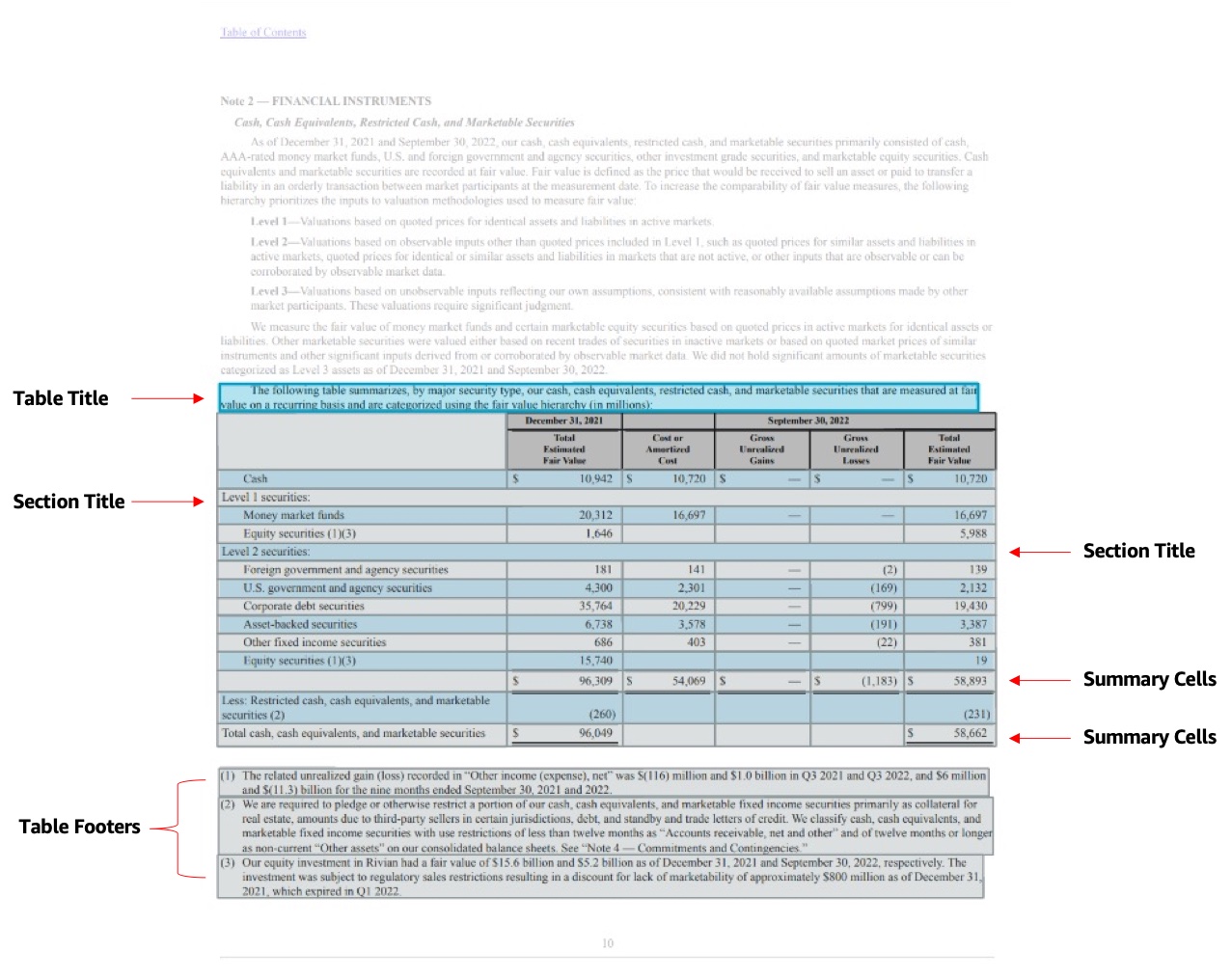
Amazon Textract can determine a number of parts of a desk corresponding to desk cells and merged cells. These parts, generally known as Blockobjects, encapsulate the main points associated to the element, such because the bounding geometry, relationships, and confidence rating. A Block represents gadgets which are acknowledged in a doc inside a bunch of pixels shut to one another. The next are the brand new Table Blocks launched on this enhancement:
- Desk title – A brand new
Blockkind known asTABLE_TITLEthat allows you to determine the title of a given desk. Titles might be a number of traces, that are sometimes above a desk or embedded as a cell inside the desk. - Desk footers – A brand new
Blockkind known asTABLE_FOOTERthat allows you to determine the footers related to a given desk. Footers might be a number of traces which are sometimes beneath the desk or embedded as a cell inside the desk. - Part title – A brand new
Blockkind known asTABLE_SECTION_TITLEthat allows you to determine if the cell detected is a bit title. - Abstract cells – A brand new
Blockkind known asTABLE_SUMMARYthat allows you to determine if the cell is a abstract cell, corresponding to a cell for totals on a paystub.
Kinds of tables
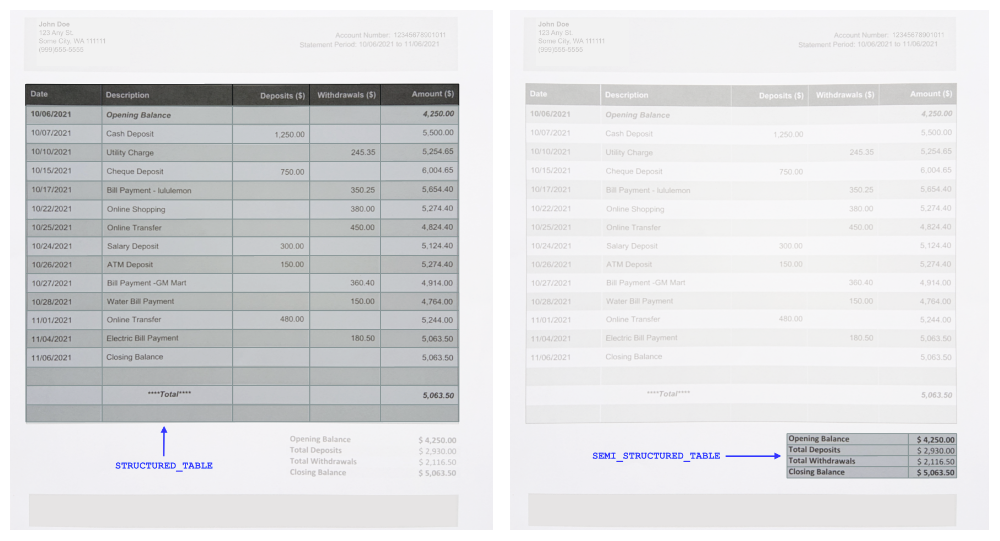
When Amazon Textract identifies a desk in a doc, it extracts all the main points of the desk right into a top-level Block kind of TABLE. Tables can are available in varied styles and sizes. For instance, paperwork usually include tables which will or might not have a discernible desk header. To assist distinguish a majority of these tables, we added two new entity sorts for a TABLE Block: SEMI_STRUCTURED_TABLE and STRUCTURED_TABLE. These entity sorts assist you distinguish between a structured versus a semistructured desk.
Structured tables are tables which have clearly outlined column headers. However with semi-structured tables, knowledge won’t observe a strict construction. For instance, knowledge might seem in tabular construction that isn’t a desk with outlined headers. The brand new entity sorts provide the flexibleness to decide on which tables to maintain or take away throughout post-processing. The next picture reveals an instance of STRUCTURED_TABLE and SEMI_STRUCTURED_TABLE.
Analyzing the API output
On this part, we discover how you should use the Amazon Textract Textractor library to postprocess the API output of AnalyzeDocument with the Tables characteristic enhancements. This lets you extract related data from tables.
Textractor is a library created to work seamlessly with Amazon Textract APIs and utilities to subsequently convert the JSON responses returned by the APIs into programmable objects. You can too use it to visualise entities on the doc and export the info in codecs corresponding to comma-separated values (CSV) recordsdata. It’s supposed to assist Amazon Textract prospects in establishing their postprocessing pipelines.
In our examples, we use the next pattern web page from a 10-Okay SEC submitting doc.
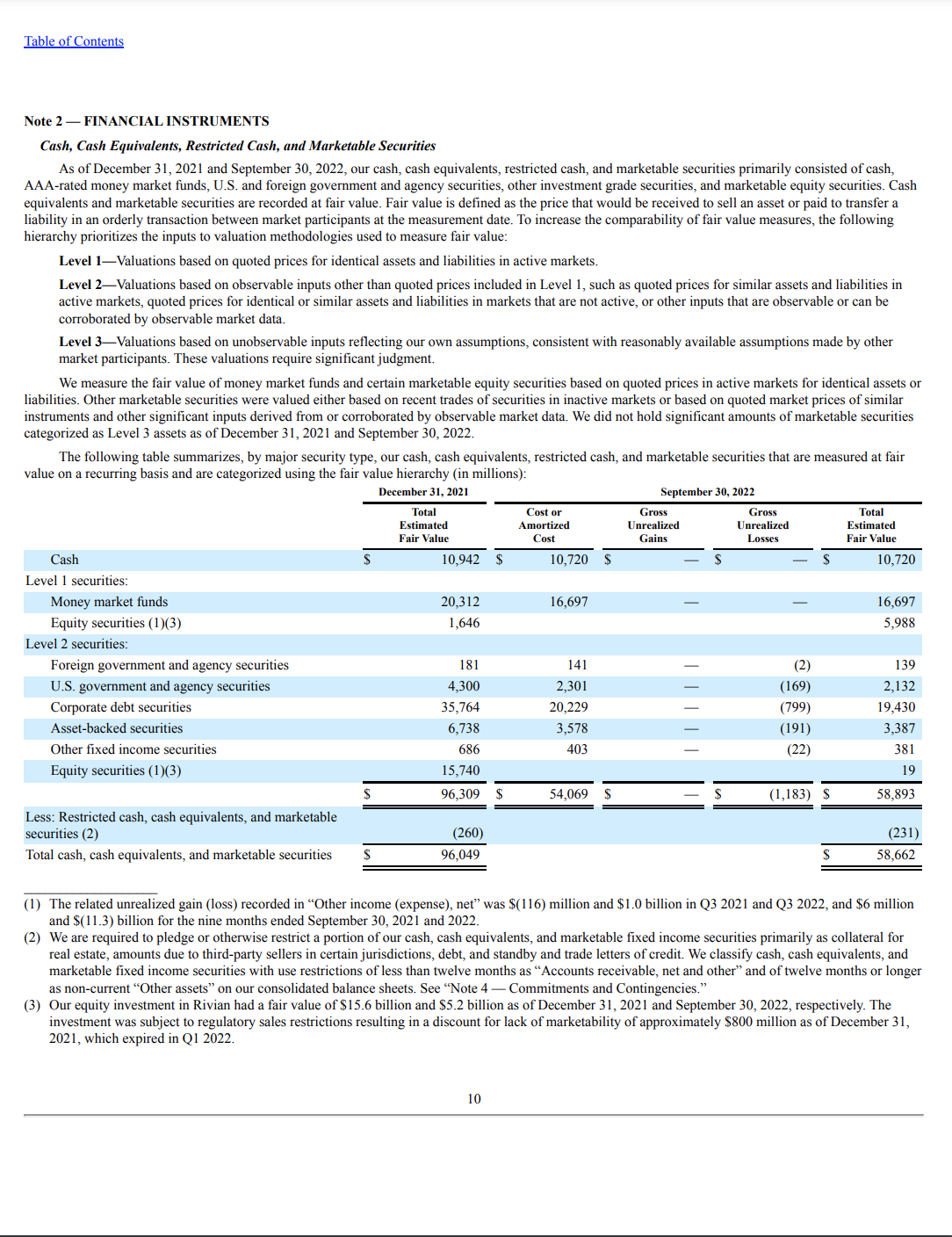
The next code might be discovered inside our GitHub repository. To course of this doc, we make use of the Textractor library and import it for us to postprocess the API outputs and visualize the info:
Step one is to name Amazon Textract AnalyzeDocument with Tables characteristic, denoted by the options=[TextractFeatures.TABLES] parameter to extract the desk data. Be aware that this technique invokes the real-time (or synchronous) AnalyzeDocument API, which helps single-page paperwork. Nonetheless, you should use the asynchronous StartDocumentAnalysis API to course of multi-page paperwork (with as much as 3,000 pages).
The doc object comprises metadata concerning the doc that may be reviewed. Discover that it acknowledges one desk within the doc together with different entities within the doc:
Now that now we have the API output containing the desk data, we visualize the totally different parts of the desk utilizing the response construction mentioned beforehand:
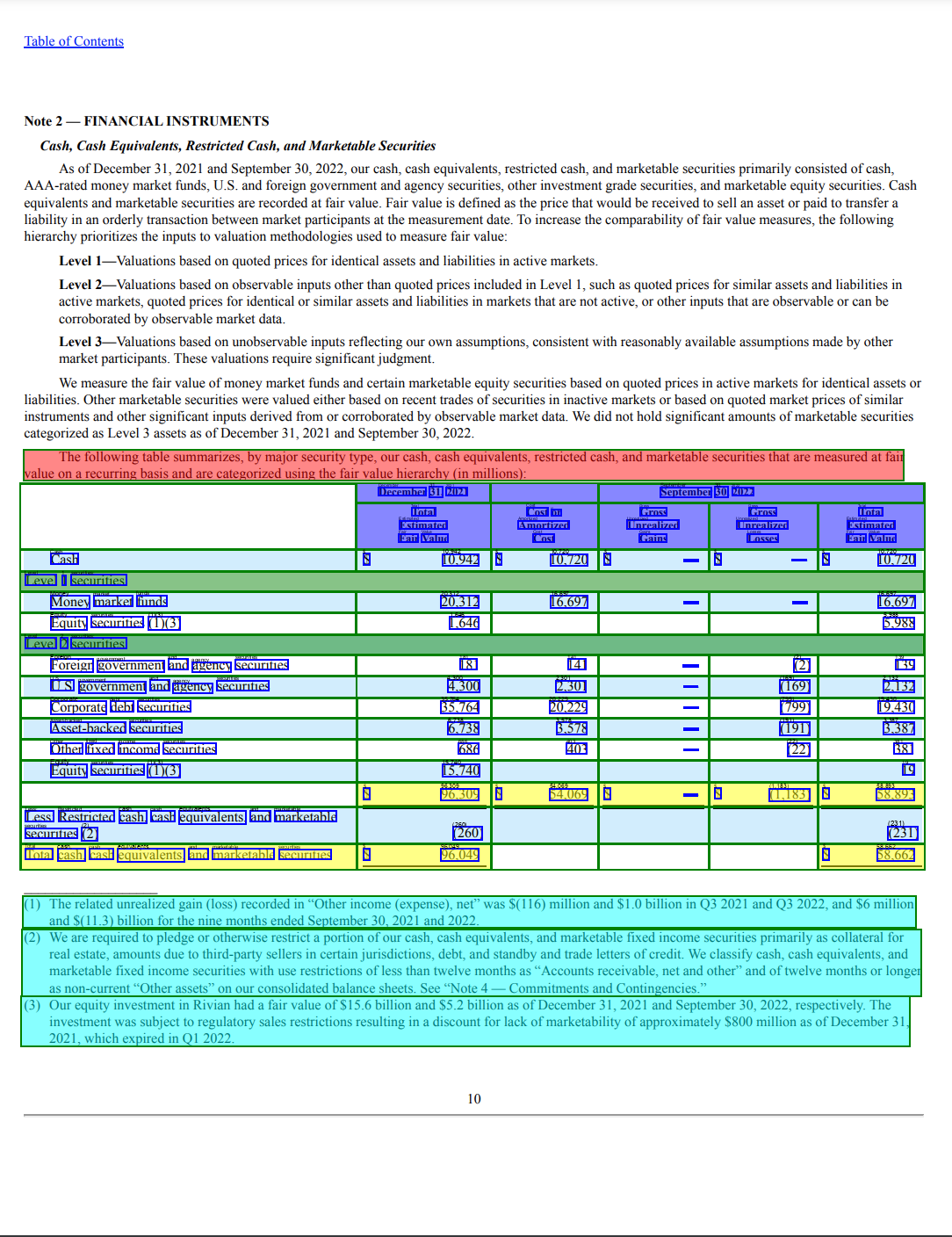
The Textractor library highlights the assorted entities inside the detected desk with a distinct coloration code for every desk aspect. Let’s dive deeper into how we will extract every aspect. The next code snippet demonstrates extracting the title of the desk:
Equally, we will use the next code to extract the footers of the desk. Discover that table_footers is an inventory, which signifies that there might be a number of footers related to the desk. We will iterate over this checklist to see all of the footers current, and as proven within the following code snippet, the output shows three footers:
Producing knowledge for downstream ingestion
The Textractor library additionally helps you simplify the ingestion of desk knowledge into downstream techniques or different workflows. For instance, you may export the extracted desk knowledge right into a human readable Microsoft Excel file. On the time of this writing, that is the one format that helps merged tables.
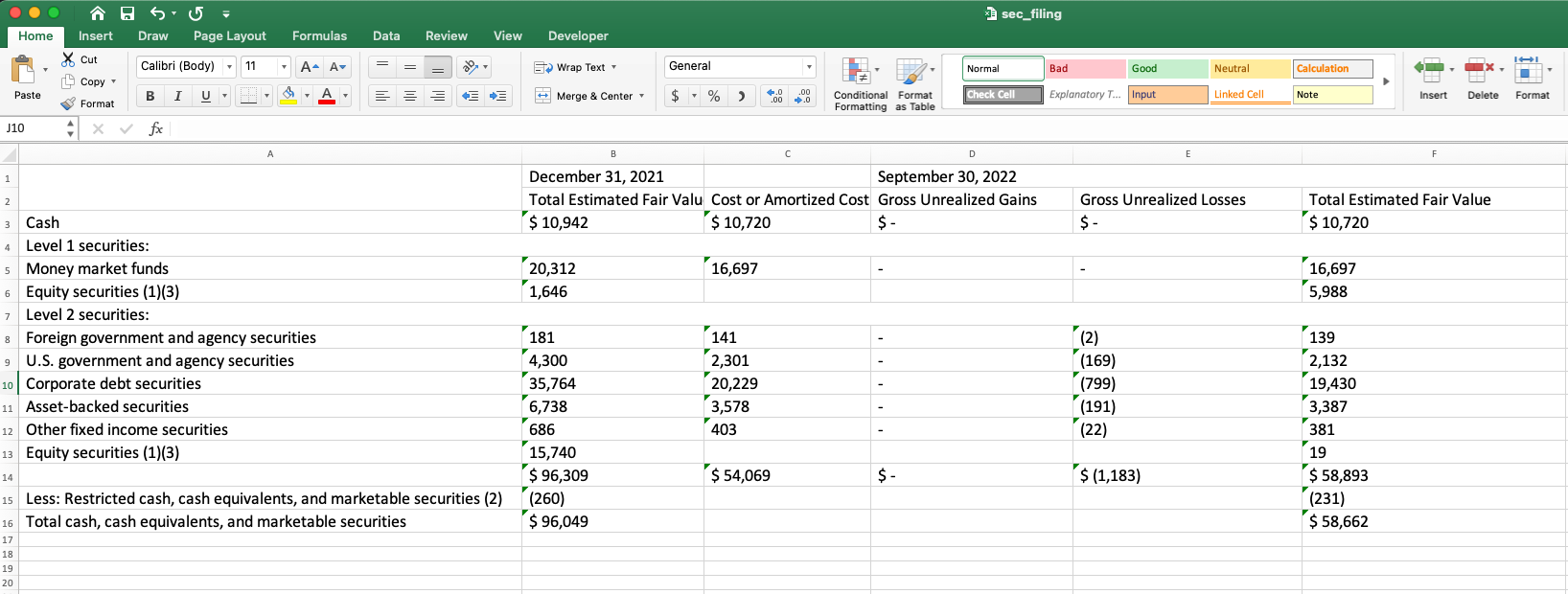
We will additionally convert it to a Pandas DataFrame. DataFrame is a well-liked selection for knowledge manipulation, evaluation, and visualization in programming languages corresponding to Python and R.
In Python, DataFrame is a major knowledge construction within the Pandas library. It’s versatile and highly effective, and is commonly the primary selection for knowledge evaluation professionals for varied knowledge evaluation and ML duties. The next code snippet reveals find out how to convert the extracted desk data right into a DataFrame with a single line of code:
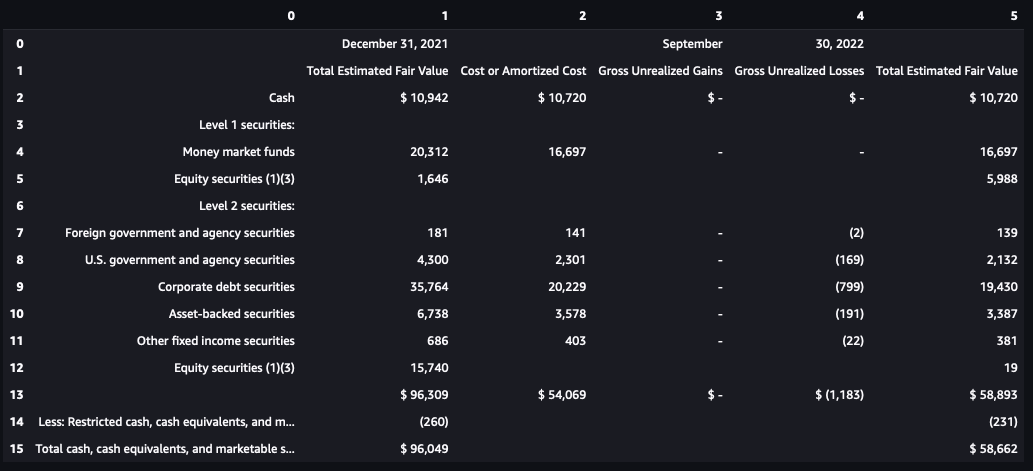
Lastly, we will convert the desk knowledge right into a CSV file. CSV recordsdata are sometimes used to ingest knowledge into relational databases or knowledge warehouses. See the next code:
Conclusion
The introduction of those new block and entity sorts (TABLE_TITLE, TABLE_FOOTER, STRUCTURED_TABLE, SEMI_STRUCTURED_TABLE, TABLE_SECTION_TITLE, TABLE_FOOTER, and TABLE_SUMMARY) marks a big development in extraction of tabular constructions from paperwork with Amazon Textract.
These instruments present a extra nuanced and versatile strategy, catering to each structured and semistructured tables and ensuring that no necessary knowledge is missed, no matter its location in a doc.
This implies we will now deal with various knowledge sorts and desk constructions with enhanced effectivity and accuracy. As we proceed to embrace the facility of automation in doc processing workflows, these enhancements will little doubt pave the best way for extra streamlined workflows, greater productiveness, and extra insightful knowledge evaluation. For extra data on AnalyzeDocument and the Tables characteristic, consult with AnalyzeDocument.
Concerning the authors
 Raj Pathak is a Senior Options Architect and Technologist specializing in Monetary Providers (Insurance coverage, Banking, Capital Markets) and Machine Studying. He focuses on Pure Language Processing (NLP), Giant Language Fashions (LLM) and Machine Studying infrastructure and operations initiatives (MLOps).
Raj Pathak is a Senior Options Architect and Technologist specializing in Monetary Providers (Insurance coverage, Banking, Capital Markets) and Machine Studying. He focuses on Pure Language Processing (NLP), Giant Language Fashions (LLM) and Machine Studying infrastructure and operations initiatives (MLOps).
 Anjan Biswas is a Senior AI Providers Options Architect with deal with AI/ML and Knowledge Analytics. Anjan is a part of the world-wide AI providers group and works with prospects to assist them perceive, and develop options to enterprise issues with AI and ML. Anjan has over 14 years of expertise working with international provide chain, manufacturing, and retail organizations and is actively serving to prospects get began and scale on AWS AI providers.
Anjan Biswas is a Senior AI Providers Options Architect with deal with AI/ML and Knowledge Analytics. Anjan is a part of the world-wide AI providers group and works with prospects to assist them perceive, and develop options to enterprise issues with AI and ML. Anjan has over 14 years of expertise working with international provide chain, manufacturing, and retail organizations and is actively serving to prospects get began and scale on AWS AI providers.
 Lalita Reddi is a Senior Technical Product Supervisor with the Amazon Textract group. She is concentrated on constructing machine learning-based providers for AWS prospects. In her spare time, Lalita likes to play board video games, and go on hikes.
Lalita Reddi is a Senior Technical Product Supervisor with the Amazon Textract group. She is concentrated on constructing machine learning-based providers for AWS prospects. In her spare time, Lalita likes to play board video games, and go on hikes.





